土壤速效磷近红外迁移学习预测方法研究
2020-11-06郑文瑞李绍稳韩亚鲁石胜群朱先志
郑文瑞,李绍稳,韩亚鲁,石胜群,朱先志,金 秀
(安徽农业大学 信息与计算机学院 智慧农业技术与装备安徽省重点实验室,安徽 合肥 230036)
土壤速效磷(Available phosphorus,AP)是农作物生长过程中所必须的营养元素,检测土壤中AP含量在作物精准施肥和环境保护方面具有重要意义[1]。近年来,国内外均有利用可见-近红外光谱预测土壤AP含量的报道,且取得了良好效果。如齐海军等[2]提出利用偏最小二乘回归(PLSR)对可见-近红外光谱数据进行特征提取和降维,将得到的潜在变量和特征波长分别输入反向传播神经网络(BPNN)建立了土壤AP含量预测模型,与全波长数据建模结果相比,PLS-BPNN算法能有效地降低高光谱数据冗余和共线性影响。Paz-Kagan等[3]利用机载成像光谱技术(IS)绘制光谱土壤质量指数(SSQI)图,为SSQI的评估提供了一种快速可靠的方法,该方法采用PLSR算法在350~2 500 nm可见-近红外光谱区域建立的土壤AP回归模型的相对分析误差(RPD)达到1.92。目前,研究主要集中于对同一地区土壤样本进行建模预测,存在预测样本采集地区改变,已建光谱模型不能提供准确的预测结果,出现模型失效的问题[4]。而新地区重新采集大量样本建模会增加成本、降低效率,并降低对已有土壤样本的利用率。
本研究拟低成本将皖南地区土壤AP预测模型迁移给皖北地区使用。研究的关键在于解决不同地区土壤光谱差异即光谱数据不同分布问题,因为传统回归算法假设训练集和测试集的数据必须是同分布的。为此,本文采用迁移学习(Transfer learning)[5]中迁移成分分析(Transfer component analysis,TCA)[6]方法以减少不同地区间的光谱差异,在皖南和皖北土壤光谱进行TCA变换前后,设计了4个基于不同训练集建立模型,预测皖北地区土壤AP含量。
