基于领域知识库的语义出版形态研究
2020-11-09苏静


[摘 要] 指出领域知识库是对知识单元进行管理、存储和关联利用的有效工具,是专业出版机构开展语义出版服务的基础性工程。提出语义出版领域知识库的知识单元可划分为出版载体与文献类型模块、母体要素模块、科学陈述模块、知识形态模块和外部关联模块,通过书目关联关系、概念关联关系、引证关联关系、论证关联关系、科研本体关联关系构建适用于出版业的资源语义网络。阐释面向集成揭示和智能推理两种语义出版形态,并提出采用“众包”模式建设领域知识库和推动开放知识组织体系共享利用的建议,以期对我国语义出版领域知识库构建及其应用提供借鉴。
[关键词] 语义出版 领域知识库 知识单元 服务形态 数字出版
[中图分类号] G237[文献标识码] A[文章编号] 1009-5853 (2020) 05-0091-09
[Abstract] The domain knowledge base is an effective tool for managing, storing and associating knowledge units, and it is the groundwork for professional publishing institutions to develop semantic publishing services. The knowledge units of the domain knowledge bases in the field of semantic publishing can be divided into publication media and document type module, parent element module, scientific statement module, knowledge type module and external association module. Meanwhile, these knowledge units can be built into content resource semantic networks suitable for the publishing industry through bibliographic associations, conceptual associations, citation associations, argument associations and research ontology associations. Based on the above analysis, it first explained two forms of semantic publishing oriented to integral showcase and intelligent reasoning respectively; then put forward the suggestions of using the‘crowdsourcing model to construct domain knowledge bases and sharing open knowledge organization systems, in order to provide references for the development of semantic publishing and its application in China.
[Key words] Semantic publishing Domain knowledge base Knowledge unit Service form Digital publishing
1 引 言
