基于激光SLAM和深度学习的语义地图构建
2020-11-14郭乐江
何 松,孙 静,郭乐江,陈 梁
(1.空军预警学院,湖北 武汉 430019;2.空军通信士官学校,辽宁 大连 116100;3.武汉大学 计算机学院,湖北 武汉 430072)
0 引 言
传统的机器人SLAM(simultaneous localization and mapping)与导航避障算法,侧重于标识出障碍物并进行规避,它并不知道障碍物是什么,只需要绕开障碍物到达目的地即可[1]。但在实际生活中,智能机器人所处的工作环境往往是动态的、未知的,移动机器人自主导航过程中,需要能够实时地对周围目标进行识别并做出反应,以完成更复杂的特定任务。通过将识别的物体及位置信息,标注在SLAM得到的地图上,可以极好地提高地图的可读性和人机交互的便利性[2],同时也可应用于环境数据采集和物品搜索等多个方面。基于语义信息的地图构建技术[3-4]逐渐成为移动机器人自主导航研究的热点问题之一。
语义地图构建技术,也称为语义SLAM,其关键在于对环境中目标物体的语义识别和对其位置的精确标注[5]。结合语义信息的SLAM算法不仅能提升应用系统对环境的理解能力,还能提高SLAM算法定位与建图的精度[6]。随着深度学习技术的发展,特别是基于卷积神经网络(convolutional neural network,CNN)的相关算法在目标识别领域的应用和识别效率的提升,结合视觉信息、雷达点云数据、超声波数据等进行目标检测和定位[7-8],都成为语义地图研究的手段。近年来,国内外学者已提出较多的融合SLAM和深度学习的地图构建技术,如Tateno等人[9]提出CNN-SLAM算法,利用卷积神经网络预测的深度信息来取代SLAM算法本身对深度的假设和估计,McCormac等人[10]提出利用CNN架构结合ElasticFusion SLAM实现语义地图,白云汉等人[11]提出基于视觉SLAM和深度神经网络构建语义地图,屈文彬等人[12]提出多特征融合的服务机器人语义地图构建技术。
以上方法多是首先基于视觉SLAM构建环境地图,然后结合视觉特征和深度学习方法获取环境语义信息,进而构建语义地图。在实际应用中,机器人是融合多源传感器获取环境信息,常用的SLAM方法有激光SLAM和视觉SLAM,这两种方法各有优点和不足。其中激光SLAM技术起步较早,产品和理论成熟,运用激光雷达发射激光束来探测目标位置、速度等特征信息,并运用粒子滤波算法结合惯性传感单元(IMU)和机器人里程计数据来估计自身位置,具有测量精度高、方向准、地图数据量小,处理速度快等优点,但缺乏语义信息,基于激光点云特征进行目标匹配或深度学习的检测算法发展也不够成熟。而视觉SLAM可以获取丰富的纹理信息,基于视觉信息的深度学习目标检测获取语义信息技术发展已非常成熟。但视觉SLAM存在受光线影响较大,边界不够清晰,暗处纹理少,且运算负荷大,地图构建存在累计误差,难以直接应用于路径规划和导航等缺点。因此,文中综合激光雷达和视觉摄像头两类传感器的优点,采用激光SLAM构建环境地图,采用视觉信息运用深度神经网络检测算法识别目标语义,然后结合目标深度信息进行坐标转换,最终实现更精确迅速的实时地图语义信息标注,构建语义地图。
1 语义SLAM总体架构设计
结合现有的基于ROS的移动智能机器人,提出融合多源传感器获取语义地图的系统框架,如图1所示。
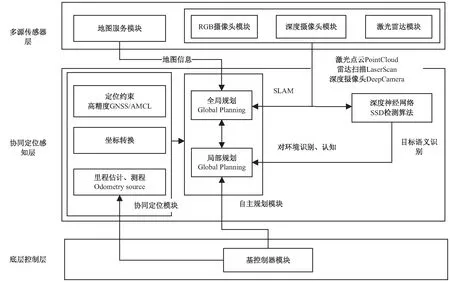
图1 语义地图系统框架
框架从上到下分为多源传感器层、协同定位感知层、底层控制层。
多源传感器层包括各类的传感器模块和地图服务模块,这一层主要依赖各类传感器,对外界环境进行独立感知,传感器主要包括激光雷达、深度摄像头、RGB摄像头等。从传感器获取激光点云、视觉RGB图像和深度图像等数据,数据在各自的ROS模块中进行处理,并发布成ROS标准消息格式,以供下层协同处理计算。地图服务利用传感器数据增量式构建地图将并地图数据交给下层。
协同定位感知层是机器人提高自我认知水平的核心,面向激光点云的AMCL(自适应蒙特卡罗)算法、里程计信息获得机器人自身的定位结果,各定位结果在ROS系统中进行坐标转换处理,实现机器人的协同定位,并将定位结果提供给自主规划模块和目标语义识别模块。目标语义识别模块将从上层获取的RGB图像信息带入深度神经网络中,获得图像中目标的语义信息及其在原始RGB图像中的位置,由目标在RGB图像中的位置可以从深度摄像头获得相应的物体深度图像信息,由此计算物体相对机器人的位置,并通过机器人自身的协同定位结果确定物体位置,并完成地图语义的添加。
