融合常用语的大规模疾病术语图谱构建
2020-11-10张晨童张佳影张知行葛小玲
张晨童 张佳影 张知行 阮 彤 何 萍 葛小玲
1(华东理工大学 上海 200237)
2(上海申康医院发展中心 上海 200041)
3(复旦大学附属儿科医院 上海 201108)(chentong_zhang@163.com)
随着医疗领域信息化程度的不断提升,欧美国家的医疗研究机构已经建立起一系列医学术语库,如临床医疗术语集(systematized nomenclature of medicine-clinical terms, SNOMED-CT)(1)http://www.snomed.org/snomed-ct/、一体化医学语言系统(unified medical language system, UMLS)(2)https://www.nlm.nih.gov.research.umls、ICD-10(international classification of dis-eases 10th revision)(3)https://icd.who.int/browse10/2016/en、ICD-11(international classifica-tion of diseases 11th revision)(4)https://icd.who.int/browse11/l-m/en等.其中,中华人民共和国国家卫生健康委员会明确要求各医疗机构在病案书写中统一使用ICD-10中文版(简称ICD10),这极大地推进了医疗服务规范化、标准化管理.
然而,ICD10在实际应用于临床数据时,能够直接建立映射的比例不足20%.其主要问题有2点:第一,疾病名称描述的多样性.例如,“尿路感染”是临床诊断中的常用语,但在ICD10中并未收录该词.该词是“泌尿道感染”的同义词,后者在ICD10中对应的编码为N39.0.第二,疾病常用语的粒度更细.例如,“糖尿病伴有眼部改变”在ICD10中无法找到与之匹配的同义词,仅能找到它的上位词“糖尿病”,糖尿病在ICD10中对应的编码为E14.900.因此,以ICD10为标准,构建一个融合常用语的疾病术语图谱,将常用语作为同义词或下位词融入ICD10,可以有效建立疾病名称与ICD10的映射关系,将方便医生查找疾病名称或是机器进行ICD自动编码.然而常用语的融合需要大量医学知识,而人工建立映射耗时耗力,机器自动映射准确率比较低.另外,ICD10的分类体系延续了传统的列表式结构,过于平面,并不方便浏览与查找.
针对上述问题与难点,本文提出了一种融合常用语的大规模疾病术语图谱构建方案.具体来说,本文筛选出上海市区域医疗健康平台(其包含市内38家三级医院的临床诊疗信息)的疾病数据中的常用语,将常用语与ICD10进行融合.此外,为方便医生查找,将ICD10的类目层与ICD-11中文版(简称ICD11)的层次结构进行进一步融合,形成融合常用语的大规模疾病术语图谱.本方案的贡献点有3个方面:
1) 疾病术语图谱的构建将机器与人工的优点结合起来.首先分析疾病词构成成分,利用基于疾病构成成分的规则算法识别出疾病间的同义关系,并通过基于数据增强的BERT(bidirectional encoder representation from transformers)上下位关系识别算法找出疾病间的上下位关系,进而利用ICD体系本身特点,按照疾病类型,基于专科分组校验疾病数据.本文还设计了基于疾病-科室关联图谱的任务分配方法,方便校对人员对医疗数据进行校验,以保证疾病医学实体关系的准确度.
2) 面向临床诊断数据构建出了融合常用语的大规模疾病术语图谱,图谱可以表示出医疗术语间的上下位关系和同义关系,将常用语与标准术语融合起来.最终找出1 460条同义关系、46 508条上下位关系.
3) 本文构建的疾病术语图谱,在维护现有标准体系的同时,兼顾了临床使用的方便性.本文从编码覆盖率、编码效率和编码正确率3方面对疾病术语图谱进行了评估,利用本文构建的疾病术语图谱相比于ICD10体系能够平均多覆盖75.31%的临床诊断数据,并且利用疾病术语图谱辅助编码相比于人工编码,能够缩短约59.75%的时间,且正确率达到85%.
