融合Fisher判别分析的多任务深度判别度量学习的化妆人脸验证方法
2020-11-12陆兵
陆 兵
(常州工业职业技术学院信息技术与工程学院 江苏 常州 213164) (常州大学信息科学与工程学院 江苏 常州 213164)
0 引 言
近十年,人脸识别技术成为计算机视觉和图像处理等领域的热点研究。人脸识别问题常分成两大类:人脸确认和人脸验证[1]。人脸确认是解决“你是谁”的问题,在给定的数据库中查询确认未知人脸的身份;人脸验证解决“是你吗”的问题,通过人脸的一对一比对,确认两张人脸是否属于同一个人。目前,人脸验证广泛应用到不同的身份验证场景中,如支付宝商用的“刷脸支付”,机场和地铁站启用的“刷脸登机”和“刷脸进站”,以及住宅公寓实施“刷脸开门”等。与传统的指纹识别和虹膜识别相比,人脸验证的特点在于:1) 借助于国内权威的身份证人脸数据库系统,实施人脸验证的基础数据强大;2) 无须验证者的主观配合,仅需人员面对摄像头就可完成验证操作;3) 人脸作为人类最明显的生物学特征, 对验证者的自我认知具有参考意义。
随着人工智能、云计算和高性能计算的发展,人脸验证领域出现了大量性能优秀的算法,逐步解决了与姿势、照片和面部表情等相关的难题,这些算法能够在不同应用场景中实现无约束的人脸验证和面部识别。但人脸验证仍在一些应用中存在挑战,包括跨年龄场景和化妆场景等。在现实世界的应用中,面部化妆常见且会显著改变面部的感知外观,降低人脸的辨识,文献[2-4]指出面部化妆对绝大部分的人脸验证算法的性能带来负面的影响。由图1所示的化妆前后的人脸差异比较可以直观地看到面部外观的明显变化。因此,对人脸化妆具有鲁棒性的人脸验证算法在实际应用中具有重要的意义。为了开发一个强大的面部识别系统,化妆品对人脸验证的影响亟需解决。为此,文献[5]提出一种双属性方法分别学习化妆和非化妆的面部属性,面部匹配使用语义级属性来减少化妆对低级特征的影响。文献[6]使用自商(self-quotient image)图像技术对人脸图像进行预处理,以减少人脸匹配前的化妆效果。然而,这些方法不能显著降低化妆品的影响。文献[7]提出一种基于相关的构造不变人脸认证方案。文献[8]提出一种人脸特征向量的方法,能捕获了输入人脸的形状、纹理和颜色特征,并利用分类器确定是否存在化妆。除了从整个面部提取特征外,该方法还考虑了面部与左眼、右眼和嘴巴相关的部分。文献[9]为了进一步降低化妆品对人脸识别的影响,提出一种人脸化妆品检测方法,能捕获输入面的形状和纹理特征,并使用三个公开的面部化妆数据库测试了该技术的性能。

