面向大规模图像检索的深度强相关散列学习方法
2020-11-10贺周雨冯旭鹏刘利军黄青松
贺周雨 冯旭鹏 刘利军,3 黄青松,4
1(昆明理工大学信息工程与自动化学院 昆明 650500)
2(昆明理工大学信息化建设管理中心 昆明 650500)
3(云南大学信息学院 昆明 650091)
4(昆明理工大学云南省计算机技术应用重点实验室 昆明 650500)(he535040@qq.com)
随着移动设备和互联网的快速发展,每天有大量的图像被上传到网络.百万级甚至是千万级的图像数据量使得准确、快速地检索出用户需要的图像变得越来越困难.大规模图像检索是计算机视觉研究的根基,直接关系到计算机视觉的实际应用[1].图像检索主要分为基于文本的图像检索(text-based image retrieval, TBIR)以及基于内容的图像检索(content-based image retrieval, CBIR).TBIR的一般方法是对图像进行标注,再根据标注的文本进行基于关键字的检索[2].TBIR的优势在于用户只需要提供关键字就可以得到检索结果.但相应地,这导致检索性能的好坏很大程度上取决于用户输入的关键字准确与否[3].然而,在实际应用中,文本很难准确地描述相应的图像,这直接导致了TBIR的检索性能差强人意.文本的局限性使得其不适用于图像信息爆炸增长的现状,因此目前主流方法是CBIR.CBIR根据图像本身的纹理、颜色、款式等信息进行检索,从根本上解决了TBIR的缺陷.在CBIR中,最为重要的一步是对图像信息进行提取,提取出的图像特征信息质量将直接决定该图像检索系统的性能好坏.目前,CBIR中常用的图像特征提取方法可分为经典方法与深度学习方法.常用的经典方法主要有3类:1)基于颜色特征.基于颜色特征的图像检索方法[4]提取出的图像特征属于全局特征,且简单、易实现.缺点在于,该方法很难描述图像中的具体对象以及无法考虑到对象空间位置.2)基于纹理特征.基于纹理特征的图像检索方法的优点在于特征拥有旋转不变性和一定的抗噪能力.这类方法的缺点在于无法利用图像的全局信息,从2维图像得到的纹理特征不一定是相应3维物体的真实纹理,从而导致检索性能表现不好.3)基于形状上下文特征.基于形状上下文特征的图像检索方法相对于上面2种特征来说,能够描述图像中的具体对象,有一定的语义关系.通常,形状的描述子可分为轮廓和区域2种,具体的方法有链码、边界长度、小波变换、傅里叶描述子、曲率尺度空间描述子、多边形逼近等.这类方法的缺点在于计算复杂度高,无法适用于大规模的图像检索[5].可以看出,经典方法没有使用图像的全局空间信息,且具有计算开销大、检索速度慢等缺点.深度卷积神经网络(convolutional neural network, CNN)就此应运而生,它能够挖掘到图像信息之间的内在隐含关系,对图像信息进行全局编码.CNN具有多个层,不同的层进行不同的计算,通过层与层之间的前向传播与后向传播进行数据更新,多次迭代以学习到更好的特征表示.文献[5]通过实验证明了CNN能够保留图像的全局空间信息,将原始图像像素矩阵进行卷积、池化、激活、全连接等操作,得到了一个特征表示,再使用这个特征表示重构出了原始的输入图像.自从AlexNet[6]在ILSVRC2012比赛中取得冠军后,深度学习备受关注并迅速占领主导地位.近2年,在世界信息技术顶级会议CVPR(Conference on Computer Vision and Pattern Recog-nition),ECCV(European Conference on Computer Vision)以及ICCV(International Conference on Computer Vision)中,7成以上的图像检索方法研究是基于深度卷积神经网络的.国内也出现大量改进深度卷积神经网络进行图像检索的学术研究[7-8].可以看到,相对于传统方法,基于CNN的方法性能表现良好且具有很大的潜力.
随着互联网的快速发展,数据规模得到爆炸式增长,与此同时散列方法与深度学习相结合的方法被广泛地应用在加速图像检索任务中.散列方法在检索速度以及存储开销上有其他方法无法比拟的优势,它能够将高维的特征矩阵降维成紧凑的二分散列码.在图像检索中,通过比较2个散列码之间的汉明距离判断2个图像是否属于同一类别.其中,汉明距离的计算开销要远远小于其他距离计算方法,因此可以很快地返回结果,以实现快速地图像检索.在散列方法中,最重要的步骤是特征提取部分,这一步骤将直接影响图像检索的准确率.传统的散列方法大多是基于手工特征的,比如文献[9]提出的语义散列方法、文献[10]提出的词袋散列方法.这些方法不具有泛化性,它们需要大量的人力开销.局部敏感散列[11]是具有代表性的一种散列方法,它预测相邻的数据通过散列计算后仍然是相邻的.该方法成功地降低了计算成本并且具有一定的准确性.2014年,文献[12]将深度学习与散列方法结合得到了显著的实验效果提升,自此出现了大量的深度学习与散列方法结合的研究.文献[13]提出了一种监督散列检索方法,与之前的方法相比检索性能有所提升.但是该方法的网络结构需要3个图像构成的三元组信息作为输入,需要人为设计三元组,使得人为工作量增大以及泛化能力降低.文献[14]将研究重心转移到汉明距离的计算方法上,他们使用加权的汉明距离计算方法,得到了较好的实验效果.但加权汉明矩阵需要三元组图像作为输入并生成汉明空间,必然使得计算开销增大,牺牲了散列方法的部分优势.
目前,对于散列方法与深度学习研究的热点在于改进散列编码的约束方式.文献[15]提出一种深度离散散列方法,该方法提供了一种解决离散散列问题的最优化方法,实验结果表明该方法能有效提升检索准确率.但是该方法需要图像进行成对输入,使得计算开销变大.文献[16]通过精心设计的损失函数得到了更具有区分性的散列码,使用成对的图像输入,通过相应的标签判断2个样本是否为同一类别,再根据相似矩阵改进损失函数,最后得到一个松弛的散列码用于前向传播与反向传播.这样做的优点在于考虑了更多的原始信息以及能够得到更具有区分性的散列码,缺点在于成对的输入使得计算开销增大以及需要制作标签.因此该方法并不适用于大规模的图像检索.目前大多数散列方法都使用“成对”或“三元组”的输入来寻找隐藏的数据关系.这类方法必然会增大计算开销,不适用于大规模的图像检索.为了实现快速且准确的大规模图像检索,本文提出一个深度强相关散列学习方法.该方法具有3个特点:
1) 是一种简单、有效、可广泛使用于各种网络结构的深度监督散列学习方法.
2) 提出了一个独特设计的强相关损失函数.相比于常用的“成对”、“三元组”策略,在减少计算开销的同时能够保证提取到的特征更具有区分性.
3) 在CIFAR-10, NUS-WIDE, SVHN这3个大规模公开数据集上进行实验,结果表明本文方法在检索性能上优于目前主流方法.