1 实验部分
1.1 样本采集与处理
采集了安徽省两种不同类型的土壤样本共180份,其中皖南地区为黄山区乌石乡桃园基地和池州市石台县大演乡,共计120份,土壤类型为黄红壤土;皖北地区为蒙城县和宿州市埇桥区共计60份,土壤类型为砂姜黑土。采样深度均为0~20 cm。样本采集后密封带回实验室风干、研磨,过20目筛,再进行光谱数据采集,并从每个土壤样本中取出部分用于实验室理化检测。
使用OFS1700地物光谱仪(海洋光学公司)和50 W卤钨灯接触式反射探头采集土壤近红外光谱数据,光谱范围为350~1 700 nm,其中350~900 nm的光谱分辨率为2 nm,900~1 700 nm的光谱分辨率为5 nm。土壤AP的理化检测使用碳酸氢钠浸提-钼锑抗分光光度法[7],由安徽农业大学资源与环境学院土壤学实验室完成。
1.2 数据处理
1.2.1 迁移学习方法迁移学习是机器学习中一个重要研究问题,侧重将前期的学习经验适应于新的学习中,提高新的学习效率[8]。迁移成分分析(TCA)是一种经典的基于特征的迁移学习方法,旨在让一个领域学习到的模型适应到另一个不同但相关的领域中[6]。它与主成分分析(PCA)算法[9]类似之处在于均可实现降维,但PCA并不能解决源域(Source domain)和目标域(Target domain)数据不同分布的问题。TCA通过将不同边缘概率分布的源域和目标域数据映射到一个高维的再生核希尔伯特空间(RKHS)[10-11],在此空间中通过最小化源域和目标域数据距离以减少其数据分布差异,同时最大程度地保留了各自的内部属性。刘翠玲等[12]利用TCA方法研究不同光谱仪间食用油光谱模型的传递,Tao等[13]利用TCA方法研究不同地区间土壤砷污染诊断模型的可转移性,均得到了具有良好预测性能的迁移模型。