图1 同一个人化妆前后的差异比较示意图
近年来,深度学习方法显著改善了人脸验证[9-10]。深度学习方法可以分为两类:(1) 基于深度神经网络提取非线性特征和识别特征来表示人脸图像。例如,文献[11]根据人脸属性和人脸结构的特征,使用卷积神经网络和人脸部件来处理人脸的识别。文献[12]采用深度卷积神经网络端到端地学习人脸特征,并使用双线性模型对网络多个尺度下的输出特征进行二阶池化以加强人脸特征的判别。(2) 深度度量学习。目前常用的距离学习的距离度量方法主要基于欧氏距离和马氏距离,但这些方法不足以解决复杂场景下的人脸识别问题[13]。深度度量学习的目标是使用深度学习的方法来学习距离度量,以发现配对样本之间的相似性和不配对样本之间的差异性。文献[14]使用从原始图像到特征空间的非线性变换的方法,提出了基于深度独立子空间分析网络的度量学习。文献[15]提出一种用于人脸识别的深度判别度量学习(Deep Discriminative Metric Learning,DDML)方法,该方法利用层次非线性变换学习来解决野外人脸识别问题。
在面对化妆人脸验证的任务时,通常认为无论外表如何变化,同一个人的一对面部图像与所呈现的化妆品都应具有最大的相关性,而不同的人即使拥有相同的化妆品或不化妆,也不应具有很大的相关性。人脸验证可以看作是一个二值分类问题[16],同一个人的图像对可以标记为正对,不同人的图像对可以标记为负对。从分类的角度来看,如果能找到一个投影空间,使得同一个人图像距离尽可能小,不同人图像间的距离尽可能大,那么人脸验证问题可以得到有效解决。另外,人脸具有很多属性,而属性之间很多是具有一定的相关性的,例如:如果性别是女性,其极大可能会涂抹口红和穿戴配饰等,这些属性是强相关的;如果性别是女性,一般也没有谈论其胡须颜色和形状的需要,此时性别和胡须的关系可形成互斥关系。按照这些关系,将人脸属性分组或形成多任务学习,可提高人脸识别的准确性[17]。本研究通过属性划分,将多个化妆人脸验证任务构成了多任务学习,任务间可以共享各自学习的知识,从而提高每个任务的学习性能。本文基于DDML模型构建一个深度判别度量学习,并融入Fisher判别分析和多任务的思想,提出了融合Fisher判别分析的多任务深度判别度量学习(Multi-task Deep Discriminative Metric Learning with Fisher Discriminant Analysis,MT-DDML-FDA)模型。MT-DDML-FDA使用多层深度判别度量学习结构,通过共享一个网络层,在多个任务之间学习共享的转换知识来捕获不同任务的人脸图像之间的潜在识别信息。神经网络的每一层均形成非线性变换,以形成一个良好的距离度量。同时,融合Fisher判别分析将类内相关矩阵和类间相关矩阵引入深度神经网络,将具有高相似性的类间样本投影到一个邻域中,使得类间邻域样本尽可能远离,保证每个任务所学习的距离度量以有效的方式执行。MT-DDML-FDA的优点在于:1) 引入多任务学习框架,在多个任务之间学习共享的投影信息,这些投影信息可以捕获不同任务的人脸图像之间的潜在识别信息。2) 利用每个任务特殊的识别信息,同时考虑不同任务之间的差异性,使得每个任务所学习的距离度量更有效。3) 图像的局部几何信息是人脸识别问题的重要信息,将Fisher判别引入多任务深度度量学习,在投影过程基于配对信息建立能较好区分人脸图像的方法。实验结果表明,MT-DDML-FDA在真实化妆人脸数据集Disguised Faces in the Wild (DFW)上取得了较好的性能。
1 相关知识
1.1 度量学习

(1)
马氏距离学习一个d×m(m≤d)的变换矩阵W,矩阵A可以分解为A=WTW,而成对图像之间的距离可以写为:
(2)
虽然马氏距离度量学习可以等价于基于矩阵W计算变换子空间中的欧氏距离,但是式(2)得到的线性变换不能捕获图像的复杂非线性结构。
1.2 深度判别度量学习
深度判别度量学习(DDML)[15]采用深度神经网络框架下学习多层次的非线性变换。假设一个L+1层神经网络,对于人脸图像xi,其第一层的输出是g(1)=φ(W(1)x+b(1)),其中φ函数是一个非线性激活函数,W(1)和b(1)分别是第1层中学习到的映射矩阵和偏差向量。网络前一层的输出作为后一层的输入,因此,顶层的输出是g(L)=φ(W(L)g(L-1)+b(L)),其中g(L-1)是第(L-1)层的输出,W(L)和b(L)是顶层学习到的映射矩阵和偏移向量。给定成对图像xi和xj,DDML使用以下欧氏距离计算两个图像之间的距离度量:
(3)
DDML在深度神经网络最顶层的优化问题为:
(4)
式中:‖·‖F是F-范数;函数f(·)是广义逻辑损失函数;lij是两个图像的成对标号;λ(λ≥0)是正则化参数。
2 模型设计
多任务学习通过共同学习多个相关任务来提高每个任务学习的效果。多任务之间共享的有用信息能防止对某一任务的过度学习[19]。相关任务之间的信息传递常见的类型有:共享投影[20]和共享参数[21-22],如马氏矩阵和正则化参数等。鉴于深度判别度量学习的特点,MT-DDML-FDA模型在DDML的基础上让多个任务共享一个公共投影,即设置深层度量学习中的公共层,那么所有任务共享的投影将有助于每一个任务的学习。以三层神经网络为例,MT-DDML-FDA模型的示意图如图2所示。