由于海量的異构数字资源仍呈现指数式增长,人们倾向于让计算代理执行信息资源发现和集成任务。然而,当前数字出版服务更多依赖于传统文献资源的元数据检索,而其中的关键词匹配机制较少考虑关键词的多义性、组合关键词的复杂性和被用于不同语境时的差异性[1],因此,其结果难以满足高效率、知识性、体系化的用户服务需求。作为数字出版的高级形态,语义出版旨在将可发现、可引用并可重用的信息资源有序关联和发布,这对提升出版业知识服务能力具有重要意义。
目前,在语义出版形态的设计与应用研究方面,主要集中在:(1)学术期刊的内容增强研究,如基于本体和关联数据等方法的学术期刊数字资源聚合模型[2]、利用XML实现学术期刊数据交换与集成[3];(2)不同粒度知识单元的发布模型研究,如纳米出版物[4]、液体出版物、微型出版物等;(3)语义出版服务功能分析,如语义索引、按需检索[5]、本体导航等基本功能,主题知识聚类与演化、知识推理分析等知识管理功能[6],以及科研实体影响力可视化分析、科技热点监测、学科预测与规划等定制功能[7][8];(4)面向语义出版的结构化工具研究,如基于科研论文引文关系的智能信息检索工具CIRRA,可提供引用文本时间轴、追溯引文原始表达、集中展示核心关键词所在文本等功能[9],或提供从素材收集、数字对象制作、自动标引参考文献、按期刊版式呈现到Word文档格式转换等一系列功能的论文写作工具DPaper [10],以及面向作者服务的学术论文语义注释自动增强工具CISE [11]等。
其中,领域知识库是对领域知识单元进行管理、存储和关联利用的有效工具,是发挥语义出版价值的主要发力点,是专业出版机构开展语义出版服务的基础性工程。因此,本文通过描述领域知识库的构建元素及其关联关系,构建适用于出版业的资源语义网络,并提出两种基于领域知识库的语义出版形态,以期为我国语义出版领域知识库构建及应用提供借鉴。
2 领域知识库构建:适用于语义出版的资源网络框架
在传统出版机构特别是专业出版机构数字化转型升级过程中,领域知识库构建是发挥已有内容资源优势、实现语义内容开发、开拓知识服务范围的可行路径。通过对原始内容资源进行知识单元的精细化抽取、标识和分类,并以机器可理解、可处理的方式来表示,进而根据语义关系构建多维知识网络,可以探索语义出版服务新形态。因此,下文主要从内容组织视角入手,识别知识单元并揭示其间的关联关系,构建适用于语义出版形态的资源网络框架。
2.1 基于知识单元识别的资源模块
知识单元是指客观知识系统中有实际意义的基本单位,如一个明确的语词概念、具体观点、科学定理、数学公式等;数字内容中每一个层次的信息都可以作为具体的知识单元被解析、被描述、被重组[12][13]。知识单元的识别是开展语义出版内容服务的基础,有助于后端借助知识单元的语义逻辑关系构建知识网络。领域知识库的知识单元不仅蕴含于图书、期刊、报纸、音频、视频等传统文献和载体中,也存在于开放出版、数据仓储[14][15]、社交网络等新型科学交流与出版平台。此外,领域知识库往往围绕某一知识主题形成对知识单元的有效识别和有序集成,以快速构建面向某一主题、结构完整的知识体系。例如,围绕某一农作物对象,关联该农作物的分布地图、相关统计数据、科学研究产出、维基百科事实、世界银行数据、濒危生物数据等;采用Mesh语义本体集中某一药物的临床试验数据、正式发布的药物数据、副作用记录、使用报道等,知识单元的表现形态则涵盖数据、文档、网络链接、图片、软件、项目、出版物、研究活动、新闻等[16]。
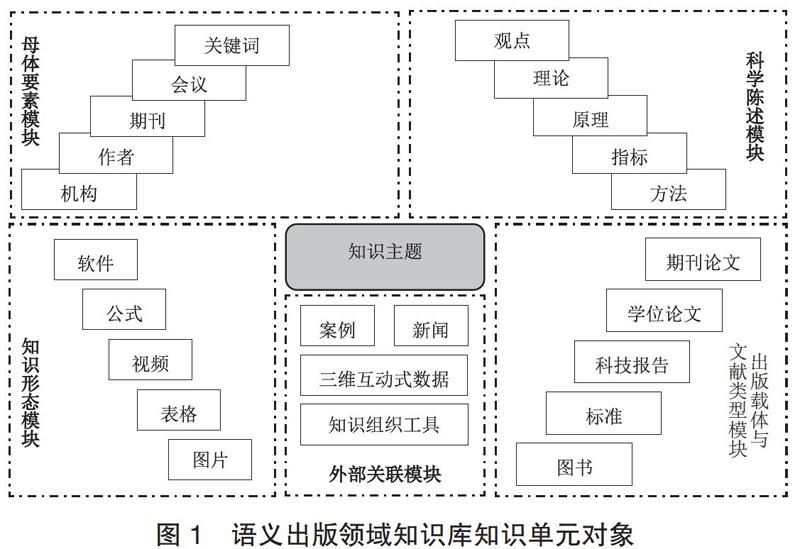
