基于数据流计算图的卷积神经网络的理论和设计
2020-11-10谢仁杰
谢仁杰


摘要:近年来在许多信号处理应用领域中,深度卷积神经网络引起了学术界和工业界很大的关注,其中基于数据流图的深度学习网络Tensorflow框架得到了很多人的青睐。但在一些商业落地的研究和调查中发现,部分机构涉及一些自开发的计算单元,而它不被大型网络框架所支持,又出于技术的保密性往往需要自行修改工业界的深度学习框架,这就造成了以下情况,①工业级大型代码框架极其复杂,各大库之间的调用很深且一般没有注释,不容易读懂和修改,②对某一个单一应用来说,工业界绝大多数的代码都是有冗余的,这就使得代码整体比较臃肿(厚),性能会受点影响。基于这种受限的情况下,本文提出了一种基于信号处理数据流计算图模型的方法,在多个平台多核下实现车辆分类。该方法在整个使用过程中,展现了灵活地设计实现优化转换能力,多平台的兼容可实施性,可在有限的资源内根据自己的算法需求,分立式地量身定制。在硬件电路加速或芯片的设计中,数据流所得到的高输出率、低延时特点是各厂家在写RTL硬件设计语言时着重提出的特点,其次基于数据流的软硬件设计易于算法代码之间的转换、实现、移植、调试、分析、综合、集成、优化和验证。
关键词:深度学习;数据流;计算图;多核运算;车辆分类
0引言
随着国家进入人工智能时代,深度学习在嵌入式和计算机应用领域无处不在,例如汽车嵌入式系统和物联网,从而激发了在资源受限的边缘端做深度卷积神经网络的设计方法和研究。本文中以车辆分类作为具体研究案例,设计一种基于信号处理的数据流计算图的模型框架和实现优化方法,迭代式的实现,实验及优化,并在不同的平台及有限的计算资源下实现针对四种相近车辆的分类。本文以数据流计算图原理出发,介绍不同数据流技术建模的原理和形式,后举一个从零开始基于车辆分类的例子,从训练某个应用的网络,选取网络参数和神经元权重开始,进行Matlab的仿真代码实现,并以此为参考代码进行基于数据流计算图c代码实现,随后对整个计算图进行深度优化,最后单核和多核在不同平台下的性能进行了——对比。数据流计算图的简洁,跨平台,可扩展的完全自主的特性,可用于任何特定领域,特别适合量身定制的的嵌入图像和视频信号的操作。
1数据流模型(DatafIow Modemg)
1.1数据流模型原理
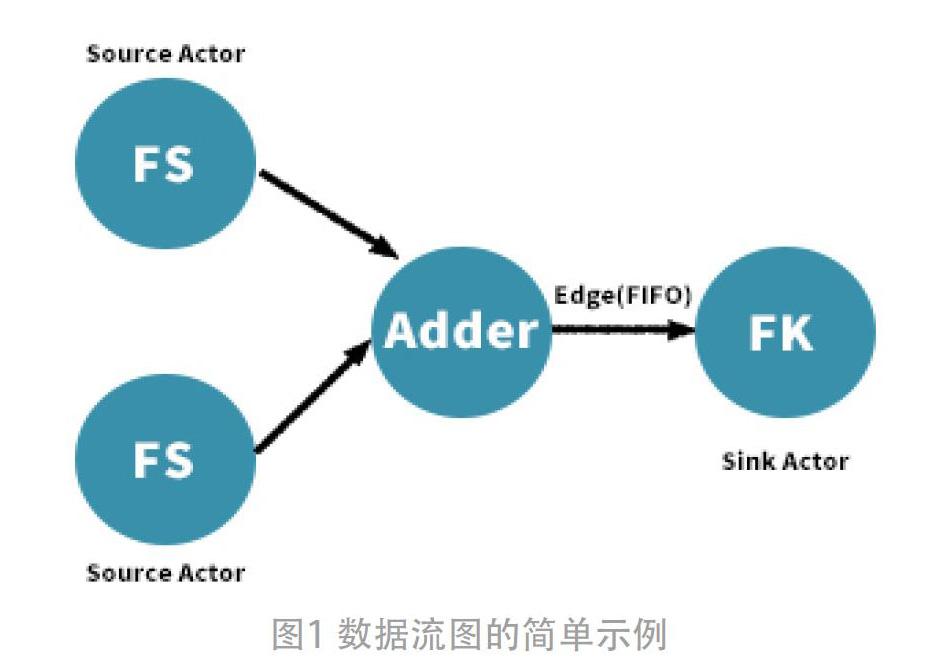
在数据流建模模型中,数据流图可表示为有向图,由一系列Actors(顶点)和edges(前进先出,FIFO)组成,其中actor表示任意复杂程度的计算单元(可以是高节点的actor封装了一些计算图),edge表示连接各actors的连线,从而构成一组计算图,代表一个函数功能系统,数据类型则封装在token,在一个actor通过edge输出至另一个actor输入端。数据流边缘可以表示e=(vl;v2),表示数据从v1至0v2。这里src(e)表示的v1称为源actor,sink(e)表示的1,2称为接收器。在一个数据流计算图中,一个actor在其接受的数据足以计算该单元actor的算法时可以启动和调用该actor通过其enable和invoke函数,每个actor需要明确定义其输入口消耗和输出口产生的token的数量。整個数据流计算图运行是一个离散的操作。在图1中,Actor:FS 1,FS2是2个源的参与者;Actor:Adder是加法操作:Actor:FK是接收器。整个图表产生每个actor触发(消耗)一个token到每个actor输出(输入)端口上。
1.2数据流模型概述
