基于语义嵌入模型的Kafka平台发布订阅信息分类方法
2020-11-11陈福海韩小波
李 杨,陈福海,韩小波
(中国电子科技集团第二十八研究所,江苏 南京 210000)
0 引 言
互联网技术的广泛应用及移动计算和分布式计算的快速发展,使得统一管理和组织海量信息变得更加复杂[1]。从Kafka平台上获取需要的信息时,庞大的发布订阅消息数量使得人工选择和分类变得复杂[2]。当下常见的分类算法存在明显的问题,例如使用最近邻分类器时,如果分类的类别属于跨领域,那么识别难度较大且存在误差,需要通过人工定制相应的特征信息,但人工定制的信息存在先天性的不足,如特征较少等。
以语义嵌入模型为代表的神经网络算法能够较好地解决上述问题。通过语义嵌入模型能够大大较低人工获取特征的难度,在降低难度的同时还能够更加准确地获取特征。准确获取的特征可以广泛运用于人工智能等领域,且性能十分强大。因此,本文基于语义嵌入模型的良好性能,提出了一种基于语义嵌入模型的Kafka平台发布订阅信息分类方法,将发布订阅信息中的每一个词都映射成语义空间向量[3]。词向量表现了词上下文的基本特征,将该词向量输入到长短时记忆网络中[4],会输出一个向量来代表该信息特征。每一个发布订阅的信息不仅含有其自身属性信息,而且含有与其他信息的关联信息[5],包含订阅发布信息的逻辑等。通过组合信息语义向量与关联信息,基于语义嵌入模型的Kafka平台能够自动生成信息归类类别。基于此,阐述研究背景和研究现状,给出基于语义嵌入模型Kafka平台发布订阅信息分类方法的实现过程,生成代码语义向量并进行实验对比分析。实验结果表明,采用该改进方法可有效提高信息分类精度。
1 基于语义嵌入模型的Kafka平台发布订阅信息分类方法
1.1 发布订阅信息分类方法整体方案
为使Kafka平台中发布和订阅信息能够实现更好的分类效果,设计了整个Kafka平台框架。为了解决特征的问题,将Kafka平台中发布和订阅信息中的每一个词都映射成一个语义空间向量,在获取单个信息的同时还需获取全面且完整的信息。此外,使用长短时记忆网络可将获取到的完整信息以一个全局信息向量的形式输出。
经过以上步骤后,发布和订阅信息被转换成了一个语义空间向量V。信息相关的搜索蕴含了信息的分类、发布和订阅信息的分类过程,可以反映信息的内部逻辑。通过分析发布订阅信息的关联,可提取关联信息特征向量T={t1,t2,…,tn}。
结合关联信息特征向量T和语义空间向量V的信息,将两个组合连接成一个向量输入到前馈神经网络(Feedforward Neural Network,FNN)(为获取非线性特征关系设置一层隐藏层),由Softmax层输出每个类标签{C1,C2,…,Cn}的概率,且所有的概率相加为1。文中取概率最大的类标签作为发布订阅信息的标签[6]。
1.2 算法过程
信息的源代码中包含着变量名等信息。得到发布订阅信息的源码后,由于发布订阅信息之间可以互相调用,且一个信息的功能需要另一个信息的配合才能完成,因此有调用关系的信息在功能上存在一定的联系。在预处理过程中,如果一个信息调用了一个信息函数,那么需将被调用的函数扩充到调用函数的对应位置。
1.3 代码语义向量生成
通过长短时记忆模型(Long-Short Term Memory,LSTM)可生成源代码的代码语义向量。LSTM可实现向量到向量的映射,灵活控制输出向量的大小,因此本文选择用LSTM生成发布订阅信息的语义向量。
每一套代码都可以将其看成一个词的序列{w1,w2,…,wn}。在词嵌入层中将每一个词wi映射成一个300维的稠密词嵌入向量[7]。生成词嵌入向量后,将其输入到LSTM。初始阶段,每一个新的词嵌入向量都要被输入到LSTM中,通过LSTM输出一个向量,这个向量位于语义空间向量中,最终可得出结论:信息相关性较高的句子的向量在该语义空间向量中的距离较近,且可以归为一类信息;信息相关性较低的句子的向量在语义空间向量中的距离较远,代表的不是同一类信息。
LSTM[8]可扩展自循环神经网络(Recurrent neural network,RNN)。设当前的输入为xt,上一步的输出为ht-1,则可利用循环神经网络计算下一个输出ht为:

其中,W与Wr是模型的参数,b是偏差,lt是隐含状态。
LSTM主要通过输入门、遗忘门以及输出门3种类型门来解决时序问题[9]。在输入较长时,LSTM能够比RNN更好地获取到输入的依赖关系[10]。设置LSTM记忆状态为ct、输入状态为it、之前的状态ft,给定一个输入xt、上一个输出ht-1、上一状态ct-1,输出ht计算过程为:
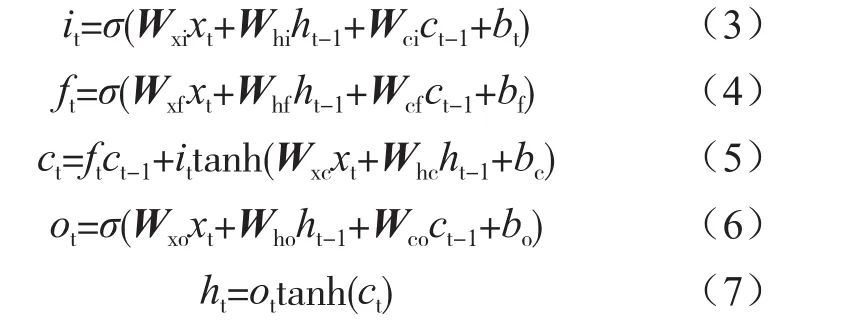
式(3)~式(7)中,矩阵W和偏差bi、bf、bc、bo是要学习的参数,σ是Sigmoid函数[2]。输入最后一个词后,最终的输出结果代表源代码的语义向量。这个向量可以获取源码的上下文语义信息,并进行下一步处理。得到发布订阅信息源代码的向量表示后,再将向量表示与发布订阅信息结合起来输入到前馈神经网络中,得到的输出结果为发布订阅源码可能的类标签及其对应概率。
2 实验结果与分析
2.1 实验设定
通过分析Kafka平台的相关应用,本文将发布订阅的主要用途分为经济相关类、家居娱乐类和其他类。本文所有试验均由一台Intel Xeon E5八核的电脑完成,CPU主频为3.7 GHz,内存为8 GB,程序使用Jave JDK 1.8编写完成。由于Kafka平台数据集规模在单机可处理,因此本文算法无需使用集群训练与验证,可以方便地移植。
2.2 有效性分析
采用语义嵌入算法模型的目的是高效地将发布订阅信息源码分类。为了验证它的效果,将该模型的效果与其他两种常见算法进行对比。
2.2.1 朴素贝叶斯算法模型(NBC)
为与语义嵌入模型进行对比,先用词袋模型将源码转换为相应向量,然后将发布订阅信息作为朴素贝叶斯的输入。朴素贝叶斯能够计算出每一个类别的概率,取概率最大的信息与发布订阅信息的预测进行对比。
2.2.2 支持向量机算法模型(SVM)
该模型主要用于分类问题,主要的应用场景包括字符识别、面部识别、行人检测以及文本分类等。通常使用SVM将多元分类问题分解为多个二元分类问题后再继续进行分类。为了能让SVM进行多种类型的分类,可在分类时采用one vs all算法。
本文利用precision、recall、accuracy以及flscore共4个评估指标来评估语义嵌入模型模型、朴素贝叶斯模型及支持向量机模型[2]。发布信息和订阅信息在3种不同算法模型的不同场景下(如经济相关类和家居娱乐类等)的评估结果分别如表1~表3所示。通过对比3种算法模型的结果,证实了语义嵌入算法模型的效果较好。

表1 语义嵌入算法模型评估结果

表2 朴素贝叶斯算法模型评估结果

表3 支持向量机算法模型评估结果
3 结 论
通过深入了解Kafka平台上的发布订阅信息,结合语义嵌入模型,提出了一种基于语义嵌入模型的Kafka平台发布订阅信息分类方法。通过用词嵌入模型对发布订阅信息代码的语义信息建模,能够更深入地理解发布订阅信息的逻辑行为。经实验证实,基于语义嵌入模型的Kafka平台发布订阅信息分类方法应用性能优良,可更好地对Kafka平台发布的订阅信息进行分类和搜索。
