基于经典算法的教育大数据挖掘实践研究
2020-11-09肖中杰
肖中杰

摘 要: 在信息技术与高等教育深度融合的背景下,高校逐渐积累了种类繁多的学生教育教学行为大数据。针对数据长期闲置,造成数据资源浪费的问题,文章以学生图书馆进出次数、图书借阅情况、综合测评成绩、奖助学金评定数据为依据,基于SPSS Modeler关联规则挖掘算法,对数据间潜在的关联规则进行研究,得出了数据间的系列关联规则,找出了学生学习行为轨迹中影响学业成绩的因素。
关键词: 学习行为; 信息化; 大数据; 数据挖掘; 算法
中图分类号:TP393.04 文献标识码:A 文章编号:1006-8228(2020)10-09-03
Abstract: With the deep integration of information technology and higher education, colleges and universities have gradually accumulated a wide variety of student education and teaching behavior big data. In view of the problem of long-term idle data, resulting in waste of data resources, according to the library access times, book borrowing, comprehensive evaluation results and scholarship evaluation data of student, this paper studies the potential association rules between data with SPSS modeler association rule mining algorithm, to obtain the series of association rules between data and find out the factors that affect the academic achievement in the track of students' learning behavior.
Key words: learning behavior; informatization; big data; data mining; algorithm
0 引言
以数字化、网络化、信息化技术为主要特征的教育信息化1.0,引领我国教育信息化事业实现了前所未有的快速发展,也取得了全方位、历史性成就。在教育信息化1.0技术驱动下,高校教育信息化整体水平得到提升,与此同时也积累了大量的教学、科研、管理过程数据,并进一步形成校园特有的教育大数据资源。