Core Functional Dataflow(CFDF)是一种可编程的模型,常用于设计、分析及实现信号处理系统,尤其是一种确定消耗产出比和有着动态数据流比例的的信号处理单元的系统开发;Synchronous Dataflow(SDF)是最简单最流行的数据流模型,它有个限制,即一个actor在每个传出边缘上产生的数据值是个数字常量,同时actor从进入边缘消耗的数据值的数量也需要是常量;Cyclo-StOic Dataflow(cSDF)是一种类型的SDF,在一个actor产生和消耗的token比是可变的,只要这个变值是一个固定的周期性的模式;Parameterized Dataflow(PDF)是一种结合动态参数与运行参数化的数据流计算图,尤其是那些有很明确的图迭代概念的图形;Boolean Dataflow(BDF)是SDF的扩展,其中一个actor产生和消耗的吞吐率取决于控制的二值函数token,它源自于动态数据流actor中的一个指定控制端口;Enable-Invoke Dataflow(EIDF)是另一种动态数据流建模技术。它将actors分成一系列模式,每个模式都有一个固定的消耗和生成的token的数量,代表一个分支可以在运行时切换多种模式。
1.3数据流模型环境:Ligh tW eight Data flow
Environm ent-C(LID E-C)
LIDE-C(轻量级数据流环境c)是一个灵活设计的c语言的编程环境,允许设计人员挖掘基于数据流的技术信号处理系统的设计实现和优化,专注于基本的应用程序编程接口(API)功能。在整个框架提供广泛的实现信号处理系统功能的组件,以及跨平台操作,包括可编程门阵列(FPGA),图形处理单元(GPU),可编程数字信号处理器(DSP)和服务器工作站。LIDE-C软件包拥有许多数据流图元素(actor和edge)实现库,基于这些基本要素可以自由设计自己的数据流图并定义元素,开发特定的应用程序(例如,控制,参数化和仪器相关的模块),和触发整个数据流图的调度程序,详解可参考文章。在LIDE-C数据流计算图种actor和edge是关键2元素,其中Actor设计包括四个接口函数:构造,启动,调用和种植函数(图2)。
1)构造函数:创建actor的实例并连接端口,通过函数参数列表进行算法处理后传递给相连的一组边。
2)启用功能:在运行时检查该actor是否有足够的输入数据和空的缓冲区空间来支持下一次调用。
3)调用函数:为actor执行单次调用。
4)终止功能:关闭此actor在计算图的作用,包括释放相关的存储对象及其所占用的资源。
LIDE-C中的FIFO设计构成的数据流图与其actors本身相互独立实现和优化,开发者可专注于Actor的设计(如算法的实现和优化),然后通过明确定义的接口和fifos集成这些actors,从而进行数据流图的调度优化(并行,优先级),这些可通过相互沟通实现整个性能的表现。FIFO操作由c中的接口函数封装。函数指针是指向这些接口功能,以不同形式实现不同的接口。LIDE-C中的标准FIFO有以下执行操作:
创建具有特定容量的新FIFO。
从/向一个fifo读取和写入token。
检查FIFO的容量。
检查FIFO中当前的token数。
使用FIFO完成后,用FIFO解除存储。
在一个数据流计算图应用程序中创建所有actors和fifos之后,逐步连接并逐步触发检查图形下一个关键actor,从而验证检查调试整个系统的当前使用情况。
2基于图像的车辆识别的网络架构
