基于Tesseract-OCR的字符识别技术在特定场合的应用
2020-11-07吴鸣
吴 鸣
(湖南城市学院 信息与电子工程学院,湖南 益阳 413000)
图片的字符识别过程是一整套流程,它包括图片分析、预处理、字符识别和识别矫正等,每个步骤都关系着最终识别结果的准确性﹒比如要进行字符识别的图片越清晰(即预处理做的越好),识别效果往往就越好﹒字符识别是图片的字符识别过程中最重要的环节﹒目前,最常用也最成熟的字符识别技术是光学字符识别(Optical Character Recognition,OCR)[1]﹒OCR 是针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术﹒
国内很多企业和平台都提供了OCR 服务,如汉王OCR、百度OCR 和阿里OCR 等,还有OCRMAKER 等在线字符识别网站﹒这些开放平台字符识别的准确率很高,但有2 个缺点:一是不适合图片的批处理;二是用户无法控制识别的准确度,不能在OCR 识别上做改进,能做的只有预处理和后期矫正[2]﹒因此,针对某些特定的应用场合,专门为其设计字符自动识别的系统显得尤为重要﹒
Tesseract 是一款由 HP 实验室开发并由Google 维护的OCR 引擎,它可以读取各种格式的图像并将它们转化成超过60 种语言(包括中文)的文本,并且支持用户不断训练字库,以提高字符识别准确率﹒如果有实际需要,还可以它为模板,开发出符合自身需求的OCR 引擎﹒本系统将使用Tesseract 进行字符识别﹒
1 应用背景
针对某娱乐平台上所积累的上千张玩家游戏成绩的样本图片(如图1 所示),系统要求能识别出图片上的玩家姓名及其对应的总成绩,并整合成一个json 文件,以供后续的数据分析和处理﹒
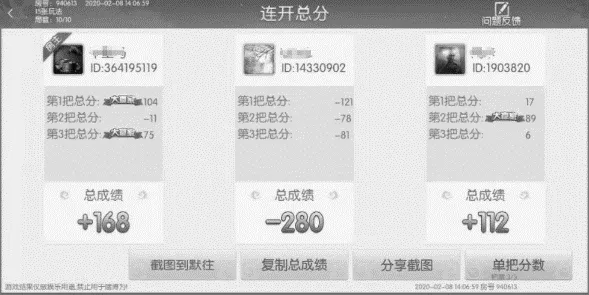
图1 样本图片示例
2 系统结构
本系统主要分为4 个部分:图片预处理、训练字库、字符识别以及识别矫正﹒整个系统结构如图2 所示﹒

图2 系统结构
图2 中,各部分主要功能如下:
1)图片预处理﹒该模块的功能主要是将样本图片进行尺寸统一、分割、灰度化和二值化等预处理,为后续的字符识别做准备﹒
2)训练字库﹒利用Tesseract 对样本图片里的字符进行针对性训练,以提高识别准确率﹒
3)字符识别﹒调用Tesseract 引擎对预处理后的图片进行字符识别﹒
4)识别矫正﹒针对拒识或误识的图片字符进行矫正﹒
3 图片预处理
3.1 分割图片
经过分析,发现这些样本图片(见图1)的大小和分辨率都不一致,不利于后续的批量处理﹒另外图片里有很多字符,而真正有用的只有6 个内容,即3 个玩家的姓名,以及对应的总成绩﹒因此,首先要做的是统一图片的尺寸,然后把这些图片分割成6 张小图片,以此简化识别难度,提高识别准确率﹒
统一尺寸再分割后的图片保存到cropped 文件夹中,里面的图片如图3 所示﹒

