大数据环境下审计取证定位及其方向选择研究
2020-11-11李浩尘谢劲松
李浩尘 谢劲松
[摘要]本文通过开展大数据环境下审计取证定位及其方向选择问题研究,旨在尝试为人工智能审计软件设计开发提供新思路,为审计证据定量研究提供新途径,为快速准确获取审计证据探索新方法。
[关键词]大数据 审计取证 定位 研究
随着计算机、物联网等技术的应用与普及,网络空间中人、机、物交互、融合产生和获取的数据规模与速度极大提高,由此人类社会步入大数据时代。在这种情况下,如何在海量数据中挖掘到与被审计单位相关的各种有用信息,准确高效地获取审计证据,是审计人员必须面对和思考的问题。由于研究范围仅涉及证据收集切入点选择等问题,因此,通过引入信息生成传递及决策树模型,将重点放在对同一经济活动信息集合中信息链环上的上/下位信息及其相互关联等方面。
一、上/下位信息概念、成因及其表現形态
(一)从信息生成规律分析
审计中审计主体接触到的各种信息,均属于被审计单位相关经济活动的自在信息、自有信息和记录信息集合。其中,自在信息是经济活动以信息方式向外部世界显示的存在和特征,在转化为人类大脑记忆或者机器智能、信息系统信息及通过一定载体记录为文字、符号、电子数据等信息之前,人类意识不到它,更谈不上认识它。这类信息遵循了物质世界物理学定律,在时空上位置指向唯一。如未经计量的用户照明、动力等电能。这种随时间变化处理的信息,是经济活动信息集合中的底层信息(初始信息),是自有信息和记录信息的唯一来源,是认识信息时空序列的客观依据。在数字化时代,这些信息通过交互式应用系统(如Web系统、互联计算机集群——云系统、电子商务系统等)、嵌入式应用系统(如移动电话中使用的软件)、数据采集系统、批处理系统运行顺序输出生成记录信息。如电网企业通过集中抄表终端(或公用变压器采集终端)对低压电力用户电能数据和配电变压器用电量及运行参数的实时采集的数据;通过单片机(主控MCU模块,又称中心单元)将实时采集数据经过处理、控制,输出、上传到采集终端器和主站数据库等数据。这些数据保持了经济活动发展踪迹,体现了被审计事项的时序构成,组成了信息集合原子性(不可分割)、序列化链环。这种同一信息集合中含义相互关联、相互承续,时空位置相邻、生成顺序邻接的信息称为链环信息。
当链环信息成为审计对象时,审计主体会根据审计假设或命题信息需要,将审计取证切入点或者审计观察点前后相连的链环信息划分为上位信息与下位信息。这种划分是信息含义上的划分,与信息载体独立与否无关。其中,上位信息是下位信息的部分或全部来源,下位信息是上位信息含义的承续,是上位信息这个“因”或“前提”基础上产生的“结果”。审计中,如果上位信息得到查实,那么与其相关联的下位信息自然也就得到查实。反之,下位信息所蕴含的上位信息就不可能得到查实。查证属实、符合经济活动时空次序的上位信息属于确定性信息,而确定性信息是形成审计证据的基础;下位信息与当下审计命题或假设无关,是另一事项信息,相对于特定被审计事项而言,它属于非相关信息,而非相关信息不能作为证据使用。如果下位信息可以证成上位信息,实质上就是错误预设了下位信息已经隐含了上位信息被证明的事实,用需要证明的事实去证明事实自身,其逻辑推理的结果必然是死循环,违背了逻辑规律。