综合新型科学交流环境下知识单元的产生渠道、外部出版特征和内容资源内涵,梳理适用于语义出版的关联要素,领域知识库知识单元可分5个模块进行识别和集成,如图1所示:(1)出版载体与文献类型模块,如围绕某一知识主题的期刊论文、学位论文、科技报告、标准、图书等,有利于跨出版物载体提供主题服务。(2)母体要素模块,如期刊名称、会议名称、作者、发表机构、关键词、基金项目、发表时间、参考文献等书目元素,有利于梳理知识主题的研究热点与发展趋势,及时展现某一学科领域中信息吸收与知识扩散的发展演变。(3)科学陈述模块,是指经过自然语言处理,由文献自动抽取的观点、理论、原理、指标和方法等,有利于根据规则对上述要素的权威性、影响力和前沿性进行评价和筛选,形成基于科学陈述要素的自动综述等。(4)知识形态模块,即从文献内部提取的软件、工具、公式、视频、表格、图片、数据集等具有独立表现形态的知识单元。(5)外部关联模块,是对原有文献内容的语义化、交互式、概念性扩展,如DBpedia、SemSur [17]、汉语主题词表等知识组织工具,权威机构发布的财经数据、地理数据、生物数据等,或是某一知识主题的专业软件、专家释义、典型案例和新闻等知识对象。这有利于在服务层结构化展示主题与体系内上下位类目、相关类目的关系,以及向用户立体化地展现可交互的三维图像数据。
值得注意的是,知识单元有可分解与不可分解两类;也有学者将不可分解的知识单元称之为“知识元”[18],它在分类和索引实践中极为有用。上述知识单元中的概念、理论、图表、数据等,也隶属于知识元的概念范畴。因此,语义出版应侧重于知识元释义和知识元关系建设,强化对文章、篇、章、节、段落等独立、完整的文字内容进行的碎片化加工、标引标注、主题词创建等技术处理,完善知识元修改、标引、超链、备注、标签等流程环节的专业编辑,提升面向多元应用场景的图标、公式、表格矢量化处理的专业能力。
2.2 基于關联揭示的知识单元网络
语义出版中的领域知识库,可大致从书目关联关系、概念关联关系、引证关联关系、论证关联关系、科研本体关联关系5个维度加以构建。结果既可包括知识主题本身的结构属性,也能涵盖时间序列下的知识主题演进网络,此外还涉及知识主题与其他相关资源的关联关系。
(1)书目关联关系。书目是以“记录”为单位,由描述书目实体内容与形式特征的各项书目元素及其数据组成。书目元素包括题名、责任者、出版社、出版日期、版本、ISBN、主题/关键词、格式、标识符、权限、语种等。书目关联关系可从两方面加以揭示:一是书目实体与书目实体的关联关系,如等同、修订、改编、翻译、描述、整体与部分、附属、连续等;二是书目实体与其书目元素的关联关系,通过对书目实体的元素值进行识别、提取和对比,以都柏林核心(Dublin Core,DC)元数据描述方式可发现实体间的潜在书目关联关系。如图2所示,Resource1(资源1)和Resource3(资源3)可通过DC元数据元素creator(创建者)的属性值构建书目关联关系,Resource1(资源1)和Resource2(资源2)可通过DC元数据元素language(语种)的属性值构建书目关联关系。
(2)概念关联关系。同一概念可以有多种表达形式,而这些表达形式又可以被划分为人们公认的、能够代表概念的优先术语(也可称为优选词、叙词)和若干个非优先术语(也可称为非优选词)。如“马铃薯”即为优先术语,与其对应的非优先术语包括“土豆”“洋芋”等。概念关联关系可以把不同词语表述的完全相同或相近主题的文献信息聚集在一个信息集合之内,有利于概念的集成存储、关联与发布。具体来看,可包括以下3种关系:一是基于术语结构的语义关系,即基于概念关系类型实现内容资源的语义表达,主要包括等同关系、等级关系和相关关系。二是基于术语映射关联的语义关系,即通过映射揭示基于不同知识组织体系描述的内容资源之间的语义关联关系。如两个术语含义完全相同的精确等同,目标概念是源概念上位词的向上等同,含义基本相同或只有部分相同的近义等同,以及与某一概念虽既不具有同义或准同义关系,亦不具有向上匹配与向下匹配关系,但在语义上或使用中与其有密切联系的相关等同。三是基于术语分类关联的语义关系,即依据学科、主题、词性等分类描述,从不同语义层次揭示术语的语义关联关系。