1 相关工作
1.1 深度监督散列学习
随着数据的爆炸式增长,散列方法得到了更多的关注.散列方法能够将高维的特征矩阵降维成低维、紧凑的二分散列码,在检索速度以及存储开销上具有其他方法无法比拟的优势.与此同时,CNN[17-19]在计算机视觉任务比赛中取得了巨大的成功.CNN在图像检索任务中可以达到很高的准确率,而散列方法能够实现快速地图像检索.深度散列学习就此应运而生.深度监督散列学习方法是有监督的深度散列方法.典型的深度监督散列学习方法通过标签信息生成一个相似矩阵,利用得到的相似矩阵约束散列码的生成.在深度监督散列学习方法中,散列码直接来自于神经网络.通过深度监督散列神经网络学习散列函数,能够挖掘到数据间更深层的隐藏关系.但是,深度监督散列方法面临一个难题,二分散列码编码过程中的离散约束会造成量化损失.一些深度监督散列学习方法[20-21]使用惩罚机制来削弱离散约束带来的负面影响,但效果不够理想.文献[22]添加一个全连接层以得到一个散列码,再通过最大值激活输出.这样做有一定的提升效果,但并未直接对散列编码进行约束,不能够挖掘到特征之间潜在的联系.本文方法设计了一个强相关损失函数,能一定程度地解决这个问题.
1.2 度量学习
度量学习,也叫作相似度学习,被广泛地应用在计算机视觉领域.度量学习的基本思想是,尽量增大特征的类间距离,减小类内距离.深度散列学习方法是一种特殊的度量学习.它是深度学习与散列方法的结合,目标是学习到一个相似函数,通过相似函数生成二分散列码.目前,大多数的深度监督散列方法使用二元或者三元损失函数对散列学习进行约束.常用的做法是通过标签信息生成一个相似矩阵,再利用相似矩阵构建损失函数,通过迭代计算损失值来约束散列码的生成.这类方法的输入数据是一个二元组或者三元组,使得训练样本量达到O(n2)或者O(n3),其中,n为训练样本数量.这类方法[16,23-24]牺牲了散列方法最大的优势——低内存消耗、高计算速度,对于大规模数据来说计算开销太大.我们的目标是设计一个新的损失函数来约束散列码的生成,实现在不失准确率的前提下大幅提升计算速度.
目前,softmax函数被广泛地应用在CNN中.softmax函数是一个归一化指数函数,具有简单且能用数学概率解释的特点.它可以与交叉熵方法相结合成为softmax交叉熵损失函数,一般作为卷积神经网络中分类器的基本公式.随后的一些研究,如Center Loss[25],L-softmax[26]等一元损失函数都是在softmax交叉熵损失函数的基础上进行改进的,它们能够学习到一个很好的距离.大量实验证明,这类一元损失函数在人脸识别、图像检索等实验中表现出优异的性能[25].本文方法的强相关损失函数也是受到一元损失函数的启发并加以改进.强相关损失函数是一个根据学习目标进行调节的函数,它有4个优点:1)能够调节特征之间的距离,通过增加训练学习时的难度,调节权重矩阵敏感度以学习到更具有区分性的特征.2)能够适用于各种卷积神经网络结构.3)能够有效地防止发生过拟合.4)内存开销小、计算速度快.
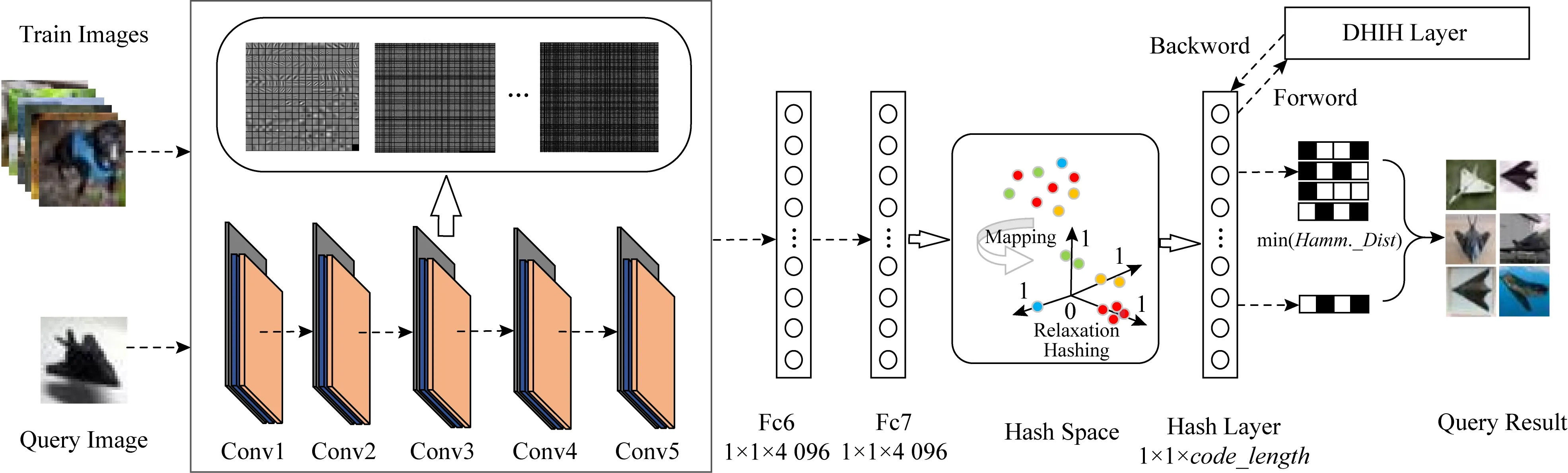
Fig. 1 The pipeline of our proposed method
1.3 深度强相关
强相关又称为高度相关,是数据计量分析法研究的要点之一.强相关是研究对象的数组和另一数组或者另一复合数组之间是否存在高度的相关关系.在数理统计中存在定理[27]: 当且仅当随机变量矩阵X与Y之间存在线性关系,即Y=kX+b时,它们的相关系数的绝对值等于1,X与Y为强相关关系.为了方便计算,可以忽略偏置b.在本文方法的强相关损失函数中,Z为损失层1的输出矩阵,其计算公式为Z=mαXW,其中m为正整数,α为权重相关系数,X为损失层1的输入矩阵,W为权重矩阵.由上述定理可知,Z与W之间存在线性关系,且权重相关系数α的设置使得Z值对权重矩阵W更敏感,Z和W之间是高度正相关的.深度强相关为深度学习与数据计量分析法的结合.本文提出一个深度强相关散列学习方法,能够与各种卷积神经网络结构相结合,通过迭代训练学习到一组紧凑的二分散列码,可以实现高效的大规模图像检索.本文方法学习到的二分散列码在公开、大规模数据集的图像检索任务中取得很好的成绩.
2 本文方法
2.1 深度强相关散列学习模型
本文方法的主要改进在于为卷积神经网络添加散列层及设计强相关损失层.在散列层做出的改进为限制神经元个数,使得输出一个低维度的矩阵,再限制该矩阵的取值范围,从而得到松弛的散列码.在损失层使用基于常规损失函数进行改进的强相关损失函数.本文方法保留且遵循卷积神经网络的基本结构及原理,可以应用到多种卷积神经网络中,将在4.3节验证本文方法的普遍适用性.为了方便介绍本文方法,在本节采用AlexNet为例进行改进,将深度强相关散列学习方法应用在AlexNet中,得到深度强相关散列(deep highly interrelated hashing, DHIH)模型.图1为DHIH模型的总体框架,主要分为模型训练与图像检索2个部分.模型训练部分展示了从训练图像输入到反馈损失值驱动网络更新的整个训练过程.图像检索部分提供了一个从待检索图像输入到相似图像输出的检索功能.网络配置如表1所示,其中Hash Layer为散列层,code_length为散列码位数.
