自动图像标注技术综述
2020-11-10马艳春刘永坚熊盛武唐伶俐
马艳春 刘永坚 解 庆 熊盛武 唐伶俐
(武汉理工大学计算机科学与技术学院 武汉 430070)(mayanchun@whut.edu.cn)
随着计算机软硬件、互联网、大数据及分布式存储等技术的不断成熟和快速发展,图像数据在数量和内容上呈现爆炸式增长.2017年1月中国互联网络信息中心(China Internet Network Information Center, CNNIC)发布的《中国互联网发展状况统计报告》显示,网页中的图片所占比率已达总的多媒体形式的79.63%,以数字图像作为载体也是文化资源数字化的最主要方式.然而,在数字图像数据保持高速增长的同时,人们对图像数据的利用能力却没有随之增强.究其原因,是计算机难以通过图像的低层视觉特征提取出可供人类理解的高层语义信息,低层视觉特征和高层语义特征之间存在“语义鸿沟”的缺陷.这也导致我们在应对大规模图像数据时缺少有效的检索方案,从而难以获取所需信息.
图像自动标注技术是减少“语义鸿沟”的最有效的途径之一,其以图像为研究目标,以知识为研究手段,利用人工智能和模式识别等方法完成对图像内容的语义解释,使计算机系统自动获取图像蕴含的信息内容,从而协助人们完成对图像信息的获取,检索到感兴趣的内容.因此研究图像的自动标注技术和算法,对于帮助人类从海量图像数据中检索兴趣内容,获取所需信息,具有重要现实意义.
在2003年以前,国内外学者对图像自动标注技术的研究仍然处于初级探索阶段,随后广大学者不但加强了对该技术的关注度,同时也取得了一定的研究成果.考察已有研究成果,大部分工作仍是将解决或缩小图像的视觉特征表达与高层语义信息之间的鸿沟问题作为研究重点,主要探索方向为:1)选取鲁棒性强、适应广泛的图像特征;2)建立有效的计算模型;3)设计更加适用的标注算法,使图像标注的上下文信息得到更加充分的利用;4)针对图像本身数据量大、标签空间特征维度高、已有图像标签环境复杂的特点,如何在不影响性能的情况下降低标签空间维度,去除已有图像的标签噪声.到目前为止,对各种已经出现的图像标注模型进行统一分类、梳理的综述性工作仍然相对缺乏,少量的综述性研究工作[1-4]往往存在分类单一、归类模糊以及综合性不强等问题.因此,本文旨在通过深入分析和研究公开发表的图像标注文献,系统归类已有图像标注模型,总结各类模型的优缺点、一般性问题及一般性框架,为后续图像自动标注领域的研究工作提供帮助与思路.
本文的贡献:1)通过研究近20年公开发表的图像标注文献,总结了图像标注模型的一般性框架;并通过该框架结合各种具体工作,分析出在图像标注问题中需要解决的一般性问题.2)对各种图像标注模型按照其主要使用的方法类型进行了归类;对每一类方法类型的图像标注模型,首先进行了基本的原理介绍,然后对该方法类型下的图像标注模型之间的差异进行了具体的分析,最后对每一类方法类型的标注模型做简单总结.3)总结了一些比较著名的标注模型的性能和实验数据,并据此对各种方法类型的标注模型做了优缺点分析.4)总结了图像标注模型常用的一些数据集和评测指标.5)给出了图像标注领域一些开放式问题和研究方向.
1 图像标注的一般问题
图像的自动标注是利用人工智能或模式识别等计算机方法对数字图像的低层视觉特征进行分析,从而对图像打上特定语义标签的一个过程.本文通过对近20年各种图像标注模型(方法)进行深入分析与研究,总结出图像标注模型的通用框架(如图1所示),并依据通用框架中对应的各部分内容,归纳出图像标注技术中存在的一些一般性问题.
如图1所示,图像的标注框架总体可分为3个模块,包括2个特征提取模块和1个标注模型模块.其中,2个特征提取模块表示通过图像的特征提取方法以及词汇(标签)的特征提取方法可分别得到对应的图像低层视觉特征与标注词特征(也称为标签特征).图像的标注模型表示通过需要建立最关键的“图像-标签(I-W)”之间的关联关系,并通过该关联关系和低层视觉特征对未标注图像进行标签预测;同时,更进一步地充分利用“图像-图像(I-I)”、“标签-标签(W-W)”关系对标注模型进行优化,使其得到更加稳健和鲁棒的标注结果.

Fig. 1 General framework of the image annotation model
图像的低层视觉特征提取方法包括全局特征提取方法(如颜色、形状、纹理、直方图等)以及局部特征提取方法(如SIFT(scale invariant feature trans-form)角点、斑点等);词汇的特征提取方法包括“one-hot”以及“word2vec”等.根据标注模型的不同,研究人员往往需要选择不同的特征提取方法使选取的特征能够适应特定的应用场景,从而促进模型性能的提升.由于本文关注的重心在于标注模型本身,因此对特征提取方法不做过多讨论.
图像的标注模型最关键的是需要充分利用低层视觉特征和标注词特征,建立起“图像-图像”、“图像-标签”以及“标签-标签”3种关系.但是由于图像训练集本身存在的固有特点、特征提取算法存在差别以及模型对各种特征的适应性不同,所以标注模型在建立3种关系的同时,还需要考虑7个一般性问题:
1) 标签的不均衡问题.在图像的训练集中,有少部分标签只存在于较少的图像之中,而另外一些标签则出现频率较高,这种标签分布的不均衡有可能会影响模型的精确性.造成这种问题的原因是在制作训练集时,人们往往倾向用更加广泛和一般性的词汇来进行标注,从而导致标签的频率不尽相同.
2) 弱标签问题.这种问题通常在社交领域图像集上出现,即训练集图像中的标注并不能完整地表现图1中反映的所有语义信息,存在标签缺失或错误的情况.产生这种现象的原因是人们在标注时的主观性不同.
3) 特征的高维度问题.从图像中提取的特征往往维度过高,导致模型计算量增加;此外,维度过高也会产生特征的冗余与噪声.
4) 特征内维度不均衡问题.由于标注模型往往需要使用多种低层的图像特征共同作用进行标签预测,而每种特征以及特征内的每一维度对标签预测的贡献程度不一致,影响模型精确性.
5) 特征的选择问题.针对特定标注模型所选取、设计的视觉特征,在其他模型上通常表现较差.因此,在设计新的标注模型时需考虑在多种图像特征之中选取具有更加泛化性能的特征.
6) 3种关系利用不全的问题.由于在“图像-图像”、“图像-标签”以及“标签-标签”3种关系中,只需通过最关键的“图像-标签”间相关关系即可对未标注图像进行标签预测.因此,很多模型忽视了“图像-图像”、“标签-标签”2种关系,影响了标注精度的进一步提升.
7) 标注模型的计算量和运行效率问题.
图像自动标注模型的研究重点基本聚焦于解决上述7个问题,从而使标注结果更加精确、模型运行高效并能适用于更多的应用场景.
2 图像标注模型
图像标注领域自本世纪初进入快速发展时期以来,出现了各种不同的方法和模型,也有学者对各种图像标注模型进行综述性研究.然而,需要说明的是,这些研究工作往往存在分类单一和不够清晰的问题.如文献[1-2]主要以基于内容的图像检索角度进行综述,文献[3]主要以统计方法的角度进行综述,文献[4]虽以相对综合的方式进行综述,但是其对方法的类型和标注问题进行了混合,使得归类不够清晰.本文针对这些问题,将众多的图像标注算法和模型依据其主要使用的方法类型分为相关模型、隐Markov模型、主题模型、矩阵分解模型、近邻模型、基于支持向量机的模型、图模型、典型相关分析模型以及深度学习模型9个大类方法类型,并依次对每种方法类型的图像标注模型进行分析与总结.在每种方法类型的相关小节,首先对共性的原理进行介绍,再分别介绍每一种图像标注模型的差异.
2.1 相关模型
相关模型是图像标注领域受到关注之后最早出现的一类模型,相关模型的代表有TM(translation model)模型[5]、CMRM(cross-media relevance model)模型[6]、CRM(continuous-space relevance model)模型[7]以及MBRM(multiple Bernoulli relevance model)模型[8].其基本思想为:首先将图像分块,假定分块的图像特征和标签之间存在某种特定的概率;然后建立分块图像的特征和标签之间的联合概率密度;最后根据待标注图像的分块信息,求得其针对每个标签的后验概率.
TM模型[5]借鉴了一种词汇翻译模型的思想.词汇翻译模型的原理是:给定一段分别用2种语言翻译过的文档,其在2种语言上的对应关系仅仅在粗粒度(如段落或句子)上已知,而细粒度(如单词与单词)之间的对应关系未知,词汇翻译模型即需要求解这种精确的细粒度的单词与单词之间的对应关系.同理,图像标注问题可类比为:给定了训练集每幅图像以及和其对应的标注词汇,但是细化的图像区域与每个单词之间的对应关系未知,模型即需要求解细粒度的图像区域与单词之间的对应关系.TM模型首先将图像按照分割算法分块,然后用K-means算法对这些块的图像特征进行聚类,每一个聚类称之为1个blob.假定每一个blob对应1个单词,则所有的blob和单词之间存在详细的对应关系,即“probability table”.由于训练集中的图像和标注词汇的对应关系已知,因此,可采用EM(expectation-maximization)算法求解“probability table”.对于待标注图像,先求出其对应的blob,然后根据“pro-bability table”选择具有最高概率值的单词作为该图像的标注.
CMRM模型[6]同样需要先将图像进行分块,然后根据图像块的特征聚类成blob,并假定每副图像I符合一个潜在的概率分布P(·|I).对于图像标注问题来说,假定图像I可以由blob近似表示为{b1,b2,…,bm},单词表示为w,则待求的P(w|I)可以近似地由贝叶斯公式得到:

(1)
针对训练集τ,如果假定w和b1,b2,…,bm相互独立,则P(w,b1,b2,…,bm)可根据全概率公式得到:

(2)
由于训练集为固定大小,所以可认为先验概率P(J)为定值.P(w|J)和P(bi|J)可根据训练集中的统计信息获得:
(3)
(4)
其中,#(w,J)表示某一个单词在图像J中出现的次数(一般来说为0或者1),#(w,τ)表示该单词w在整个训练集τ中出现的次数.#(b,J)表示图像J中被标记为b的blob个数,#(b,τ)表示在整个训练集中被标记为b的blob个数.|τ|为整个训练集的大小,αJ和βJ为平滑因子,控制单词和blob在图像和训练集中的占比.
CRM模型[7]没有像TM模型和CMRM模型采取将图像分块的方法,而是将图像看作很多包含了显著物体的区域{r1,r2,…,rn}叠加的结果.假定1幅图像可以被表示为R=CM×H,每一个区域为一个r,r中的部分像素代表了图像中的某个显著物体,其余部分像素被设置为“透明”,多个区域叠加即构成图像R,词汇{w1,w2,…,wm}用来描述区域{r1,r2,…,rn}.G为映射函数,其功能为将区域r∈R映射成为一个实值特征向量g∈Rk,用来表示区域r的图像特征.则训练集τ中的任一图像J可表示为1组图像区域和标注词汇的组合{RA,WB},其中RA={r1,r2,…,rnA},WB={w1,w2,…,wnB}.{RA,WB}的生成过程可分为3个独立的步骤:
1) 从训练集τ中抽样图像J,图像J在训练集中的先验概率记为Pτ(J);
2) 在PV(·|J)的分布下,依次对WB中的每个单词w进行抽样,其中PV(·|J)表示单词在图像J条件下的概率,其中V代表潜在的概率映射函数;
3) 在PR(·|J)的分布下,依次对RA中的每个区域r进行抽样,其中PR(·|J)表示区域在图像J条件下的概率;
则{RA,WB}的联合概率密度可表示为
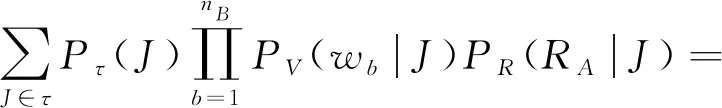
(5)

(6)
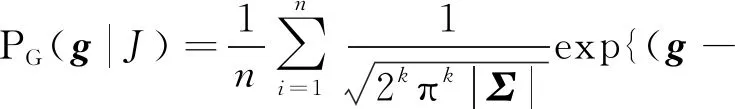
(7)
(8)
Ng是所有可以令G(r)=g的区域的总数,由于无法精确估计因此取某一不依赖于g的常数.Σ表示向量g每一维特征的协方差矩阵,Nw,J代表单词w在WJ中出现的次数,pw是单词w在训练集中出现的频率,w′指图像J中出现的所有单词.
CRM模型直接求取区域与词汇的联合概率密度,而非像TM模型中将单词和图像中分块做一一对应.此外,由于其不需要生成blob,因此不会像TM模型和CMRM模型一样受到聚类算法的影响.最后,由于其直接建模的是连续特征,因此也不会受到特征离散化的干扰.
MBRM模型[8]为基于CRM模型的改进,CRM,TM,CMRM模型都是基于词的多项式分布,而MBRM模型是将词的分布看作为多重伯努利分布.基于词的多重伯努利分布在于解决多项式分布中存在的一个缺点,即在训练集中图像标注词汇长短不一或具有层次结构时会存在索引精度降低的问题.此外,MBRM模型为解决图像分块受聚类算法影响的问题,直接将图像分成固定大小的方块,降低了计算时间,使模型参数更容易估计,更容易关联上下文和模型.MBRM模型对{RA,WB}的联合概率密度可表示为

(9)
在实际标注过程中,WB由于不可能遍历所有词汇组合,因此只选取1个词,然后根据式(10)选取所需词汇数量即可:
(10)
PV(w|J)即为采用的多重伯努利分布:
(11)
其中,Nw代表训练集中标注有单词w的图像个数,N代表训练集图像总数.如果w是J的标注,则δw,J=1否则δw,J=0,μ是平滑参数.
总体来说,相关模型建立了“图像-标签(I-W)”之间的关联关系,但是此类模型标注精度并不高,其主要原因是相关模型需要假定图像中的目标与标注词汇之间存在某种概率分布关系,而由于训练集中的图片数量有限,所建立的概率分布模型往往只能反映特定的训练集,泛化性能不高.此外,模型对图像中的目标需要依赖于分块、分割以及聚类算法的先序处理,其精度、图像中目标的特征构建也会受分块以及聚类算法的影响.从速度方面来看,相关模型的计算也比较复杂,如EM算法需要大量迭代,因此耗时较高.
2.2 隐Markov模型
隐Markov模型(hidden Markov model, HMM)类似于相关模型,同样需要根据图像块和标注词的联合概率密度来求得最终的标注,但不同之处在于隐Markov模型是通过隐Markov链来建立这种相关关系.HMM的代表模型有文献[9-13]等.
HMM模型[9]利用I={i1,i2,…,iT}代表图像中被分割的有序区域,图像区域按照固定个数4×6来进行划分.每一区域的图像特征为d维向量xt∈Rd,{c1,c2,…,cN}代表图像的标注词汇.模型将标注词汇看作是隐Markov链,也即链上的隐含状态st∈{c1,c2,…,cN},xt由潜在的分布函数f(·|st)产生.根据Markov链公式,由有序区域r1={x1,x2,…,xT}和某一有序标注词汇S1={s1,s2,…,sT}组成的联合概率密度可表示为
f(x1,x2,…,xT,s1,s2,…,sT|s0)=
(12)
其中s0认为已知,由于图像的标注词汇是无序的,用最大似然的方法去掉式(12)中标注词汇的序列性即有:
(13)
其中C为所有的词汇序列组合.对未知图像是否标注某一词汇c,可根据贝叶斯公式得到:

(14)

(15)
式(15)为定值,因此

(16)
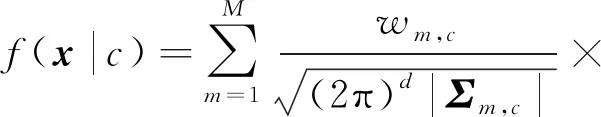
(17)
f(x|c)表示隐Markov模型的混淆矩阵概率,其中wm,c表示权值,μm,c代表在所有词汇V中c所对应的所有区域特征x的均值,Σm,c代表向量x元素间协方差矩阵.
TSVM-HMM(transductive support vector machine based HMM)模型[10]的提出,是为了改善HMM模型中存在的问题,即若训练集中已标注的图像区域过少,会导致对HMM中混合概率密度f(feature|word)估计不准确.TSVM-HMM即基于支持向量机(support vector machine, SVM)的半监督学习方法,首先利用训练集中已标注的图像区域训练一个二分类的SVM分类器,接着根据该分类器对训练集中未标注区域进行分类,将其中最可能的相关区域和非相关区域分别加入到对应的训练集中;然后根据新扩展的训练集重新训练SVM,并重复对未标注区域的分类过程,直到重复次数达到预设的最大迭代次数.最后,由于新扩展的训练集之中,具有更多的已标注图像区域,因此对HMM中混合概率密度的建模也会更加准确.
SHMM(spatial HMM)模型[11]以及SMK(spatial Markov kernels)模型[12]为HMM模型在垂直方向上的扩展,也即对于图像的分块来说,SHMM模型分别考虑了水平和垂直方向前一相邻图像分块对当前图像分块的影响:

(18)
l,m表示图像分块的位置下标,q代表图像分块的状态,⊖可理解为减号,代表在横向或纵向的位置下标做向前移动的操作.
HMM-SVM模型[13]首先分别对颜色和纹理特征用Markov模型进行建模,据此可分别得到基于颜色和纹理特征的对图像分块区域的标注概率,在此过程之后,每个图像分块都可以得到一个二元的预测组{Pcolor,Ptexture},其中Pcolor和Ptexture分别代表某图像块基于颜色和基于纹理特征的预测结果.然后,将此二元预测组{Pcolor,Ptexture}作为中级的图像输入特征,标注单词作为分类结果,训练出多个one-against-all的SVM分类器.最后,根据训练出的SVM分类器对图像进行标注.
基于HMM的模型用一种很自然的方式建模了每个单词和图像特征之间的关系f(feature|word),也即“图像-标签(I-W)”之间的关联关系,从可解释性上提供了有效的推导过程;而且相较于相关模型,基于HMM的模型更关注抽象信息,如对整个语料库来说,仅保留了如均值和方差等图像的高层次特征,因此模型计算效率较高.然而基于HMM的模型也继承了Markov模型的固有缺陷,即在给定的标注词条件下,图像的特征是条件独立的,没有利用图像内容上的相关性,并且对于“标签-标签(W-W)”与“图像-图像(I-I)”特征之间所存在的复杂语义关系,仅通过混合矩阵进行建模也不够精确.
2.3 主题模型
LSA(latent semantic analysis)模型是主题建模的基础,其最早的用途是对文档进行检索[14],它的核心思想是把对应的“文档-项”矩阵分解成相互独立的“文档-主题”矩阵和“主题-项”矩阵,从而在隐藏的主题空间建立文档和词汇之间的语义关系.在文档检索领域,“项”即对应检索词汇.在图像标注领域,LSA模型将图像作为一个独立的文档,标注词汇或者视觉特征等被定义为“项”.假定“文档-项”矩阵表示为A∈RN×M,N为文档的数量,M为项的数量,则矩阵A可通过奇异值分解(singular value decomposition, SVD)为
A≈USVT,
(19)
其中U∈RN×K,S∈RK×K,V∈RM×K,K表示降维后的主题空间维度,U的每一行代表训练集图像在主题空间中的特征表示,该主题空间(也称为隐语义空间)可表示“项”之间的语义关联关系.当利用训练集图像求解U与V之后,对未标注图像q∈R1×M来说,可先将其映射至主题空间

(20)