目前,很多方法可尝试减小源域和目标域间的距离,而TCA的贡献在于其计算距离的方法更加简单。TCA算法步骤如下:首先,定义源域和目标域的光谱数据分别为Xs=[xs1…xsi…xsns]和Xt=[xt1…xti…xtnt],xsi和xti为光谱特征向量,ns、nt分别为源域和目标域样本数量。然后在RKHS空间中通过最大均值差异(MMD)[14]来度量Xs和Xt的边缘分布距离,公式如下:

(1)
找到一个合适的映射φ可以使得这个距离最小,但φ通常是高度非线性的,难以寻求。于是Pan等[15]提出将这个距离的最小化问题转化为核学习问题,利用核技巧k(即k(xixj)=φ(xi)Tφ(xj))可以将公式(1)改写为核矩阵的迹:
Dist(Xs,Xt)=trace(KL)
(2)
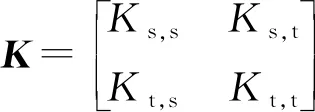
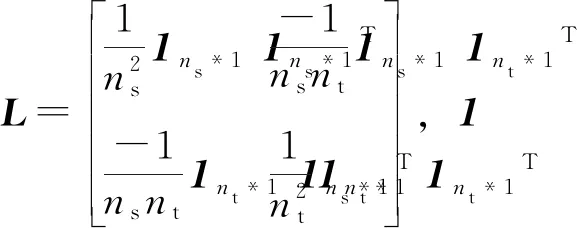
(3)
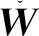
(4)
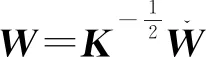
Dist(Xs,Xt)=trace((KWWTK)L)=tr(WTKLKW)
(5)
最小化公式(5),得到的W表示TCA降维后源域和目标域的光谱矩阵,则转变为求:
minwtr(WTKLKW)+μtr(WTW)
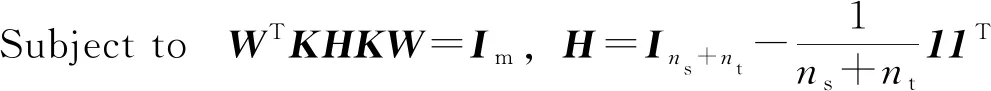
(6)
其中,μ为一个平衡参数,正则化项tr(WTW)的加入是为了控制W的复杂度。加入约束WTKHKW=Im是为了避免平凡解(即W=0)。最终,Pan等[6]通过数学推导得出,W的解即为(KLK+μI)-1KHK的前m个特征值对应的特征向量,将其输出得到源域和目标域TCA转移后的数据,即可使用传统回归算法运算。