本文以基于图像的车辆识别网络系统,从零开始一步一步得到相应的网络,实现参考的Matlab推理网络代码,从而进一步实现优化基于数据流计算图的c代码实现,此方法具有一定的普适性和扩展性,且根据不同的需求可量身定制其它的应用需求。案例中的CNN实现四种车辆之间的分类——公共汽车,卡车,面包车和汽车,此源数据和工作基于之前的车辆分类工作,提取了相关的有用信息,使用Caffe+Python随机搜索来最优的超参数。在使用50组随机生成的超参数(图3)进行一系列搜索迭代之后,针对精确率和参数大小及性能的特征平衡,推导出一套可实施的优化过的超参数车辆分类系统,等到训练模型稳定后,提取相关的模型权重图4(注:本文目的是演示实现优化数据流计算图的方法,所选取的类型为double型,读者可根据深度学习相关知识,可相应地调整网络,例如用全卷积网络或半精度数据类型或者8比特的整数类型)。
训练好后得到的超参数所形成的CNN架构(见图4)由五层组成——两个卷积层,两个全连接层,最后是分类器层。第一层包括三个通道(红绿蓝RGB通道),每个输入图像96x96的三通道经过过滤后分解成32个特征图,然后最大值池化为48×48。在第二层中,有32组特征图再次卷积,然后下采样最大值池化到24×24。第三层和第四层是两层全连接层,每个节点有100个节点。分类器层执行从100个元素到4个元素并通过softmax运算符得到4个等级可能概率值。在层于层相邻之间,应用整流线性单元非线性激活函數(ReLU)。
3基于数据流的网络架构计算图设计
在得到整个网络拓扑图(图5)并提取出网络各个神经元的权重(图4)后,先在Matlab环境中实现其CNN推理的图像分类代码,其主要目的其一是确保此参数模型的最后效果,性能和准确性,其二是有一个参考代码并可收集每一层运算后的数值,便于后续数据流计算图c代码的实现、比较、调试和优化,这种逐层式至最后庞大系统的检测有益于整体代码实现的鲁棒性,并将可能的测试失败的原因显示化在具体的某一层某个aJctor或fifo,进行更好更快速的实现代码设计优化和迭代。
在开发了基于Matlab的CNN车辆分类系统的仿真参考模型后(图6和图7),我们继续开发基于数据流计算图LIDE-C的设计以及实现,并在多平台多核上进行性能测试,通过迭代式优化数据流计算图及actor算法来提高整体性能。
作为数据流模型的第一步,把CNN网络拓图转换了网络框图(图8),每个框图都可以看成带参数的高阶actor,高阶actor可以封装一个或多个带参数subgraph系统子图,而其中可能存在成千上万的actor互连,其形式类似于硬件模块的实现,所以可以进行很好的软硬件结合,此网络包含了共10种不同类型的actor:读通道actor,写通道actor,卷积actor,池化actor,非线性激活函数actor,分类器actor,聚合actor,广播actor,乘加actor,矩阵乘法actor。针对这些actors,按照不同的图结构进行封装设计,形成三种不同的数据流计算图(图9,图10,图11)。
设计一的优点是整个架构与框图最接近,且非常的清晰,易于理解和实现,验证和检查整个数据流计算图很直接方便。缺点是当子图已经确定且封装为一个大的actor后,难以进一步深层次地优化,若子图来自于第三方机构,当整个程序有错误时,很难进行调试;设计二相对简洁,在卷积层用到了循环展开(loop unrolling)和流水线(pipeline)技术进行优化,增加延迟但提高输出量。此方法很适合用于网络训练图结构,但需要一些技巧,总体来说,整个计算图仍旧可以理解;设计三的优点是整个数据流计算图可以任意地在某一步、某一个actor或fifo或缓冲区里跟踪,控制,管理,验证,检测数据,除此之外,设计三的颗粒度更细,可以更深层次进行优化,自行控制的选择余地比较多,相反的,缺点是不易于理解,构成,实现,优化这颗粒度细且庞大复杂的数据流计算图。