图像相应的散列码提取自训练好的DHIH模型的散列层输出.DHIH模型的训练过程为:输入图像经过卷积子网络,把图像信息映射到特征空间中,得到一个局部式特征表示;再经过全连接层6以及全连接层7,把上层得到的局部式特征表示映射到样本标记空间中,其中全连接层6的输出特征矩阵为1×1×4 096,全连接层7的输出特征矩阵为1×1×4 096;再进入散列层进行降维及散列编码,散列层输出code_length维的图像特征(code_length为设置的散列码位数);再进入强相关损失层,利用强相关损失函数计算出当前迭代的损失值;最后返回损失值,根据损失值更新网络参数,驱动模型的训练.
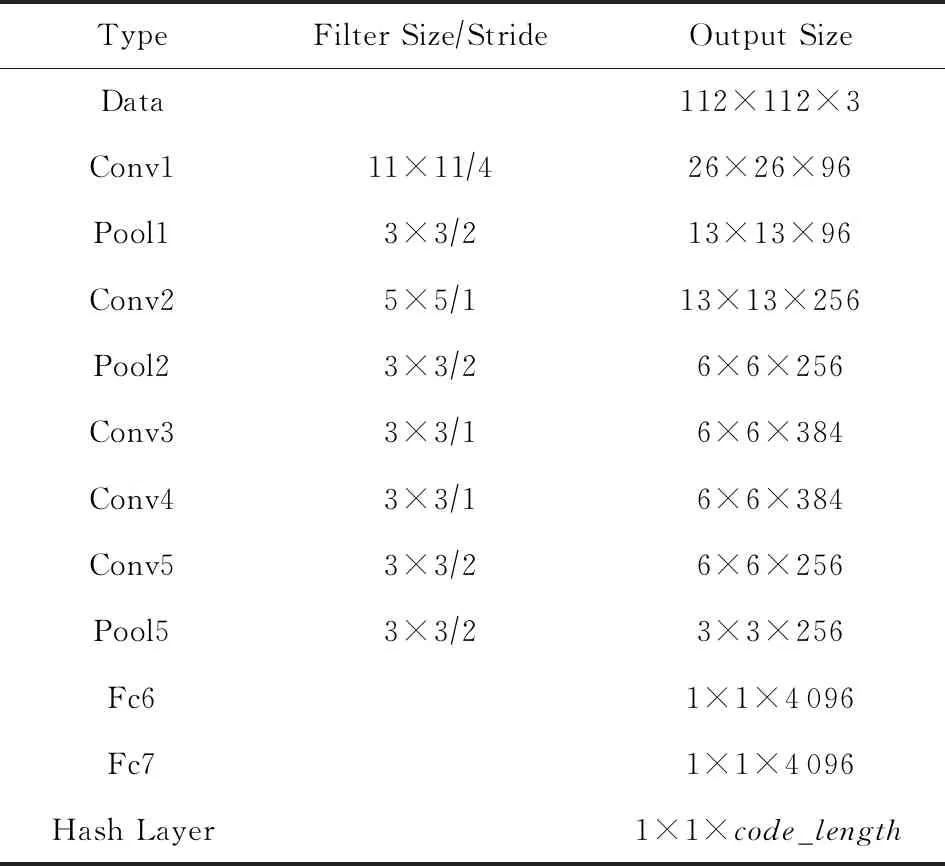
Table 1 Deep Highly Interrelated Hashing Network Structure Based on AlexNet
DHIH模型完成图像检索任务的过程为:通过DHIH模型学习到目标区域的特征表示和相应的散列码;分别输入图像库图像和待检索图像可以得到一个散列码特征库和待检索图像的散列码;再比较待检索图像的散列码与特征库中的散列码之间的汉明距离;将汉明距离按从小到大的顺序排列,然后返回前q个值对应的图像,即为该待检索图像的检索结果.
2.2 散列层
文献[28]成功将卷积层的特征输出复原为原始图像,证明经过卷积、池化、激活等操作后的特征表示仍然保留着图像的原始信息.这些提取到的中层图像特征表示可以直接用于图像分类、检索等计算机视觉任务中,文献[24]完成了大量相关实验.但由于中层图像特征表示的维度太大导致计算开销太大,一般不会使用中层图像特征表示进行计算机视觉任务.本文基于这个思想,为网络结构添加一个散列层.散列层的目的是将高维的中层图像特征表示转换成低维的松弛散列码.局部敏感散列认为相邻的数据在经过随机映射后依然相邻.同样地,DHIH的散列层通过随机映射进行降维,相邻的数据仍然相邻,表示为:
fj(xi)=xiwj,
(1)
其中,散列层的上一层为全连接层7,则散列层的输入为1×1×4 096的特征矩阵,记为xi(i=1,2,…,4 096);wj为权重矩阵,j的取值范围为1,2,…,code_length.再使用sigmoid函数激活特征矩阵,使得特征值属于[0,1],从而得到一个松弛的散列码.sigmoid函数为:
(2)
其中,fj(xi)由式(1)可得.通过散列层可以得到一个松弛的散列码.在2.4节中,松弛的散列码可以转换成完整的二分散列码,我们使用完整的二分散列码进行图像检索.
2.3 强相关损失层
在CNNs中,通过比较模型的输出和目标值,最小化损失值来驱动模型的训练.本文设计了一个强相关损失函数来完成此项任务.该函数能够学习到更具有区分性的特征表示.强相关损失层从散列层接收一个1×1×code_length的特征矩阵,通过强相关损失函数计算得到一个1×1×L(L是类别数)的特征矩阵,再通过交叉熵函数计算损失值.利用得到的损失值进行反向传播,更新模型的参数.为了便于说明本文方法,我们将强相关损失层分为损失层1和损失层2.其中,损失层1是通过强相关损失函数得到1×1×L(L是类别数)的特征矩阵,损失层2是利用损失层1得到的特征矩阵计算损失值.
我们为强相关损失层设计了一个强相关损失函数.假设有样本集G={G1,G2,…,Gn},该样本集只拥有类别1和类别2这2个分类,且每个样本只属于一个类别.存在样本G1,它的所属类别为类别1,则在softmax交叉熵损失函数中有:
G1W1>G1W2,
(3)
则分类正确.其中,W1为类别1对应的权重矩阵,W2为类别2对应的权重矩阵.在强相关损失函数中,我们添加了一个权重相关系数α,式(3)变为
α1G1W1>α2G1W2,
(4)
其中,如能正确分类,则α1>α2.可以通过加大模型学习的难度来迫使网络学习到更具有区分性的特征.因此,增加一个超参数m,取值为正整数.使得式(4)变为
α1G1W1>mα2G1W2,
(5)
此时,我们仍然希望式(5)左边大于右边,因为当且仅当式(5)左边大于右边时,分类正确.通过超参数m的设置使得模型学习难度增加,权重相关系数α使得模型对权重矩阵更为敏感,以此调节特征之间的距离,也就达到了强迫网络学习到更具有区分性特征的目的.
强相关损失层的具体计算过程如下.假定,当前样本的真实标签为i,其他标签为j.强相关损失层的输入为散列层的输出,记为X,X的维度为1×K.X进入损失层1,通过计算得到损失层1的输出矩阵Z,Z的维度为1×L(L是类别数).zi和zj是矩阵Z的元素,zi表示当前样本的真实标签对应的值,zj为其余标签对应的值.如果当前真实标签为0,即i=0时,zi的值为Z的第1个元素.zi和zj可计算为:
(6)
式(6)为强相关损失函数.其中,m和β为超参数,m的取值为正整数,β的取值为0~1,wki和wkj是权重矩阵W的元素,W的维度为K×L,αi和αj为权重相关系数.αi,αj可计算为:
(7)
αi为样本的真实标签对应的值,αj为其余标签对应的值.由式(7)可以看出,权重相关系数α的值取决于当前标签对应的权重值.