对LSA模型的改进一般集中在对“文档-项”矩阵中“项”的表征方面.如文献[15]首先将图像划分为上、中、下3个区域,然后通过图像的标注词以及每个区域的RGB颜色直方图、区域号和区域坐标串联起来,形成的向量表征“文档-项”矩阵中“项”.
文献[16]将图像视觉特征和标注词汇特征融合的结果作为“文档-项(document-term)”矩阵中的“项”.对于每幅图像中的视觉特征,其采用了一种视觉词袋(bag of words, BOW)的模型进行构建.首先对每幅图像按矩形栅格以及分割算法分块,同时求出每幅图像的角点;然后,串联每个图像块的质心位置、RGB直方图、Gabor系数以及每个角点的SIFT特征[17]作为图像的视觉特征;之后再用K-means聚类算法将图像集中所有的视觉特征聚类为k个簇,每幅训练图像即可根据其视觉特征在聚类簇中出现的次数离散化为一种“次数向量”作为该图像的“视觉项”;最后,训练集中所有图像即可形成新的“文档-视觉项”矩阵Md,v.对于每幅图像中标注词汇的特征,其采用向量空间模型(vector space model, VSM)进行构建,也即获得其词频以及逆文档词频作为“词汇项”,从而使训练集中所有图像形成新的“文档-词汇项”矩阵Md,t.在Md,v与Md,t获取之后,根据原始标注图像视觉特征与标注词汇之间的对应关系获取“视觉项”与“词汇项”的互相关矩阵Mt,v,之后即可将Mt,v降维到主题空间,尽管取得了一定的成功,基于SVD的LSA仍然存在计算量较大的缺点,而且从概率的意义上也缺乏可解释性.
PLSA(probabilistic latent semantic analysis)模型[18]是一种在概率意义上具有可解释性的主题模型.模型假定主题zk为基于“文档”和“项”的生成模型中存在的一个隐藏主题空间中的元素,“文档”与“项”之间相互独立.则包含有“文档-项-主题”三者的联合概率密度可表示为
P(xj,zk,di)=P(di)P(zk|di)P(xj|zk),
(21)
其中,x,z,d分别代表“项”、“主题”与“文档”,i,j,k分别为其对应的索引.通过求解z的边缘概率密度即可求得“文档-项”的联合概率密度:
(22)
类似于相关模型,这里P(di)代表某文档在整个训练集中的占比,P(z|d)和P(x|z)分别代表选定文档包含某一主题的概率以及选定主题包含某一“项”的概率,在训练阶段,可根据训练集由EM算法求解.在图像标注领域,P(di)表示图像在训练集中的占比,“项”x可表示普通变量,也可表示特征向量,其物理含义根据各种模型变体略有不同.如文献[15]中的PLSA-MIXED模型,串联单词特征与视觉特征形成x=(word,visual).在测试阶段,对于未标注图像,则将其标注部分置0为xnew=(0,visualnew),然后根据folding-in算法[18]求得其P(z|dnew),从而进一步得到P(x|dnew),图像的标注P(word|dnew)即可从P(x|dnew)抽取得到.对PLSA模型的改进大多集中在对多种模态的利用方式上以及多种图像视觉特征的使用方式层面.如文献[19-20]中的PLSA-WORD模型,将图像与标注词汇视为2种不对等模态,通过不对称的学习算法从标注词汇的数据中学习一个潜在的空间,并将其关联到视觉模态,从而改进了PLSA-MIXED模型中将标注词汇与图像视觉特征2种模态视为同等重要的缺陷,也即改善了标注词汇数量和图像视觉特征数量之间的不平衡问题.文献[21]提出的PLSA-FUSION模型和文献[22]提出的MM-PLSA(multilayer multimodal PLSA)模型在PLSA-WORD模型基础上进一步使用2组潜在主题分别从标注词汇和图像视觉特征2种模态中学习,然后再融合为一个共同的潜在空间.其中,PLSA-FUSION模型采用了一种自适应的动态方法进行学习,根据每幅图像各自的视觉词分布确定各不相同的权值对2组主题进行融合;MM-PLSA模型将标注词汇和图像视觉特征的2种模态学习到的主题作为2片叶子,再通过1个顶层的PLSA根节点构建1个多层次的主题空间树,进而对2组主题进行融合.文献[23]提出的MF-PLSA(multi-feature PLSA)模型在原始模型基础上采用了多特征组合而非融合的方式进行改进,其将图像的SIFT[17]特征v和局部变换颜色直方图特征(local transformed color histogram, LTCH)w分别作为条件独立于主题z的变量,从而求得图像视觉特征(SIFT和LTCH)与文档d的联合概率密度变为
(23)
其中N(w,v,d)代表(w,v,d)的共现次数.
主题模型最早用于对文档的检索,解决了检索问题中的“一词多义”以及“一义多词”问题.在图像标注领域,主题模型同样通过构建隐藏的主题空间,使得具有语义相似度的模态能够映射到同一主题,或者同一主题可被多种模态所表示.因此,隐藏的主题空间能够较好地建立起图像底层视觉特征同自然语义之间的联系,也即“图像-标签(I-W)”之间的关联关系.但由于主题模型依然是通过选取训练集图像中相应的底层视觉特征和标注词汇来进行概率运算,因此其概率分布难以有效描述样本外的情况,泛化性能不高.对于选取何种底层视觉特征、标注词汇特征,以及对特征的融合利用也是主题模型需要解决的难题.此外,主题模型中需用到SVD分解以及EM算法等,都需要耗费大量时间以及运算资源.
2.4 矩阵分解模型
基于矩阵分解的图像标注通过矩阵分解的方式来建立图像、标签等之间的相关关系.本文归类于主题模型中的LSA模型,通过SVD分解的方式建立隐语义空间,因此也可归类于矩阵分解模型,但由于其分解之后的物理意义更偏重隐藏的语义主题,因此本文将其归类于主题模型.
另一类矩阵分解如非负矩阵分解(nonnegative matrix factorization, NMF)模型最初是用来做人脸识别任务[24],其核心思想是将图像的特征矩阵V分解为2个非负的矩阵因子W和H:
V≈WH,
s.t. ∀Wi,j,Hi,j≥0,
(24)
其中,W代表特征在新的空间形成的基,H可代表某样本在基W下的坐标,因此如果将W形成的空间看做新的语义空间,则H·,j可代表样本在语义空间下的特征表示,因此基于NMF的图像标注模型关键在于寻找可靠的矩阵分解因子W和H.基于矩阵分解的图像标注模型代表有文献[25-30]等.
文献[25]类似于文献[16],首先利用SIFT特征建立的视觉词项作为图像特征.接着,对于训练集所有图像来说,根据图像特征即可构建“视觉词汇-文档”矩阵V,对V做非负矩阵分解V≈WH.由于H可视为样本在语义空间下的特征,则对于未标注图像的语义特征,可通过hquery=W-1q求得,其中q为图像的原始特征.然后,通过cos距离计算,得到其在语义空间中的近邻图像.最后,将最近邻的图像标签扩散至未标注图像.

文献[27]提出了一种松散的联合框架,同时对图像的视觉特征和词汇特征进行非负矩阵分解.如式(25)所示,统一空间中视觉模式和词汇模式之间的相似性越高,则其距离越近:

(25)
其中,V和T分别代表图像的视觉特征和词汇特征.α1,α2,α3分别代表正则化系数,ΔH=H1-λH2则用来控制统一空间视觉模式和词汇模式之间的相似性.
文献[28]在文献[27]的基础上,进一步将所有的视觉特征种类包括词汇特征都视为一种视图(view).在同一框架中:1)对每种视图同时做非负矩阵分解;2)同时降低所有视图在统一空间的相互距离;3)对所有视图做拉普拉斯正则化操作.融合3种操作即可得到优化目标:
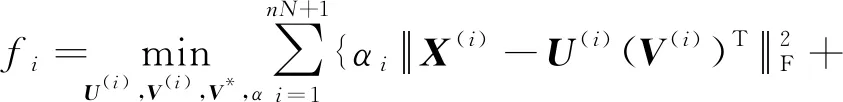
(26)
其中,n为训练集样本个数,N为视觉特征个数,+1代表将词汇特征也作为一种视图,Q用来控制在统一空间中模式之间的相似性,L表示拉普拉斯正则化约束.
传统的NMF模型通过非负矩阵分解求得新的特征基之后,往往还需要额外的分类步骤对未标注图像进行标注,导致效率低下.文献[29]针对此问题,提出了一个可以同时进行矩阵分解和分类步骤的框架.具体来说,对图像的特征矩阵F进行非负矩阵分解F≈WH,但有别于传统NMF模型,该模型将H视为图像的近似标签矩阵,用来决策某一图像是否属于标签i.因此,H应当与图像原始标签矩阵L具有一致性.据此可得优化目标式为

(27)
其中D用来度量H和原始标签矩阵L的相似性.
文献[30]提出了一种具有结构化信息的NMF模型,其核心思想是具有相同标签的图像特征经分解过后应该处在相同的子空间中,也即分解过后的图像特征矩阵应当具有对角的块状结构.假定V为分解过后的特征矩阵,为了保持V的块状结构,模型定义了指示矩阵I:
(28)
其中C表示标签的个数,并以指示矩阵I定义最小化正则化项(式):
(29)
其中⊙表示矩阵元素的对应相乘运算.因此,模型总的优化目标可被定义为
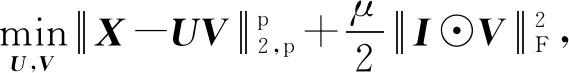
(30)
由于分解过后的特征矩阵V中每个块结构对应一个标签类别,因此特征具有较强的判别能力,更容易区分不同标签类别的图像.
文献[31-32]采用了多层次矩阵分解的方法建立图像视觉特征、标签特征以及其相关关系.文献[31]假定X表示图像的视觉特征矩阵,F表示标签矩阵,则:
(31)
通过多层次的矩阵分解,将F与X统一到一个潜在的语义空间,也即第M层.Wm(m=1,2,…,M)表示第m层的变换矩阵,V表示潜在的标签特征矩阵,Um表示第m层的图像特征矩阵.其目标函数(式(32))类似于传统的NMF模型:

