基于秘密分享和梯度选择的高效安全联邦学习
2020-11-11陈小军
董 业 侯 炜 陈小军 曾 帅
1(中国科学院信息工程研究所 北京 100195) 2(中国科学院大学网络空间安全学院 北京 101408)
在互联网、大数据和机器学习的推动下,人工智能技术飞速发展,语音识别、图像处理等应用逐步改变着人类的生产、生活方式.然而,在这些应用背后,大规模的用户敏感数据,如医疗数据、生理特征、社交网络等,被各类企业、机构随意收集.这些数据的收集能够带动机器学习性能的提升,实现经济效益和公众效益的双赢,但却使得个人隐私和数据安全面临更大的风险.与此同时,个人隐私和数据安全愈发受到国内外的重视关注.2017年6月施行的《中华人民共和国网络安全法》(1)http://www.cac.gov.cn/2016-11/07/c_1119867116.htm、2018年3月欧盟宣布的欧盟通用数据保护条例(General Data Protection Regulation, GDPR)(2)https://gdpr-info.eu/都对企业处理用户数据提出了明确要求.可见,企业在用户不知情时进行数据收集、共享和分析已经被视为一种违法行为.因此,如何在保证用户个人隐私和数据安全的情况下,充分发挥机器学习等人工智能方法的潜力是一项意义深远而又亟待解决的问题.
联邦学习(federated learning)[1-3]作为一种新兴的分布式隐私保护机器学习训练框架得到越来越多的重视.在联邦学习中,分布式用户在本地根据自己的私有数据训练机器学习模型,然后借助参数服务器仅共享训练得到的梯度来提升模型的性能.联邦学习避免了用户将自己的数据暴露给企业或者其他参与方,从而在一定程度上保护了自己的隐私和数据安全.但是,联邦学习还处在发展初期,现有的方案还存在较多的不足:1)直接分享梯度的方式面临许多的隐私威胁,敌手可以针对用户的梯度推测出用户数据中的敏感信息,甚至可以逆向推演得到用户的私有数据;2)简单地将隐私保护技术,例如安全多方计算(secure multi-party computation, MPC)、同态加密(homomorphic encryption, HE)等,应用到联邦学习中可能带来巨大的、甚至无法接受的额外开销.
为了解决现有联邦学习方案的问题和不足,本文基于梯度选择和安全多方计算中的秘密分享技术,设计了高效的安全联邦学习方案,在保护用户隐私的前提下大大减小了通信开销.进一步,我们还提出了一种验证方案用来防止服务器的恶意篡改.
本文的贡献主要包括3个方面:
1) 结合梯度选择和秘密分享,提出了一种高效的安全联邦学习方案.和现有的工作相比,我们在保证准确性的前提下,将通信开销减少到了原来的1%~10%.
2) 基于梯度的索引和值的数量积,我们设计了一种验证梯度聚合结果有效性的方案.在合理的安全性假设下,我们的验证方案可以抵抗服务器的恶意篡改.
3) 我们在真实的数据集上验证了方案通信的效率提升和模型的准确性.实验结果表明本文提出的机制实现了隐私保护、通信开销和模型性能三者之间的有效平衡.
1 相关工作
本节主要介绍有关梯度选择算法和联邦学习隐私保护的方案.
1.1 Top-K梯度选择算法
Top-K梯度选择算法在减小联邦学习通信开销方面发挥着重要作用,在学术界和工业界都受到了广泛的关注和重视.Strom[4]首先提出在训练过程中,客户端可以只上传绝对值大于某个阈值的梯度.之后,Aji等人[5]提出了梯度丢弃算法.与Strom的方案不同的是,梯度丢弃算法不再依赖一个固定的阈值来选择梯度,而是将梯度按照绝对值的大小排序,然后按照从大到小的原则选择固定比例的梯度上传.进一步,Wang等人[6]从梯度的稀疏性和方差2个方面综合考量来选择梯度.最近,Alistarh等人[7]第一次在理论上给出了针对Top-K梯度选择算法的收敛性分析.然而,尽管Top-K梯度选择算法上传的只是稀疏的部分梯度值,暴露这些梯度的真实值仍然会威胁到用户的隐私安全.