图3 分割后的图片
3.2 图片灰度化
分割后的彩色图片需要先转换为灰度图﹒灰度图又称灰阶图,就是将白与黑中间的颜色等分为若干等级,称为灰度,灰度分为256 阶[3]﹒灰度化的过程就是将每个像素点的RGB 值统一成同一个值,因此需要分别对RGB 3 种分量进行处理﹒根据重要性及其它指标,按式(1)对RGB 分量进行加权平均能得到较合理的灰度图片﹒
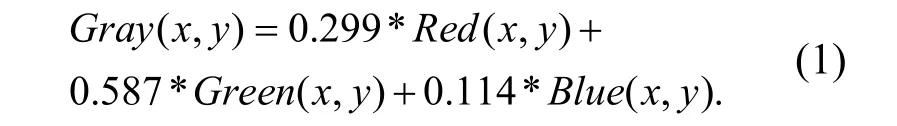
3.3 图片二值化
3.3.1 基本概念
图片的二值化[4-5],就是将图片变成黑或者白2 种颜色﹒在很多场合,对图片进行二值化,可以忽略图片的颜色信息、背景信息,保留更加重要的形态信息﹒并且图片二值化处理之后,图片的信息量大为减少,处理起来也更加方便﹒
二值化常用的方法是设定一个阈值T,用T将图片的数据分成2 部分:大于T 的像素群和小于T 的像素群[4]﹒常用的确定最佳阈值的算法有很多种,如双峰法、P 参数法、OTSU 法和最大熵阈值法等[5]﹒本系统采用OTSU 算法,它具有简单、易实现和执行速度快等特点﹒
3.3.2 OSTU 算法原理
OSTU 算法的基本思想是用某一假定的灰度值t 将图片的灰度分成2 组,求出2 组的类间方差,将t 在0~255 灰度值之间进行迭代,当2 组的类间方差最大时,此灰度值t 就是图片二值化的最佳阈值[6]﹒设图片有M 个灰度值,取值范围在0~(M−1)(在灰度图里,M 的值为256),在此范围内选取灰度值t;再将图片分成2 组(即G0和G1),G0包含的像素的灰度值在0~t,G1的灰度值在(t+1)~(M−1);用N 表示图片像素总数,ni表示灰度值为i 的像素的个数﹒已知每个灰度值出现的概率为pi=ni/N,假设G0和G12 组像素的个数在整体图片中所占百分比为w0和w1,2 组的平均灰度值为u0和u1,可得式(2)~式(8)所示参数[7]﹒
概率:

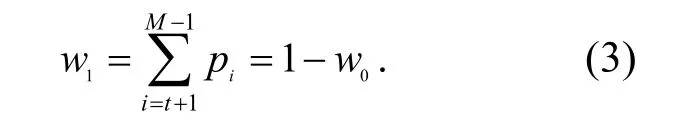
平均灰度值:
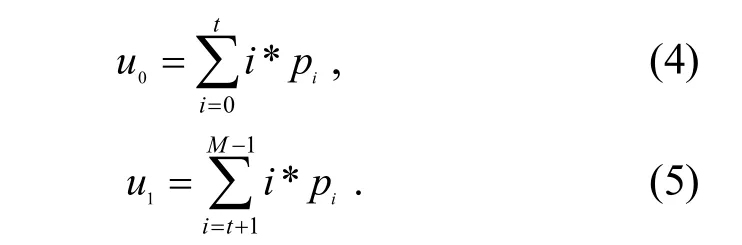
图片的总平均灰度:
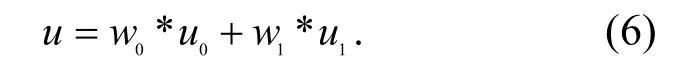
类间方差:
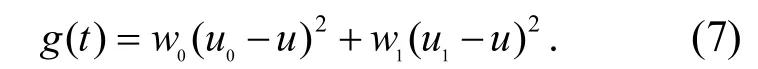
最佳阈值:

3.3.3 OTSU 算法实现
根据OTSU 算法原理,可以通过以下步骤求出每张灰度图的最佳阈值﹒
1)统计图片0~255 个灰度值中每个灰度值出现的数量,放在pixel_counts 数组中;
2)假定初始阈值best_threshold=0.0,最大方差max_g=0.0;
3)阈值threshold 从0 开始一直到255,循环执行步骤4)~步骤9);
4)根据pixel_counts 数组,求得阈值以下像素总数n0和阈值以上像素总数n1;
5)用n0和n1分别除以图片像素总数,得到w0和w1;
6)根据式(4)~式(6),求出图片的总平均灰度u;
7)根据式(7),求出类间方差g(t);
8)当g(t)值大于max_g 时,则max_g=g,且best_threshold=threshold;
9)返回步骤3),直到循环结束,最后得到的best_threshold 就是最佳阈值﹒
cropped 文件夹下的图片经过预处理后,得到其灰度图和二值图,如图4 所示﹒