为便于理解,举例说明。如审计主体在审查某国有企业员工出差费用报销的真实性时,记载这项经济活动的记账凭证以及相关的明细账、总账记录等下位信息就不能作为证明员工出差的证据使用,作为证据使用的只能是员工出差申请单以及车船票、住宿费发票等上位信息。
从信息生成来源考察所获得的上/下位信息,属于实质性的上/下位信息,它是审计取证定位及方向选择的客观依据。
(二)从计算机软硬件体系结构中数据流的规律分析
在现阶段计算机的计算模型下,无论是传统的控制流计算模型即计算机内的数据按指令循序操作模式,还是大数据处理平台上以数据流为核心的数据流计算模型即新型数据驱动方式处理生成的数据,都是按上一个数据计算处理完成,将结果传递给下一个计算单元操作执行这一顺序进行的。各种信息系统在需求描述、设计、开发以及运行中均遵循了经济活动的规律,体现了实际业务流程,具有严密的逻辑性。编程语言也提供了相应的实现语句。例如,C++程序设计语言就提供了多种不同的控制流语句,其中顺序执行的语句规定:第一条语句首先执行,然后是第二条语句,以此类推。现阶段,被审计单位各种交互式应用系统、嵌入式控制系统、批处理系统、数据采集系统、集成式系统等,所采用的计算机语言和解决实际问题的算法,都是按经济活动时序关系或程序设计语言事前确定的方向和有限规则操作步骤设计运行的,反映了被审计单位经济活动数据处理的过程与流程,体现了经济活动信息含义的递归关系,如货币资金=库存现金+银行存款+其他货币资金,总是从“库存现金”到“银行存款”和“其他货币资金”的值计算“货币资金”的值。
计算机软硬件体系结构中数据流所形成的上/下位信息属于形式上的上/下位信息,它是审计主体认识实质性上/下位信息的结构化、形式化载体。
(三)从智能化审计软件推理过程分析
随着人工智能(Artificial Intelligence,AI)技术的快速发展及其在金融、交通、商业、电信、电力等领域的广泛应用,被审计单位生产经营活动过程中人、机、物交互、融合所产生的并在互联网上获得的数据也将越来越多。适应这些大容量、多类型、集中化存储的海量数据的智能化审计软件,也将得到快速开发与应用。智能审计软件所采用的从初始事实(证据)出发,运用知识库中特定领域的基本原理、常识或经验知识,通过推理机逐步推出与审计命题或审计假设相关的审计结论的推理过程,系统性、结构化地体现了应用领域的规律和规则,反映了事实(前提)与结论、上位信息与下位信息的逻辑关系。