底层控制层也称基控制模块,用于接收上层的运动控制信号,让机器人按照指令移动,并将机器人自身的状态信息反馈,进一步提高航迹推算与里程估计中的精度,它主要包含基控制器模块,将运动控制信号转化为电机运动的电信号,并将电机编码器、运动传感器信息反馈给上层,结合局部规则和全局规划算法,实现边定位边建图和自主导航避障,并完成语义级任务。
2 语义SLAM架构实现
2.1 基于单线雷达的激光SLAM
SLAM即同步定位与地图构建,是机器人根据传感器获取外部环境信息,以此增量式地建立机器人所处环境的地图,反过来又依靠建立的环境地图确定自身的位姿的过程,即定位和构图两个程序同步进行。激光雷达定位与建图的基本原理是根据雷达在高速旋转过程中不断发射激光束和获取反射信息,以采集其四周工作范围内障碍物的距离信息,组合成空间点云信息,经过滤波处理、地图拼合、回环检测从而得到空间地图信息。
该系统采取Google开源的Catorgrapher SLAM算法,主要包含cartographer和cartographer_ros两大部分。cartographer主要负责处理来自雷达、IMU和里程计的数据并基于这些数据进行地图的构建,是cartographer理论的底层实现。cartographer_ros则基于ros的通信机制获取传感器的数据并将它们转换成cartographer中定义的格式传递给cartographer处理,与此同时也将cartographer的处理结果发布用于显示或保存,是基于cartographer的上层应用。地图以占据栅格地图表示。用大小相同的栅格来表示当前的环境,每个栅格至少存在三种状态:未知、可通过、有障碍物。它尽可能保留了整个环境的各种信息,易于创建和维护。但是在环境范围较大时栅格地图占用空间过大,不易维护,此时的实时性也因为定位算法搜索空间太大而大打折扣。
而机器人同步定位应用的是AMCL算法,根据激光扫描特征,使用粒子滤波获取最佳定位点,即作为机器人在地图的位置点。其核心思想是用大量的粒子来描述机器人可能的位置,通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替状态方程,从而获得状态最小方差分布的过程。
2.1.4 微量元素缺乏 放牧过程中,由于当地土壤内微量元素的含量各有差异,很容易造成羊只的铁、硒、铜、锌、钴等微量元素的缺乏症。所以在养殖时尽可能补饲。
为实现机器人“边测绘,边规划”,系统采用一种基于D*动态规划算法的D*-SLAM算法,将D*动态规划和机器人SLAM构图整合,并设计其在ROS中的全局规划和局部规划实现过程。D*也称之为动态A*(D-Star,Dynamic A*),它是一种动态的路径规划算法,可在规划后对环境变化做出反应,动态修改自己的规划路径。
通过以上三种算法的结合,即可实现机器人边测绘边建图,实现自主路径规划和导航避障。但此处利用激光雷达所建环境地图只有障碍物位置标记,没有障碍物语义信息。
2.2 目标语义识别模块设计
目标语义识别模块是为了解决机器人对环境认知不足的问题,通过将基于深度学习的目标检测算法移植到ROS中,结合机器人深度摄像头测距与定位,实现机器人对目标的识别和地图语义的添加,包括目标识别和目标定位两大部分。常用的基于深度学习的目标检测算法有Faster R-CNN[13]、YOLO(you only look once)[14]和SSD(single shot multibox detector)[15]等。相比较而言,Faster R-CNN拥有较高的准确率,YOLO速度较快,而SSD算法综合二者的优点,其在实时性和检测精度方面都有较好的表现。文中选取SSD算法进行目标检测和识别。
2.2.1 基于深度学习的目标语义识别算法
SSD是一种基于深度学习卷积神经网络的物体检测模型,通过它可以获取到物体的语义信息和物体在图像中的位置,具有良好的实时性和准确率。它将整个物体识别过程整合成一个深度神经网络,便于训练和优化,从而提高检测的速度。
SSD网络结构如图2所示,它在网络的前半部分使用了一个普通的卷积神经网络,用于对图像中的目标进行分类,每一个类别会对应一个语义结果,如person、bottle、dog等,在网络的后半部分实现目标在图像中的定位。SSD网络使用了大量的小的卷积核(1*1,3*3),用于提取边缘特征和边界框的位置回归,通过一组边界框集合实现不同长宽比的目标检测,在卷积生成的多个尺度的特征图上,将特征图划分为8*8或者4*4的方格,每个小方格都有一组边界框集合,如图3所示,包含4个:长的、宽的、小正方形、大正方形,用于匹配物体位置。网络最终输出的向量将会和前面各层边界框与图像对应关系相连接,以此来进行网络的训练和图像中物体位置的确定。