(32)
其中后2项分别代表正则化操作.文献[32]在文献[31]的基础上,进一步对UM-1,U,V增加了拉普拉斯约束,如式(33)所示,使潜在语义空间中的特征矩阵以及标签矩阵具有更好的聚类特性.
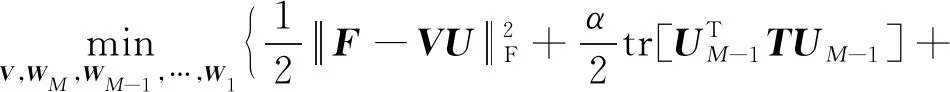
(33)
其中,rm表示第m层矩阵分解的节点个数.
此外,还有其他的矩阵分解模型如文献[33]提出了一种多模态的概率矩阵分解(probabilistic matrix factorization, PMF)模型用来建立“特征-标签”、“特征-特征”以及“标签-标签”之间的相关关系,然后通过分解得到的代表潜在语义空间的矩阵因子来连接3种相关关系.文献[34]采用弱监督的方法使隐语义空间中“标签相似矩阵”和“特征相似矩阵”与原始空间中的“标签相似矩阵”和“特征相似矩阵”相似度最小,文献[35]通过低秩矩阵分解来寻找更加本质和符合感官“特征-标签”矩阵.
矩阵分解模型如NMF可以很好地表征图像的局部特征,从直观上来说,图像总体是由各局部特征叠加而成,因此具有很好的解释性.此外,矩阵分解模型对于标签具有噪声和缺失的情况具有较高的鲁棒性.然而,如何选取合适的矩阵分解因子中的隐语义空间维度,以及如何有效、快速求解由矩阵分解转化而来的优化目标,仍然是矩阵分解模型面临的问题.
2.5 近邻模型
近邻模型在图像标注模型中思想比较简单,其基本原理是具有相似低层视觉特征的图像应该具有相似的语义.因此,利用近邻模型进行图像标注的一般步骤为:1)构建图像低层视觉特征;2)通过对低层视觉特征采用某种距离度量策略,选择与待标注图像距离较近的已标注图像;3)通过合适的标签扩散方法将已标注图像中的标签应用到待标注图像.相应地,对近邻模型的改进也基本集中在:1)选取或构造更适合用来标签扩散的视觉特征;2)采取更合适的距离度量策略,使图像集中视觉特征的距离远近符合语义空间上的距离远近;3)采用更加优化的标签扩散算法使标签能够良好扩散.近邻模型的代表模型有JEC(joint equal contribution)模型[36]、TagProp(tag propagation)模型[37]、2PKNN(2-passk-nearest neighbor)模型[38]、VS-KNN(visual semantic KNN)模型[39]、SNLWL(semantic neighborhood learning for weakly label)模型[40]、SEM(semantic extension model)模型[41]、weight-KNN(weight KNN)模型[42]、AWD-IKNN(adaptive weighted distance method based on improved KNN)模型[43]、NMF-KNN模型[44]、AL(active learning)模型[45]等.

TagProp模型[37]为了解决近邻图像之间权值不均衡以及各种视觉特征之间权值不均衡的问题,提出了一种加权的近邻模型.即假定单词w出现在图像i的预测值p(yi,w=+1)(+1-1表示标签是否存在)可由所有近邻图像j对i的条件预测值加权得到:
(34)
从而进一步求得对数似然函数L:
(35)
其中,ci,w即为近邻图像间权值,用来解决某一标签对应的负样本远大于正样本的问题,也即对某一单词,不包含该单词的图像个数要远大于包含该单词的图像个数所带来的不均衡问题.其中,若yi,w=+1,则令ci,w=1n+;若yi,w=-1,则令ci,w=1n-,n+和n-分别代表正负样本个数.对于各种视觉特征之间权值不均衡的问题,TagProp模型定义πi,j为
(36)
从而使得πi,j可以根据图像j依据到图像i的距离而衰减,W表示每种视觉特征的权值向量,di,j表示图像i和图像j各种视觉特征的基础距离所构成的向量.此外,为解决标签不平衡问题,也即使用频率较少的标签召回率低的问题,该模型利用sigmoid函数改进对图像i的预测:
p(yi,c=+1)=σ(αwxi,w+βw),
(37)
使得相对稀少的标签权重增强,而减弱出现频率较高的标签权重.其中sigmoid函数σ(z)=(1+exp(-z))-1.
2PKNN模型[38,46]为解决标签的不平衡问题,采取了一种语义近邻组的方式来构建图像的近邻集合.假定将训练集中每个标签yi看作为一个分类,则训练集τ可被划分为l个“标签-图像”对,即τ={(τ1,y1),(τ2,y2),…,(τl,yl)},其中l代表标签个数,τi表示标签yi对应的图像集合,每一个集合τi称之为一个语义组.给定未标注图像J,从每个语义组中选择K1个视觉相似的近邻构成新的集合τJ.由此方式构建的近邻集合τJ,每个标签在其中至少会出现K1次,因此解决了标签不平衡的问题.根据近邻集合τJ可以定义未标注图像J对于标签yk∈Y的后验概率:

(38)
其中,如果标签yk属于某一近邻图像Ii的标签集合Yi,则δ(yk∈Yi)=1,否则δ(yk∈Yi)=0.exp(-D(J,Ii))表示基于近邻图像间视觉特征的距离对于后验概率的贡献.为了解决各种视觉特征之间以及特征向量内部的不均衡问题,2PKNN为视觉特征距离D(A,B)分别定义了距离空间权值w以及特征空间权值v:
(39)
n为视觉特征的个数,Ni为对应视觉特征的维度,di,j(A,B)表示对应视觉特征的基础距离.然后,根据组间最大、组内最小的原则定义LOSS函数,并采用随机梯度下降求解参数.在P(J|yk)求解之后,最后可根据贝叶斯公式求解后验概率:
(40)
其中先验概率P(yk)和P(J)可认为是定值.
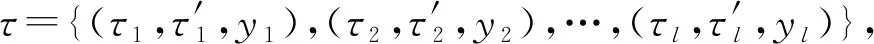
S(xj,xk)=αD(xj,xk)+(1-α)dis(xj,xk),
(41)
其中xj表示某一标签的语义近邻组内的图片,xk表示该标签对应的语义近邻组外的图片,α表示平滑参数,D和dis分别表示图像的视觉特征距离和标签距离.根据式(41)求得每一个近邻组内图片K2个近邻组外的邻居,再求并集即可得到对应次近邻图像集合τ′.
SNLWL模型[40]构建语义近邻的方式类似于2PKNN模型[38,46],但是为了解决弱标签和标签不平衡问题,通过在构建语义近邻组之前求解其定义的学习误差函数(如式(42))来平衡训练集样本标签,进而使低频标签可以更有效地参与标注.
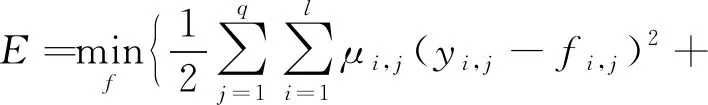
(42)

SEM模型[41]和weight-KNN模型[42]针对传统模型需要手动设计视觉特征并且视觉特征性能泛化程度不高的问题,采用了从预训练的经典深度学习模型中抽取特征的方法来构建具有更泛化的视觉特征,此外,weight-KNN模型为了解决视觉特征元素之间的不平衡问题以及充分利用标签之间的相关信息,采用了一种多标签线性判别(multiple linear discriminant analysis, MLDA)方法[47],在KNN的距离计算中给元素赋值适当的权重W.假定图像的每个标签为1个类别,则权重W需要满足条件使得类内距离最近、类间距离最远.因此,根据MLDA方法可定义目标函数为
(43)
其中,类内散布矩阵Sb、类间散布矩阵Sw以及总散布矩阵St分别定义为
(44)
K和k分别为标签个数和索引,N和Nk分别为训练集图像数目和第k个标签对应的图像数目,mk和m分别代表第k个标签对应图像的特征向量均值和总的图像特征向量均值,fi表示第i幅图像的特征向量.对于标签之间相关信息的利用,weight-KNN模型重定义了标签矩阵L:
L=YC,
(45)
其中,Y为原始标签矩阵,C∈RK×K代表标签之间的相关关系矩阵,元素Ck,l表示任意第k个和第l个标签之间的相关性:
(46)
将包含有标签关系的新标签矩阵引入之后可得到新的散布矩阵为
(47)
Sw=St-Sb,

AWD-IKNN模型[43]集成了图像的CNN(con-volutional neural networks)特征与传统视觉特征,并且针对标签的不平衡问题设计了一种加权模型(如式(48)):

(48)
D(i,j)表示图像i和j之间的视觉特征距离,Ω1和Ω2分别表示图像i和图像j对应的标签集合,W(l,k)表示在对应图像中,针对第k种特征,标签l对应的权值,N为图像特征数目,dk(xi,k,xj,k)为第k种特征的基础距离.由式(48)可知,如果2个图像之间存在共同的标签,则该标签的权重将被重复计算,也即表明这些标签的相应特征在图像之间的距离运算中权重更大.所有标签都会被同等对待即使某些标签出现频率较小,如果2个图像有相同标签,则2个图像之间的距离会更短,从而解决标签不平衡的问题.根据正样本(具有相同标签的图像)间距最小、负样本间距最大的原则来定义LOSS函数:
(49)

NMF-KNN模型[44]借鉴了NMF多视图聚类[48]的思想,将每一种视觉特征以及图像的标签特征视作为一种视图(view).训练集所有图像针对任意一种特征都可构成特征矩阵X(f),X(f)可通过NMF分解成为1组由基U(f)和系数相关表达式V(f)组成的矩阵.在NMF分解之后,系数表达式V(f)应当与潜在的表达空间V*有近似的语义.由此,可定义LOSS函数为
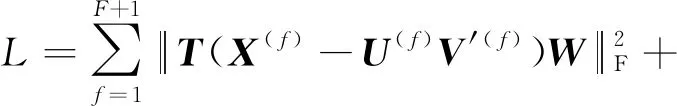
s.t. ∀1≤f≤F+1,U(f),V(f),V*≥0,
(50)