从学生角度,这些数据包括学生档案基本信息,食堂消费、公寓出入、超市购物等生活信息;图书馆进出及图书借阅、考勤、选课、成绩、获奖等学习信息;上网情况、参加社团、竞赛、讲座等第二课堂信息。同时随着移动互联网以及物联网等新技术的普及,由学校师生主动产生和由设备自动收集的信息越来越多,如微博、微信等社交信息,各类搜索点击记录信息等。
适应大数据时代教育信息化新需求,面对种类繁多、结构复杂的教育大数据,如何借助成熟的技术及算法实现数据深度挖掘并加以利用,促进教育信息化向深层发展,更好的服务于学校的教学、科研、管理及师生日常生活,已成为当下智慧校园建设的重要应用之一,也是当下高校面临的重要课题。
SPSS Modeler是一款专门用于数据挖掘的工具,通过引入复杂的统计方法和机器学习技术,形成软件强大的数据挖掘功能,可视化界面允许用户充分利用统计和数据挖掘算法,而无需编程。Apriori作为SPSS Modeler 数据挖掘中简单关联规则技术的核心算法,可以找出数据集中有效的关联规则,进而针对具体数据作进一步的关联度分析[1]。
1 数据挖掘设计
1.1 原始样本数据采集
学生图书借阅数据及图书馆出入数据,分别从图书借阅系统和一卡通系统中以.xlsx文件格式导出,根据需要对数据初步筛选,图书借阅数据保留“学号(读者条码)、(读者)姓名、院系、年级、借阅时间(操作时间)、借还情况(操作类型)、图书名称(书籍题名)”七个字段;图书馆出入数据保留“学号、姓名、院系年级、出入时间、进出情况”等五个数据项。学生综合测评和奖助学金数据从学工系统中导出,主要选取学号、姓名、专业、测评结果、奖助级别(备注)几个字段。本文采集了某学院某年度183名学生学习行为样本数据。
1.2 原始样本数据预处理
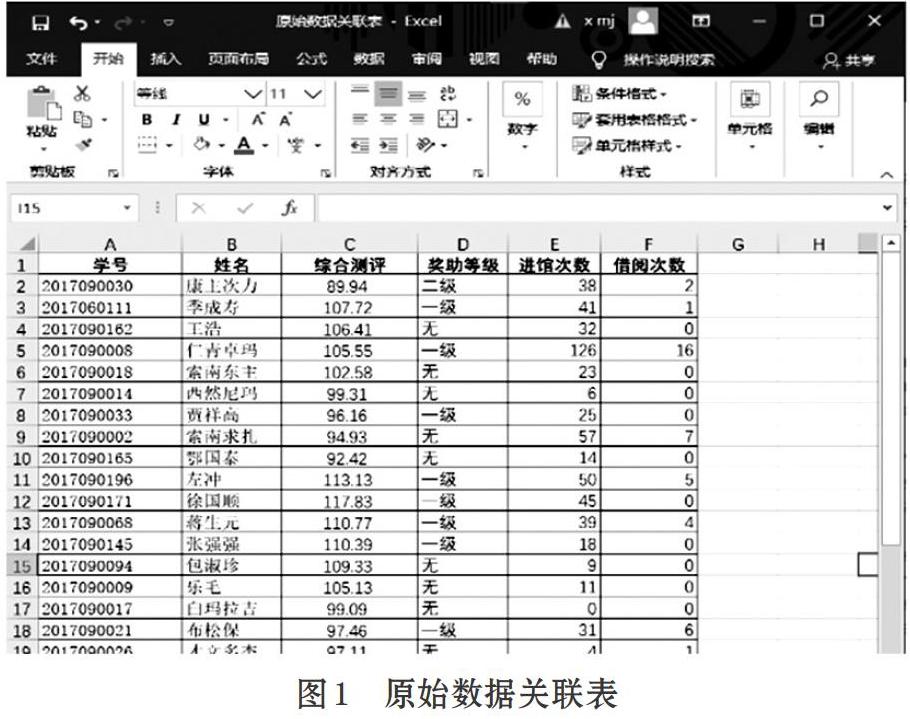
图书借阅及图书馆出入数据文件中含有冗余数据,为便于挖掘分析,首先需要按“学号”进行查询统计处理,分别得到学生借阅图书次数和出入馆次数。其次使用VLOOKUP()函数按照学号把学生综合测评结果、奖助评定结果、图书借阅次数,以及图书馆出入次数等数据关联到一张表中,最终得到预处理后的原始数据关联表[2],如图1所示。
最后,对关联表中数据做二值化变量的数据处理。主要是通过计算得到全部样本图书借阅次数和出入图书馆次数的平均次数,选取中间值为参照标准,再将学生图书借阅行为和图书馆出入行为分别定义为借阅规律、出入规律,并分别用JY、JG表示。二值化的原则是大于等于中间值标准的学生其值记为“T”,小于中间值標准的学生其值记为“F”。同样,学生综合测评规律和奖助规律分别用ZH、JZ表示,对综合测评数据按平均成绩进行二值化,对奖助学金数据按“有”和“无”进行二值化处理。通过二值化处理后得到一张综合数据表,删除表中除ZH、JZ、JY、JG四个数据项之处的其他数据,最终生成一张可用于SPSS算法分析的二值化数据表[3,5]。如图2所示。
至此,四类原始数据预处理环节完毕,接下来使用Apriori算法对二值化数据表作进一步的关联分析及数据潜在含义的挖掘。