1.2 联邦学习隐私保护
如引言所述,直接暴露梯度的真实值可能使得各参与方本地的数据被敌手逆向推理,从而造成隐私泄露.针对上述威胁,目前的方案主要从2方面考虑:1)差分隐私;2)密码学技术.
利用差分隐私,可以在本地模型训练及全局模型整个过程中对相关参数进行扰动,从而令敌手无法获取真实模型参数[8-9].但是,与密码学技术相比,差分隐私无法保证参数传递过程中的机密性,从而增加了模型遭受隐私攻击的可能性.例如刘俊旭等人[10]针对联邦学习下差分隐私中存在的攻击方法进行了详细的调研.
目前在隐私保护联邦学习中常用的密码学技术包括安全多方计算、同态加密等.研究者们利用这些技术旨在实现联邦学习中的核心问题——安全聚合(secure aggregation).目前的方案[11-13]在不同的方面都取得了长足的进步,但是也存在一些问题亟待解决.例如文献[12-13]基于秘密分享构造了安全聚合协议,旨在保证用户梯度隐私的情况下高效地聚合梯度.其计算性能良好,但是其通信开销远远大于在明文方案和利用差分隐私的方案,这大大限制了其应用.

Fig. 1 The system architecture of federated learning图1 联邦学习系统结构
1.3 秘密分享
秘密分享技术是安全多方计算领域的一种常用的技术.秘密分享最早由Shamir和Blakley分别在文献[14]和文献[15]中提出,并广泛用于密钥管理、门限加密等方面.其后,针对秘密分享和恢复过程中正确性的问题,Feldman[16]构造了可验证秘密分享方案(Feldman VSS),从而防止秘密分享者和参与者作弊;进一步,为了克服Feldman VSS安全性对于秘密先验分布的依赖,Pedersen[17]将Pedersen承诺和秘密分享方案结合,构造了Pedersen可验证秘密分享方案(Pedersen VSS).
另一方面,加法秘密分享技术由于其高效性也受到大量研究者的关注,并被用于许多重要的安全两方(多方)计算方案,例如Sharemind[18],SPDZ[19]等.本文出于对安全和性能的综合考虑,将采用加法秘密分享构造安全方案.
2 理论基础
本节主要介绍联邦学习、Top-K梯度选择算法、秘密分享技术和消息验证码.
2.1 联邦学习
在联邦学习中,用户Ci持有本地私密数据集Di,所有的用户共享同一个模型架构θ.每个用户都和参数服务器S建立安全信道.用户的数目记作m.
训练阶段如图1所示,形式化描述如下:
1) 用户Ci基于本地私密数据集训练模型θ,计算得到梯度向量gi:
gi=Train(θ,Di).
(1)
2) 用户Ci将gi上传到服务器S.
3) 服务器S聚合所有用户上传的梯度向量.在本文中采用加法聚合:
(2)
4) 服务器S将聚合结果gS返回给所有用户,用户计算均值,更新本地模型:
(3)
其中,α是学习率.
一轮更新完成之后,用户检测本地模型的准确率是否达到要求.如果满足要求则停止训练;否则,准备进行下一轮的训练.
2.2 Top-K梯度选择
在2.1节中,我们介绍了联邦学习的基础训练框架.在基础框架中,用户每次需要上传所有的梯度.对于大型的网络来说,上传、下载梯度所需要的通信开销可能成为系统的瓶颈.因此,梯度选择成为一个改善通信性能的有效方法.在本文中,我们参考Aji等人[5]提出的梯度选择方案来选择上传的K个梯度值.
具体来说,每次训练中用户C计算得到梯度向量g后,首先将求g中每个元素g[j]的绝对值.然后根据绝对值的大小将所有g[j]排序.排序之后,我们需要选择出绝对值最大的K个梯度值.然后将这K个梯度值上传到服务器S.图2给出了梯度选择的具体描述.算法细节如算法1所示.