AL模型[45]类似于2PKNN模型,仍然采取了语义近邻组的方法来避免标签不平衡问题;此外,与传统方法[36-38]选择固定数量的近邻数量有所不同,AL模型采取了一种动态阈值的方法选取近邻图像.其中阈值定义为
τ=Sm-ε,
(51)
其中,Sm为图像视觉特征相似度均值,ε为控制召回率大小的容忍值参数.
此外,还有其他的基于KNN的图像标注模型,如文献[49]定义了一个最优化的框架,分别集成了标签集合与图像之间的相关关系以及图像集合之间的相关关系2种因素,用以提高标注精度.文献[50]采用了SIFT以及SURF(speeded up robust features)的图像局部特征进行单标签图像分类.文献[51]在JEC模型基础上增加了一种标签过滤机制,用以去除大部分图像中不相关标签,从而提高标注的精度.文献[52]进一步将近邻图像划分为强相关图像近邻与弱相关图像近邻,同时提出了基于范围约束视觉邻域的标签相关随机搜索方法,可以找出每个候选标签的可信部分,从而增强注释性能的鲁棒性.
近邻模型的基础思想相对比较简单,通常聚焦于解决图像标注的一般性问题(如弱标签、标签不平衡、特征的选取与权值赋值等),并且与其他方法的结合也比较灵活.由于其标注效果相对较好,近年来得到了广泛的研究和应用.近邻模型由于需要与训练集中的图片进行轮询对比,因此只适用于较小或中型的数据集,在面对超大规模数据集时往往耗时较长.
2.6 基于SVM的模型
SVM是专门用于解决二分类问题的分类器,而图像的标注问题可被视为图像的多分类问题.因此,最基本的基于SVM的图像标注模型[53]是通过训练多个SVM分类器并采取一定的策略结合多个分类器的结果来完成分类.常用的2种策略包括“one-against-all”和“one-against-one”2种,假定将每个标签作为1个类别,“one-against-all”策略是对每个标签训练1个“本标签相对于其他标签”的SVM,每个SVM分类器都会定义1个判别函数fi用来区分某一图像是否属于标签i或属于其他标签,多分类器的输出即为具有最大输出的判别函数fi所对应的标签类别.最常用的判别函数可表示为
(52)
其中,x表示图像的视觉特征,wi和bi分别表示为第i个标签所对应SVM分类器的权值和偏置.对待标注图像的标注为:
(53)
其中K表示标签个数.
“one-against-one”策略是对任意2个标签都训练1个SVM.然后对未标注图像的分类结果进行投票,投票最多的标签即认为是图像标签.
文献[54]结合了多实例学习的方法,针对图像的“包特征(bag-features)”与全局特征分别构建2类SVM,并针对2类SVM的分类结果进行融合得到最终的标注结果.假定依据“包特征”所构建SVM的输出作为概率向量表示为pm,依据全局特征所构建SVM的输出作为概率向量表示为pg,则融合2类SVM的最终概率向量p可表示为
p=w⊙pm+(1-w)⊙pg,
(54)
其中⊙表示对应元素相乘,概率向量的长度与标签个数相同,概率向量pm与pg的每个元素表示图像属于某一标签的概率.w表示对应的权值,可以通过“包特征”和“全局特征”分别对应的权值向量wm与wg进行估计:
(55)
其中除法表示为对应元素相除.wm,wg中的元素可通过式(56)进行估计:
(56)
其中Lm(n,c)与Lg(n,c)分别表示图像n依据“包特征”属于标签c的概率和依据“全局特征”属于标签c的概率.
文献[55]为改善传统SVM在训练过程中因约束过强导致过拟合的问题,提出了一种松弛的SVM分类方法,允许有少量样本不受约束;同时为了更好地利用标签与图像特征的一致性,在框架中增加了对标签特征和图像特征的拉普拉斯约束,如式(57)的后2项.其标注框架的总体目标函数可表示为:

(57)


(58)
此外,还有文献[57]对SVM的分类输出通过标签关系矩阵重新加权作为标注结果;文献[58]通过为生成模型和SVM分类输出设置不同的权重,用来作为标注结果.
由于SVM专门用于解决二分类问题,因此大多基于SVM的语义标注模型也继承了SVM的缺点,在标注词(也意味着分类个数)较多时,需要训练大量的分类器,因此模型在训练阶段的速度往往比较低下.此外,由于SVM模型本身的构建方式比较固定,对性能的提升主要集中在选取更加泛化和鲁棒的特征之上,而对图像标注的一般性问题如标签不平衡、弱标签、特征的权值赋值以及对“图像-图像(I-I)”、“标签-标签(W-W)”之间的关系利用等,难以融合其他方法进行有效解决.
2.7 图模型
图模型的基本思想是通过图来集成样本间的相似关系,包括样本间视觉特征之间的相似性、标签特征之间的相似性以及视觉特征和标签特征的对应关系,然后再利用相关的图论技术建立图结构中样本以及各种特征的关联模型,从而对标签进行预测.因此,大多基于图的标注模型的区别在于图的构建方式以及选择的图论技术存在差别.描述基于图的图像标注模型的代表文献有[59-72]等.
文献[59]首先利用分割算法将图像分块,提取每个图像块的视觉特征.构建图的时候,将图像的视觉特征和标签特征统一视为图的节点,并将这些节点分为3层.其中,作为视觉特征的节点为1层,图像节点作为1层,标签特征作为1层,视觉特征节点和标签特征节点作为图像节点的属性节点.将图像节点与其对应的视觉特征节点和标签特征节点通过边连接起来即可构成“图像-属性”的连接;再通过KNN方法对每个视觉特征的近邻通过边连接起来,构成“近邻连接”关系.据此,即可得到对应的关系图.对于待标注图像I节点来说,通过对建立的关系图采用重启随机游走算法(random walking with restart, RWR),即可获得图中所有节点的稳定概率,具有最高稳定概率的标签特征节点,即可作为图像I的标注结果.文献[67]只是将节点分为2层,并按照图像和标签的对应关系进行双向连接,更加细致地定义了从标签到标签、标签到视觉特征、视觉特征到标签的3种转移概率.
文献[60,62,64]首先用基于图像特征的图学习方法得到每幅图像的备选标注,然后再采用基于标签特征的图学习方式来优化图像和标注之间的关联关系,进而得到最终的标注结果.其中,文献[60,64]的新颖之处在于,为了利用图像间的结构化信息,提出了一种最近生成链(nearest spanning chain, NSC)的图模型用来建立节点间的相似性关系.NSC的构建原则为:1)N个节点通过N-1条边构成1条链,除了链的2个端点只有1条边相连,其余节点均有2条边相连;2)每个节点在构建链的时候,选择剩余节点中最近的节点作为相连节点.因此,若将图像视作节点构建NSC图,则通过统计建立的多条NSC的统计信息,即可得到图像i和图像j间的统计性描述关系Ci,j:
(59)

(60)
其中Wi,j表示原始的图像间相似关系,xi和xj分别表示图像i和j的视觉特征.将W归一化为S之后,即可通过迭代式(61)直到收敛从而得到每幅图像的备选标注:

(61)
其中,Y为原始标签矩阵,t表示迭代次数.从标签关系的角度,为了使低频且具有更高判别性能的标签有更大的权值,可设计标签之间的统计性描述关系K*为
(62)
K(x,y)为原始的标签相似性矩阵K中的元素,表示标签x与标签y的相似性;nx表示标签x在训练集图像中出现的次数;NT表示训练集总数.类似地,再继续采用式(61)中的迭代方法,预测最终的标注结果,其中把式(61)中S用K*代入,Y用收敛后的图像备选标注代入即可.
文献[61]采用类似谱聚类的方式分别为图像和标签建立相似性关系图,然后再将2种相似性关系整合到一个统一的标注框架.以图像本身作为图的节点,图像i和j的相似度Wi,j作为边(Wi,j的定义见式(60)),根据相似的图像标签也应该类似的原则,即可定义二次能量函数E(f)为
(63)
其中f代表对图像的实值预测函数.同理,可定义标签的二次能量函数E′(g)为
(64)
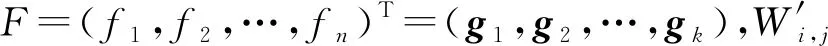
(65)
通过对式(65)的解f进行排序,即可得到未标注图像的标注.

(66)
其中:

(67)
据此,任意多实例包Bi都通过映射得到一个单实例特征描述:
[s(x1,Bi),s(x2,Bi),…,s(xm,Bi)],
(68)


(69)

文献[65]针对每个标签类别分别构建图,包含该标签的图像作为正节点,反之为负节点,其中正节点之间和负节点之间通过实线边进行连接,表示其具有标签一致性,正负节点用虚线连接,表示具有标签的非一致性.对于某一类标签,其目标就是构建具有最大数量实线边的图,使其具有最大一致性.考虑到节点之间的相似性Wi,j,其目标函数可被定义为

(70)
其中,S+和S-分别表示正节点和负节点.求解式(70)即可得到针对每一个标签的二分类分类器,之后再利用每个标签的分类器对未标注图像进行标注.
文献[66]针对每幅图像设计了一种基于KNN的稀疏图用来建立图像与近邻的潜在映射关系W,并假定该图像的标签与其近邻的标签具有相同的映射关系,然后通过这种映射关系来建立预测标签与真实标签的损失函数,从而对待标注图像进行标注.其中,W可通过式(71)进行求解:
(71)
其中,xi表示图像i的视觉特征向量,Bi表示由图像i的近邻所构成的特征矩阵,wi表示映射关系.由于标签具有相同的映射关系,因此有:
(72)

此外,还有文献[68,70-71]同时利用了图像的视觉信息和标签信息,以及文献[72]同时利用了图像搜索引擎的返回结果和候选标注词在Web页面中的重要程度进行特征相似图的构建.文献[68]更进一步地在目标框架中嵌入了潜语义空间中的信息.文献[69]利用图和KNN相结合的方法对图像特征进行降维,使相关联的图像特征距离更近,而不相关的图像特征距离更远.
由于多数基于图的标注模型是通过与其他方法相结合的方式来融合各自的优点,因此对于解决一般性的图像标注问题(如特征的不平衡、特征选取、“图像-图像(I-I)”、“标签-标签(W-W)”之间的关系利用等)更加取决于与其结合的方法的特性,并且构建关系图的方式非常多样,使得基于图的标注模型具有相当的灵活性.
2.8 典型相关分析模型
典型相关分析(canonical correlation analysis, CCA)模型与KCCA(kernel CCA)模型的本质是用来寻找2组特征变量的最大相关关系,最早被用于基于语义的图像检索领域[73-74],其基本思想为:假定图像的视觉特征与对应的标签特征分别为异构的2种特征,则CCA模型通过2组对应的基可将2种异构特征分别映射到一个具有最大相关性的可对比的隐藏语义空间,进而再通过适当的距离运算或比较模型,获得与图像最相关的标签.由于KCCA模型是在CCA模型基础上,通过核函数的方式增强了模型的非线性特征,其本质与CCA并无区别,因此,本文统一将CCA模型和KCCA模型都称之为CCA模型.基于CCA的图像标注模型代表有文献[75-81]等.
由于基于CCA的图像标注模型的基本思想类似,区别大多集中在特征的选择、距离运算以及比较模型方面.因此,本文先以文献[79]为例,介绍CCA模型方法,在此基础上进一步描述各模型的区别.