1.2.2 基于TCA的实验方法PLSR算法[16]是一种适用性广泛的化学计量学建模方法,它将光谱变量矩阵和浓度矩阵同时进行分解并考虑二者间的相互关系,从而加强了两者的对应计算关系,且计算速度快,但PLSR是基于线性回归的多元校正方法,光谱变量和浓度间存在一定的非线性,当非线性严重时,则不能建立理想的校正模型;SVR算法[17]是常用的非线性校正方法,具有很强的抗过拟合能力,但它存在数据量过大会减慢建模速度的缺点,PLSR和SVR均被广泛应用于光谱分析中。本研究设计了4个实验,在光谱预处理后,将源域划分为源域训练集和源域测试集,目标域划为目标域训练集和目标域测试集,建模方法选择PLSR和SVR,基于此设计实验①~③,再结合TCA方法设计实验④,总体实验流程图见图1。4个实验内容如下:①采用目标域训练集建模,对目标域测试集样本进行预测,用于研究样本量不大的情况下能否建立具有良好预测效果的模型。②采用源域训练集建模,对目标域测试集样本进行预测,用于研究源域模型能否直接给目标域使用的模型。③采用源域训练集混合目标域训练集建模,对目标域测试集样本进行预测,用于研究部分目标域样本加入源域训练集能否提高模型预测精度的模型。④用TCA变换后的源域训练集混合目标域训练集建模,再对TCA变换后的目标域测试集样本进行预测,研究基于TCA光谱变换和部分目标域样本加入训练集建立的模型是否能显著提升预测精度。对4个实验模型的性能进行评估和对比,分析采用TCA方法能否将源域模型应用于目标域,提高对目标域的预测精度。
1.2.3 模型评价参数模型预测性能的评价标准选用预测均方根误差(RMSEP)、决定系数(R2)和相对分析误差(RPD)。RMSEP越小,表明模型的预测性能越好,并采用Chang等[18]划分的预测模型等级(Predictive model level)进行描述:当RPD>2.0且R2≥0.80时,模型具有良好的预测能力,可用于定量预测,为A类模型;当1.4≤RPD≤2.0且0.50≤R2<0.80时,模型具有中等的预测能力,可近似估计,为B类模型;当RPD< 1.4且R2<0.50时,模型具有较差的预测能力,不能用于定量预测,属C类模型。
