基于改进RFM与GMDH算法的MOOC用户流失预测
2020-11-06魏玲郭新悦
魏玲 郭新悦

【摘要】
MOOC在全球引起在线学习风靡的同时存在着严峻的挑战。通过调查发现MOOC用户中途放弃课程学习的现象十分严重。为最大限度保持和发展更多的MOOC用户,需要对其流失状态进行准确预测,确保对学习危机用户及时发出预警。本研究首先通过改进商业领域中RFM模型建立针对MOOC用户学习行为与流失预测的RFLP指标体系;其次通过直方图检验与卡方检验确定影响MOOC用户流失的特征变量;最后结合数据分组处理(GMDH)网络作为后置处理信息系统构建MOOC用户流失预测模型。利用该模型对中国大学MOOC上一门课程的学习者流失状态进行预测,并与经典决策树C5.0和支持向量机SVM算法进行实验对比。研究结果表明,该模型对MOOC用户流失判别的预测精度更高且在不同数据规模与极端值干扰下均有良好表现。
【关键词】 MOOC;在线学习;学习者;学习者流失预测;学习预警;学习危机;GMDH算法;RFM模型;学习分析
【中图分类号】 G434 【文献标识码】 A 【文章编号】 1009-458x(2020)9-0039-06
一、引言
近年来,众多大规模开放在线课程(Massive Open Online Course, MOOC)平台相继涌现并快速发展,但仍存在诸多问题。相关研究结果显示,大多数MOOC用户所选课程的实际完成平均率低于10%(袁松鹤, 等, 2014),用户自主学习网络课程时中途放弃的现象尤为突出。对于如此严重的用户流失情形,康叶钦(2014)认为,平台注册人数的骤增与最初的用户个性化学习产生矛盾冲突,导致用户学习质量下降,主动学习能力匮乏,继而引发MOOC注册者课程完成率低的问题。邵进(2017)指出,有充裕时间学习网络课程或兴趣爱好较多且学习能力较强的MOOC注册者同时选择多门课程进行在线学习,也可能导致MOOC平台某些课程完成率低。为尽可能保持和发展更多的学习用户,MOOC平台管理者需要密切关注课程学习者行为,精准预测其流失状态,以便课程组织者和运营人员对学习危机用户采取一定的预警措施。本研究以MOOC平台用户学习行为特征为基础,利用改进的RFM分析方法对在线学习者流失预测的指标变量进行定义,同时结合数据分组处理(Group Method of Data Handling, GMDH)算法构建MOOC用户流失预测模型,以此为基础帮助平台管理者解决用户流失预测方面的相关问题,促进平台的可持续发展。
二、研究现状
目前,在线学习者行为模式发现、学业成绩预测、流失预测指标体系等已成为教育数据研究领域的热点与重点(范逸洲, 等, 2018)。国内学者更倾向于利用大数据、学习分析等技术进行学习者模型、学习反馈与评价等方面的研究,对于学习者流失预测的研究仍处于起步阶段。王雪宇等(2017)针对不同课程利用多元线性回归和神经网络算法建立不同的预测模型对学习者进行流失预测,取得较好效果。卢晓航等(2017)根据课程数据特点提取相应特征,利用支持向量机与长短期记忆法构建滑动窗口模型动态预测MOOC用户流失。