(3)引证关联关系。主要指以引文链接为基础,通过人工规范、自动规范和数字对象标识符(Digital Object Identifier,DOI)关联,形成作者、机构、基金和引文题名等信息对象的关系聚合,以识别核心学术主体、揭示科学结构、描绘科学发展历程。具体而言,可划分为4种语义关系类型:一是耦合关系聚合,通过文献耦合来客观测度文献的相关性;二是引证路径聚合,通过引证关系网络图来量化文献的相似性;三是引证强度聚合,通过引证关系的强度计算文献之间的相关性;四是引证扩展聚合,文献的引证关系可扩展至作者、机构等科研实体的相互引证,这样能够揭示科研实体之间的相关性。
(4)论证关联关系。论证的基础,即为论点和论据。论证关联关系,是基于逻辑衍推的关系构建过程。可根据逻辑学的一般原理,在自然语言处理的基础上提取特定情境下的论点和论据(claim-evidence-context)[19],形成智能化、自动化语义推理框架,以用于后期在内容层面构建具有某种逻辑关系的语义出版服务产品。例如,根据科学文献自身的论证结构形成自动文摘;根据科学文献描述内容的因果关系形成如“症状-疾病”语义推理产品;根据某一主题和论证本体动态形成基于该主题的智能综述。其中,科学论文的论据覆盖范围较为广泛,既包括数据、图片、表格、公式、情境,又包括本体、工具、软件代码等,以及理论、原理、方法(试验方法、调查方法、数据分析方法等)或技术。由此,本研究的论据可以被定义为:凡是对论点和结论具有支撑作用的客观事物均可作为论据加以使用;事物单位涵盖篇章、段落、词句及其蕴含的知识单元。在关联关系表现方面,需依据论点、论据和论证构建语义逻辑。其中,科学论文的观点或结论可以直接被视为论点。支撑论点的论据应是根据逻辑关系(如“时间、目的、原因”等关系明显的主谓宾词对关系),从出版内容资源直接抽取的知识单元或知识片段,主要包括理论论据(如定理、公式)和事实论据(如具体事实、概括事实和数字/数据集),具体对象可参照上述论据的覆盖范围。同时,在支撑论点、组织论据的论证过程中,可以优先选择以归纳法和比较法的形式系统罗列论据的论证结构。归纳法以案例集、自动文摘等例证或概括的形式有序化地罗列知识单元;比较法则对知识单元的差异性进行对比和类比。例如,对某一观点的引用就可采用对比法,从正面引用和负面引用两个方面全面揭示对某一观点的统一或多方对立认知。
(5)科研本体关联关系。通过对科研项目、科研人员、科研机构、科研活动和科研成果5大科研对象进行本体化语义关系描述,全面、系统地反映科研本体的属性与关系。首先,对规模化的科研对象数据集进行采集、匹配、归一,将同一科研对象的相关属性信息和所有名称形式进行关联,以形成确保唯一性和稳定性的规范文档,从而实现科研对象的有序集成。其次,根据科研本体层级关系、组织结构和属性特征,对科研对象进行语义推理和可视化展示。如借助等级层次分明的科研本体分析和计算科研对象之间关联关系的强弱程度,以便为后期语义出版服务提供强关联的科研实体推荐功能。以科研机构关联关系为例,可分为基于科研机构内部关联的语义关系和基于机构外部关联的语义关系。前者指某一机构实体自身产生的关联关系如用代关联、参照关联、属分关联等,包括单一机构实体各个名称之间的关联关系和机构整体与其内在各部门的上下级关系。后者指多个机构实体通过某种共性或者活动而产生的关联关系,如地域关联、行业关联、学科关联、合作关联、从属关联等。为揭示科研机构关联关系,需要描述科研机构的属性特征。这主要包括机构唯一标识符、规范名称、交替名称、所属行业、学科主题等。
3 基于領域知识库的语义出版形态
依据知识单元识别及其关联关系构建的差异,语义出版形态既可以是一种基于知识主题本体的出版资源知识体系集成揭示模型,又可以是一种面向评价和推理的知识主题出版资源自动化发布平台。它的功能特征可包括发掘并丰富文献内部的知识内涵和表现形式,提供可供网络自动发现的外部显示数据、可自动链接与之相关的篇级文献、数据等材料,支持访问、可操作和结果再现,以及面向科学计量的知识图谱构建和科研实体评价等。
3.1 面向集成揭示的语义出版形态