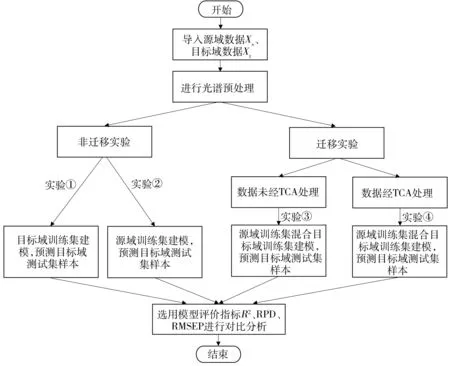
图1 总体实验流程图Fig.1 Experimental flow chart
2 结果与讨论
2.1 样本分析
为降低噪声等的影响,采用Savitzky-Golay卷积平滑(SG)、标准正态变量变换(SNV)和SG+SNV分别对皖南和皖北土壤光谱进行预处理。结果显示,皖南(图2A~D)和皖北(图2E~H)地区土壤光谱曲线差异明显,说明两者的数据分布不同;皖北地区采集的砂姜黑土颜色偏深,故和皖南地区相比原始光谱反射率整体较低(图2A、E);SG平滑能够降低光谱噪声,使得光谱曲线更加平滑(图2B、F);而经SNV预处理后的光谱曲线变化明显(图2C、G);经SG+SNV组合预处理后不仅光谱曲线的变化明显,而且在650~1 000 nm处能观察到有效降低了光谱噪声(图2D、H)。本研究以皖南地区为源域,皖北地区为目标域,经理化检测得到源域和目标域土壤AP含量见表1,再将预处理后的源域数据(src)和目标域数据(tar)分别以2∶1的比例划分为训练集和测试集,结合4个实验得到基于迁移学习的土壤样本划分及分析表(表2)。根据表1~2可知皖南和皖北两个地区尤其是皖南地区总样本AP含量的标准差较大,4个实验中含有皖南地区样本的训练集标准差也更大,所以对数据进行对数变换,使其更接近正态分布[13]。
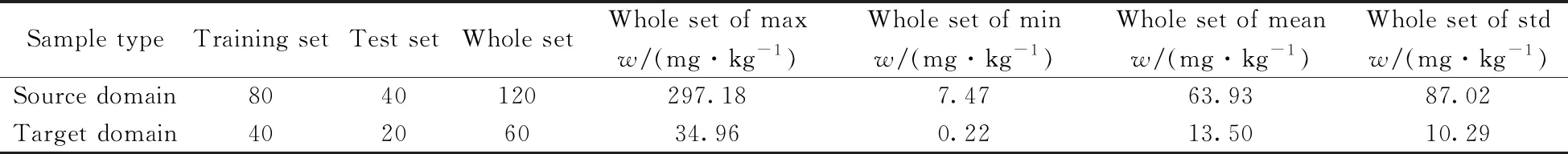
表1 土壤样本AP含量统计Table 1 Statistical of AP content in soil samples

表2 基于迁移学习的土壤样本划分及分析Table 2 Standard deviation of AP content in soil samples
2.2 基于源域及目标域的近红外光谱迁移实验结果