1 相关工作
国内外关于术语体系构建方面有很丰富的研究.国外构建了大量的生物医疗分类体系,除了UMLS[1],SNOMED-CT等通用的分类系统,还有面向药物的命名系统RxNorm(5)https://www.nlm.nih.gov/research/umls/rxnorm/docs/prescribe.html、针对检验的编码系统LOINC(6)https://loinc.org和被广泛应用的国际疾病分类系统等细分的系统.而国内在医学术语体系上不断和国际接轨,如ICD10.
早期术语体系的构建采用纯手工的方式,如面向语义的英语词典WordNet[2]和常识知识图谱CYC[3],其中CYC由50万实体、700万条断言构成.近年来,采用自动方法构建术语体系得到广泛应用,其构建过程涉及自动分类归纳的问题,即能够有效地扩充整个知识结构,有大量的工作研究了基于语言模型匹配的方法,用来解决术语与其上位词之间关系的自动分类归纳问题.如Hearst[4]描述了一种从无限制文本中自动获取下位词的方法,确定了一组易于识别的词汇-句法模式.Navigli等人[5]提出了一种基于图形的方法,旨在从域语料库和Web开始自动学习词汇分类法.实验表明,无论是在构建全新的分类法时还是在重构WordNet子层次结构时,都能获得高质量的结果.Snow等人[6]提出了一种从文本中自动学习上下位(is-a)关系的新算法来解决自动构建和扩展语义分类法(如WordNet)的问题.Yang等人[7]提出了一种新的基于度量的框架,用于自动分类归纳的任务.近年来,使用基于字嵌入的方法来识别关系以重建分类法的做法也十分普及[8-11].
将常用术语等新信息加入到现存分类法中,主要集中在增强WordNet分类标准上.Toral等人[12]丰富了WordNet的310 742个命名实体和381 043个“关系实例”.Fellbaum等人[13]创建了Medical-WordNet,其不仅是对原始WordNet中医学术语的词汇扩展,而是提出了一种新型的存储库.Vedula等人[14]研究了知识结构扩充问题,即对于大量出现的新的概念,怎么将其添加到已有的知识结构中.这一问题存在双重挑战,如何检测未知的实体或概念,以及新的概念怎样插入到已有的知识结构中而不破坏新创建的关系的语义完整性.他们提出了ETF的框架,用来自新闻和研究出版物等资源的新概念来丰富大规模的通用分类法,将新概念链接到现有概念上,获得潜在的父子关系.
然而,单纯采用人工构建的方式需要耗费大量的人力物力,仅使用自动构建的方式又不能保证机器的正确率.因此本文采用了人工和自动构建相结合的方法.
2 疾病术语图谱构建
2.1 问题定义
本文参考并扩展了ICD10及ICD11的分类层级体系,将疾病医学实体关系定义为:
定义1.不同疾病医学实体之间的映射关系R(Ei,Ej).其中Ei,Ej为疾病医学实体,R为映射关系.映射关系包括2类:
1)is_hypernym关系.is_hypernym(Ei,Ej)表示实体Ei和Ej之间的上下位关系.特别地,is_hypernym关系具有反函数性:is_hypernym(Ei,Ej)⟺is_hyponymy(Ej,Ei),即Ei是Ej的上位词,等价于Ej是Ei的下位词.为了方便,如若不做特别说明,本文此后的上下位关系专指上位关系.
2)is_same关系.is_same(Ei,Ej)表示实体Ei和Ej之间的同义关系.同义关系包括2部分:一是医学上的同义关系,类似于“胰岛素依赖型糖尿病”和“1型糖尿病”属于同义关系.二是因医生书写习惯不同导致的同义关系,类似于“1型糖尿病”与“糖尿病(1型)”属于同义关系.