舒莹等(2019)对处于流失边缘的学生进行聚类分组,采用朴素贝叶斯构建流失预测模型,并通过邮件进行学习干预。国外研究者也对在线学习用户流失预测进行了大量探索,如Amnueypornsakul等(2014)利用支持向量机算法对是否包含不活跃用户分别进行流失预测模型构建。结果显示,剔除不活跃用户进行预测模型构建时准确率有很大提升。Fei等(2015)发现在预测学习者流失率方面,逻辑回归算法的能力优于支持向量机算法。Liang等(2016)在一项基于39门学堂在线MOOC用户流失预测分析中,得出梯度提升决策树算法和随机森林算法优于逻辑回归算法和支持向量机算法。当前,国内对MOOC用户流失预测研究较少,本研究借助营销领域中发展成熟的客户行为理论以及数据挖掘技术手段,基于改进RFM模型与GMDH算法构建MOOC用户流失预测模型,以期為在线学习领域用户流失预测的研究提供有价值、可参考的理论和实践依据,解决MOOC发展过程中面临的相关问题。
三、构建MOOC用户流失预测模型
(一)模型理论研究方法
1. 构建RFLP指标体系
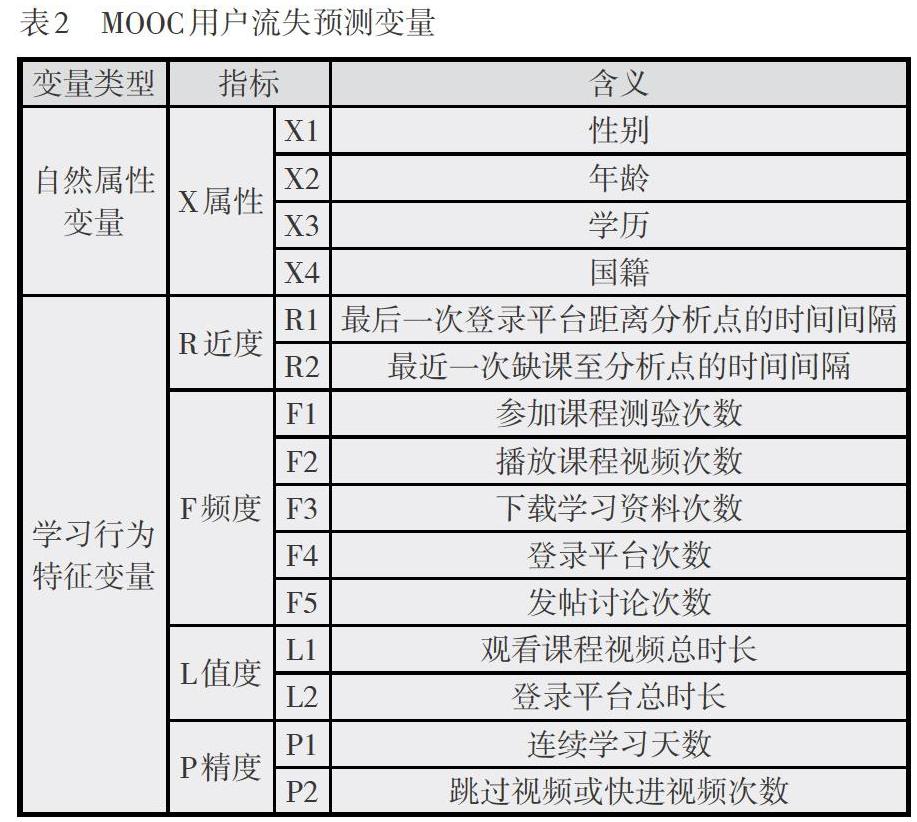
RFM模型是对客户行为特征进行分析的重要方法之一,通过近度R( Recency) 、频度F( Frequency)、值度M( Monetary) 3个行为变量对客户进行分类(Hughes, 1994)。传统RFM模型通过电子商务平台中客户以往的购买行为,对客户未来的短期行为进行预测。MOOC平台区别于普通电子商务平台,即:多数MOOC用户在学习过程中并没有产生实际消费,但二者在某种程度上具备一定的关联性。本研究通过改进RFM模型构建,针对MOOC用户学习行为与流失预测的RFLP指标体系,详细内容如表1所示。在RFLP指标体系中指标P(Precision)代表学习精度,测量类型包括学习者在某一期间内连续学习天数、大量跳过视频以及快进视频的次数等,是可以说明用户学习毅力与学习耐心的行为指标。通过对用户学习毅力与耐心的掌握判断其是否容易流失,如连续学习天数越多,学习者越容易养成学习习惯,进而可以判定学习者具有较好的学习毅力。跳过视频以及快进视频次数则可以判定学习者的学习耐心。加入学习精度指标可以更精准地预测用户流失状态。
2. GMDH的起源与内涵
数据分组处理是自组织数据挖掘的核心技术(Ivakhnenko, 1970),是以参考函数构成的初始模型为基础,依据相应法则产生第一代中间候选模型,从中筛选出最优的若干项,再依据一定法则产生第二代中间候选模型,此过程不断反复进行使中间模型复杂度逐步提高,直至得到最优复杂度模型的学习过程。GMDH算法具有以下特点:第一,通过计算机利用原始数据与外准则自动筛选出变量,从而使模型结果较为客观、公正;第二,由于只需数据、准则便可进行预测,在其他领域中可实现性强;第三,GMDH算法有很强的抗干扰能力;第四,在建模过程中能够利用自组织方式自动生成最优复杂度模型,不需人为设定函数关系式,因此模型的拟合精度相较于其他模型更高,适应性较强且预测效果更好。
(二)MOOC用户流失指标变量选取