通过强相关损失函数式(6),我们得到了损失层1的输出矩阵Z.进入损失层2,通过交叉熵函数计算损失值:
(8)
其中,zi和zj来自Z,由式(6)可得.
以上为强相关损失层的正向传播过程.散列层的输出为X,损失层1的输出为Z,损失层2的输出为损失值.利用强相关损失层得到的损失值能够进行反向传播,驱动网络的训练.
为了能更直观地理解强相关损失函数能够得到更具有区分性的特征,使用数据集为CIFAR-10、散列码位数为48的DHIH模型进行实验,提取模型损失层中的输出矩阵Z进行可视化.图2为Z降维后的特征可视化图.使用t-sne方法进行特征降维并可视化.t-sne方法将一组高维空间的点映射到低维空间,能在一定程度上保持这些点在高维空间的关系,得到的可视化图不能反映簇与簇之间的距离,但是可以反映簇内距离.参数设置为:特征个数为10 000,PCA预处理使得特征维度由10降到5,高斯分布困惑度为40,迭代次数为3 000,学习率为0.01.图2(a)为softmax交叉熵损失函数计算出的特征可视化图;图2(b)为强相关损失函数(β=0.4,m=2)计算出的特征可视化图;图2(c)为强相关损失函数(β=0.7,m=2)计算出的特征可视化图;图2(d)为强相关损失函数(β=0.7,m=3)计算出的特征可视化图.从图2中可以看出,在同样的参数设置下通过强相关损失函数学习到的特征更聚拢,即类内距离更小.
2.4 图像检索
由2.2节可知,我们能在DHIH模型中的散列层得到一个松弛的散列码.在图像检索过程中,根据式(9)将松弛的散列码转换成一个二分散列码:
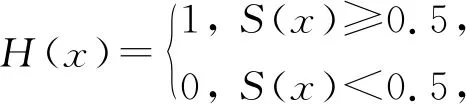
(9)
其中,S(x)由式(2)可得.训练图像通过DHIH模型的散列层得到一个松弛散列码特征库,再将松弛的散列码转换成二分散列码,得到一个二分散列码特征库.同样地,待检索图像通过DHIH模型可得到相应的松弛散列码,再将松弛散列码转换为二分散列码.本文采用汉明距离来衡量待检索图像的二分散列码与特征库中的二分散列码之间的相似度.对这2个散列码进行异或运算,统计结果为1的个数,这个数就是汉明距离D(x,y):
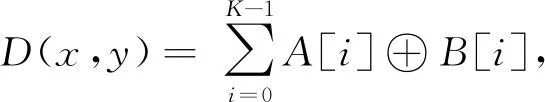
(10)
其中,i=0,1,…,K-1,A和B是2个K位的散列码.
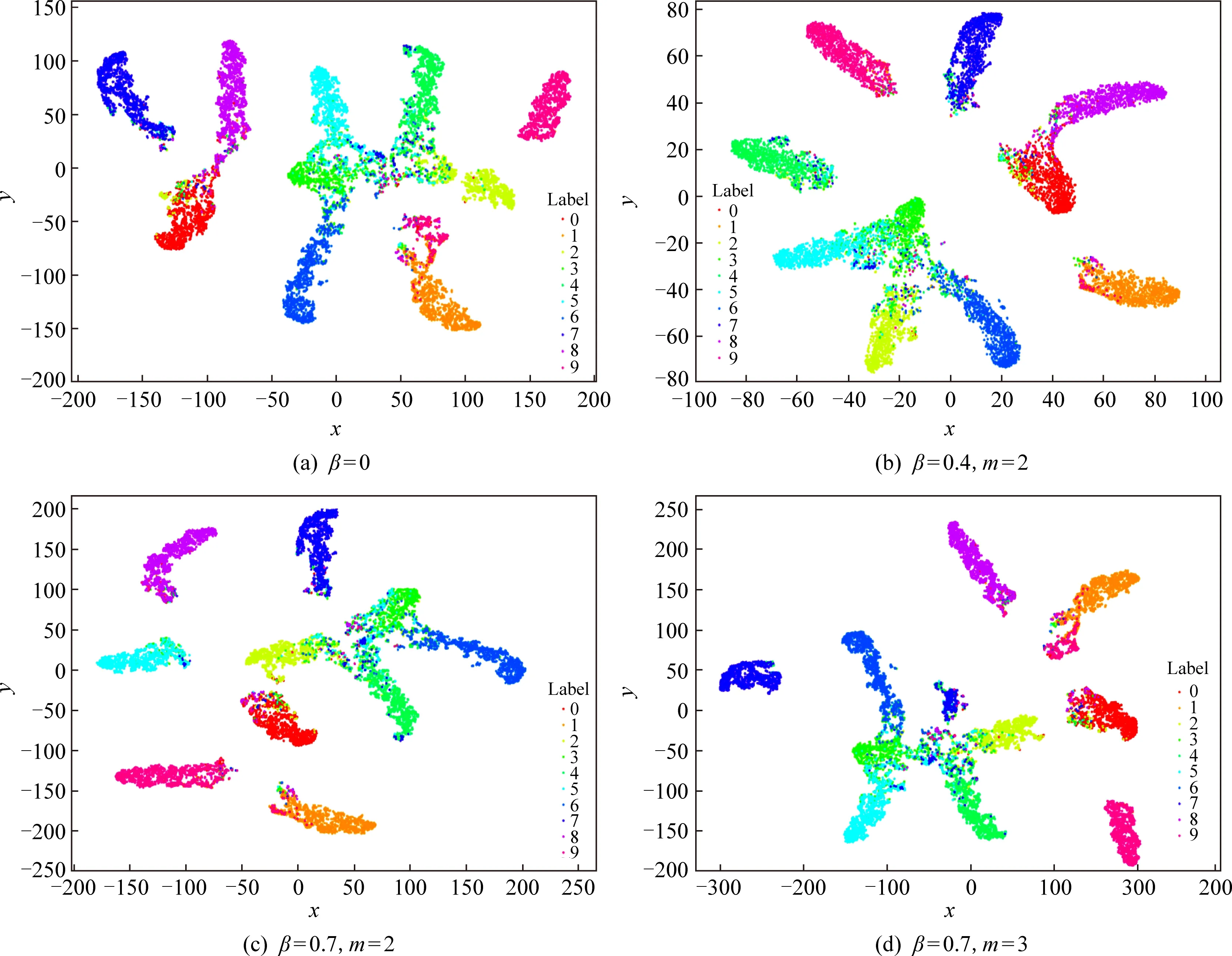
Fig. 2 Visualization on Z based on CIFAR-10 dataset
汉明距离越大,则待检索图像与当前特征库图像之间的差异越大,即相似度低.将汉明距离按从小到大排序,采用最近邻策略选取前q个相似图像返回作为检索结果.
