最小角回归结合核极限学习机的近红外光谱对柑橘黄龙病的鉴别
2020-11-06陈文丽王其滨路皓翔杨辉华许定舟杜文川
陈文丽,王其滨,路皓翔,杨辉华,3*,刘 彤,许定舟,杜文川
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学 电子工程 与自动化学院,广西 桂林 541004;3.北京邮电大学 自动化学院,北京 100876; 4.广州迅动网络科技有限公司,广东 广州 510700)
近红外光谱分析技术的检测准确度高且在检测过程中不会产生化学以及废弃物等污染,在食品、药品监督以及植物疾病预防等领域得到了广泛的应用[1-4]。柑橘黄龙病菌拉丁学名为Candidatus liberobacter asiaticus,属韧皮部杆菌属,可感染当前所有种类的柑橘。黄龙病又称为柑橘“不死的癌症”,是由黄龙病菌引起的细菌性疾病[5-6]。
我国最早发现柑橘黄龙病是在20世纪初,当时华南地区的一些柑橘种植地发生了这种奇怪的病症,之后在我国的广西、江南等柑橘主产地也逐渐出现。由于柑橘黄龙病的传播性极强且无法彻底根治,所以园区内一旦有果树被感染,就必须砍伐掉园区全部的果树,这种不得已的做法让人民群众背负了沉重的经济负担[7]。因此,对柑橘黄龙病进行早期筛查是一项极为必要的工作。当前,国内外的研究学者尝试将机器学习的方法用于光谱分析技术对柑橘黄龙病进行早期筛查。Wetterich等[8]利用支持向量机(Support vector machine,SVM)和人工神经网络(Artificial neural network,ANN)算法结合荧光成像技术完成了柑橘黄龙病的鉴别以及缺锌症状的检测,其检测准确度分别为92.8%和92.2%。Garcia等[9]首先采用航空成像技术获取柑橘树的光谱图像,然后利用SVM(Liner)对柑橘树的光谱图像进行分析进而实现黄龙病的检测,然而该方法成本极高不宜广泛应用。Sankaran等[10]分析研究了近红外和热成像技术在柑桔黄龙病检测中的应用价值,通过SVM等分类模型实现了黄龙病的检测,但是平均整体分类准确度仅为85%。李修华等[11]通过分析不同条件下的患有柑橘黄龙病果树的近红外光谱特征,快速检测了柑橘黄龙病且无损伤。Xu等[12]采用激光诱导击穿光谱法(LIBS)联合近红外光谱法对黄龙病进行鉴定,训练集和测试集的鉴别准确度分别为89.5%和95.7%,揭示了光学传感器在柑橘黄龙病检测中的潜力。刘燕德等[13]采用无信息变量消除(Uninformative variable elimination,UVE)组合连续投影算法(Successive projections algorithm,SPA)对柑橘叶片的高光谱数据降维,结合偏最小二乘支持向量机(Partial least squares support vector machine,LSSVM)检测柑橘黄龙病,其模型较为复杂,且对全谱的鉴别误差达11.9%。刘燕德等[14]将可见与近红外光谱拼接,结合偏最小二乘判别分析(Partial least squares discriminant analysis,PLS-DA)方法,提高了柑橘黄龙病的检测准确度。虽然国内外的学者针对柑橘黄龙病的检测做了相当多的研究工作,但是近红外光谱技术在黄龙病检测方面的应用研究还处于起始阶段,检测准确度不高。