在对MOOC用户流失状态进行预测之前,需准确选取预测变量。首先,通过调研MOOC用户实际学习情况并结合RFLP指标变量,总结出可能影响在线学习用户流失的初始变量。其次,对这些初始变量进行筛选,检验其对预测在线学习用户流失是否存在一定影响。本研究先后利用直方图检验与卡方检验两种检验方法,前者可直观地分辨出某个变量是否作用于在线学习用户流失行为,而后者可以进一步判断特征变量对预测结果的影响程度。最后,在确定预测MOOC用户流失的特征变量后,对预测指标变量的取值做归一化处理。基于RFLP指标选出MOOC用户流失特征变量,然后结合GMDH网络构建MOOC用户流失预测模型,可有效降低GMDH网络的复杂性并且缩短其训练时间(朱帮助, 等, 2011)。
(三)MOOC用户流失预测模型
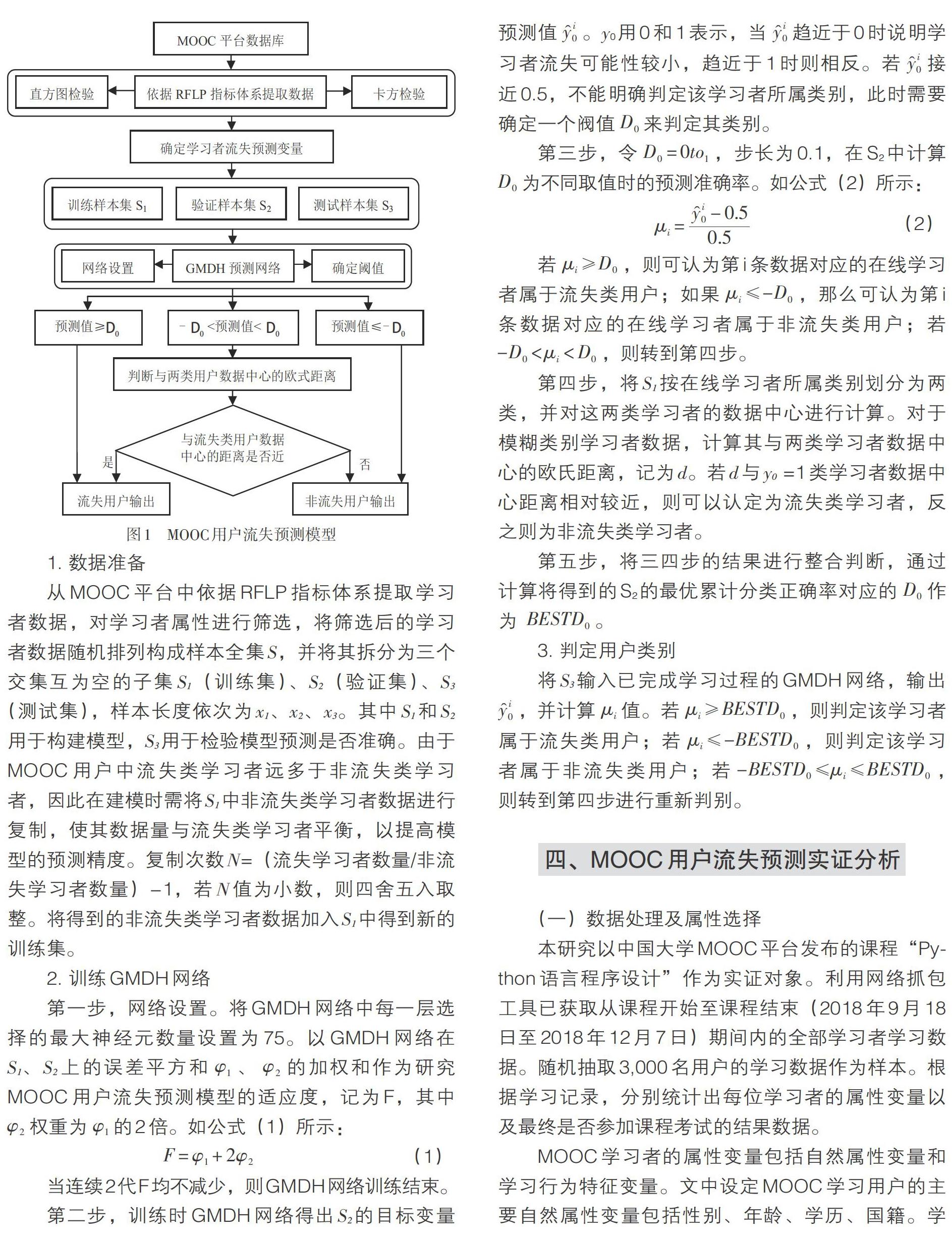
利用Matlab软件构建MOOC用户流失预测模型,如图1所示。
1. 数据准备
从MOOC平台中依据RFLP指标体系提取学习者数据,对学习者属性进行筛选,将筛选后的学习者数据随机排列构成样本全集S,并将其拆分为三个交集互为空的子集S1(训练集)、S2(验证集)、S3(测试集),样本长度依次为x1、x2、x3。其中S1和S2用于构建模型,S3用于检验模型预测是否准确。由于MOOC用户中流失类学习者远多于非流失类学习者,因此在建模时需将S1中非流失类学习者数据进行复制,使其数据量与流失类学习者平衡,以提高模型的预测精度。复制次数N=(流失学习者数量/非流失学习者数量)-1,若N值为小数,则四舍五入取整。将得到的非流失类学习者数据加入S1中得到新的训练集。
2. 训练GMDH网络
第一步,网络设置。将GMDH网络中每一层选择的最大神经元数量设置为75。以GMDH网络在S1、S2上的误差平方和[φ1]、[φ2]的加权和作为研究MOOC用户流失预测模型的适应度,记为F,其中[φ2]权重为[φ1]的2倍。如公式(1)所示:
当连续2代F均不减少,则GMDH网络训练结束。
第二步,训练时GMDH网络得出S2的目标变量预测值[yi0]。y0用0和1表示,当[yi0]趋近于0时说明学习者流失可能性较小,趋近于1时则相反。若[yi0]接近0.5,不能明确判定该学习者所属类别,此时需要确定一个阀值[D0]来判定其类别。
第三步,令[D0=0to1],步长为0.1,在S2中计算[D0]为不同取值时的预测准确率。如公式(2)所示:
若[μi≥D0],则可认为第i条数据对应的在线学习者属于流失类用户;如果[μi≤-D0],那么可认为第i条数据对应的在线学习者属于非流失类用户;若[-D0<μi 第四步,将S1按在线学习者所属类别划分为两类,并对这两类学习者的数据中心进行计算。对于模糊类别学习者数据,计算其与两类学习者数据中心的欧氏距离,记为d。若d与y0 =1类学习者数据中心距离相对较近,则可以认定为流失类学习者,反之则为非流失类学习者。 第五步,将三四步的结果进行整合判断,通过计算将得到的S2的最优累计分类正确率对应的[D0]作为[ BESTD0]。 3. 