(73)
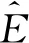
(74)
其中α和β分别为新的映射方向,Kv和Kt分别表示对训练集N幅图片经由视觉特征和标签特征各自的核函数映射过后的内积矩阵.经正则化[82]之后,可转化为标准的特征向量问题:
(Kv+kI)-1Kt(Kt+kI)-1Kvα=λ2α,
(75)
最大的D个特征值分别对应的特征向量组成的矩阵A=(α(1),α(2),…,α(D))和B=(β(1),β(2),…,β(D))即可作为图像特征与标签特征的基矩阵,映射2种特征到具有最大相关性的隐藏空间.
文献[75]采用SIFT特征[17]构成的视觉词袋(BOW)作为图像的视觉特征,对图像的标签采用“词频-逆文档频率(term frequency inverse document frequency, TFIDF)”P{TFIDF}作为特征:
P{TFIDF}(di,wj)=
|{wj∈di}|lg(l|di∈D:wj∈di|-1)|,
(76)
利用TFIDF作为标签特征是一种扩大在文档中经常出现但在整个集合中较少出现的单词影响的方法.其中di代表视作为文档的图像,wj代表标签,l为训练集中总的图像数量.
文献[76]中提出的PLSA+CCA模型,首先利用CCA模型将图像视觉特征与标签特征映射至隐藏的语义空间,然后再通过PLSA模型[18]中的方法,建立起联合2种特征之间的联合概率密度.
文献[79]将Gist、颜色直方图以及由SIFT特征构成的视觉词袋作为图像的视觉特征分别来表征图像的全局和局部特征.针对每种视觉特征的距离采用χ2核函数增强其非线性关系:

(77)
其中,A为训练集中所有特征的χ2距离均值,d为某种视觉特征f的维度,h表示其视觉特征的表示函数.从而,针对2幅图像总的视觉特征距离,其核函数可定义为
(78)

(79)
最后通过KCCA方法建立隐藏空间.对于待标注图像,则可通过图像在隐藏空间的视觉特征与标签特征的内积来寻找近邻标签并进行标签扩散.
文献[77]在文献[79]的视觉特征基础上,将训练图像中每幅图像的标签顺序进行建模,从而使被标注的图像能够更符合人类的感官.其基本依据是,人们在对图像进行标注时往往会先对图像中最显著的目标进行标注,从而使得每幅图像的标注词列表中带有目标的重要性信息,也即越显著的物体其标注词在列表中越靠前.标签的相对顺序与绝对顺序分别定义为
(80)
(81)
其中,wi,k表示第i个标签在第k幅图像中出现的次序,N为训练集图像总数,J=min(ai,H),H为选定的阈值,为了防止wi,k出现在超长列表中排序过于靠后的情况.ai代表第i个标签在所有图像中的平均排序.其对于核函数的建立与文献[79]保持一致.
文献[78]通过K-means算法对所有图像的标签特征先进行聚类,并假定聚类可得到c个具有语义相似性的簇.针对所有的n幅训练图像,可得到C∈Rn×c,其中Ci,j∈{1,0}表示第i幅图像是否属于第j个聚类簇,每幅图像也就对应有了一个c维向量作为其语义特征.然后,类似于CCA,建立“视觉特征-标签特征”、“视觉特征-语义特征”、“标签特征-语义特征”三者之间的最大相关关系:
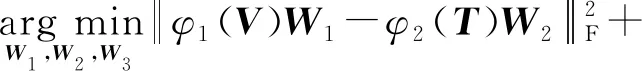
(82)
其中φ1(V),φ2(T),φ3(C)分别代表图像的视觉特征、标签特征以及语义特征.
文献[80-81]都采用从预训练的CNN模型中提取的特征作为视觉特征,其中文献[80]选用了词向量(word2vec[83])作为标签特征.
CCA,KCCA模型的构建模式比较固定,最关键的步骤在于寻找到映射2种异构特征到具有最大相关性的潜语义空间中的基.对于图像标注的一般性问题来说,由于与其他类型方法结合的灵活性也较差,使得可供解决这些问题的方法不够充分,从而也导致相关的研究工作不够充足.此外,由于解决CCA,KCCA模型的核心问题最终会演变为寻找矩阵的特征值和特征向量,因此在面对大规模数据集时,同样也会遭遇到运算效率低下的问题.
2.9 深度学习模型
近年来,由于硬件运算设备如GPU,NPU(neural-network process unit)等运算性能的大幅提升,以深度学习为基础的模型克服了早期存在的运算瓶颈,并且在计算机视觉、文本处理、电子商务[84]等各应用领域,以高泛化性和优异的性能得到了广泛的应用和发展.深度学习模型通过若干层的卷积神经网络(CNN)、非线性激活函数和池化层相连接,直接建立从图像原始像素到图像标签的端到端关系映射.深度学习模型具有2个重要优势:1)与传统方法中手工设计的图像特征相比,通过预训练的深度学习模型提取出的图像特征具有更高的泛化性以及抽象性[85-88];2)通过基于深度学习的文本处理模型提取出的标签特征[83]具有高层的语义相关关系.
深度学习模型近年来成为计算机视觉领域研究热点,源于以AlexNet(Alex net)模型[89]、VGG(visual geometry group)模型[90]、GoogLeNet(Google net)模型[91]、ResNet(residual network)模型[92]等著名深度学习模型在大规模图像分类竞赛ILSVRC(image-net large scale visual recognition challenge)中的大放异彩.ILSVRC竞赛任务为单一类别图像分类问题,而图像标注从分类角度可归类于图像的多分类问题,因此这些深度学习模型的模型结构大多适用于图像标注任务,区别仅在于对每一类别的预测得分选取方法有所不同.此外,各模型均基于前馈神经网络[93],差异大多集中在模型结构、激活函数、超参数调节等方面.因此,本文仅以AlexNet模型为例介绍深度模型结构,并在此基础上进一步描述各模型的区别.
AlexNet模型[89]的输入为RGB图像,包括5个卷积层、3个全连接层,最后通过Softmax函数输出预测,并通过预测结果与标签建立的损失函数对模型进行训练.其中,在第1,2,5卷积层之后使用了最大池化操作,避免了传统CNN模型使用平均池化所带来的模糊化效果.模型采用了ReLU作为每层卷积之后的非线性激活函数,从而减缓传统CNN模型采取sigmoid函数所面对网络较深时的梯度弥散问题,ReLU函数定义为
f(x)=max(0,x).
(83)
同时,提出了局部响应归一化(local response normalization, LRN)层,用来抑制反馈较小的神经元,从而使相应比较大的神经元值变得相对更大,从而增加模型泛化能力.对在ReLU层第i个卷积核(x,y)位置的LRN值定义为
(84)