本文的主要任务,是将常用语根据疾病医学实体关系链接上ICD10,并且将ICD10中类目层与ICD11的层次结构进行融合,以构建出融合常用语的大规模疾病术语图谱.其中,常用语定义为区域平台上临床诊断疾病数据中出现频次大于5次的疾病名称.
2.2 整体框架
本文的整体框架如图1所示.首先ICD10融合常用语,然后再添加ICD11层次结构信息,最终形成融合常用语的疾病术语图谱.

Fig. 1 Overall framework of large-scale diseases terminology graph by integrating common terms
图1左侧展示了疾病术语图谱的基本框架,首先将常用语与ICD10中标准疾病名称融合,融合过程即判断疾病对ICD10中标准疾病术语,常用语是否具有上下位关系或同义关系,根据疾病对的疾病医学实体关系,将常用语链到ICD10各层上,实现对常用语的归类.图1右侧分别显示了利用疾病构成成分的规则算法识别疾病对是否具有同义关系以及在基于疾病构成成分的规则算法基础上,结合BERT识别疾病对是否具有上下位关系.其次,根据映射规则将ICD10中类目层链接到ICD11的层级结构上.最后,为了保证融合结果的正确性,引入了基于疾病-科室关联图谱的任务分配方法,方便校验人员对疾病术语图谱包含的疾病医学实体关系进行修正处理.
2.3 ICD10融合常用语
对于疾病术语之间的关系识别任务,本文定义为同义和上下位关系识别,而其重点在于上下位关系的识别.Wang等人[15]提出基于规则的上下位识别算法,由知识驱动,通过预先构建包含大量细粒度临床实体的词典以及实体间上下位关系的集合,用以关系判断.基于规则的方法能够高质量地识别出上下位关系,然而受限于词典的规模,其召回率很低.因此,本文在使用预训练模型的基础上,结合规则提供的参考结果予以辅助信息,提出基于数据增强的BERT上下位关系识别算法.
本文将常用语与所有ICD10中标准疾病术语组成疾病对,利用基于数据增强的BERT上下位关系识别模型对疾病对进行上下位关系的预测,并对所有的预测结果根据模型预测为上下位关系的概率进行排序,将最高概率的X1,X2作为最终输出结果.
2.3.1 参考对构造
1) 疾病构成成分定义
基于对ICD及区域医疗平台包含的38家医院的临床诊断数据的分析,本文将疾病词归纳为由原子疾病词(atomic disease words)、病因词(causal words)、病理词(pathological words)、部位词(part words)、临床表现词(clinical expression words)5大成分构成,表1给出了具体含义.

Table 1 Examples of Disease Components
2) 基于疾病构成成分的规则算法
给定ICD10的疾病名称集合D={D1,D2,…,Dn},其中n为疾病名称的总个数.基于疾病构成成分的规则算法先基于疾病构成成分的双向最大匹配算法分别对Di和X2进行分词,剔除其中的无效词,无效词具体包括连接词、副词、程度词、标点符号,如“患有、的、伴有”等.然后,将剩下的词替换成其对应的标准名称,由此分别得到有效元素集合setD和setX.对于Di,X2的有效元素集合setD和setX中的元素,本文迭代地用其上位词替换下位疾病成分以检测上位关系,直到出现以下这2种情况:若setX中包含setD,则Di是X2的上位词,并返回替换次数;否则,继续进行上位词替换,直到没有上位词可替换为止.最后,设定X3为满足上位词条件且替换次数最少的Dj.算法伪代码如算法1所示.
算法1.基于疾病构成成分的规则算法.