3 优化及实验准备
3.1 优 化
强相关损失函数是一种一元损失函数,本文使用随机梯度下降法来进行优化.与常用的softmax交叉熵损失函数的不同点在于Z值的不同,因此我们可以只计算Z值的前向传播值和反向传播值.式(6)可以化简为:
Z=(1-β)XW+βXW[pmαj-(p-1)αi],
(11)
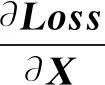
(12)
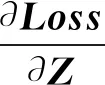
(13)


(14)
(15)
为了简化计算,我们将αi,αj看作一个每次迭代都会更新的参数,即在当前迭代的反向传播过程中,αi,αj是一个与权重无关的具体数值.根据式(14),可化简为
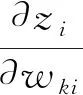
(16)
根据式(15),可化简为
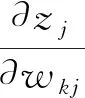
(17)
可以将式(16)与式(17)进行合并,得到:
(18)
化简式(13)得到:
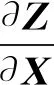
(19)
其中,p的取值为0,1.当Z值为真实标签对应值时,即zi,p=0;当Z值为其他标签对应值时,即zj,p=1.根据式(11)(18)(19)可以计算出强相关损失函数的前向传播值和后向传播值.
3.2 数据集
为了验证本文方法的有效性,我们在3个大规模公开数据集上做了相关实验,分别是CIFAR-10, NUS-WIDE, SVHN.实验部分选取的3个数据集各有特点:CIFAR-10为单标签的自然图像数据集,SVHN为数据量不均衡的单标签数字图像数据集,NUS-WIDE为多标签的自然图像数据集.在这3个数据集上进行实验,可以很好地评估本文方法的性能.
CIFAR-10数据集包含60 000张尺寸为32×32的彩色图像,共有10个类别,每个类别拥有6 000张图像.为了更好地训练模型及评估性能,从每个类别随机抽取1 000张图像作为验证集,再随机抽取1 000张图像作为检索测试集,剩余的4 000张图像作为训练集.NUS-WIDE是一个公开的大规模多标签图像数据集,总共有269 648张图像.该数据集共5 018个标签,每个图像对应1个或多个标签.我们挑选了21个标签及其相关图像195 834张,每个标签都拥有500张图像作为检索测试集.SVHN数据集包含630 420张32×32尺寸的图像,这些图像来自谷歌街景上的房屋门牌数字.该数据集是一个不均衡的图像集.比如,类别“1”包含13 861张图像,而类别“9”仅有4 659张图像.为了节省训练时间,不同于AlexNet需要227×227的输入,我们将3个数据集图像的尺寸均转换成128×128进行训练.
3.3 性能评估
我们采用最广泛使用的检索性能评估方法来比较DHIH与其他方法的检索性能.分别是平均准确率均值、返回最近邻个数-平均准确率均值曲线、模型训练时间以及检索时间.计算公式为:
(20)
(21)
其中,Np为测试集图像的总图像数,Ntp为测试集图像中正确分类的图像数,P为查询结果中正确分类的结果所占的比例,Pa为平均分类准确度,Pm,a为多个测试集的查询结果的平均准确率均值.返回最近邻个数-准确率曲线能反映最近邻个数对准确率的影响,是大规模图像检索的重要性能之一.模型训练时间是模型训练时进行一次迭代所需要的时间,记为training_time,可以反映当前模型的计算开销大小,是大规模图像检索的重要性能之一.检索时间为一张查询图像输入到返回检索结果所用的时间,记为query_time.
4 实 验
4.1 实验环境及参数设置
本文实验的环境配置是:CPU为Intel®CoreTMi7-8750H,GPU为Nvidia GeForce GTX 1060,操作系统为ubuntu16.04,深度学习框架为Caffe,软件平台为Python & Matlab.为了更好地进行对比实验,本文方法与对比方法使用统一的网络结构,如表1所示.模型采用预训练好的AlexNet模型进行迁移学习,使用随机梯度下降法来训练,学习率策略为“inv”,权值衰减量为0.000 5.训练过程中,基础学习率为0.001,训练以gamma=0.1,power=0.75进行迭代下降.
4.2 强相关损失函数有效性验证
在数据集CIFAR-10上进行强相关损失函数的有效性验证实验.使用表1的网络结构训练出模型,选取的散列码位数为48 b,检索返回最近邻个数为100,accurary为训练模型时测试集准确率.如表2所示,当β=0时,当前损失函数为softmax交叉熵损失函数,Pm,a值最低.随着β值的增大,测试集准确率提高,但检索的Pm,a值并没有持续提高.进一步实验发现,β值越大,模型越容易出现过拟合,需要使用较小β值训练出的模型进行迁移学习.通过与softmax交叉熵损失函数进行比较可知,本文方法中的强相关损失函数能够有效地提升模型的检索性能.实验发现,当β=0.7,m=3时,表现出的检索性能最好,与softmax交叉熵损失函数相比Pm,a值提高了近4.1个百分点.所以,我们选用这一组超参数设置进行之后的对比实验,即在4.3节与4.4节的实验中,DHIH模型β=0.7,m=3.
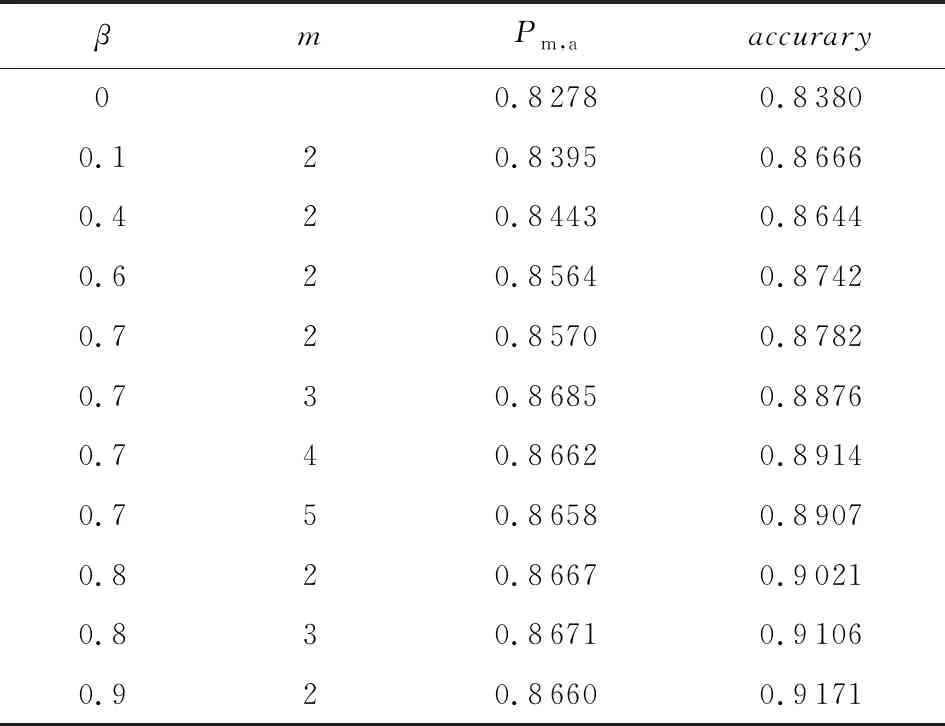
Table 2 Comparison of Retrieval Performance Under Different Hyper-Parameters (top_q=100,code_length=48 b)
4.3 本文方法的普遍适用性验证
为了验证深度强相关散列方法适用于多种卷积神经网络,我们设计了3组实验:第1组实验的网络结构为Vgg16[19]与Resnet50[29];第2组实验的网络结构为Vgg16+Hash与Resnet50+Hash,即在Vgg16与Resnet50的分类器前添加一个散列层,输出的散列码位数设置为48;第3组实验的网络结构为Vgg16+DHIH与Resnet50+DHIH,即为网络添加散列层并将损失层替换为强相关损失层,输出的散列码位数设置为48,β=0.7,m=3.在模型的训练过程中参数与4.1节一致,数据集为CIFAR-10,不采用预训练模型,迭代100 000次后作为当前网络的预训练模型进行微调.特别地,由于Vgg16与Resnet50缺少散列层而不能输出散列码,我们提取Vgg16的第2个全连接层输出矩阵(维度为1×4 096)与Resnet50的最后一个池化层输出矩阵(维度为1×2048)进行检索.检索实验中,top_q=100,除Vgg16与Resnet50使用欧氏距离计算相似度外,其余采用汉明距离计算相似度.