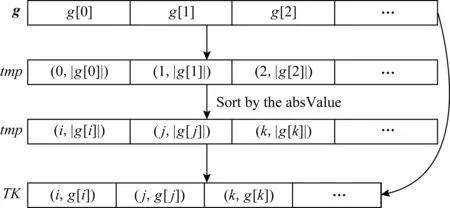
Fig. 2 Top-K gradients selection algorithm图2 Top-K 梯度选择算法
算法1.Top-K梯度选择算法.
输入:梯度向量g,K;
输出:Top-K梯度值和对应的索引信息.
①tmp=[],TK=[];*tmp存储梯度绝对值和索引信息,TK存储最终选择的梯度*
② forg[j] ing
③tmp.append({j,abs(g[j])});*tmp中的每个元素包含索引ind和梯度绝对值abs*
④ end for
⑤ Sorttmpbytmp.absValue;
⑦TK.append({tmp[d].ind,g[tmp[d].
ind]});*TK中每个元素包含索引
ind和梯度值*
⑧ end for
在算法1的行②~④,用户将每个梯度值的索引和绝对值作为一个整体存储到tmp中.行⑤,用户基于梯度绝对值的大小将tmp中所有元素降序排序.行⑥~⑧,用户依据tmp中排序之后的索引信息选择绝对值最大的K个梯度值,并将相应的索引信息作为一个整体存入TK.最后,用户得到TK,其中包含了绝对值最大的K个梯度值和对应的索引信息.
与上传所有梯度的方案相比,本文采用的方法大大减小了训练过程的通信开销;和基于梯度阈值的梯度选择方案[4]相比,本文采用的方法能将通信开销限制在固定的范围.
2.3 秘密分享
秘密分享将秘密x分成n个份额{x1,x2,…,xn},然后将xi安全地保存在第i个秘密持有者Pi.所有的份额满足任意少于t个份额无法揭示任何关于秘密x的信息,而任何不少于t个份额可以恢复原来的秘密x,其中t≤n.出于对系统整体性能的考虑,在本文中我们采用高效的加法秘密分享[20],其中t=n.
定义1.加法秘密分享包含分享算法Sharing、恢复算法Reconst、分享的份额数目n.
互联网与通信技术的发展打破了传统学习的时空约束,改变了学生的学习行为,使学习更具有灵活性和主动性,网络学习的即时性也最大限度的帮助成人学生克服工学矛盾, 但网络学习改变成人学习行为的同时也产生了一些消极的影响。在未来成人教育体系中,学生不仅仅是传统课堂学习的“补充型”学习,而且是终身学习的践行者,而网络学习给成人学生的终身学习提供了条件。成人教育的研究者和工作者,应更客观地看待互联网在网络学习中的作用和学生具体学习行为的嬗变,努力扬长避短,使成人学生在网络学习中朝着更有益的方向发展。
Sharing:将秘密x、份额数目n作为输入,输出n个关于秘密x的份额如下:
1) 随机选取n-1个随机数
(4)
作为n-1个秘密份额.
2) 计算第n个秘密份额:
(5)
Reconst:输入n个秘密份额{x1,x2,…,xn},恢复秘密x:
(6)
从而,任意的少于n个份额不能泄露秘密x的任何私密信息.而任意获得n份秘密份额的用户便可以根据式(6)恢复秘密.
除此之外,秘密分享方案还具有加同态性质.
定理1.给定秘密x和y的秘密分享份额,份额持有者Pi可以在秘密分享的状态下计算得到秘密x+y的分享份额.
证明. 根据定义1,对x进行加法秘密分享,得到:
{x1,x2,…,xn}←Sharing(x,n).
(7)
同理,对y的秘密分享,有:
{y1,y2,…,yn}←Sharing(y,n).
(8)
对于∀i∈{1,2,…,n},Pi可以在本地计算:
zi=xi+yi(mod 2l).
(9)
同时,根据式(6),有:
(10)
故{z1,z2,…,zn}是x+y的加法秘密分享份额.Pi可以根据式(9)计算x+y的秘密分享份额.