输入: ICD10中标准疾病术语X1、临床诊断疾病数据中的常用语X2、疾病构成成分词典中的同义关系集合R、停用词集合S={S1,S2,…,Sn}、疾病构成成分词典中的上位关系HypernymMap;
① 对X1,X2根据双向最大匹配算法进行分词,分别得到X1={X11,X12,…,X1m},X2={X21,X22,…,X2n}的组成部分;
② forX2i∈X2do
③ ifX2i=Sithen
④ 将X2i移出X2;
⑤ else ifX2iinRthen
⑥ 将X2i用在R中的标准同义词替换;
⑦ end if
⑧ end for
⑨ 对X1同样进行步骤②~⑧操作;
⑩ 分别得到X2的有效成分集setX和X1的有效成分集setD;
2.3.2 基于数据增强的BERT上下位关系识别算法
判别疾病医疗实体语义关系的问题,可看作一个分类任务,即ICD10中标准疾病术语X1是否是常用语X2的上位词.模型架构如图2所示:
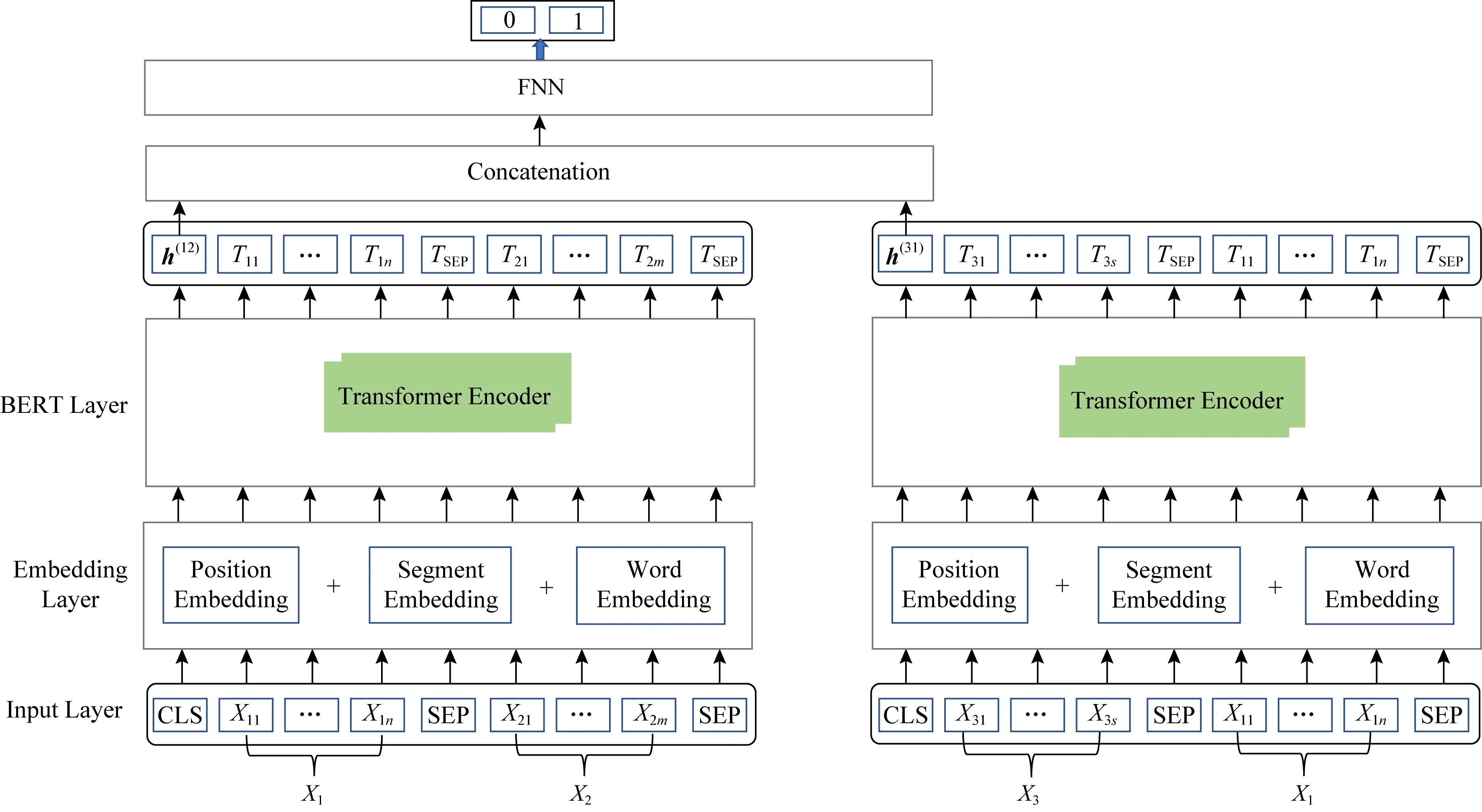
Fig. 2 Model of hypernym recognition algorithms of BERT based on data enhancement
2.3.3 术语图谱关系识别算法对比实验
本文验证了构建融合常用语的疾病术语图谱中所用算法的有效性,我们利用区域医疗平台中的疾病数据作为实验数据集.特别地,该数据集中疾病名称之间的同义关系较少,因此直接利用基于疾病构成成分的规则算法判断同义关系,故本文仅针对上下位关系进行对比实验.