2 基于Apriori算法数据挖掘
根据Apriori算法原理,学生综合测评成绩排名的高和低、奖助学金评定、出入图书馆、图书借阅行为都是一种事务。这里,构成事务的事务标识为“学号”,项目集合(简称项集)由ZH、JZ、JG、JY组成;如果用 I 代表包含了k个项目的总体,即I={i1,i2,…,ik},则事务 T∈I,项集 P∈I,项集 P1和P2的简单关联规则可表示为:P1→P2(規则支持度,规则置信度),其中P1称为规则的前项,可以是一个项目或者项集,也可以是一个包含逻辑关系的逻辑表达式;P2称为规则的后项,一般为一个项目,表示某种结论或事实。例如:JG(T)∩JY(T)→ZH(T),其前项是一个包括逻辑“与”的逻辑表达式,表示两个项集(进馆次数和借阅次数)之间为并且的关系,后项是一个综合测评成绩的项集,项目为好。结果表示学生进馆次数和借阅次数都好的情况下,综合测评成绩排名也是好的[4]。
基于算法规则,在SPSS Modeler软件中首先建立一个新的数据流,默认名为“流1”,通过工具面板区“源”选项卡的“Excel”数据源创建一个节点,使用节点快捷菜单的“编辑”命令将准备好的“二值化数据表”导入到数据流中;然后把“建模”选项卡中的“Apriori”节点添加到数据流中,建立该节点和Excel数据源节点间的连接;最后通过“Apriori”节点菜单中的“编辑”选项设置节点相关参数,主要是字段、模型、专家三项。
在“字段”选项中,由于数据挖掘过程中是自行指定建模变量,故选择“使用定制设置”选项,并分别在“后项”和“前项”框中选择关联规则的后项和前项变量。
“模型”选项中的“最低条件支持度”描述的是指定前项的最小支持度,系统默认值为10%,也就是在进行 Apriori 关联规则分析时,前项的数据至少要占总体数据的10%,否则,这个前项的重要程度就很低。
“最小规则置信度”描述的是指定规则的最小置信度,默认值为80%,即在进行 Apriori 关联规则分析时,在包含前项数据的基础上,又包含的后项数据和前项数据的比值至少是 80%,否则,生成的关联规则的可靠性就很低。
“最大前项数”描述的是系统关联分析时可以使用的最大前项的项目数。
“专家”选项卡用于指定关联规则的评价指标,一般选用“规则置信度”,即提升度。
实验中算法“最低条件支持度”设置为15%,“最小规则置信度”取默认值80%。系统分析关联参数和评价指标设置完成后,通过“Apriori”节点“预览”功能,即可输出Apriori 关联分析的结果[6]。
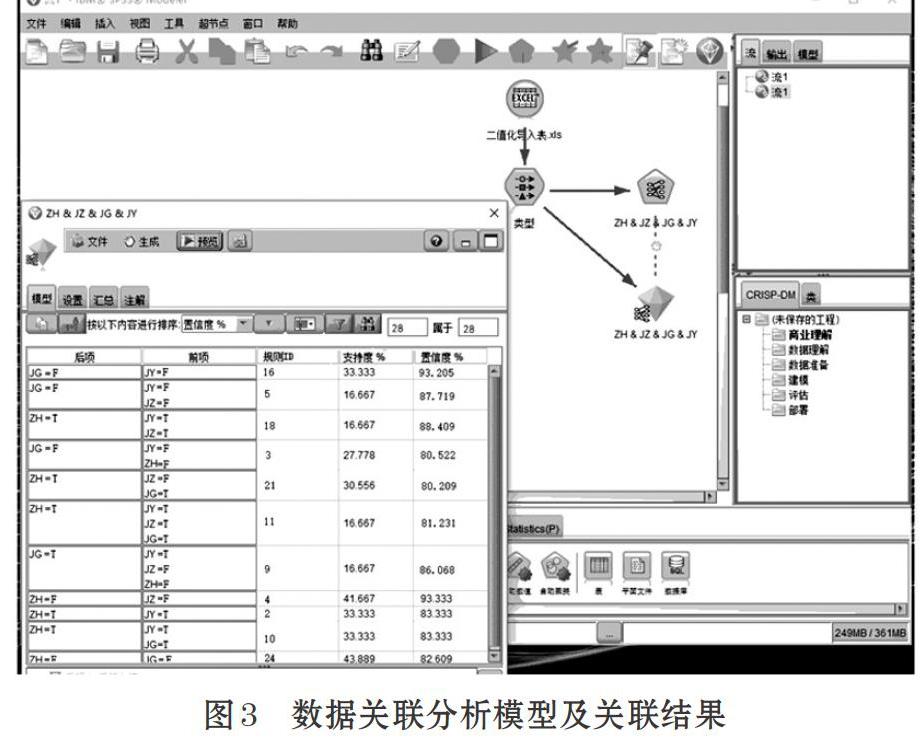
Apriori算法数据关联分析模型及二值化数据表中四个数据项的关联关系如图3所示。
3 实验结果分析
数据挖掘实验结果中共产生 28条关联规则,其中后项为“综合测评”的规则共有五条,ID号分别为18、21、11、10、24。分别描述如下:
下面以ID=11的规则为例进行分析。
这条规则可描述为:借阅图书次数多、获得奖/助学金、进入图书馆次数多,则“综合测评”成绩排名好。此类学生样本量为31,即总样本数的16.667%。其中有81.231%的学生综合测评成绩排名可能是好的,即25个样本。这条规则的支持度为13.7%,即借阅图书次数多、获得奖/助学金、进入图书馆次数多且“综合测评”成绩排名好的学生占总样本数的13.7%。经过对其他规则做同样的分析发现,ID=21及ID=24的规则中,奖/助学金情况与综合测评成绩并不是正相关关系,即获得奖/助学金的学生并非全部都是综合测评成绩好的,实际评定中有一定的均衡因素考虑。此外,进入图书馆次数少、没有获得奖/助学金二个因素并不能直接影响综合测评成绩排名,每个变量都没有单独导致成绩排名好坏。
这条关联规则的实用性可通过简单计算来验证。经过统计,全部样本中,综合测评绩排名好的学生有89 人,占总体样本的 48.6%。而规则中成绩排名好的学生比例明显高于该比例,故此条规则的关联是正向关联。
从提升度来看,本条规则中综合成绩排名好的支持度为48.6%,置信度为 81.231%,则提升度为二者的商即1.677。表示在全部样本中,排名好的样本概率为48.6%,如果把学生限定在借阅图书次数多、获得奖/助学金、进入图书馆次数多的 31 人中,成绩排名好的概率可提高1.677倍。
4 结束语
通过对数据关联分析模型产生的数据关联结果的研究分析,可以发现规则的提升度都很高,关联规则有效,规则对学生学习行为数据分析起到了一定的指导作用,对教育教学部门工作效率的提升有一定的指导意义,成功挖掘出了数据资源中蕴藏的价值。
随着高校信息化建设工作的逐步深入,各部门业务系统产生了大量可用的教育大数据,传统人工数据处理方式已经远远无法适应大数据处理的要求,如何利用成熟的大数据处理技术,通过更加广泛的教育大数据关联规则分析,提升高校数据挖掘和应用能力,提升数据资源的利用率,为学校教学、科研、管理工作提供决策支持,已经成为大数据时代高校面临的重要任务之一。教育大数据关联规则分析对基于教育大数据的智慧校园建设有重要意义。
参考文献(References):
[1] 蒋智钢等.SPSS软件及应用课程教学体系助学自训系统设计[J].实验室研究与探索,2019.38(3):199-202
[2] 肖宇.校园一卡通应用数据分析系统的研究与实现[D].西南科技大学硕士学位论文,2018.
[3] 马如义.Apriori算法在词性标注规则获取中的应用[J].计算机时代,2016.10:32-35
[4] 丁雪梅等.SPSS数据分析及Excel作图在毕业论文中的应用[J].实验室研究与探索,2012.31(3):122-128
[5] 曾馨.基于数字化校园的一卡通系统设计与应用[J].电子技术与软件工程,2016.6:57
[6] 薛颂.基于校园卡数据的学生成绩关联性因素分析[D].内蒙古师范大学硕士学位论文,2017.