VGG模型[90]相对AlexNet模型采用了更小的卷积核,也即3×3和1×1卷积核,而AlexNet模型中包括11×11以及5×5卷积核.采用小卷积核的原因是经试验验证,在卷积步长相同的情况下,不同卷积核大小对网络参数量差别影响不大,但大的卷积核会导致计算量增大,而大的卷积核所覆盖的感受野可通过小卷积核的叠加实现.同时,模型将卷积层增加到了19层,另有一个分支模型为16层,其中分支的VGG16模型中的若干层采用了1×1卷积核做线性映射.
GoogLeNet[91]采用了一种inception模型作为构建深度模型的基本模块,通过多个inception的模块串联形成最终的深度网络结构.inception模块由4个分支组成,每个分支都包含一个1×1且步长为1的卷积核,第2,3个分支分别在1×1卷积核后串联3×3以及5×5卷积核来增加感受野,第4个分支在1×1卷积核之前采用3×3最大池化层获取局部关键信息;最后,将4个分支的输出在维度上进行串联,作为下一个inception模块的输入.其中,采用4分支的并行结构依据为:首先在直观感觉上对多个尺度同时进行卷积,可提取到不同尺度的特征,使得最后分类判断更加准确;其次,根据Hebbian原则,4个分支分别代表4种具有高度聚类相关性的神经元,由于训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用.而在每个分支采用的1×1卷积核,其采用的依据为在相同尺寸的感受野中叠加更多的卷积,可提取到更丰富的特征[94],同时也降低了特征的维度,减少了计算复杂度.此外,由于每个卷积核后串联ReLU函数,因此还可增强模型的非线性关系.
ResNet模型[92]针对深度网络模型的层数加深达到一定数量之后模型准确率不升反降的问题,提出采用恒等映射(identity mapping)的方式使得网络加深的同时不会导致误差增加,也即通过“shortcut connections(捷径链接)”之间将输入x传到输出作为结果.假设某一段网络的输入为x,期望输出为H(x)=F(x)+x,则当网络已经学习到较饱和准确率时,F(x)=0,从而相当于H(x)=x,也即此时学习的目标为恒等映射.F(x)H(x)-x即代表网络中的残差.ResNet通过引入残差的结构,打破了传统神经网络第n层的输出只能作为第n+1层输入的惯例,使得某一层的输出可以直接跨过几层作为后面某一层的输入,在某种程度上解决了网络模型叠加多层之后精度不升反降的问题.
在深度学习的基础上,文献[95]针对社交网络图像的标注问题,有效结合了图像领域的元数据信息作为原始图像信息的补充.模型将图像的标签、图像上传时所属的集合以及图像的分组信息作为图像的元数据,然后利用这些元数据的相似性可获取某一图像的近邻集合.对图像及其近邻利用深度模型提取特征之后,采用最大池化的方式对所有特征进行融合,并将融合后的特征作为图像特征,最后训练模型.文献[96]类似于文献[95],也是利用了图像的拍摄时间和位置作为上下文信息.不同的是,文献[96]针对上下文信息建立了一个和原图像并行的网络,合并由原图像作为输入的深度网络输出结果和上下文信息作为输入的深度网络输出结果,作为总的网络结构的预测结果,从而训练深度学习模型,进而完成标注任务.
文献[97]将不同类型的视觉特征看作不同的视图(view),首先为不同的view建立深度模型作为encoder,并以此encoder输出的分布作为图像的标签特征,然后再利用图像本身结合标签特征作为输入,训练另外一个深度模型,从而得到最终的图像预测结果.
文献[98]为了建模提取标签之间的相关关系,将RNN(recurrent neural networks)模型与CNN模型相结合形成了一个统一的框架.其中,CNN用来提取图像的视觉信息并作为RNN模型在每一个节点的输入,从而使得RNN模型可提取到“图像-标签”、“标签-标签”之间的相互关系.文献[99]同样是为了利用标签之间的相关关系,但不同于文献[98],文献[99]将原始图像和标签特征统一到了一个深度学习框架中,让原始图像和标签特征统一作为模型的输入.
文献[100]首先利用分块算法将图像中包含有目标的区域划分为很多个候选块,由于多个候选块会对应至少一个标签,因此将这种对应关系转化为多实例学习问题,最后再利用多实例学习的模型框架来完成图像标注.文献[101]类似于文献[100],也是先将图像分解成包含有目标区域的多个候选块,多个候选块分别进入深度网络会形成多个预测向量,模型再将多个预测向量做最大池化操作,形成最终的多分类预测结果.
文献[102-103]分别在VGG网络[90]和GAN网络[104]的基础上引入了一种行列式点过程(DPP[105]).为了去除候选标签集合中的同义词等冗余标签,将最终的标注词的选定视为一种标签子集选择过程,在所有可能的标记中检索K个大小的标记子集作为最终的图像标注.文献[106]针对网络社交图像进行语义标注,利用具有相似视觉特征、相似主题、相似地标信息等元数据的图像构建近邻关系图,并引入到ResNet[92]网络,进一步提升视觉特征不明显的图像标注精度.文献[107]在VGG的训练过程中,加入了视觉特征一致性、标签关系一致性以及用户误标注的稀疏性作为每一批训练样本的限制,从而强化“图像-图像(I-I)”、“标签-标签(W-W)”关系.
由于传统的深度学习模型大多为针对特定领域大型数据集的分类任务而设计,在面对新领域视觉任务、小数据集或新数据集标签类别较少等特定情况下,重新设计或训练网络会造成网络过拟合、增加运算负担等一系列问题.因此,有学者提出利用深度迁移学习的思想将某个领域或任务上学习到的知识或模式(如样本特征、网络的部分层次结构等)应用到不同领域或问题中,如文献[86,108-111]等.
文献[108]设计了一系列有2个不同但相关领域的分类任务A和B,通过对网络结构不同层数迁移、微调、预训练参数等实验,表明了神经网络的前几层通常表示图像的通用特征.此外该工作与文献[86]的实验结果都可反映,经大型数据集(如ImageNet)训练的网络结构,其网络参数可用来初始化其他未经训练的同构网络.这种优势使模型在面对相似领域但数据集不同的视觉任务(如图像标注)时,仅通过新的数据集对网络某些层进行微调(fine-tune)即可达到较好的效果,从而避免了重新训练的代价,是小数据集、标签数量少等问题的有效解决方案.例如文献[109]即采用了同AlexNet模型相同的网络结构,针对图像的标注问题,将最后的Softmax层输出进行排序,排序结果最大的topN个向量元素对应的标签作为图像的标注结果.
此外,实验还表明由预训练模型的全连接层提取出的向量,可作为其他视觉任务的中级特征,并且具有良好的泛化性能.如本文归类于近邻模型的SEM模型[41]和weight-KNN模型[42],以及归类于CCA模型的文献[80-81]都利用了从深度学习的预训练模型中提取图像特征的方法.
文献[110-111]更进一步地针对数据集的领域不同问题,利用处于2个不同领域之间的若干领域,将知识传递式地完成迁移.
基于深度学习的图像标注模型大多聚焦于对网络结构的变换以及利用深度模型提取“标签-标签(W-W)”之间相关关系.由于深度学习中的深层网络结构较之其他模型建立的相关关系具有更加复杂、非线性的特性,因此具有良好的标注性能.此外,从深度学习网络结构中提取出的图像特征也具有较强的泛化性能,因此近年来得到了广泛的应用和发展.但基于深度学习的模型也存在4方面不足:1)缺乏可解释性,即对于模型结构的调参以及如何使模型收敛缺乏理论指导依据,也是基于此原因,近年来的深度学习模型大部分集中于对模型结构的改进;2)传统深度模型需要较大的训练集,对于某些样本难以获取的图像领域任务来说代价及开销过大;3)模型过度依赖于硬件设备的性能如GPU,NPU等;4)现有的深度学习模型始终无法跳出人类设计的框架,无法自动化地生成具有高性能、高泛化性能的网络结构.
3 模型特点及对比
本文选取了一些有代表性的图像标注模型,针对其在公用数据集上的性能指标进行对比(如表1和表2所示,其中相关指标P(precision),R(recall),F1(balanced score),N+在本文4.2节中有详细说明),并将各种图像标注模型所采用的主要方法类型归为9种类型,分别为相关模型、隐Markov模型、主题模型、矩阵分解模型、近邻模型、基于支持向量机的模型、图模型、典型相关分析模型以及深度学习模型,通过表3概要列出了每种方法类型所对应的优缺点,其中,“相关文献(年份)”列表示本文所引用的各种类型相关文献公开发表的起始年份和该类模型活跃的平均年份.

Table 1 Comparison of Traditional Models(1)

Continued (Table 1)