本研究采用4个实验,基于原始数据、3种不同预处理方法(SG、SNV、SG+SNV)和2种建模方法(PLSR、SVR)共建立了32个回归模型,其预测性能见表3。结果显示:实验④全为B类模型,②全为C类模型,①中B类模型较多,③中C类模型较多。图3更直观地展示了4个实验模型的RPD水平差距,②中模型的RPD水平普遍低于其它实验;④对源域和目标域光谱进行TCA变换后建立的模型RPD水平普遍高于其它实验。综上,可得出如下结论:(1) 在样本量不大的情况下建立的模型,预测精度较低;(2)源域模型不能直接用于目标域,会出现模型失效问题;(3) 在源域中加入部分目标域数据建立的模型,预测精度有所提升但仍不理想;(4) 基于TCA光谱变换和部分目标域样本加入训练集,可显著提高模型的预测精度。
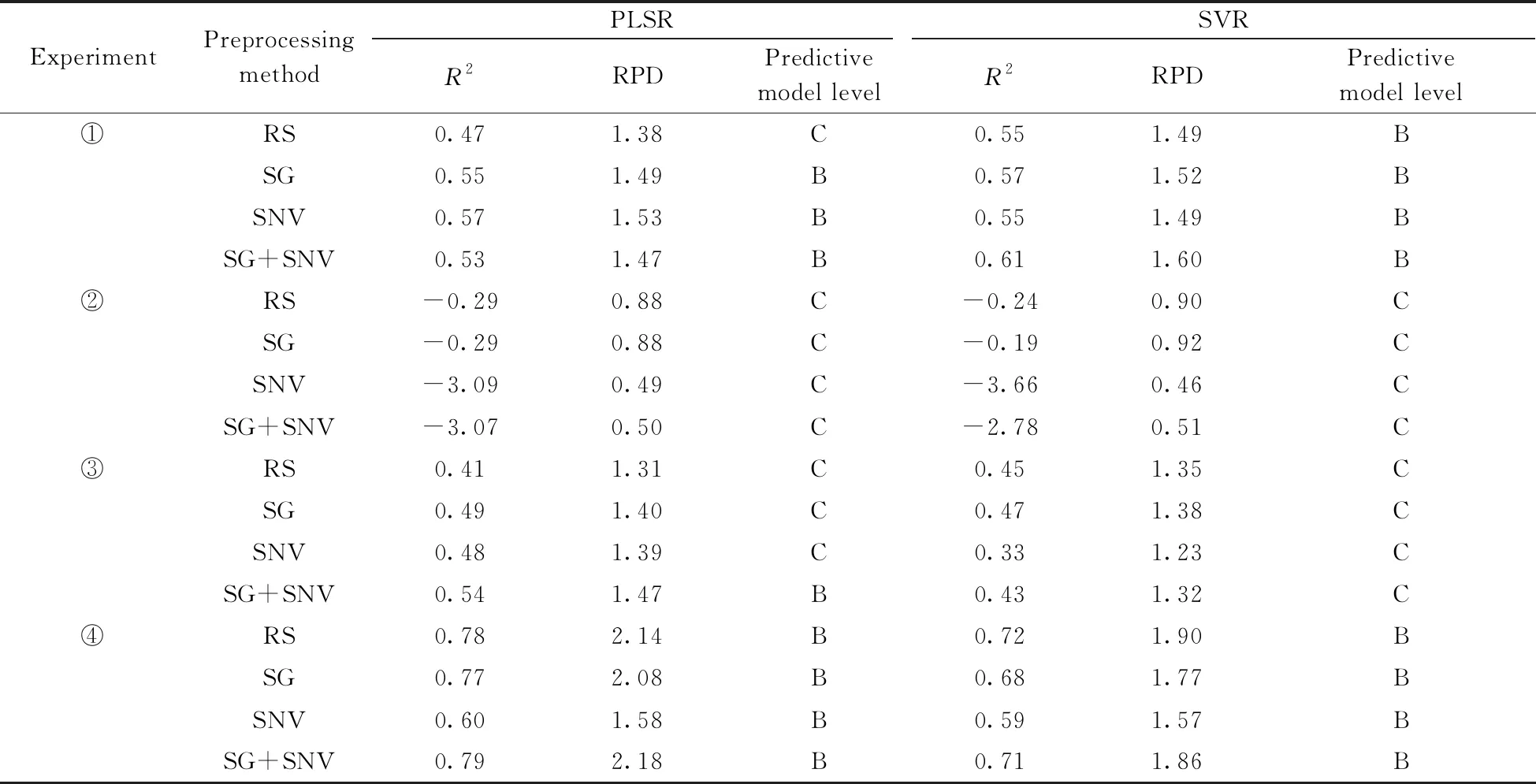
表3 4个实验中基于不同预处理方法和建模方法的模型性能Table 3 Model performances based on different preprocessing methods and modeling methods in four experiments
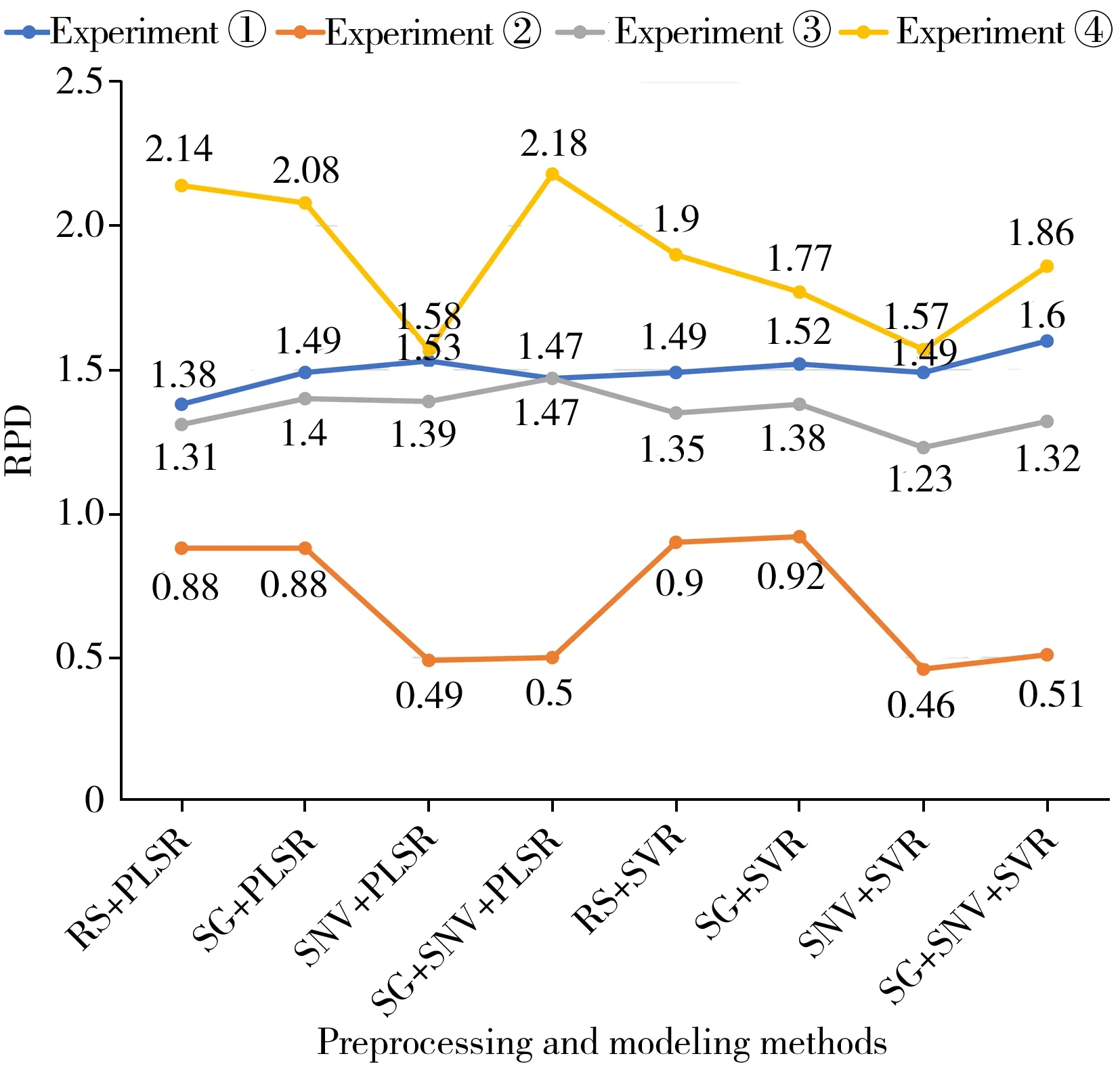
图3 不同预处理和建模方法在4个实验下的RPD水平Fig.3 RPD levels of regression models with different Preprocessing and modeling methods
2.3 讨论与分析
由图3可见,实验①~④中RPD最高模型的预处理和建模组合分别为SG+SNV+SVR、SG+SVR、SG+SNV+PLSR、SG+SNV+PLSR,其回归模型的预测值和测量真实值间的散点图见图4,预测精度见表4。结果显示,实验②模型预测点几乎完全偏离1:1回归线,印证其模型失效(图4B);实验①和③模型预测精度较低,预测点比较分散(图4A、C);而实验④基于TCA光谱变换的预测模型性能较好,预测点最接近1∶1回归线(图4D)。