图2 三层MT-DDML-FDA模型的示意图
假设同时有M个任务学习,给定第m个任务的人脸图像对{(xm,i,ym,i,lm,i)|i=1,2,…,nm,m=1,2,…,M},其中:xm,i,ym,i∈Rd表示任一人脸图像;lm,i表示其相应的图像对的标签,lm,i=1说明图像xm,i和ym,i来源于同一人,lm,i=-1说明图像xm,i和ym,i来源于不同的人。如图2所示,MT-DDML-FDA的第1层是所有任务的共享层,输入的人脸图像xm,i在共享层的输出g(1)(xm,i)为:
g(1)(xm,i)=φ(W(1)xm,i+b(1))
(5)

(6)
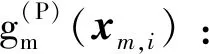
(7)

(8)
根据上文在多任务深度判别度量学习的框架上考虑Fisher准则,即引入各个任务中人脸图像数据的类间和类内相关矩阵,从而MT-DDML-FDA定义的优化问题如下:
(9)

(10)
(11)
式(10)和式(11)中的qi,c和qi,b分别定义如下:
(12)
(13)

下面介绍MT-DDML-FDA的求解方法。在众多的训练方法中,反向传播方法是神经网络常用的训练策略。反向传播方法使用递归更新算法,可以在输出层更新所有映射矩阵和偏差向量,并返回到第一层。在训练过程的每次迭代中,根据梯度下降公式更新各层的参数,映射矩阵和偏差向量为:
(14)
(15)
式中:μ是梯度下降的学习速率。
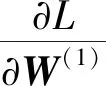
(16)
(17)

(18)
(19)
(20)
(21)
(22)
(23)
式中:Δ表示元素乘法运算。根据MT-DDML-FDA的输入可得:
(24)
(25)
基于以上的分析,MT-DDML-FDA模型见算法1。
算法1MT-DDML-FDA模型
输入:P个任务的人脸图像,正则化参数α,β,最大迭代次数T, 最大近邻数k,和收敛阈值ε。

Step1特征提取每对人脸图像的特征,得到P个任务的人脸图像对的特征向量表示Xk={(xk,i,xk,j,li,j)|k=1,2,…,P};
Step2初始化所有映射矩阵和偏差向量;

Fort=1,2,…,T
Fork=1,2,…,P

Step5使用式(8)计算d2(xp,i,yp,i);
Step6从第L层到第一层使用式(14)和式(15)计算∂J/∂W和∂J/∂b;
Step7更新映射矩阵W(1)和偏差向量b(1);

Step9使用式(9)计算目标函数Jt;

end
Step11如果|Jt-Jt-1|<ε,转至Step 12;
end

3 实 验
3.1 实验设置
本文选用了被广泛应用于化妆人脸数据集Disguised Faces in the Wild (DFW)[23]和变化人脸数据集CALFW[24],如图3所示。DFW数据集中包含了从网络上收集的1 000个人的11 155幅不同的图片,来自于电影明星、歌星、运动员和政治家等的人脸图像,每个人物均包含一幅未化妆和多张化妆人脸图像,并且在姿态、年龄、光照和表情等方面存在差异。每人有多幅不同图片,包含一幅不化妆照片和多幅化妆照片,佩戴眼镜和帽子也算化妆的范畴。CALFW数据集是广泛使用的LFW人脸数据库的一个子集, 内容同样来自电影明星、歌星、运动员和政治家等的人脸图像,共包括4 025个不同人的图像,每人2~4幅图片。本文从DFW数据集和CALFW数据集中分别选取900对和300对人脸,按照男士(不戴帽子和眼镜)、男士戴帽子、男士戴眼镜、女士(不戴帽子和眼镜)、女士戴帽子和女士戴眼镜,分成6个任务,每个任务中的负对采用随机选取的方式获得,各个任务的基本信息如表1所示。每个任务随机将75%的数据作为训练集,用于多任务学习,剩下25%的数据作为测试集。整个训练和测试过程执行5次,取5次的平均计算结果作为最终结果。