如对某供电企业配网设备检修工程设计变更(签证)事项的真实性进行审计时,智能化审计软件会依据知识库中有关配网设备检修工程以及设计变更(签证)深/浅层知识,按以下步骤收集审查信息,固化相关证据:第一步,收集审查设计(签证)工程名称及变更卷册号、图号信息;第二步,收集审查设计(签证)事项内容、相关施工措施、纪要或协议信息;第三步,收集审查变更图纸、照片、示意图信息;第四步,收集审查变更工程量信息;第五步收集审查变更费用计算书信息;第六步,收集审查设计变更工程安全质量稽查信息;第七步,收集审查设计变更工程监理、中间(隐蔽)工程验收及工程竣工验收等信息。至于该工程设计变更后续的结算(决算)、财务转资等信息,由于属于上述流程中的下位信息,因而不得作为证明本事项的证据使用。
这种基于实质和形式化上/下位信息,通过智能化审计软件推理过程所确认的上/下位信息,属于审计主体认识上的上/下位信息,是形成审计证据的基础。
二、不同形态的上/下位信息及其含义递归关系分析
不同形态的上/下位信息之间既相互联系又互相区别。实质性的上/下位信息真实地反映了被审计单位经济活动实际,是审计证据取舍的依据;而形式上的上/下位信息则是审计主体实施审计搜索、识别的载体与对象;认识上的上/下位信息则是审计主体已经获取到、最终能够形成审计证据的相关信息,这类信息既可以证成审计事项,也可能因为与经济活动不符,导致审计失败。
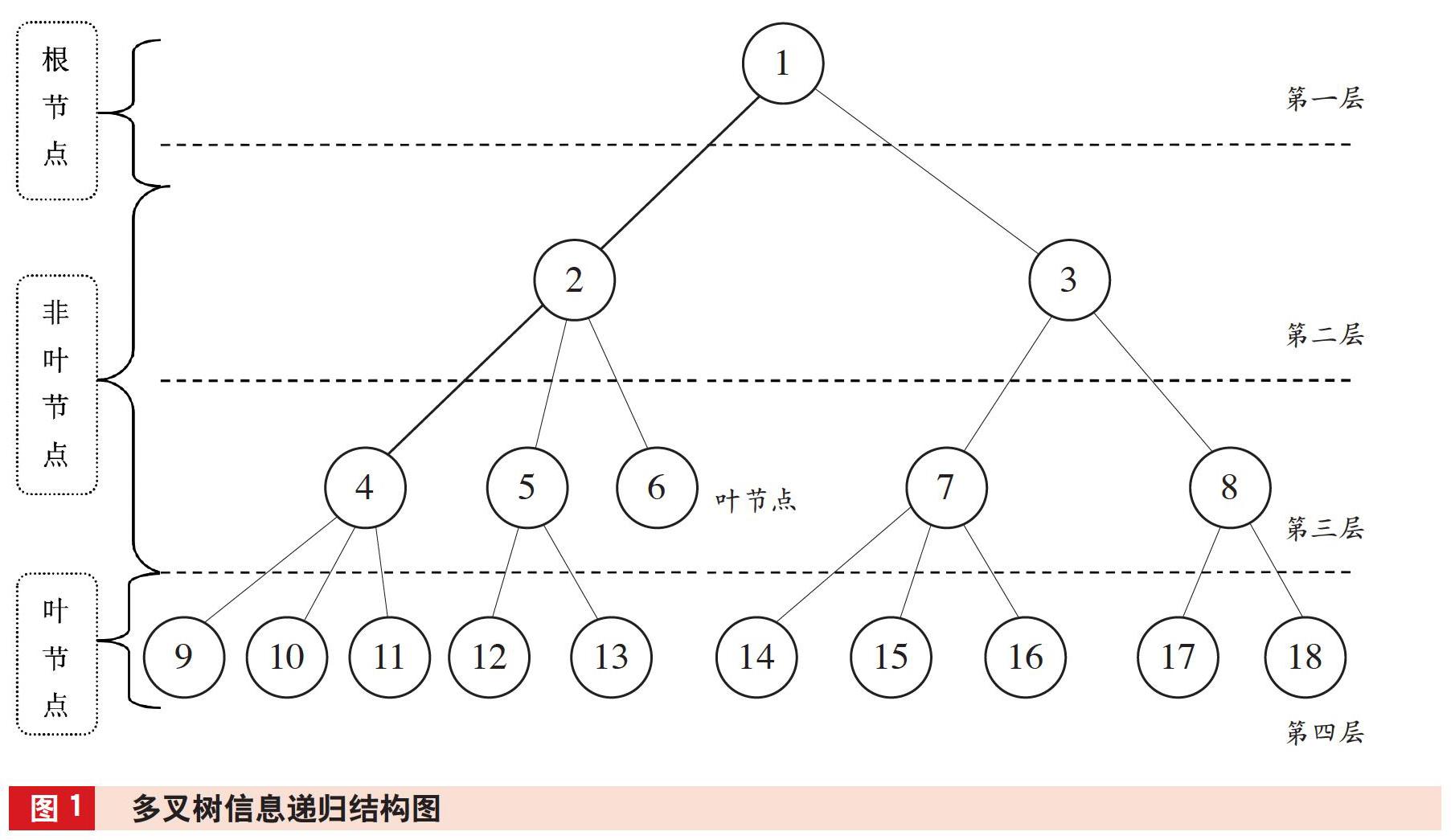
信息的形成是从底层向高层聚合的,具有类似树形的结构。从树形结构底层的叶子节点所代表的信息源开始也就是信息生产者如文件或者传感器采集设备生成的数据开始的上位信息,然后通过配准、汇集、关联和计算等信息加工,将底层数据或信息融合成更加抽象的高层信息表示,逐次完成既定融合目标任务,直至根节点,形成某一经济活动的信息集合,在融合的过程中形成自下而上的多叉树形结构,如图1所示。
多叉树信息递归结构图中,某一经济活动信息集合组成的信息网中,任一独立载体或载体中不同描述段所记载的记录信息或自有信息可视为该信息网中的节点,节点之间的连接弧表示节点对节点的直接影响。叶节点与根节点之间的层次距离为节点深度。结构图中含有的节点和弧越多,表明相应的经济活动信息越复杂。结构图中的信息节点主要由信息节点之间的上位/下位关系连接,这种关系体现了经济活动各信息节点之间信息内容的承继关系,表明信息是从上位节点逐层向下位节点加工融合传递的,上位信息是下位信息的具体呈现。同一事项的下位信息与所有的上位信息输出点,构成下位信息因果网。而因果网具有上位/下位关系的两个信息节点共享同一经济活动部分信息,且下位信息继承了同一经济活动的全部或部分上位信息。叶节点与根节点之间的深度越大即与根节点的层次距离越远,所蕴含的经济活动信息就越具体且数量也越大,而越接近根节点信息量则越少。