Table 2 Comparison of Traditional Models(2)
通过分析表1中的数据以及对比表3中各种模型的优缺点可知,早期的图像标注模型如相关模型、隐Markov模型等,有较强的可解释性,但这类模型比较依赖于其他算法,图像的标注性能和泛化能力往往一般;近些年取得广泛研究成果的矩阵分解模型、近邻模型、CCA(KCCA)模型等,其泛化性能有所提高,但可解释性有所降低;深度学习模型可以处理超大规模的数据集,性能相比其他模型也更高,但可解释性最差;在如何与其他的计算机方法相结合来解决标注的一般性问题,以及对“I-I”,“W-W”关系的利用程度等方面,每一类模型各有不同;此外,由于图像标注模型存在的一些固有特征(如使用的数据集过大、优化求解算法复杂等),几乎所有的模型运算速度都有待提升.
从各类模型出现的相关年份可反映出,标注模型的性能随着时间往越来越高的方向演进,所能处理的数据集也由早期的小型逐渐过渡到大型与超大型,深度学习模型以其优异的标注性能成为近年来标注模型的主流;同时,近邻模型以及矩阵分解模型等也有相当的发展.不难理解,造成这种趋势的原因是随着时代的发展,硬件处理、运算能力不断提升,以及大型超大型数据集的出现对深度学习等依赖于运算能力和数据集的模型有显著的促进作用,而其他类型标注模型根据其自身特点也可被运用于一些仅需要处理中小型数据集、运算需求较小的应用场景.
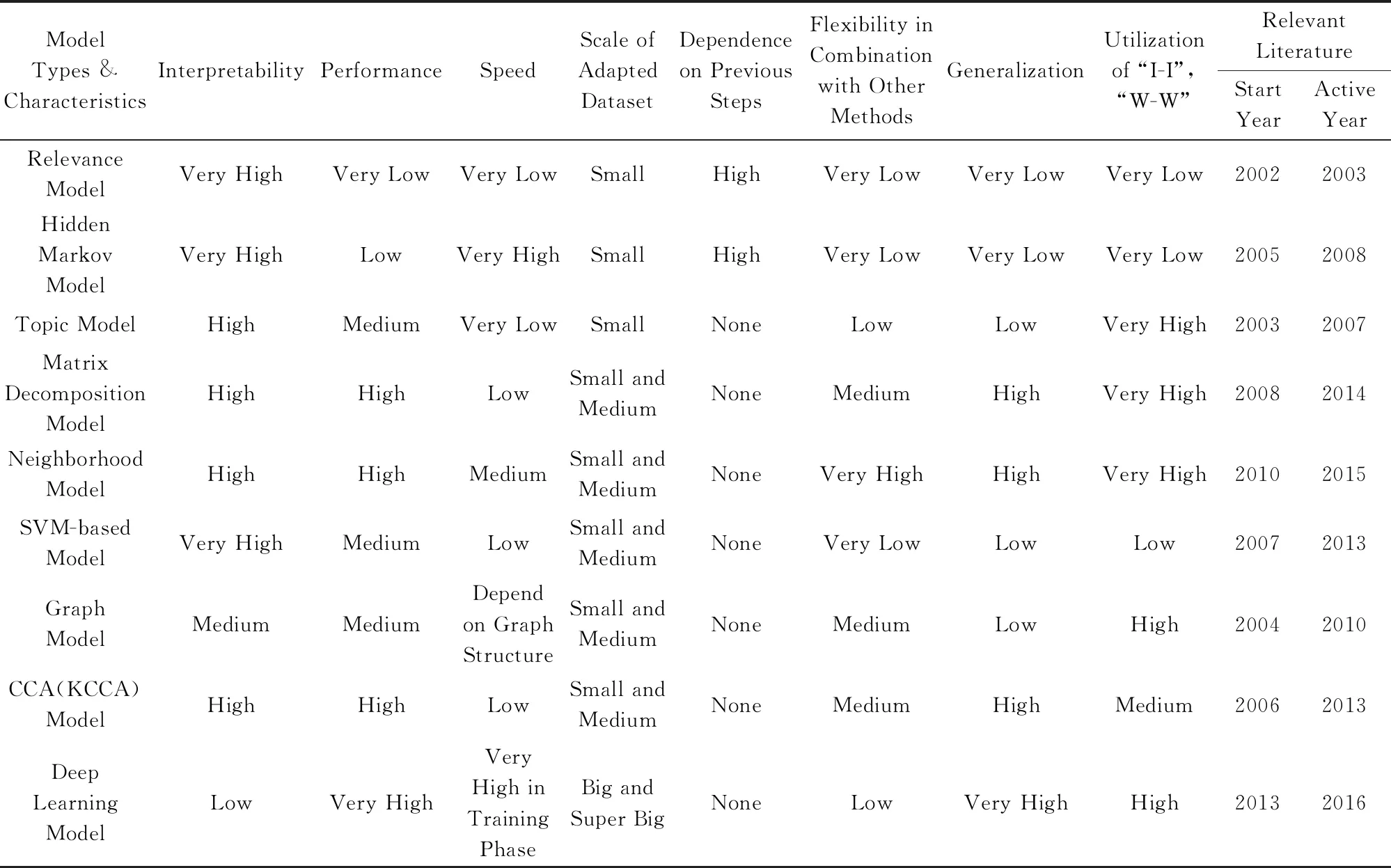
Table 3 Comparison of Advantages and Disadvantages of Different Type Models
4 图像标注数据集与评测指标
图像数据集常用来对各种任务模型进行训练,并可以结合各种评测指标对不同的模型进行对比.由于任务的不同,图像数据集的具体针对情况可能会存在偏差,但多数都可用于图像标注任务.因此,本文对已有标注工作中常用的部分图像数据集以及各种标注模型评测指标进行了归纳总结.
4.1 图像标注数据集
1) Corel5K.Corel5K数据集包含科雷尔(Corel)公司收集整理的5 000幅图片,因此命名为Corel5K.自从第1次被提出用于图像目标识别[5]实验后,已经成为图像实验的标准数据集,被广泛应用于标注算法性能的比较,也常用于图像的分类、检索等任务.图像集涵盖50个语义主题,如公共汽车、恐龙、海滩等,每个主题包含100张大小相等的图像,可以转换成多种格式.5 000幅图片常被分为3个部分,其中训练集包含4 000幅,验证集和测试集各500幅.集合共包含260个标签,每幅图像包含1~5个标签.
2) ESP-Game.ESP-Game数据集[112]源自一款双人标注游戏,游戏的内容是让2个人在不进行交流的情况下对同一图像进行标注,然后选取相同的词作为图像的标注.常用作图像标注的数据集共包含20 770幅图像和268个标签,其中训练集包含18 689幅图像,测试集包含2 081幅图像,每幅图像包含3~5个标签.
3) IAPR TC-12.IAPR TC-12数据集[113]包含19 627幅从世界各地拍摄的自然图像,其中包括各种语义场景,如体育运动、人物、动物、城市、海滩等.训练集图像为17 665幅,测试集图像为1 962幅,并包含291个语义标签.
4) NUS-WIDE.NUS-WIDE数据集[114]是由新加坡国立大学NUS实验室收集整理的网络图像数据集,图像内容侧重于人们的日常生活和事件.数据集被划分为3个集合:第1个集合包含81个从Flickr网站中获取到的基本标签,包括通用标签(如动物、植物)和特殊标签(如狗、花),而且标签大部分是由高校学生提供,因此标签噪声相对其他从网络上搜集的图像要少;第2个和第3个集合中的图像也来自于Flickr网站,分别包含1 000和5 000个原始标签.图像集共包含269 648幅图像,训练集和测试集根据任务需求可自行设置.
5) MS-COCO.MS-COCO数据集[115]是微软团队发布的一个可以用于图像识别、分割和标注的多任务用途数据集,其内容主要从复杂的日常场景中截取.数据集共包含91个类别,平均每张图片包含3.5个类别和7.7个实例目标,仅有不到20%的图片只包含1个类别,仅有10%的图片包含1个实例目标,也即每一类所包含的图像较多,有利于获得更多的每类中位于某种特定场景的能力.MS-COCO数据集分2部分发布,前部分发布于2014年,后部分发布于2015年,其中2014年的版本中包含82 783训练集图像、40 504验证集图像和40 775测试集图像,还有27万的被分割出来的人物目标和88.6万的实物目标;2015年的版本其训练集、验证集和测试集图像数量分别为165 482,81 208,81 434.
6) PASCAL VOC.PASCAL VOC数据集是由每年一度的PASCAL VOC挑战赛所发布的数据集,其主要任务包括图像分类、目标识别、目标分割、人物定位以及行为识别等.以PASCAL VOC 2012为例,数据集总共分4个大类20个小类.数据集共包含23 080幅图像,其中训练集图像数量为5 717幅,验证集图像数量为5 823幅,测试集图像数量为11 540幅,共包含54 900个目标.
7) ImageNet.ImageNet图像数据集始于2009年文献[116]中的计算机视觉系统识别项目工作,而后从2010年开始每年基于ImageNet数据集会举办大规模视觉识别挑战赛,到2017年后截止.比赛项目包括:图像分类、目标定位、目标检测、视频目标检测、场景分类、场景解析等.ImageNet数据集共包含14 197 122幅图像,常用于竞赛ISLVRC使用的公开数据集是ImageNet的子集,以2012年ILSVRC分类数据集为例,其训练集为1 281 167张图像,验证集为50 000张图像,测试集为100 000张图像在每次竞赛中单独发布,共包含1 000个不同的类别.
此外,还有其他如MIRFlickr,Flickr25k,Flickr30k等从Flickr网站获取的带有描述性标题的图像集合,也常被用于图像的标注任务.
4.2 常用评测指标
图像标注算法的评测指标常用来检验各种模型的优劣,其中包括精确度P、召回率R、F1、N+、平均精度(average precision,AP)、平均准确率(mean average precision,MAP)等,下文将对这些指标进行简单介绍.
精确度用来表明预测为正的样本中有多少是真正的正样本,它表示的结果为:某一标签预测正确的图像数量对该标签的总预测图像数量的占比.P值可表示为:
(85)
召回率用来表明样本中的正例有多少被正确预测,它表示的结果为:某一标签预测正确的图像数量对该标签的总的真实图像数量的占比.R值可表示为:
(86)
其中,Correct(wk)表示针对第k个标签预测正确的图像数量,Predicted(wk)表示针对第k个标签预测图像的总数量,GroundTruth(wk)表示所有标注有第k个标签的总的图像数量.
在判断模型优劣的时候往往希望P,R值都是越高越好,但这两者之间有时会存在矛盾.F1可以综合两者之间的关系,也即对两者进行调和:
(87)
F1综合了P,R两者的结果,当F1的值较高时说明模型方法比较理想.
N+值表示至少被正确标注过一次的标签数量.对于具有标签不平衡问题的测试数据,该指标具有很大参考意义.
P,R,F1,N+即为图像标注最常用的评测指标.此外,还有相对复杂的指标如AP和MAP,也是综合考虑了P,R的值.AP的计算方法相对复杂,该指标表示针对某一标签,在一组设定的R阈值之下,每个R值对应最大的P值的平均值.MAP指标表示对所有标签AP求均值.
5 总 结
本文通过对近年来公开发表的图像标注文献的研究,总结了图像标注模型的一般性框架,并通过该框架结合各种具体工作,分析出在图像标注问题中需要解决的一般性问题.此外,在对各种标注模型的归类方面,本文通过其主要使用的方法类型对各种模型进行了归类.首先介绍了每种方法类型的基本原理,然后具体分析了各种图像标注模型之间的差异,最后简单总结了每一类方法类型的标注模型,并结合了图像标注模型常用的一些数据集、评测指标以及比较著名的标注模型的性能和实验数据,对各种方法类型的标注模型做了优缺点分析.
总而言之,图像标注技术仍然是一个广泛、开放且具有挑战性的研究领域,其最主要的目标仍然是缩短图像的高级语义信息同低层视觉特征之间的语义鸿沟问题.本文结合标注领域的一般性问题以及各种方法类型的标注模型,有针对性地提出5个改善图像标注性能的方向:
1) 由于近年来社交网站的快速发展,用于图像标注领域的数据集往往是由不同的用户进行标注,标签里面夹杂着大量不相关或者错误的标注词汇.这些主观性的问题会导致生成的数据集产生标签不平衡、弱标签等问题.因此,如何采取自动化的方法剔除不相关标签仍然是标注模型亟待解决的问题之一.
2) 一些专业或特殊领域的图像集(如医学图像数据集、商品图像数据集等)拥有很多复杂特性,如:①图像中需要标注的目标之间具有环绕、遮挡情况;②关注的目标是细微的物品,在图像占比太小,不够显著;③关注的目标与图像中其他目标非常相似.因此,在特定的应用场景下还需要解决这类特定问题.
3) 图像的标注模型性能和速度往往会受到所采用的图像视觉特征的干扰,因此,如何使得选取的特征具有强大的泛化性能且低维是需要改进的方向.
4) 充分利用“图像-图像”、“标签-标签”之间的关联信息有助于提升标注的性能,而高层的语义关联信息在其他研究领域如自然语言处理(NLP)中也得到了广泛研究.因此,如何结合其他领域的研究方法也可作为提升图像标注性能的方向之一.
5) 由于近年来深度学习模型在图像标注领域表现出了良好的性能但可解释性低的特性,而较低的可解释性意味着深度学习模型的架构往往存在可复现及调参的问题.因此,深度学习模型在图像标注领域中的模型构建依据以及调参技巧也是需要研究的课题.此外,由于迁移学习表现出的可将已学习知识应用到新领域的强大性能,研发新的迁移学习理论和模型方法也成为改善图像标注性能的新思路.