判定用户类别 将S3输入已完成学习过程的GMDH网络,输出[yi0],并计算[μi]值。若[μi≥BESTD0],则判定该学习者属于流失类用户;若[μi≤-BESTD0],则判定该学习者属于非流失类用户;若[-BESTD0≤μi≤BESTD0],则转到第四步进行重新判别。 四、MOOC用户流失预测实证分析 (一)数据处理及属性选择 本研究以中国大学MOOC平台发布的课程“Python语言程序设计”作为实证对象。利用网络抓包工具已获取从课程开始至课程结束(2018年9月18日至2018年12月7日)期间内的全部学习者学习数据。随机抽取3,000名用户的学习数據作为样本。根据学习记录,分别统计出每位学习者的属性变量以及最终是否参加课程考试的结果数据。 MOOC学习者的属性变量包括自然属性变量和学习行为特征变量。文中设定MOOC学习用户的主要自然属性变量包括性别、年龄、学历、国籍。学习行为特征变量依据指标R、F、L、P进行划分。通过调研参加课程的用户在线学习实际情况将各指标划分为15个可能影响MOOC用户流失的初始变量,具体内容如表2所示。本研究以学习者最终没有参加课程考试作为判断学习者属于流失类用户结果的属性变量,记为Y。 对表2中的最初变量进行相关检验后选出最终的预测指标。在直方图检验中可以直观地辨别一个变量是否作用于MOOC用户流失行为。任意选择1个变量为例,如图2所示。随着学习者播放课程视频次数(F2)的增加,学习者流失人数明显随之减少,说明指标F2对用户流失具有明显作用。对上述指标依次进行检验,发现指标X1性别和X4国籍与流失用户数量不存在规律性分布,即对用户的流失无明显作用,故将其删除。 为精确变量影响程度,对其余指标进行卡方检验,结果如表3所示。 综合两种方法检验结果,最终以X2、X3、R1、R2、F1、F2、F3、F4、F5、L1、P1作为预测模型的属性变量。根据确定的预测属性变量,统计随机抽取的3,000位平台用户的学习数据并进行归一化处理。 (二)GMDH网络学习结果 课程持续时间为12周,选取前6周学习该课程的用户数据进行分析与预测,后6周学习数据用于核查3,000名学习者的用户流失状态。根据平台提供的学习数据可知3,000名学习者中有2,042名用户流失(2,042名学习者没有完成课程考试)和958名学习者没有流失(最后顺利完成课程考试并取得成绩)。样本全集S由3,000名学习者的相关学习数据组成,在S中随机抽取600个样本作为验证样本集S2,随后再从其余2,400个样本中随机抽取出600个样本作为测试样本集S3,将最后剩余的1,800个样本作为训练集S1。最终形成的S1、S2、S3中流失用户依次为1,359、313、370名,非流失用户依次为441、287、230名。 训练集S1中流失类学习者数量约是非流失类学习者数量的3倍,因此本研究将S1中所有非流失类学习者数量全部复制2倍后,将其加入到S1中形成新的训练集。当迭代次数为7,适应度F=36.567时,满足停止条件训练完成。