图4 预处理后的图片
4 字符识别
4.1 训练字库
本例图片中的字符具有特殊性,尤其是数字是艺术字形式﹒Tesseract-OCR 引擎自带的字库对这些特定的字符识别率不高,为了提高识别率,需要额外做些优化,优化的重点主要集中在提高识别单个字符的准确率﹒OCR 对获取到的图片进行操作的步骤如下:
1)通过灰度化、二值化和去噪点使得图片的内容更加突出,为下一步定位字符做准备﹒
2)从图片中定位出字符,理想情况下能够定位到单个字符﹒
3)获取定位到的字符,将其特征和特征数据进行对比,从而判断是什么字符﹒
对指定的字符而言,不同的字体所表现出来的特征也不一样﹒OCR 的任务就是将定位到的字符的字形特征和其已知的特征进行比较,从而判断出该字符是什么﹒如果OCR 本身的特征列表里面不包括要识别的字体特征,那么识别的准确率肯定不理想﹒因此,有必要增加一种对字体的支持,即要训练一个待识别字符的字库,其具体步骤如下:
1)获取或者生成包括这种字体的图片,转化成tif 格式﹒
2)通过Tesseract 的makebox 命令定位和识别字符,生成box 文件﹒
3)通过jTessBoxEditor 等工具矫正识别出来的字符﹒
4)根据box 文件和tif 文件进行特征提取和字库训练﹒
5)生成训练数据﹒
4.2 字符识别
利用谷歌开源OCR 引擎Tesseract 对图片进行字符识别﹒在系统中实现对一张图片的字符识别只需调用pytesseract 库里的image_to_string 方法,其代码只有1 行,即 text=pytesseract.image_to_string(img, lang= LANG, config='--psm 7--oem 3')
其中,text 就是识别后返回的字符内容;LANG是自己训练的字库或者Tesseract自带语言包;img是预处理后的图片﹒
4.3 识别矫正
即使训练了字库,Tesseract 依然会出现拒识或误识的现象,其识别准确率可能仍无法满足要求,故需要进一步的矫正﹒对于灰度图,可以进行灰度调整,也就是对比度增强[8]﹒增强对比度的目的是改善图片的视觉效果,更加利于人或机器分析有意义的信息以及抑制无用信息,提高图片的使用价值﹒通过调用PIL 库的ImageEnhance模块来实现灰度增强,其关键代码为
n_img=ImageEnhance.Contrast(img).enhance(10).
以其中1 张灰度图为例,实验发现增强前拒识,增强后则识别正确,如图5 所示﹒

图5 灰度增强前、后识别效果对比
5 结果分析
本系统共训练了2 个字库,即灰度图字库和二值图字库﹒实验在2 种字库下对灰度图和二值图分别进行字符识别,并统计字库训练前、训练后和矫正后的识别错误率及识别时间等数据﹒所得结果如表1~表2 所示﹒
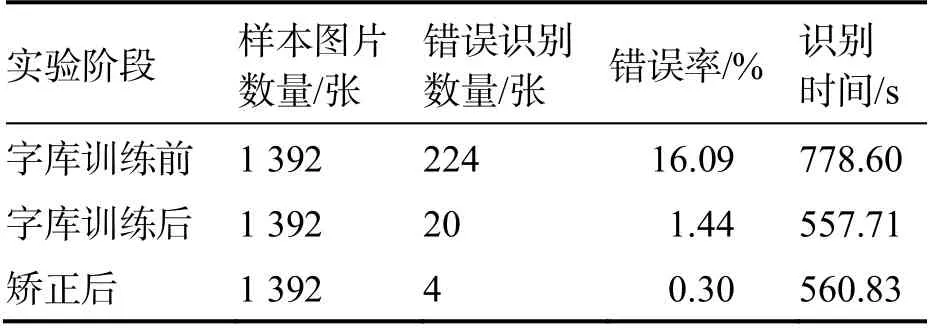
表1 灰度图实验结果
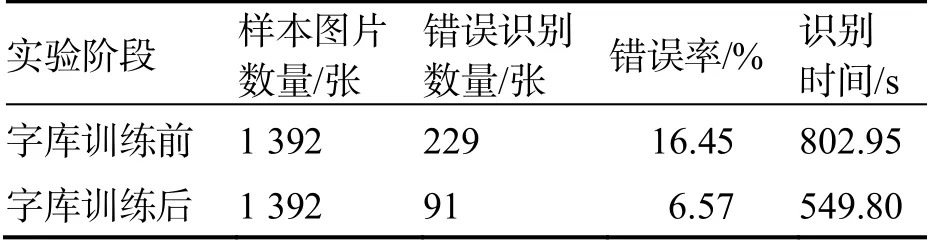
表2 二值图实验结果
从表1 和表2 可以得出以下结论:
1)训练字库可以有效地提高Tesseract 的识别准确率和识别速度﹒
2)灰度图比二值图在训练字库之后的字符识别准确率更高﹒
3)灰度图可以通过增强图片对比度进一步地提高识别准确率,而二值图因无法进行对比度增强处理,所以无法再次提高准确率﹒显然,本系统更适合使用灰度图作为字符识别的样本图片﹒
6 结语
本文详细地介绍了如何利用Tesseract-OCR技术,针对某特定场合,设计和实现字符识别系统﹒系统先经过对图片的分割、灰度化和二值化等预处理过程,再利用Tesseract 对特定字符进行针对性的训练,并完成了字符识别和矫正﹒结果表明,Tesseract 字库训练可有效提高字符识别准确率和识别速度,同时也发现灰度图更适合作为本特定场合的样本图片﹒本系统虽不具有通用性,但对于其他类似特定场合下的字符识别具有一定实际参考价值﹒