在结构图中,第四层9-18号叶节点(包括6号节点)均为上位节点信息又称初始信息,这些信息均由其他系统(互联网)提供或者本系统生成,在信息集合中最接近经济活动真相,是经济活动信息集合中信息量最大的节点。例如,通过传感器从被审计单位经济活动中采集并发送的各种实时数据;人们通過感觉器官感知后储存、记忆的自有信息或自在信息发生时第一时间转换为录音、录像、文字、数据等的记录信息。第二层、第三层中2、3、4、5、7、8号非叶节点为中间层次节点,相对于1号根节点,他们为上位节点,而与第四层9-18号叶节点相比较又换位为下位节点。
上位信息和下位信息的分界点是通过人机对话方式输入到智能审计软件中的审计命题或审计假设相对应的信息。在一组描述同一经济活动的信息集合中,上位信息是下位信息生成之前的信息,是形成下位信息的前提信息;而下位信息则是上位信息的后续信息,承续了上位信息的相关含义。之所以上位信息可以成为审计命题或假设的证据而下位信息不能作为证据使用,关键在于下位信息本身就是需要证明的事项,是未经核实(查实)的信息,如果使用未经核实(查实)的信息来推知上位信息,显然违背了人类认知科学和逻辑推理规律。例如,审查某项固定资产计提折旧有无差错时,某计提折旧业务序列中的下位信息为待证计提折旧的事实,而上位信息则是计提折旧的固定资产原值、折旧率等前端业务信息,折旧计提结果所影响的折旧、成本、费用明细账以及总分类账金额的变化则是下位信息。作为证明折旧计提事项真实性的审计证据,应该是引起折旧计提事项发生的原因——上位信息,而不是它的结果——下位信息。
三、审计取证定位及其方向性选择
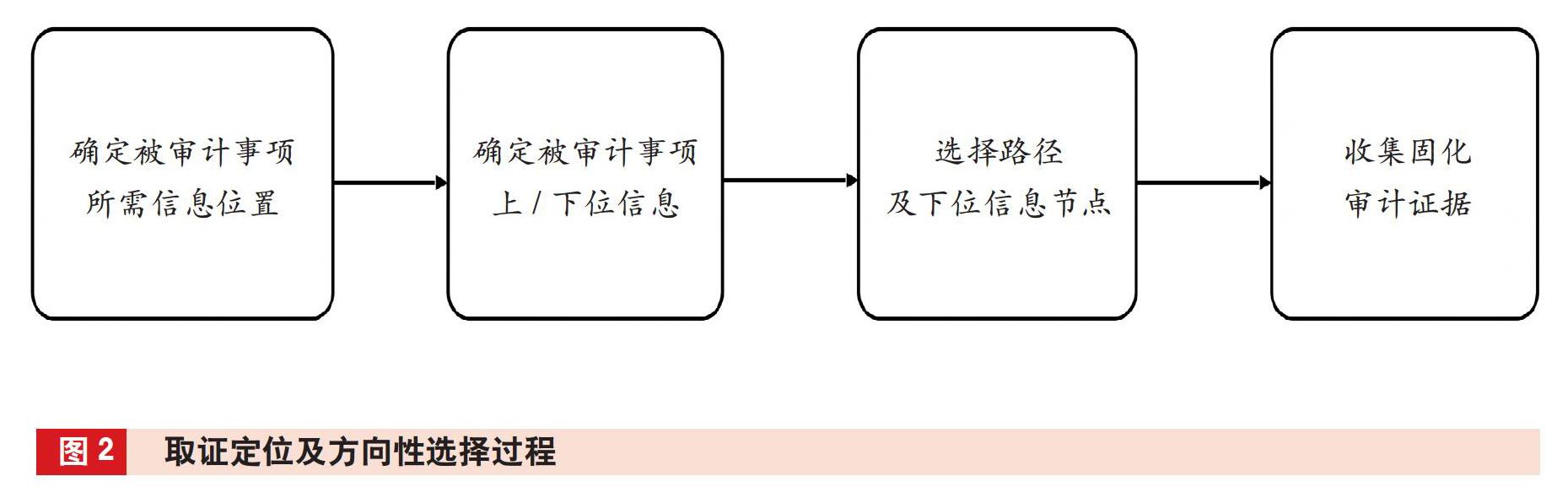
审计取证方向及其定位方法要点是:审计证据取证必须以确定的审计命题或者审计假设所需要收集的被审计事项信息为起点,从上(前)往下(后)或者由下(后)往上(前),通过对相关信息的正向或逆向溯源,收集上位信息,查清被审计事项真相的方法。审计取证定位及方向性选择过程如图2所示。
(一)确定被审计事项所需信息的位置特征
首先,以某一具体审计命题或审计假设定位切入点(观察点),再根据切入点(观察点)定义上/下位信息。具体做法就是在数据清洗、填充、修改、标准化、类型转化等预处理基础上,对照应用领域规则、业务流程或者范例库中所记载的相同经济活动相似情节、过程等特征,利用计算机检索算法来确定。这一位置特征与同一经济活动信息集中的对被审计事项起证明作用的信息相对应的字符位置相关,通常表现为上、下位两种位置:表示在被审计事项所需信息的上(前)边或者下(后)边。上/下边位置应根据经济活动自在信息的顺序而不是其记录信息或者自有信息所记载(记忆)的顺序来确定。其次,选择被审计事项信息的各种邻接节点字符特征,这样做是为了能细粒度地提取所在上/下位节点信息,它有多种选择方式,如上下两个字符或上/下一个或多个字符以及下一个或多个字符。信息细粒度应根据审计范围或审计目标甚至审计事项的重要程度灵活掌握。