图3 化妆数据集DFW和CALFW示意图

表1 多任务子集基本信息
参考文献[7],本文使用HOG[25](Histogram of Oriented Gradient)和LBP[26](Local Binary Pattern)2种特征提取算法对人脸图像进行处理。HOG算法设置图像块大小为16×16,共提取特征为1 764维。LBP将每幅人脸数据集图片分为16×16像素的16块非重叠区域,共提取3 776维数据特征。获得的特征经Principal Component Analysis (PCA)处理将至500维。实验对比方法采用了LFDA[27](Local Fisher Discriminant Analysis)、LMNN[28](Large Margin Nearest Neighbor) 、MDMML[29](multiview discriminative marginal metric learning)和DDML[6](Deep Discriminative metric learning)。在实验中,DDML和提出的MT-DDML-FDA均采用3层神经网络,神经节点为200、200、100,激活函数使用Sigmoid函数。每一层的初始化权重矩阵其主对角线上的元素为1,其他元素为0;初始偏移向量为0。参数β和γ的网格搜索范围{10-2,10-1,…,102}, 最大近邻数k的网格搜索范围{5,7,…,13}。经过大量实验,收敛阈值ε取值10-5,梯度下降的学习速率为0.05。3个对比算法参数的设置均按照对应文献中的默认设置进行设定。评价标准本文采用了分类精确率(Classification Accuracy Rate,CAR)、错误率(Equal Error Rate,EER)和ROC曲线下面积(area under the Roc curve,AUC)。CAR为nc/nt,nc为测试集中分类正确的图片对的数目,nt为测试集中所有图片对的数目。参考文献[7],实验采用的分类器为SVM[30]。
3.2 不同特征下算法性能的比较
表2显示了基于HOG特征提取的MT-DDML-FDA和3种对比算法在CAR、EER和AUC指标上的性能比较。表3显示了基于LBP特征提取的MT-DDML-FDA和3种对比算法在CAR、EER和AUC指标上的性能比较。两表的实验结果表明: 1) MT-DDML-FDA在CAR、EER和AUC指标上均取得了最佳结果。MT-DDML-FDA使用深度判别度量学习和多任务的学习框架,同时利用Fisher判别能提取每个任务的独立信息,挖掘所有任务3之间共享的隐藏相关信息,MTCS-TSK-FS能够获得最佳的性能。LFDA主要基于局部判别扩大负对数据的间隔;LMNN主要利用领域间样本的大间隔信息,均不能充分有效地利用配对信息,因此仍然表现出较差的能力;DDML虽然使用多任务深度判别度量学习方法,但不能有效地利用所有任务之间的信息,特别是不能利用所有任务之间的公共信息,其性能不能达到理想的结果。2) 所有算法在Task1和Task4任务取得了相对较高的性能,在其他4个任务上取得了较低的性能,这是因为Task1和Task4任务人物图像仅化妆而没有佩戴眼镜和帽子,Task2、Task3、Task5和Task6任务在化妆的基础上还佩戴了眼镜或者帽子,使得脸部增加了遮挡的物品,提升了人脸验证的难度。进一步提升面部有遮挡时的人脸识别问题是下一阶段的目标。3) 对比算法在CAR、EER和AUC指标取得了一致的结果,说明使用这3个指标来评价化妆人脸的验证结果是合适的。另外,在HOG和LBP特征上也取得了类似的结果,也说明这2种特征提取方法也是适合用来提取化妆人脸特征向量的。

表2 基于HOG特征提取的CAR、EER和AUC性能及其方差 %

续表2

表3 基于LBP特征提取的CAR、EER和AUC性能及其方差 %

续表3
为了更好地比较MT-DDML-FDA与对比算法的性能,图4和图5展现了两个数据集下的4种算法的ROC曲线。实验结果可以看出:1) 2种深度学习方法(MT-DDML-FDA和DDML)都优于度量学习方法,因为深度学习方法可以在深度多层次结构中学习更多的人脸识别信息。2) 在多任务学习的启发下,MT-DDML-FDA在不同任务的人脸图像中学习到比其他深度学习方法更有用的识别信息。因此,深度学习非常适合于多任务学习。3) 虽然多视角MDMML方法取得了不错的识别性能,但其不是深度学习方法,不能深度挖掘人脸识别信息。4) MT-DDML-FDA基于Fisher准则充分考虑了人脸图像对的配对信息,使得同一人人脸图像在投影空间尽可能地接近,不同人的人脸图像在投影空间尽可能地远离。因此,配对信息和样本几何信息都对人脸配对的性能产生了积极的影响。