本文选取了4种关系识别算法,与本文所使用的方法进行对比:
1) 字符串相似度算法(string similarity algorithm).首先,求解出每一个疾病对中ICD10中标准疾病术语X1和常用语X2的Levenshtein距离distance(X1,X2),Levenshtein距离指2个字符串之间由一个转成另一个所需的最少编辑操作次数.若distance(X1,X2)结果超过阈值,则认为X1,X2具有上下位关系;否则,无关系.本文设置的阈值为0.8.
2) 动态距离损失模型(dynamic distance loss model).文献[11]将每个常用语X2训练出一个下位词向量OX2和一个上位词向量EX2.每当X2作为下位词出现的时候,使用OX2;作为上位词候选出现的时候,使用EX2.然后,利用监督语料训练SVM模型,并利用训练好的模型判断输入疾病对X1,X2是否是上位词对.
3) 基于疾病构成成分的规则算法(rule algorithm based on disease components).文献[15]将疾病对X1,X2先根据词典进行分词,将分词后的元素进行去停用词、标准化操作,若X1的元素包含在X2的元素中,那么X1是X2的上位词,否则,迭代地用X2元素的上位词替换X2的该元素.
对于关系识别结果,本文的评价指标采用最常用的Precision,Recall,F1_score作为评测标准,评估结果计算公式为:
① https://icd.who.int/browse11/l-m_st_infections/en
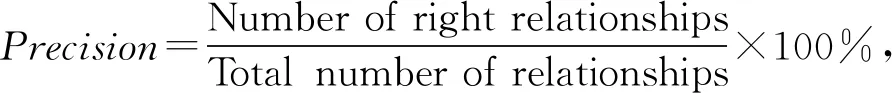
表2展示了5种对比算法的Precision,Recall,F1_score.与现有算法相比,本文使用的算法获得最好的F1_score值,其Precision,Recall,F1_score分别为97.18%,93.94%,95.53%.对于基于规则的关系识别方法,它的Precision达到了100%,Recall却很低,这是因为该算法受限于词典的规模而覆盖不全,但其预测的结果置信度很高.这也是本文融合该算法提供辅助信息的原因.此外,我们发现,本文算法的F1_score值比单独使用BERT高了0.92%,证明了基于数据增强的BERT上下位关系识别算法的有效性.

Table 2 Comparative Experimental Results
2.4 添加ICD11层次结构信息
借助于ICD10与ICD11官网发布的映射表①,本文将融合了常用语的ICD10结构中的所有类目层疾病链接到ICD11的层次结构上,以添加ICD11层次结构信息,得到更加细粒度的疾病层级结构,方便医生查看和筛选疾病.添加ICD11层次结构信息的原因在于:
1) ICD10的3位类目码的层次结构过于平面,没能体现出疾病间的层级结构.如图3所示,在ICD10中“糖尿病”与“内分泌疾病”处于同一层级上,而“糖尿病”应属于“内分泌疾病”,即“糖尿病”应位于“内分泌疾病”的下层层级.