面向集成揭示的语义出版形态,以领域知识主题挖掘为核心,由文献结构、篇章、段落、词句、图表、引文、公式等构成复合数字对象,突破文献类型的界限,实现知识聚合、知识演化、科研关系展示和学术评价等功能。它不仅能够满足语义检索需求,还能高效地为用户提供观点提炼和语义网络节点评价等服务能力。
当前,出版机构可围绕自身优质出版资源和优势出版资源,从建设经典阅读、精品阅读语义出版服务投送平台入手,围绕某一主题或知识点实现文献整合及其所蕴含知识单元要素的动态重组,形成如图书集成、文本综述、主题监测和追踪等知识网络产品。为此,本文设计了物理学语义出版服务平台中知识主题集成揭示系统的相关功能,如图3所示。
其中,图书集成服务是指以书目关联关系为核心,通过词条检索功能,运用语义搜索技术将传统关键词匹配检索提升至规范词、篇章、语用、逻辑等语义检索层次。它运用语义碎片化技术,识别和提取出版内容资源的结构化信息碎片,根据用户或者行业需求特征,将图书、文本、多媒体资源等进行个性化整合及专题服务,从而以百科阅读、主题阅读等形式对外呈现,实现对多载体检索内容的按需聚合。自动综述服务是指以概念关联关系和引证关联关系为核心,形成如简介、理化性质、制备方法、分类与应用、发展前景等主题对象知识集合。它支持文本过滤与内容对比分析功能;支持用户自定义语义出版服务的内容组织结构;支持高被引文献的核心观点/概念展示;支持多媒体资源、结构化公式的有机融合;支持不同知识元之间的关联与跳转。主题监测服务是指以科研本体关联关系为核心的学术主体评价服务。该服务可围绕知识主题,对相关机构、作者、项目和管理决策进行数据处理和信息运算,实现立体化的实体计量和对某个知识单元的有效评价,凸显某学科领域的核心或潜在作者、机构、期刊、会议、项目等知识要素及其相关关系,动态展示学科发展现状与趋势。
3.2 面向智能推理的语义出版形态
面向智能推理的语义出版形态,是指在碎片化、结构化、语义化的底层数据基础上,根据用户设置的问题,运用自然语言处理技术、可视化技术、人工智能技术等,借助前期预设的推理机制在底层数据中寻找符合条件的内容资源,以可视化、体系化的形式为用户提供面向问题的自动问答解决方案,满足用户的知识需求。具体展现方式可以是基于知识单元的自动问答;也可以是预测研究模式与规律的自动系统,如针对某一问题如何开展实验、相关步骤有哪些、所需设备型号、实验数据库建设框架等;还可以是辅助疾病诊断的治疗措施推荐,等等。
需要注意的是,面向智能推理的语义出版服务,需要在提供解决方案的同时,特别标明产生方案的出版来源和链接来源,以说明方案的真实性和科学性。以基于电脑医学专家系统的语义出版服务为例,可由一个医学领域知识库、数据库、推理库、解释机制以及知识获取5部分构成。它要求能够准确地模拟医学专家的记忆、联想、推理以及判断等思维过程,即让电脑模拟医学专家诊治各类疾病的思想和思路,让其起到医学专家的作用,以随时随地地为广大用户诊断各种疾病并开出相应药方。其中,医学领域知识库是将专家的专业知识和经验存储在其中,通过建立疾病诊断树而实现;数据库存放该系统处理对象的初始信息(包括患者姓名、年龄、症状、诊断结果、病情程度以及治疗方案等);推理机是一组程序,根据输入的数据(如患者的病史、症状与检查结果)调用知识库的知识,进行各种方式的推理;解释机制以规则队列方式记录推理轨迹,对这种物理形式的规则进行分析,并将分析结果用中文予以表述;知识获取部分,会帮助修改知识库中原有不合理的知识和扩充新知识。
目前,出版机构可以根据在某一行业领域的专业优势,研发、打造行业针对性强、用户需求度高的语义出版服务产品,将专业出版内容资源与现代信息技术相融合,提供面向金融决策的语义出版平台、面向医学诊疗的语义出版平台等。为此,本文以农业领域语义出版服务平台为例,以概念关联关系和论证关联关系为核心设计农作物病害诊断系统,着重从物种属性关系、整体与部分关系、症状与处方关系、因果关系4个方面构建语义网络架构,系统可通过用户选择的病害发生时间、病害发生位置、症状和相似性图片推荐等碎片化信息,智能化、自动化推理水稻病害名称,并同时提供病害简介、症状识别方法、发生规律和防治方法等语义关联内容,具体如图4所示。