实验结果见表3,其中,code_length为当前输出矩阵的位数;query_time为进行相似度计算并返回前100个对应图像所用时间.由表3可知,为网络结构添加散列层不会过多影响模型的检索准确率,但是能够大幅度地减少检索所需时间.本文方法能够很好地与Vgg16和Resnet50相结合,在提升检索速度的同时Pm,a值也有所提升.实验结果证明,本文方法具有普遍适用性.
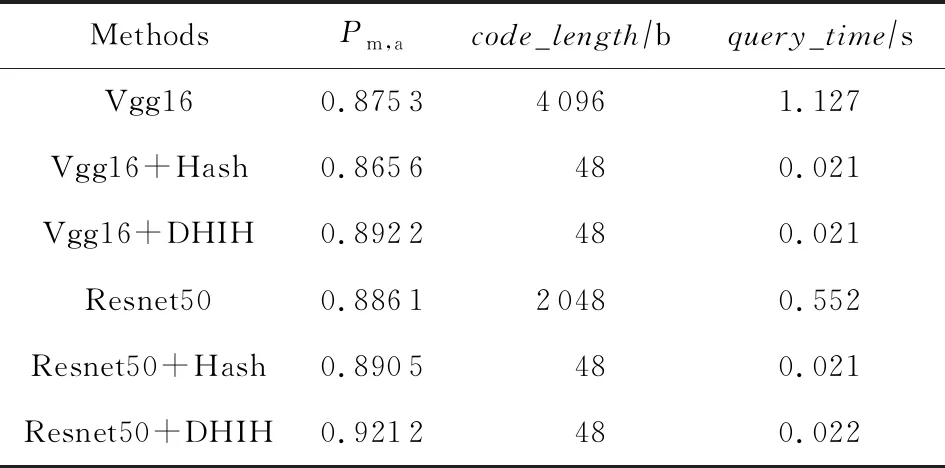
Table 3 Vgg16 and Resnet50 Combined with DHIH (top_q=100)
4.4 模型训练时间对比
DHIH是一种一元深度监督散列学习方法.相对于二元或者三元的深度监督散列学习方法,一元深度监督散列学习方法在训练模型时速度更快、计算开销更小[30],更适用于大规模的图像检索任务中.为了验证DHIH在模型训练时迭代速度更快、计算开销更小,设计了下面一组实验.选用DSH[16]作为对比实验.DSH(deep supervised hashing) 是一种二元的深度监督散列学习方法,主要思想是通过设计损失函数使得最后一个全连接层输出一个类散列码.DSH的损失层需要2个图像输入,设为I1和I2.损失层通过正则化约束I1和I2得到值为1或-1的输出.由于在DSH中,散列码位数过大容易出现过拟合[16],所以在本节的对比实验中,我们选取的散列码位数为12 b.本节实验使用同一网络结构,如表1所示,数据集为CIFAR-10,参数设置与4.1节一致,使用CPU进行训练.
如图3所示,采用同一预训练模型进行迁移学习,迭代次数达到8 000次时,学习率为0.000 648,2个模型的损失值都趋于稳定,模型训练完成.
模型训练时间可以反映出计算开销,即完成一次迭代所需时间越少,说明当前模型的计算开销越小.表4记录了DSH模型与DHIH模型各自的训练时间及Pm,a值.

Fig. 3 Comparison of training loss
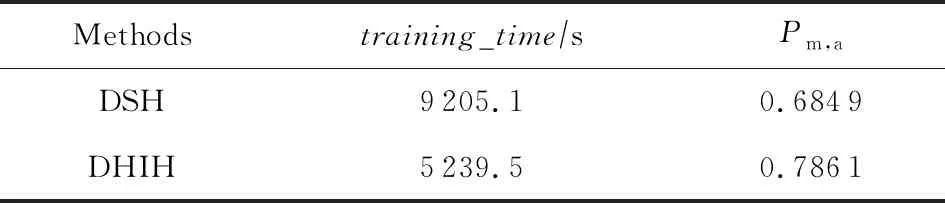
Table 4 Comparison of Training Time and Pm,a Between DHIH and DSH (top_q=100,code_length=12 b)
如表4所示,分别给出了DSH及DHIH两种方法训练平均每迭代1 000次所需时间和迭代8 000次后模型的Pm,a值.可以看到,DHIH的模型训练时间小于DSH,Pm,a值大于DSH.由此可知,本文方法在正确分类及计算速度上具有优势,能够适用于大规模的图像检索任务.
4.5 对比实验结果分析
在本节中,将DHIH与当前检索性能较理想的散列方法做了比较.参与对比实验的方法有:迭代量化散列方法(iterative quantization, ITQ)[30]、局部敏感散列(locality-sensitive hashing, LSH)[31]、基于核函数的监督散列(supervised hashing with kernels, KSH)[24]、特征学习监督散列方法(convolutional neural networks hashing, CNNH)[32]、深度离散散列方法(deep supervised discrete hashing, DSDH)[33]、语义簇一元散列方法(semantic cluster deep hashing, SCDH)[23]、多监督离散散列(discrete hashing with multiple supervision, MSDH)[34]、深度监督散列(DSH)[16].以上方法基于原理被分成2组:Group1 (LSH,ITQ,KSH,MSDH),传统特征提取方法与散列相结合的方法;Group2 (CNNH,DSDH,SCDH,DSH),基于卷积神经网络提取图像特征的方法.
表5给出了本文方法与对比方法在SVHN, CIFAR-10, NUS-WIDE数据集上的Pm,a值对比结果.