证毕.
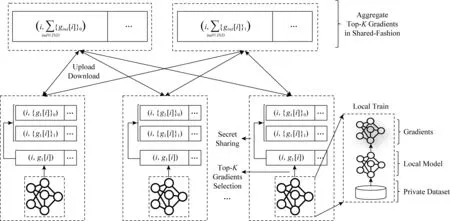
Fig. 3 The illustration of protocol 图3 协议流程图
2.4 消息验证码
消息验证码(message authentication code,MAC)是一种确认消息完整性并认证的技术[21],是一种与密钥相关联的单向Hash函数.消息验证码的形式化定义如下.
定义2.一个完成的消息验证码方案由三元组(G,Sign,Verify)构成.其中,G是密钥生成算法,给定安全参数κ,生成密钥sk←G(1κ);Sign是认证算法,给定密钥sk和消息x生成验证码MAC=Sign(sk,x);Verify是验证算法,给定验证码MAC、密钥sk和消息x,判断Verify(sk,x,MAC)=Accept是否成立;并且算法Sign和Verify需要满足:
(11)
常见的消息验证码基于分组密码和Hash函数构造方案,例如HMAC[22].
本文中,我们将消息验证码的思想和梯度选择的索引信息结合,设计了具有加同态性质的验证码,从而验证聚合结果的有效性.
3 方案设计
我们引入了n个(n≥2)服务器对用户的梯度进行安全聚合.用户的数目m≥3.
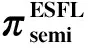
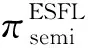
首先,用户按照式(1)训练模型θ得到梯度向量g.然后,用户调用Top-K梯度选择算法选出绝对值最大的K个梯度.进一步,用户调用加法秘密分享的Sharing算法分享选择出的梯度值.然后将分享份额上传服务器.需要注意的是,梯度的索引信息也需要上传.
另一方面,服务器在收到用户上传的梯度分享份额之后,根据索引信息将对应的份额按式(9)聚合,得到聚合结果gS的秘密分享.然后将gS的秘密分享和所有用户上传的索引信息的并集IND返回给用户.
最终,用户调用秘密恢复算法Reconst恢复聚合结果gS.并且,根据索引信息更新本地模型.
协议的形式化描述如算法2所示.
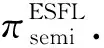
输入:用户私密数据集Di、统一的初始化模型θ;
输出:训练得到的模型θ.
① 每个用户和每个服务器之间建立安全信道;
③ 用户在本地训练模型,计算梯度;
④ 用户调用Top-K梯度选择算法,选择出Top-K的梯度元素;
⑤ 用户针对Top-K梯度元素调用秘密分享,得到梯度分享份额;
⑥ 用户将索引信息和梯度分享上传到对应的服务器;
⑦ 服务器依照索引信息,根据秘密分享的加同态性质聚合梯度分享;
⑧ 用户下载服务器的聚合梯度分享份额,并调用秘密恢复算法恢复聚合梯度;
⑨ 用户更新本地模型;
⑩ 进行下一轮训练跳转③,或者停止训练.
证明. 首先考虑敌手腐化了n-1个服务器.在这种条件下,敌手能够获得n-1个梯度秘密分享份额.但根据加法秘密分享的性质,任意不超过n-1个秘密份额无法泄露任何关于秘密真实值的私密信息.因此,在这种条件下,敌手不能获得关于梯度真实值的任何私密信息.
其次,我们考虑在敌手腐化m-2个用户的情况.在这种情况下,敌手可以得到聚合结果的真实值.除此之外,敌手还可以得到所有腐化用户的梯度真实值.因此,敌手能够按式(12)获得所有诚实用户梯度值之和:
(12)
其中,honest为诚实用户的集合,corrupted为被腐化用户的集合.
基于至少有2个诚实用户的假设,敌手在这种情况下也无法获得针对某个用户的梯度真实值.
证毕.
3.2 协议
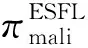
假设敌手腐化服务器S1.记S1按照式(9)聚合完成的结果为gS,1.敌手生成任意的噪声向量r.之后,敌手便可以计算:
(13)
最终用户端恢复聚合结果,得到:
gS+r(mod 2l).