4 结论与展望
互联网、数字技术、语义技术等已经深入出版业数字转型工作中,出版产品的構成、内容模式和载体形态等也在发生深刻变化,基于用户需求创造高效、精准的基于语义的阅读体验逐渐成为新兴趋势[20]。领域知识库构建是开展语义出版服务的前端环节,是在深度开发已有出版内容资源的基础上,借助多元关联关系将不同的知识单元对象有序分类和多维集成。同时,面向集成揭示和智能推理的语义出版形态,是基于领域知识库的数字出版语义服务形式,能够实现围绕某一主题的知识体系全方位展示以及基于用户知识需求的自动解答。
其中,领域知识库开发是完善知识单元识别和关系揭示、构建知识体系结构、优化语义出版形态的基础建设工作,具体可采用以下方式进行:一是应用“众包”模式,探索“分布建设、集成应用”的领域知识库发展新模式。所谓“众包”模式,是指部分专业出版机构按照服务领域既分工、又联合地开展专业数字内容资源知识库建设的模式。各个出版机构须依据内容资源的相关规律和特征,研制数据存储标准,开展语义分析和知识挖掘,设计知识库功能并构建相应层级等。一家独大的局面并不适合当下国内语义出版发展,因其更需要发挥中小出版机构的多方优势,探索多方分散型出版资源的数据加工和集群管理模式。对于中小型出版机构而言,采用“众包”模式是参与语义出版建设、降低转型升级风险、挖掘优势资源价值的重要举措。只有这样,才能够充分保留出版内容资源的“延展性”权利,即出版机构具有先占权,一旦内容资源或领域知识库被利用而产生商业价值,出版机构都能从中分取相应利益。由此,基于“众包”模式的领域知识库建设能够创建出有特色、专业性强的本地化知识库,并在此基础上由大型出版机构为主导,开发领域知识库集成与服务平台。二是推动已有开放知识组织体系的共享利用,扩充领域本体的知识架构。知识组织体系具有范畴分类、概念关联、定义注释等功能,可以有效地辅助领域本体的构建。20世纪80年代以来,我国已编制出版多个大型综合性或专业性知识组织体系。其中,叙词表是重要组成部分。目前,有代表性的综合性叙词表如《汉语主题词表》《中国分类主题词表》等,2000年以来专业性叙词表有《中国中医药学主题词表》《海军主题词表》《地质学汉语叙词表》《电力主题词表》《测绘学叙词表》等。可见,现有的知识组织体系成果较为丰硕,涉及专业领域较多,并且已逐渐呈现网络化、数字化、开放化的应用特征。出版业可引入这些开放的知识组织体系,将之用于切词、信息抽取、聚类、词频统计等文本信息处理流程,使之与出版内容资源或其他相关资源互联互通,以服务于领域知识库构建过程中的计算语言学应用;可以建立领域知识库自动分类系统,实现对海量内容资源进行自动标注、知识关联、知识组织、知识揭示等服务功能;可以通过词族知识概念体系,推进“分类(类目词)-主题词-关键词”的主题分类一体化应用,达到领域知识库内学科导航的服务目的;从自身本质就属于知识本体的意义上来说,还可进行智能推理、语义聚类和跨语言检索的服务项目。
当前,我国出版业正朝向技术、知识、服务密集型的方向加快发展,出版机构的集团化结构调整也提升了出版内容资源的整合规模,拓展了语义出版的资源基础,而语义出版的服务形态和应用场景仍处于检验阶段。下一步研究方向,将在明确用户需求的基础上,面向科研全生命周期,提出强调以传统出版物内容资源为核心,通过海量数字资源的组织、关联、聚合、评价和推荐,开展实现精准服务的语义出版形态研究。
注 释
[1] 孙坦.数字出版与数字图书馆:面向语义知识服务的融合归一[EB/OL]. [2019-12-17]. https://max.book118.com/html/2016/0811/51067082.shtm
[2] 许鑫,江燕青,翟姗姗.面向语义出版的学术期刊数字资源聚合研究[J].图书情报工作,2016,60(17):122-129
[3] 朱琳峰,李楠.学术期刊数字出版内容增强模式探索[J].编辑学报,2019,31(4):421-423,427