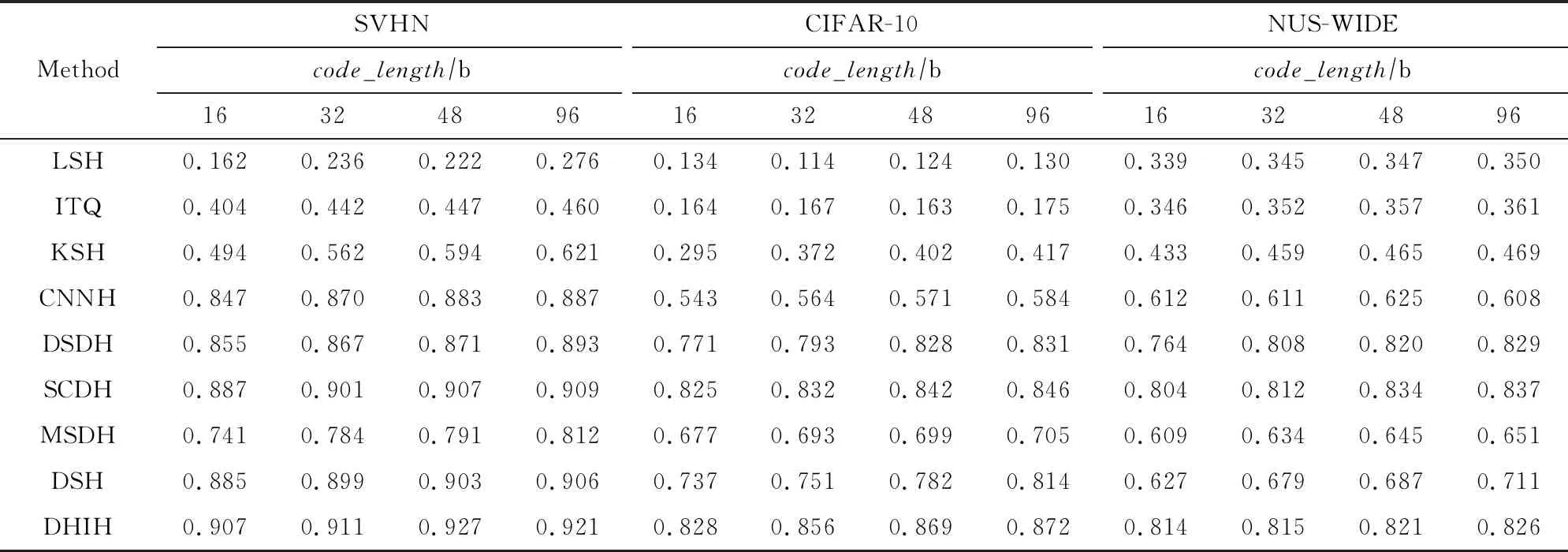
Table 5 Pm,a Comparison of Different Hash Methods
由表5可知:1)本文方法在3个数据集上全都表现优异,各项Pm,a值均大幅领先于Group1中的各方法.说明相比于传统散列方法,DHIH模型能够更好地提取并表示自然图像的特征,从而提高检索性能.2)本文方法在单标签数据集SVHN和CIFAR-10上的各项Pm,a值均优于Group2中的各方法.说明相比现有的深度散列方法,DHIH模型使用标签信息作为监督信息并使用强相关损失函数约束散列码生成,得到了更具有区分性的特征表示.3)面对数据量不均衡的数据集SVHN,本文方法的各项Pm,a值均达到0.9以上.说明DHIH模型中的强相关损失函数能够有效驱动网络去更专注于对少量样本的学习,在面对不均衡数据集时能体现出较好的鲁棒性.4)在多标签数据集NUS-WIDE上,当散列码取16 b和32 b时,本文方法的Pm,a值为各方法中最佳;但在散列码取48 b和96 b时,本文方法的Pm,a值分别低于SCDH方法0.013和0.011.由于SCDH方法在设计损失函数时特别考虑了标签信息,所以一定程度上加强了多标签数据集的学习及检索任务.实验说明DHIH模型在面对多标签数据集学习及检索任务时,性能仍有提升的空间.
图4给出了本文方法与对比方法在其他检索性能上的实验对比.图4是SVHN数据集上的检索性能对比;图5是CIFAR-10数据集上的检索性能对比;图6是NUS-WIDE数据集上的检索性能对比.分别在这3个数据集上比较了Pm,a随散列码位数变化的曲线图及Pm,a值随返回最近邻个数变化的曲线图.其中,在Pm,a随散列码位数变化实验中,固定返回最近邻个数为100.在Pm,a值随返回最近邻个数变化实验中,固定散列码位数分别为32 b,48 b,96 b.由图4~6可知,随着散列码位数的增大,各个方法的Pm,a值都增大.散列码位数越大,散列码包含更多的图像信息,更具有区分性,相应的Pm,a值更大.ITQ, LSH, DSDH方法对返回最近邻个数十分敏感,当返回最近邻个数增加,Pm,a值明显下降,而本文方法对返回最近邻个数具有稳定性.由图4~6可知,本文方法Pm,a值高且对返回最近邻个数具有稳定性,适用于大规模的图像检索.

Fig. 4 Retrieval performance comparison among different models on SVHN
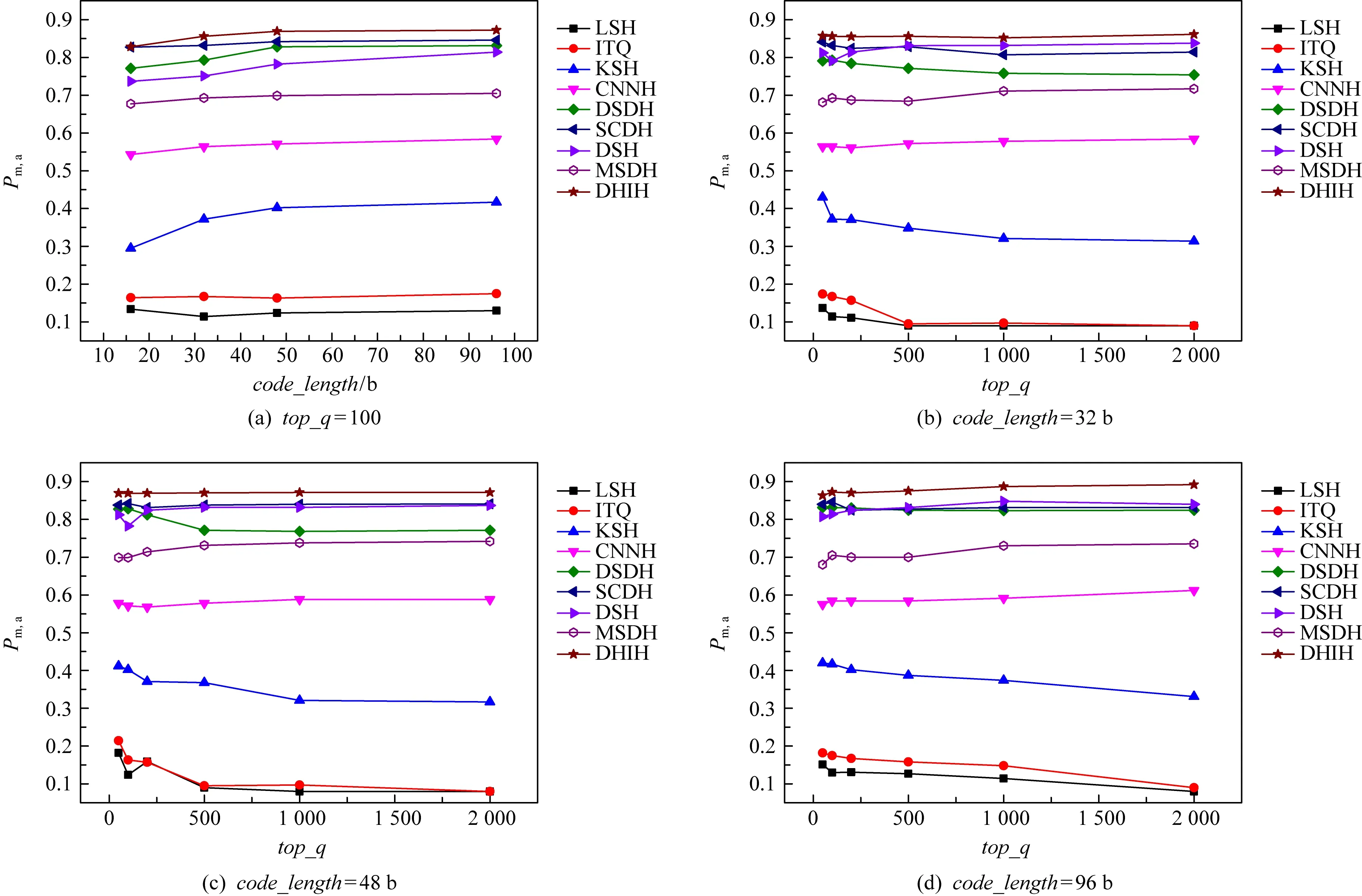