在预测过程中,GMDH网络给出S2中每个学习者的目标变量预测值,计算相应[μi]值、比较取不同[D0]时的累计分类正确率,最终得出[BESTD0=0.4],此刻在S2中的累计分类正确率为94.31%。 (三)模型预测精度检验比较 将测试集S3中的600个学习者数据输入到已完成学习过程的GMDH网络中进行预测,验证基于RFLP和GMDH网络的预测模型在MOOC用户流失预测中的有效性和可行性,最后结果正确判断了557名学习者的流失状态,其中61名学习者的[μi]值在(-0.4,0.4)内,利用步骤2中的第四步进行相关判断,其中47名被判断为流失用户,同实际结果对比,判断正确34名、错判13名;其中14名被判断为非流失用户,同实际结果对比,最后得出判断正确10名、错判4名的结果。为更好地验证本研究构建的预测模型准确率,将基于RFLP和GMDH网络的预测模型与决策树C5.0和SVM模型的预测精度用以下四个评价标准进行比较:①非流失用户正确分辨率;②流失用户正确分辨率;③总体正确分辨率;④模型ROC曲线下的面积(AUC)。基于以上四个评价标准将本研究提出的模型预测精度与SVM、决策树C5.0模型的预测精度进行对比,结果见表4。 根据表4可得出,本研究构建的预测模型误判数量相较于决策树C5.0和SVM模型明显较低,前者误判数量为43(30+13),后两者误判数量分别为97(49+48)和116(82+34)。并且非流失用户预测精度、流失用户预测精度、总体预测精度和AUC值都高于经典的决策树C5.0模型和SVM模型,前者分别为94.3%、91.9%、92.8%、0.9275,后两者分别为79.1%、86.8%、83.8%、0.8479和85.2%、77.8%、80.6%、0.8235。另外,在不同數据规模下SVM随着数据样本加大精确度较另外两种算法下降幅度较大,在出现极端值时决策树较另外两种算法会出现过度拟合情况导致准确率下降,且GMDH算法的训练和分类与决策树和SVM算法相比更加简单,具有较高的实用性,进而验证了本研究构建的预测模型对于MOOC用户流失预测领域具有实际意义。 五、结语 信息技术的飞速发展和MOOC平台的盛行正吸引越来越多的学习者。MOOC用户流失预测对有流失倾向的学习者采取相应的挽留措施,对MOOC平台保持用户以及提升平台核心竞争力至关重要。本研究构建针对MOOC用户的流失预测研究模型,以商业领域中RFM分析方法为基础提出RFLP学习者预测指标体系,通过直方图与卡方检验确定预测模型的指标变量并采集数据,利用GMDH网络作为后置处理信息系统对MOOC用户流失状态进行预测。通过中国大学MOOC中的真实课程数据进行实证检验,结果表明本研究提出的基于RFLP和GMDH的MOOC用户流失预测模型是有效的,与决策树C5.0和SVM模型相比,学习者流失判别的预测精度更加准确,且具有较高的实用性,一定程度上很好地弥补了在线学习领域中用户流失预测研究的不足。同时,该模型中的RFLP指标体系可以为MOOC平台全面发掘流失类用户的真实情况,为提高MOOC用户留存提供较好的决策支持。 [参考文献] 范逸洲,刘敏,欧阳嘉煜,等. 2018. MOOC中学习者流失问题的预测分析——基于24篇中英文文献的综述[J]. 