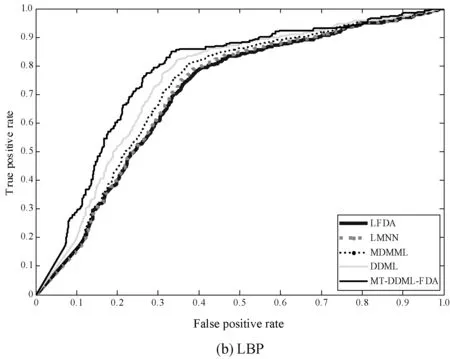
图4 DFW数据集不同特征下不同算法ROC曲线比较


图5 CALFW数据集不同特征下不同算法ROC曲线比较
3.3 模型参数选择
MT-DDML-FDA模型中参数β、γ和最大近邻数k均与模型的性能有关,本节对参数β、γ和k进行分析,表4-表6显示了MT-DDML-FDA模型6个任务在在DFW数据集上基于HOG特征提取的不同参数β、γ和k值下的CAR、EER和AUC的平均值。

表4 参数β不同时基于HOG特征提取的MT-DDML-FDA模型6个任务的平均性能 %
从表4的结果可以看出:1)β取值的不同导致了MT-DDML-FDA模型的不同性能。β数值的高低体现了多层深度神经网络的共享层上学到的共享参数映射矩阵W(1)和偏差向量b(1)在目标函数中的比重。β值越大,W(1)和b(1)在目标函数中的比重越大,目标函数更多地考虑共享知识在多任务学习中的作用。2)β值与CAR、EER和AUC的平均值之间无规律可循。MT-DDML-FDA算法在DWF数据集上β=1时,CAR、EER和AUC的平均值取得了最佳性能。因此,使用网格搜索法确定β的最优值是可行的。
从表5的结果可以看出:1)γ取值的不同也导致了MT-DDML-FDA模型的不同性能。γ体现了多层深度神经网络的各个独立层上学到的映射矩阵和偏差向量在目标函数中的比重。γ值越大,各个独立层参数在目标函数中的比重越大。2)γ=1时,CAR、EER和AUC的平均值在化妆数据集DWF取得了最佳性能。
从表6的结果可以看出:1)k值表示类内相关矩阵和类间相关矩阵中的近邻数。k值过小或过大时,类内相关矩阵和类间相关矩阵均不能合适地表示人脸图像的内在数据结构。因此,k值小于7值,CAR、EER和AUC的平均值较低;当k值大于11值,CAR、EER和AUC的平均值也出现了下降的趋势。2) 因为k取值与数据集的分布和内在结构密切相关,因此针对数据集使用网格搜索法确定k的最优值是可行的。
4 结 语
本文提出了适用于化妆人脸验证的融合Fisher判别分析的多任务深度判别度量学习MT-DDML-FDA模型。MT-DDML-FDA使用多任务深度度量来学习一个距离度量,并同时使用Fisher判别分析来度量化妆人脸图像对之间的相似性。MT-DDML-FDA的第1层网络作为一个共享层,从第2层开始是对应不同的任务的分离层。共享层有助于发现不同任务之间潜在共享知识,而分离层学习各个任务之间的差异性知识。真实化妆人脸数据集的实验结果表明,MT-DDML-FDA模型有助于利用多个人脸验证任务的知识,形成良好的距离度量来区分人脸图像对的相似性和不同性。但本文提出的模型依然面临进一步需要探讨的问题:如何将深度特征提取到MT-DDML-FDA模型中,来进一步地提高化妆人脸验证的性能。未来将扩大研究范围,将本文模型应用到更多的人脸验证实例中。