Fig. 5 Retrieval performance comparison among different models on CIFAR-10
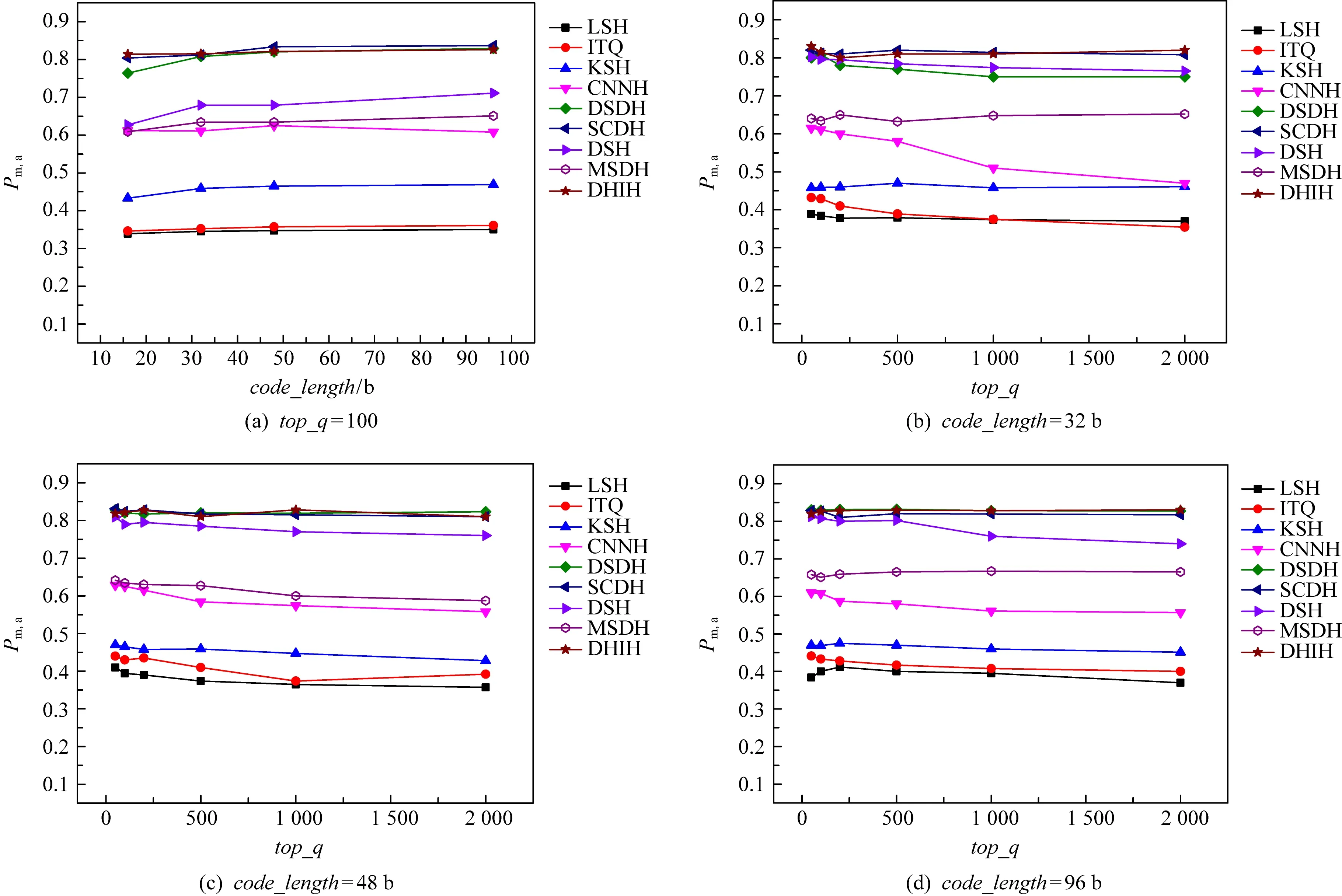
Fig. 6 Retrieval performance comparison among different models on NUS-WIDE
4.6 检索结果
散列码位数不同时对应的Pm,a和检索时间不同.散列码位数越高,汉明距离计算时开销越大,则检索时间越高.为了找出检索效果最好的散列码位数,本文设计了一个性能评估函数用来评估方法的性能:
(22)
其中,Pm,a是不同散列位数对应的平均准确率均值,r为检索时间(query_time).由式(22)计算得到的分数充分考虑到平均准确率均值和检索时间这2个重要的指标.最终得分与检索性能的好坏成正相关,即分数越高,检索性能越好.
本节实验使用的数据集为CIFAR-10,返回最近邻个数为100,超参数设置为β=0.7,m=3进行对比实验.由表6可知,散列码位数与Pm,a值成正相关,与检索时间也成正相关.通过式(22)充分考虑模型的检索性能最终得到,散列码位数为48 b时DHIH模型得分最高.由此得到,48 b的散列码表现出的检索性能最好的.随后的检索实验以散列码位数为48 b进行.
从SVHN, CIFAR-10, NUS-WIDE三个数据集中的检索测试集中随机抽取部分图像进行检索.图7展示了其中的部分检索结果.如图7所示,本文方法能够准确地检索到相似图像.
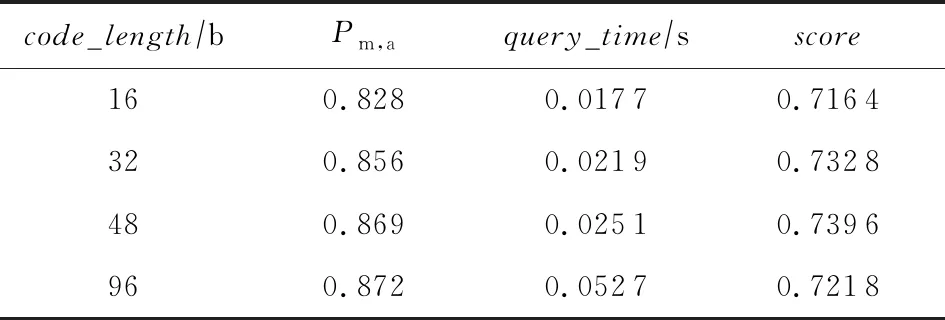
Table 6 Scores in Different Bits (top_q=100)

Fig. 7 Query result
5 总 结
本文提出了一种适用于大规模图像检索的深度强相关散列学习方法.该方法能够广泛地应用在各种卷积神经网络中,具有简单、高效的特点.本文方法的主要工作在于散列码的生成与损失函数的设计.不同于深度监督散列方法中常用的“成对”策略,为了保留散列方法计算开销小的优势,该方法是一种一元深度监督散列方法,使用随机映射产生散列码,再设计强相关损失函数约束散列码的生成.强相关损失函数能够驱使网络学习到更具有区分性的特征.因此,该方法能够快速且准确地检索出相似图像.基于CIFAR-10, NUS-WIDE, SVHN这3个大规模公开数据集的实验结果证明该方法的图像检索性能优于目前主流方法.但该方法还存在一些不足,人为设置了2个超参数,需要进行大量的实验寻找效果最好的超参数设置.在今后的工作中,可以进一步研究超参数的优化方式.