[4] 王晓光,宋宁远.语义出版物的内容组织架构研究:基于纳米出版物和微型出版物的比较分析[J].出版科学,2017,25(4):20-27
[5] 王莉莉,栾冠楠.英国广播公司(BBC)动态语义出版模式研究[J].图书情报工作,2017,61(8): 126-132
[6] Senderov V, Simov K, Franz N,et al. OpenBiodiv-O: ontology of the OpenBiodiv knowledge management system[J]. Journal of Biomedical Semantics, 2018(9):5,11
[7] 徐雷,潘珺.科学出版物语义数据及其应用研究[J].中国科技期刊研究,2018,29(7): 704-710
[8] 苏静.面向科学交流的语义出版体系建设研究[J].数字图书馆论坛,2018(11):58-64
[9] Angrosh M A, Cranefield S, Stanger N. Contextual information retrieval in research articles: Semantic publishing tools for the research community[J]. Semantic Web, 2014, 5(4): 261-293
[10] 乐小虬,王子璇,张晓林,等. DPaper:一种面向语义出版的结构化论文写作工具设计与实现[J].现代图书情报技术,2016(11):76-81
[11] Peroni S. Automating semantic publishing [J]. Data Science,2017(1):155-173
[12]彭希珺,张晓林.国际学术期刊的数字化发展趋势[J].中国科技期刊研究,2013,24(6): 1033-1038
[13]王子舟,王碧滢.知识的基本组分:文献单元和知识单元[J].中国图书馆学报,2003, 29(143):5-11
[14] 关联数据云(LOD Cloud) [EB/OL].[2019-12-17]. https://lod-cloud.net/#about
[15] Dryad[EB/OL]. [2019-12-17].https://datadryad.org/stash/our_mission
[16] Ettorre M, Pontieri P, Ruffolo M, et al. A prototypal environment for collaborative work within a research organization[C]// International Workshop on Database and Expert Systems Applications,2003:274-279
[17] Fathalla S, Vahdati S, Auer S, et al. SemSur: A Core Ontology for the Semantic Representation of Research Findings[J]. Procedia Computer Science, 2018, 137:151-162
[18] 溫有奎.基于“知识元”的知识组织与检索[J].计算机工程与应用,2005,41(1):55-57,91
[19] Ciccarese P, Ocana M, Clark T. Open semantic annotation of scientific publications using DOMEO[J]. Journal of Biomedical Semantics, 2012, 3(1):1-14
[20] 徐丽芳,丛挺.数据密集、语义、可视化与互动出版:全球科技出版发展趋势研究[J].出版科学,2012,20(4):73-80
(收稿日期:2020-03-17)