(14)
从而使得最终聚合结果受到噪声r的干扰,模型的训练过程和性能受到影响.
为了抵抗上述类型的攻击,我们利用梯度的索引和梯度值构造了验证码MAC.以此检测服务器是否对聚合结果进行恶意修改,从而抵抗恶意敌手的攻击.
TK=[{ind,g[ind]}k].
(15)
进一步,利用索引信息ind和梯度的真实值g[ind]计算验证码MAC:
(16)
然后,用户上传MAC到所有的服务器.服务器在收到所有用户上传的MAC之后,将对所有MAC求和得到MACS:
(17)
聚合完成之后,服务器将聚合结果的秘密份额和其对应的索引信息INDS,以及MACS返回给用户.用户在本地计算恢复聚合梯度真实值gS,并进行验证:
1) 所有的MACS都相等;
2) 用户计算:
(18)
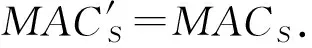
如果上述1)2)都验证通过,那么用户则接受gS并更新模型;否则,则广播错误并终止协议.具体协议如算法3.
输入:用户私密数据集Di、统一的初始化模型θ;
输出:训练得到的模型θ.
⑥ 用户按式(16)计算MAC;
⑦ 服务器聚合梯度,并按式(17)对MAC求和得到MACS;
⑨ 用户验证所有的MACS相等,并按式(18)验证聚合结果的有效性;
⑩ 如果所有的验证通过,用户更新本地模型;否则广播错误并终止训练;
首先,我们分析验证过程的正确性.
1) 如果服务器没有进行任何的恶意修改,由于所有的服务器收到的MAC都是相同的,所以按照式(16)计算得到的MACS都相等.
2) 为了简单起见,我们首先考虑2个用户的情况(此处暂时不考虑隐私保护).2个用户记作C1,C2,记C1,C2选择梯度向量为g1和g2,对应的索引集合为IND1和IND2.根据协议,我们有INDS=IND1∪IND2.
因此,对于∀ind∈INDS,有3种情况:
(19)
进而,式(18)可以分解为
MAC1+MAC2(mod 2l).
(20)
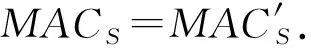
上述推理很容易可以推广到多个用户的情形.
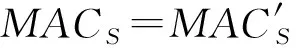
4 实验与结果
本文在手写体数字识别数据集MNIST(3)http://yann.lecun.com/exdb/mnist/上的卷积神经网络(CNN)进行实验. 数据集MNIST由4部分——Training Set Images,Training Set Labels, Test Set Images和Test Set Labels组成.各部分如表1所示.
我们在Intel Xeon E5-2650 CPU with 2.30 GHz 126 GB RAM服务器上、在局域网内模拟2个参数服务器和10用户端.我们采用Pytorch作为底层的机器学习训练库,并基于Python3实现我们的秘密分享方案和Top-K梯度选择算法.在实验中我们迭代训练100次,每次训练迭代中用户端需要和服务器交互计算1次完成梯度的安全聚合.

Table1 An Overview of MNIST
卷积神经网络的结构如图4所示:

Fig. 4 The architecture of CNN图4 卷积神经网络结构
我们分别从模型的准确率、训练的通信开销和时间开销3方面分析我们的方案.