(二)审计取证方向选择
被审计事项信息位置特征确定后,接下来就要选择审计取证方向。从信息定义考察,被审计事项上/下位信息都蕴含了信息,但下位信息只是被审计事项原有含义上的新增或重复信息,对于被审计事项来说是明确确定的,不存在未被消除的随机不确定性因素。因被审计事项的下位信息不能作为证明其真实性的证据使用,因而被审计事项的上位信息可独立或者相互印证地证明被审计事项的真实性。也就是说,被审计事项的上位信息,根据证明需要可以成为审计证据。在数据结构中与被审计事项无直接关联的其他节点信息,由于违背了审计证据的相关性规定,也不能成为证据。仍以图1为例,若节点4确定为被审计事项,那么叶节点9、10、11就可以用作节点4的证据节点,而与节点4相关联的上层节点2,则不是节点4的证据节点,除此之外,其他节点也不能收集、固化为节点4的证据。
(三)审计取证路径选择
被审计事项自在信息通过一定工具和技术转换为人们能够理解和认识的不同系统性质的自有信息或记录信息后,审计主体可以选择不同的信息获取渠道来查清相关经济活动,但取证路径必须遵循经济活动内在规律。例如,制造企业生产与存货活动发生领料、生产加工、销售产品等业务后,相应地也会产生产品生产、材料(产品)出入库、成本计算等信息,审计主体可以根据构成这些不同业务体系信息的时空次序,选择性地收集相关证据。
(四)审计取证方法选择
审计取证关键技术有关键词提取、主题提取、内容抓取等,这里仅从思路上介绍几种方法。
1.基于范例的推理方法。建立审计范例库,根据关键词索引,从审计范例库中检索出(联想到)与审计中面临问题最类似(相关)的范例,进行差别比较和解答改编,通过联想(或类比),将解决过去问题的经验包括解答和解决过程用于解决当前问题。
2.中文文本关键短语提取方法。基于统计的关键短语提取,如利用统计方法,用词频TF、词权重TF-IDF以及首位置信息作为统计特征,对候选短语进行评估,提出文本中关键短语;基于混合模型的关键短语抽取,即一种在隐马尔科夫模型和最大熵模型的基础上提出的一种无向图学习模型;利用决策树进行中文文本关键短语的自动抽取;改进的Seg Phrase算法等。
3.对完整或非完整数据库的查询方法。如PSKYline-join算法、SQL Server数据库T-SQL查询方法、基于Key/Value数据库的查询方法等。
(作者单位:国家电网有限公司 国网湖北省电力有限公司,邮政编码:430077,电子邮箱:xiejs19621xjs@sina.com)
主要参考文献
蔡圆媛.大数据环境下基于知识整合的语义计算技术与应用[M].北京:北京理工大学出版社, 2018
高济.人工智能高级技术导论[M].北京:高等教育出版社, 2009
谢亚妮,李响,黄兆坤,钟鸣,雷鸣涛.一种基于Key/Value数据库的查询方法[J].信息化研究, 2019(3)