图2 SSD网络模型

图3 SSD边界框示意图
SSD识别多尺度目标是通过不同层的特征图来实现的,低层的特征图对图像的细节表达出色从而可以提高语义分割质量,高层的特征图可以平滑分割结果。于是,将低层和高层的特征图综合起来进行检测。不同层的特征图有不同的感受野尺寸,然而不需要给某一层特征图构建不同尺寸的框,而是某层的特征图只学习检测某个尺度的对象,所以某一层的特征图只有一个尺度的框。从网络的低层到高层,框的缩放比例均匀地分布在0.2至1之间。为了进一步解决长宽比的问题,可设置不同长宽比的扩展框。
不同形状的框、不同的缩放比、不同的分辨率使得框的空间参数离散化,从而大幅提高了计算的效率。真值框的类别和位置在网络的训练时都必须明确告知给网络,并和网络输出进行比较,这样才能让损失函数的反向传播是端对端的。在训练时,需要将真值框和边界框对应起来,只要和真值框的覆盖率大于0.5,就能和该真值框对应上,每个真值框必须至少有一个边界框与其对应。对匹配的每个框计算和真值框的位移和分类概率,通过计算加权位置损失和分类置信度损失获得模型整体损失,最终结果通过极大值抑制来获得。
2.2.2 目标语义识别硬件
Kinect for Xbox 360,也称为Kinect,如图4所示,是由微软开发,应用于Xbox 360游戏主机的操控设备。它有深度摄像头和多个麦克风,为用户提供使用语音和肢体动作来操控游戏的体验[16]。

图4 Kinect摄像头
Kinect从左到右依次为红外发射镜头、RGB彩色摄像头、红外线CMOS摄像头。3D图像由红外线CMOS摄像头采集,它接收场景中的结构光,通过结构光来对镜头前的物体进行测距并形成深度的3D图像。彩色摄像头分辨率为1 280*960,红外摄像头分辨率为640*480。Kinect摄像头同时具有RGB彩色摄像头和红外测距摄像头,并且具有摄像头标定功能,可将各个摄像头获取的图像信息标定,形成同一幅图的彩色图像和深度图像。彩色图像可以用来做目标语义识别,深度图像可用于物体的测距和定位[17]。Kinect还具有追焦技术,它的底座是可以移动的,当摄像头对准焦点后,底座会跟着焦点转动,让摄像头随着焦点移动。Kinect微软官方推荐的距离为1 220 mm~3 810 mm,经过测试,精度在距离1 m时精度较高,误差在3 mm内,距离越远,精度越低,在距离3.6 m时,误差在3 cm内,采集频率为30帧每秒。ROS集成了Kinect的驱动包OpenNI,该驱动包将Kinect摄像头获取的深度图像信息、RGB图像信息发布在ROS中的主题上。
2.2.3 ROS目标语义识别模块设计
SSD算法可以识别出物体的语义信息和它在图像中的位置,根据从深度摄像头获取的图像深度信息,可以通过深度信息知道物体相对于深度摄像头的角度、位置,从而实现物体的识别和地图标注。
基于ROS的SSD目标语义识别模块结构如图5所示,它包含ObjectDection和UpdateMap两个节点,在ObjectDection节点中主要订阅Kinect图像信息,将原始RGB图像输入到SSD网络中,得到物体的语义信息和物体在原始RGB图像中的边界框。

图5 ROS目标语义识别模块结构
边界框是以原始图像左下角为坐标原点的四个坐标构成的方型框,框是算法识别出的物体范围,目标语义识别结果如图6所示。图6(a)表示它识别出了显示器,白色方框为显示器的边界框,算法认为框内物体为显示器的概率为0.980;图6(b)表示它识别出了椅子,并框出椅子位置,算法认为框内物体为椅子的概率是0.942。

图6 目标语义识别结果
在UpdateMap节点中将识别结果和深度图信息整合得到物体相对于机器自身的相对位置也就是在baselink坐标下的位置,将位置坐标通过baselink->odom->map坐标转换后,得到物体在map坐标系下的位置,将物体信息发布,由UpdateMap更新地图,实现目标语义信息在地图上显示。
目标语义识别算法流程如图7所示。首先通过Kinect摄像头获取标定后的RGB图和深度图,将RGB图带入SSD算法中,得到物体的目标语义信息和图像中的边界框,根据边界框确定深度图像中物体的范围,对该图像范围内的深度图像进行滤波,背景切割,只保留物体的深度图像信息,由物体的深度图像信息确定物体距离机器人的水平距离、角度,也就是物体在ROS的baselink坐标系中的位置,将该位置通过ROS的坐标框架进行变换,得到物体在map地图坐标系下的位置,将语义信息添加到地图该处的栅格中,从而实现目标语义识别和地图语义添加。