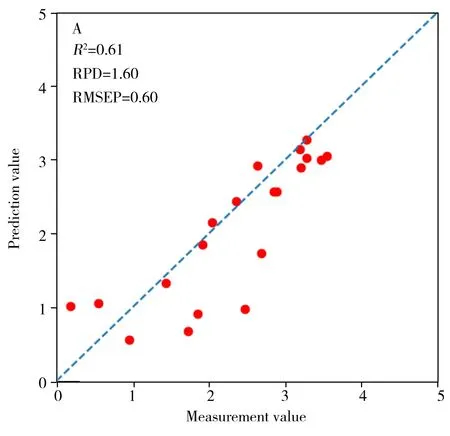
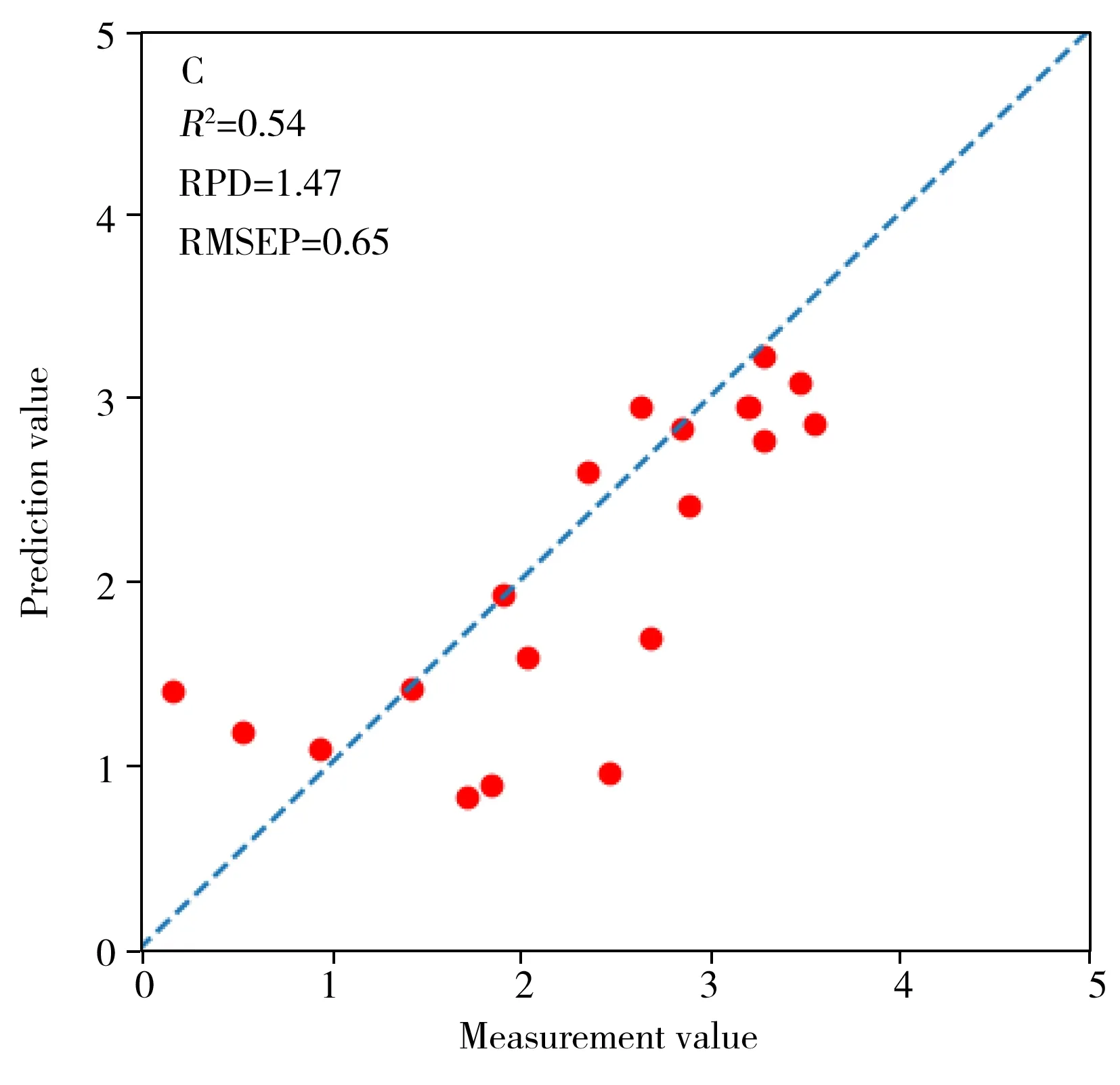

表4 4个实验中RPD最高回归模型预测精度Table 4 Highest prediction accuracy of RPD regression model in the four experiments
结合表4分析,将源域模型直接用于目标域的方法(实验②)不可行,会出现模型失效问题(模型的R2和RPD分别为-0.19和0.92,RMSEP为1.04);在源域训练集中加入部分目标域样本辅助建模(实验③)可缓解模型失效问题,预测精度有所提升,但仍不理想(模型的R2和RPD分别为0.54和1.47,RMSEP为0.65)。针对可能是源域和目标域数据不同分布的原因,采用建模前先对源域和目标域样本进行TCA光谱变换(实验④),可显著提高模型的预测精度(模型的R2和RPD分别为0.79和2.18,RMSEP为0.44)。另外,还发现样本量较小的目标域自身建模(实验①)结果(模型的R2和RPD分别为0.61和1.60,RMSEP为0.60)也明显低于实验④的模型预测精度。以上研究表明,基于TCA的方法能将皖南土壤AP预测模型应用于皖北,从而提高皖北土壤AP模型预测准确性。
3 结 论
本研究对120份皖南和60份皖北土壤样本设计了4个实验,以探究将皖南土壤AP预测模型迁移用于皖北地区。研究结果表明,皖南地区的模型不能直接用于皖北地区;且样本量不大的皖北地区模型的预测精度不高。基于TCA光谱变换可将皖南土壤AP预测模型用于皖北,提高了土壤AP模型预测准确性。该迁移方法的实现,为建立更多地区土壤AP预测模型提供了很好的思路,能提高大面积预测土壤速效磷的准确性并降低成本,具有较好的应用前景。