2) 疾病分类日益精细化,ICD11调整了分类轴心、改变分类层次、增加或细化分类单元,对ICD10原有的分类结构和分类知识进行修订与完善.但鉴于医疗机构近10年来都采用的ICD10作为疾病编码标准,因此,需利用ICD10与常用语先做融合再添加ICD11的层次结构信息.
ICD10标准的分类编码首先是类目,类目下分亚目,亚目下分细目,共3个层次.本文将ICD10类目层疾病映射到ICD11任意层疾病上,发现ICD10类目层能映射上91.26%的ICD11中的疾病,于是将ICD10中的类目层的疾病(共2 047个)映射到ICD11各层节点的结果如表3所示.
表3中共映射了2 521条,而ICD10类目层疾病共2 047条,多出474条的原因在于有213条数据不唯一映射.例如,ICD10类目层的“其他细菌性肠道感染”(编码A04)被进一步拆分成了ICD11中的“其他弧菌的肠道感染”(编码1A01)、“大肠埃希菌肠道感染”(编码1A03)、“细菌性肠道感染、未特指的”(编码1A02),从而导致映射不唯一.因此,需要把ICD10亚目层和细目层与ICD11的多重映射进一步对齐,而这需要专业医护人员介入,于是本文利用2.5节提到的基于疾病-科室关联图谱的任务分配方法对构建的融合常用语的大规模疾病术语图谱进行知识校验.

Fig. 3 Contrast schematic diagram of partial hierarchical structure between ICD10 and ICD11

Table 3 Mapping ICD10 Category Layer to ICD11 Layers

Fig. 4 Flow chart of task allocation method based on disease-department association graph
2.5 知识校验
即使经过数据增强,基于上文的上下位关系识别算法仍无法保证预测的上下位关系全部正确,可能出现2种错误情况:
1) 常用语与错误的ICD10名称具有关系.如“2型糖尿病性神经病变”通过算法得出与“2型糖尿病性神经炎”具有上下位关系,而正确的应该是“2型糖尿病伴神经并发症”.
2) ICD10名称不是常用语的直接上位词.本文将与常用语在层次结构上最相邻的上位词称为直接上位词.上下位关系具有传递性,即X是Y的直接上位词,Y是Z的直接上位词,可得X是Z的上位词(非直接上位词).如“2型糖尿病性大量白蛋白尿”通过算法与“2型糖尿病”具有上下位关系,而“2型糖尿病性肾病”才是“2型糖尿病性大量白蛋白尿”的直接上位词.
上述情况的判断和纠正依赖于更深层的领域知识,为了确保疾病术语图谱的医学正确性,需要借助人工.
因此,本文设计了一种基于疾病-科室关联图谱的任务分配方法,方法流程如图4所示.首先获取2.3.2节算法预测出的所有疾病对ICD10中的标准疾病术语,常用语集合生成待校验术语集,依据疾病对中标准疾病术语所对应的科室划分为多个基于科室的待校验术语子集.同一个待校验术语子集将被分配给同一科室的多名校对人员进行校验与修改,完成后交由机器自动进行一致性判断,校验结果可信度高于0.5的数据归为正确术语集,剩下的将由专家查验.
2) 人工校对.同一任务将分配给n(n≥3)名医护人员进行校验,目的是降低校验结果的随机性与偶然性.针对常用语链接上错误的ICD10名称的情况,医护人员修改图4知识校验表格中的[标注类型]或[标注对应ICD10编码];针对常用语链接上非直接上位词的情况,医护人员根据图4知识校验表格中[常用语所在术语库的层次结构]判断该常用语是否是直接上位词,并做相应修改.人工校对过程中对于某一条数据所有校对人员都没有修改的情况,则将该条数据直接加入正确术语集中.