中国远程教育(04):5-14,79. 康叶钦. 2014. 在线教育的“后MOOC时代”——SPOC解析[J]. 清华大学教育研究,35(1):85-93. 卢晓航,王胜清,黄俊杰,等. 2017. 一种基于滑动窗口模型的MOOCs辍学率预测方法[J]. 数据分析与知识发现,1(04):67-75. 邵进. 2017. 打造精品慕课助力教学改革[J]. 中国大学教学(2):12-14. 舒莹,姜强,赵蔚. 2019. 在线学习危机精准预警及干预:模型与实证研究[J]. 中国远程教育(08):27-34,58,93. 王雪宇,邹刚,李骁. 2017. 基于MOOC数据的学习者辍课预测研究[J]. 现代教育技术,27(06):94-100. 袁松鹤,刘选. 2014. 中国大学MOOC实践现状及共有问题——来自中国大学MOOC实践报告[J]. 现代远程教育研究(4):3-12. 朱帮助,张秋菊,邹昊飞,等. 2011. 基于OSA算法和GMDH网络集成的电子商务客户流失预测[J]. 中国管理科学,19(5):64-70. Amnueypornsakul, B., Bhat, S., & Chinprutthiwong, P. (2014). Predicting Attrition Along the Way: The UIUC Model. EMNLP 2014 Workshop on Analysis of Large Scale Social Interaction in MOOCs (pp. 55-59). Fei, M., & Yeung, D. Y. (2015). Temporal models for predicting student dropout in massive open online courses. IEEE International Conference on Data Mining Workshop (pp. 256-263). Hughes, A. (1994). Strategic database marketing. Chicago: Probus Publishing. Ivakhnenko, A. G. (1970). Heuristic Self-organization in Problems of Engineering Cybernetics. Avtomatika, 6(2), 207-219. Liang, J., Li, C., & Zheng, L. (2016). Machine learning application in MOOCs: Dropout prediction. International Conference on Computer Science & Education (pp. 52-58). 收稿日期:2019-04-10 定稿日期:2020-01-12 作者简介:魏玲,博士,教授,硕士生导师;郭新悦,硕士研究生。哈尔滨理工大学经济与管理学院(150040)。 责任编辑 张志祯 刘 莉