图7 目标语义识别算法流程
3 实验设计
3.1 实验平台
机器人的控制部分采用一种集成高精度导航定位与深度学习的机器人嵌入式计算终端,集成设置的核心处理单元包括Jetson芯片、FPGA芯片、嵌入式ARM模块和多种传感器,所述传感器IMU惯性导航模块、激光雷达和摄像头,核心处理单元Jetson芯片连接摄像头和激光雷达,FPGA芯片分别连接GNSS卫星导航模块和IMU惯性导航模块、嵌入式ARM模块;嵌入式ARM模块连接控制机器人的伺服电机;搭载软件栈,实现协同定位感知算法。运动部分采用turtlebot3机器人底盘,底盘有3个轮子,后两轮为主动轮差速轮,前轮为万向轮。主要硬件设备及软件配置参数如表1所示,外接传感器部分采用Rplidar雷达和Kinect摄像头。

表1 实验平台配置
3.2 语义地图构建实验
实现目标:在实验室室内环境,分别检验机器人在静止和移动情况下能否完成物体识别和地图语义的添加。(1)静止状态下:如人站在椅子旁边,检验机器人能否完成多目标识别和多目标地图语义添加。(2)移动过程中:规划路线使机器人自主移动并通过激光雷达传感器扫描室内环境,构建室内二维地图,检验构建地图过程中是否同步添加语义信息。
实验过程:在实验室空地开启机器人和其上的Kinect摄像头,运行物体识别节点,界面弹出窗口显示Kinect摄像头通过SSD深度神经网络对于物体的识别结果,可以看到程序在原始摄像头图像上叠加了物体的一些框,即物体的边界,设置其语义信息标注于位置框右上角,包话该物体类别以及程序推断其属于某一类别的概率。当移动机器人构建室内地图时,机器人能够创建全局地图,且地图上也会显示这些物体的标注,即语义信息,将其放大置于右侧,即完成语义地图构建,如图8所示。

图8 语义地图构建实验
由实验结果可以看出,Kinect摄像头成功识别出了椅子,并将椅子的地图语义添加到地图上,在地图上可以看到地图上椅子的位置显示“chair:0.98”,表示该位置为一个椅子,机器识别其为椅子的概率为0.98。继续移动机器人,椅子前方有一盆栽植物,地图上显示该位置“pollet plant:0.92”。表明当机器人在移动过程中识别出各个目标时,均能较准确地将语义和位置标注在地图上。
从实验结果可以看出,基于SSD深度学习神经网络对于物体进行识别,结合Kinect的深度图像,可以将物体的语义信息添加到地图中,加深机器人对于环境的理解。该方法具有较高的识别率、较好的准确率,且在多目标情况下表现出了很好的多目标识别效果,地图语义添加也比较准确,验证了该方法的有效性、可行性。
该实验是机器人感知、规划、控制的一部分,为提升机器人的认知能力、规划能力,基于ROS系统,设计了机器人协同定位感知算法,对机器人的自主规划模块、协同定位模块、目标语义识别模块进行统一设计和实现。自主规划模块实现了一种D*-SLAM算法,使机器人由先认知环境后规划路径的传统方式转变为边认知环境边规划路径的新型规划方式,增强其对陌生环境的适应能力。定位模块集成了现有的GNSS广域高精度定位算法,使其能够在ROS系统框架下持续、稳定地提供高精度的定位数据、里程信息,并实现和ROS坐标框架的整合,使它能与里程计和激光雷达AMCL组合进行协同定位,增强机器人在复杂环境下的自主定位能力。语义识别模块集成了现有深度学习识别方法,在ROS平台上实现高效的物体识别,在识别结束后,通过图像深度信息确定物体在地图中的位置,实现目标的地图语义添加,提升机器人对局部环境的认知能力,以更好地进行路径规划和完成语义级任务。
4 结束语
语义识别模块集成了现有深度学习目标检测方法,在ROS平台上实现高效的物体识别,在识别结束后,通过图像深度信息确定物体在地图中的位置,实现目标的地图语义添加,其关键在于语义和位置的准确性。因采用的传感器是单线激光雷达,目标语义识别模块对于物体的识别和地图语义的添加目前只是在二维平面上,后期可以考虑在三维空间内实现语义的添加,并且加强训练集,以丰富地图语义的内容,提升机器人对局部环境的认知能力,为后期基于地图语义的机器人应用开发打下基础。