3) 校对一致性判断.由于多人对同一条数据进行校对时,会出现多种修改情况.针对多人校对结果存在非一致性,需要对校对结果进行质量评估.
针对人工校对的结果,具体质量评估如下:将每条待校对数据视为一个校对任务Ti,保证每个校验任务Ti都有n(n≥3)名校对人员进行校验.每名校对人员在一次校验任务Di中可能出现m种校对结果.因此,每个校对结果的可信度计算为
其中,nj表示选择第j种校对结果的人数.如果tdj>0.5,则此次校对任务Ti的第j条校对任务结果正确,将其直接输出正确术语集;否则,将Ti交由医学专家进行查验.
4) 人机结合的方法节约了人力成本.首先,对于每一个常用语,算法都预测了在ICD10中的位置.虽然这个未必精确,但该所在的术语子树的分配一般来说是准确的.比如2.3.2节算法做错的“2型糖尿病性神经病变”与“2型糖尿病性大量白蛋白尿”,都是术语“2型糖尿病”的子树.这样保证了数据搜索空间从ICD全集搜索缩减至子树搜索.而且糖尿病整体属于内分泌科,专科校对人员分配也是正确的,保障了人员可以对熟悉的疾病进行校验.
3 疾病术语编码评估
3.1 评估编码覆盖率
为了验证本文构建的疾病术语图谱能够有效覆盖更多临床诊断数据,我们从电子病历(electronic medical record, EMR)出院小结表中抽取出10 038条数据,作为第1组评估数据,并从随访数据中抽取出9 426条数据作为第2组评估数据,统计基于ICD10和本文构建的疾病术语图谱进行疾病编码能够映射成功的数量,映射结果如表4所示:

Table 4 Disease Names’ Code Mapping
从表4中可以看出使用了本文构建的疾病术语图谱相比于基于ICD10,编码覆盖率能平均提升75.31%,证明使用了疾病术语图谱能找到更多的疾病对应编码.但是本文构建的疾病术语图谱仍然没能找全所有疾病医学实体关系,其原因包含2个方面:1)由于真实数据出现2种疾病名称的情况.比如疾病名称“新生儿惊厥(癫痫)”,其中“新生儿惊厥”在ICD10中对应编码是P90.x00,“癫痫”在ICD10中对应编码为G40.901,而“新生儿惊厥”和“癫痫”是2种疾病,疾病术语图谱难以根据算法分辨出其疾病编码.2)真实数据中出现并非疾病名称的数据,如“自体干细胞移植术后”、“后尿道瓣膜术后”等.对于第1种情况,可根据符号将包含2种编码的疾病名称设置不同的权重.对于第2种情况,出现非疾病名称的数据本不应该链接到疾病术语图谱上.
3.2 评估编码效率
为了验证本文构建的融合常用语的大规模疾病术语图谱在医疗领域中医生填写疾病编码时的优势,我们设置了人工编码和机器辅助编码2种评估方法,旨在对比构建的疾病术语图谱对医生编码疾病效率的影响.
对于人工编码,我们招募了5名熟悉ICD编码的医护人员,给定ICD10疾病标准分类编码,统计5名测试人员对随机采样的50条疾病名称找出匹配编码的完成时间.
对于机器辅助编码,我们首先利用本文构建的疾病术语图谱自动找出50条疾病名称对应的ICD10编码,以2.5节中图4所提及的知识校验表格的形式展示,然后5名校对人员对机器匹配结果进行校验.此时的完成时间定义为机器运行时间和校对人员校验所花费的时间之和.
实验结果如表5所示,使用了本文构建的疾病术语图谱辅助编码的完成速度是人工编码的2.48倍,表明了使用本文构建的疾病术语图谱自动进行疾病编码能够缩短医生的编码时间.实际情况下,医疗机构的医护人员对ICD编码体系并不是太熟悉,这也会影响编码效率,并且随着疾病数据量的增长,更能凸显将本文构建的疾病术语图谱应用于病案首页填写过程中的优势.