4.1 模型准确率
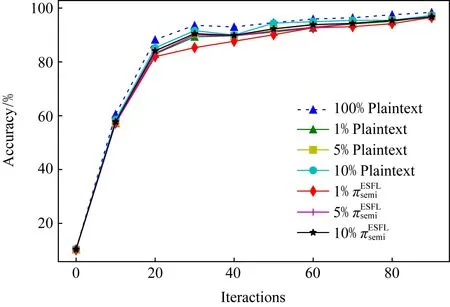
Fig. 5 The accuracy changes图5 准确率变化
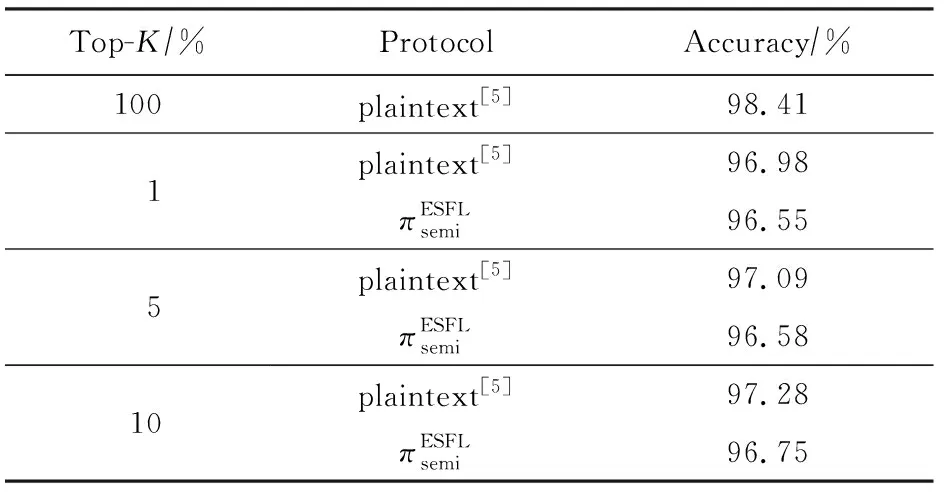
Table 2 The Accuracy Results
进一步,我们还探索不同的梯度选择比率对于模型训练的影响.在图5中,我们选择1%,5%和10%的梯度分享上传,并和明文下100%上传的方式比较.从图5和表2中可以看到,增加上传分享的梯度对于准确率的提升和收敛速度的提升并不显著.这与之前有关Top-K梯度选择工作的结论相符.
4.2 通信开销
通信开销是联邦学习的瓶颈之一,在安全的联邦学习中,由于在密文状态下无法使用压缩算法等优化技术,这个问题更为严重.为了提升通信性能,我们在Top-K梯度选择的基础上,结合秘密分享提出了高效的解决方案.

Table 3 Communication Overhead in One Training Iteration
实验结果表明,我们采用Top-K梯度选择算法,可以极大地优化在安全联邦学习中的通信开销问题.例如,我们将Top-K比率从10%优化到1%,通信性能优化了大约9.78倍.而4.1节的实验结果表明在这个范围内减少Top-K的选择比率并不会对模型性能造成很大的影响,因此Top-K梯度选择在安全联邦学习领域也具有很大的发展潜力.
4.3 时间开销

我们分别在Top-K梯度选择比率为1%,5%和10%下进行实验,并且与明文实验对比.结果如表4所示.
表4的实验结果表明:和明文训练对比,我们的安全协议在在线训练并没有引入太多的时间开销.用户端的计算时间和服务器的计算时间和明文训练对比,增加幅度很小,这种增幅在实际应用中是可以接受的.而在预处理阶段,通过1%,5%和10%的梯度选择比率对比,可以验证预处理的时间和需要的随机数的数量呈正相关.
另一方面,我们也可以观察到主要的开销来自于传输梯度的时间开销.例如,1%和10%的梯度选择比率对比,后者需要的传输时间大约是前者的10倍.这也是目前安全联邦学习面临的主要性能瓶颈之一.
5 总 结
联邦学习中的通信开销是其重要的瓶颈之一,而这个问题在安全联邦学习中带来的影响更为严重.本文将Top-K梯度选择和秘密分享的方法结合起来,在保证用户隐私和数据安全的情况下大幅提升了通信效率.进一步,我们利用索引信息构造了验证码,在保护隐私的基础上验证了服务端聚合结果的有效性,而且验证码所带来的额外通信负载是常数级别并独立于梯度的数量.这对于进一步的相关研究具有重要的参考意义.目前,也有许多工作通过对梯度量化编码的方式来提升通信性能,我们将在未来的工作中结合相关领域的方案进行下一步的探索.