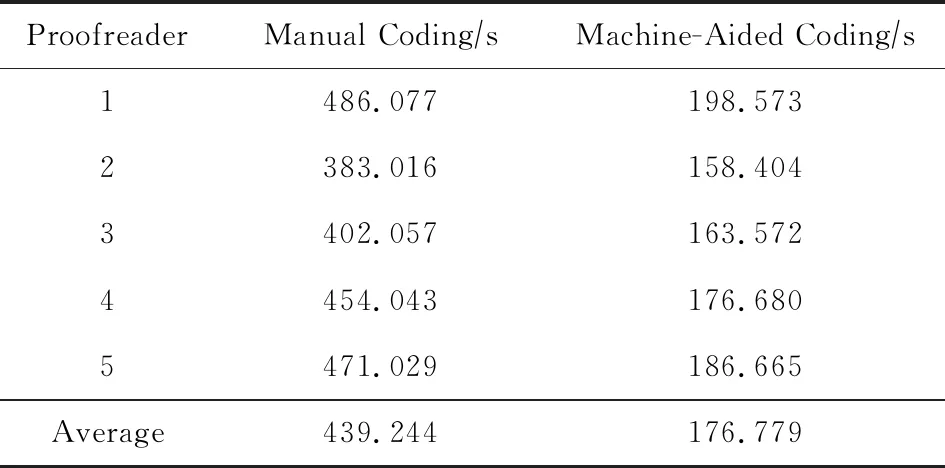
Table 5 The Completion Time Results of Manual Coding and Machine-Aided Coding
3.3 评估编码正确率
利用区域平台电子健康记录(electronic health record, EHR)数据验证本文构建的疾病术语图谱的有效性,该数据包含上海38家三甲医院的挂号数据,含医生编码的数据占536 456条,对数据进行清洗后,随机抽取2个专病数据作为评估数据.本次评估目标在于统计医生手工编码和使用了本文构建的疾病术语图谱编码各自的正确率(accuracy),结果如表6所示.值得注意的是,评估数据的标准ICD编码以经过知识校验后得到的ICD10编码为准.

Table 6 Accuracy of Doctor’s Manual Coding and Auto Coding by Disease Terminology Graph
从表6结果可以看出,利用本文构建的疾病术语图谱编码的正确率远高于医生手动编码的正确率,提升了66%.对医生手动编码正确率低的原因进行分析:1)医生对编码理解不统一,对于“2型糖尿病性酮症”这一疾病名称,医生编码包括了E11.103,E11.100,FFF这3种编码,使用疾病术语图谱编码为E11.100,经过校对人员校验,其与“2型糖尿病性酮症酸中毒”为同义关系,编码应为E11.100.2)部分医生填写疾病编码不规范.如常用语“胃恶性肿瘤Ⅳ期”应该链接在ICD10中“胃恶性肿瘤”(编码为C16.900),而医生编码为C16.再比如常用语“Ⅱ型糖尿病”,其对应于ICD10中的“2型糖尿病”(编码为E11.900),而医生编码写作E11.90000S.
4 结论与未来工作
本文通过基于疾病构成成分的规则算法和基于数据增强的BERT上下位关系识别算法辨别出常用语与ICD10中标准疾病术语的疾病医学实体关系,实现常用语与ICD10编码的映射,并且添加了ICD11的层级结构,方便医生查看疾病对应ICD10编码.利用本文构建的疾病术语图谱进行疾病编码在编码覆盖率、准确率以及编码效率3方面均有良好的表现.在未来,能够在各医疗结构中应用该疾病术语图谱,保障疾病编码的覆盖率、效率和准确率,推进医疗信息规范化进程.