本文尝试将机器学习算法用于近红外光谱分析技术实现柑橘黄龙病的鉴别,并针对柑橘黄龙病检测准确度较低的问题,采用最小角回归(LAR)算法融合核极限学习机(KELM(RBF))实现了柑橘黄龙病的检测。为了验证LAR-KELM(RBF)模型的有效性,使用傅里叶变换近红外光谱仪对广州讯动网络科技有限公司提供的柑橘叶片进行测定,将测得的漫反射光谱数据进行分类实验,通过准确度、稳定性及训练时间3个方面分析该算法的性能,并与极限学习机(ELM)、波形叠加极限学习机(SWELM)、反向传播神经网络(BP(2层))、KELM(RBF)和SVM模型作对比,实验结果表明所建立的方法能够有效鉴别柑橘黄龙病。
1 LAR-KELM(RBF)模型
近红外光谱特征波长的数量较多,其中部分波长与预测结果的相关性较低,影响预测结果的准确性。针对该问题,采用LAR算法对特征波长进行筛选,然后采用KELM(RBF)实现柑橘黄龙病的分类。通过引入核函数,避免了ELM因随机赋值对输出结果产生的随机波动,使ELM算法的稳定性和学习能力更强,分类准确度更高[15]。
LAR-KELM(RBF)的训练过程分为LAR特征波长筛选和KELM(RBF)分类鉴别两个阶段。具体过程如下:
(1)第一阶段:LAR特征筛选阶段
最小角回归算法构造了一个一阶惩罚函数,通过惩罚函数可将不相关或者相关性较小的变量系数置为零并删除,从而实现变量的筛选。其线性回归模型表示如下:
(1)
(2)
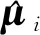
利用公式(1)求解出每个自变量对应的回归系数βj。其中,用0代替回归系数中相关性较低的回归系数,用1代替相关性较高的回归系数。基于求解的回归系数β根据公式(1)实现训练集样品特征变量的筛选:
X′=Xiβ,i=1,2,L,m
(3)
其中,Xi=[xi1,xi2,L,xil],β=[β1,β2,L,βl]T。
(2)第二阶段:KELM分类鉴别阶段
KELM算法主要实现波长筛选后样品的分类鉴别。对于m个训练样本矩阵(xj,pj),j=1,2,L,m,假设隐含层神经元的数目为L,则极限学习机的输出函数f(x)为:
(4)
Wk=[ωk1,ωk2,…,ωkn]T,βk=[βk1,βk2,…,βkm]T
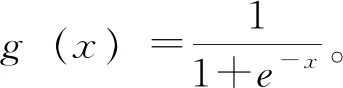
将隐含层的输出矩阵定义为H,期望输出为T,那么该问题最终转换为:
Hβ=T
(5)
其中T=[T1,T2,…,Tn]T,H表示为:
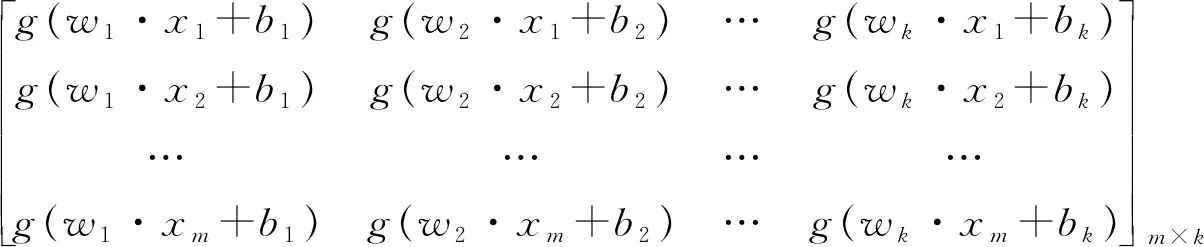
(6)
在式(5)中,β通常取其最小二乘解,计算公式如下:
β=H+T
(7)
其中,H+为隐含层的输出矩阵H的广义逆矩阵。
根据Karush-Kuhn-Tucker(KKT)理论,通过求解对偶优化问题可得ELM为:
(8)
其中,C为正则化参数。
应用Mercer条件定义核矩阵,则:
KELM=HHT
(9)
KELM(k,p)=h(xk)·h(xp)=K(xk)·(xp)
(10)
KELM的输出可以表示为:
(11)
2 实验部分
2.1 样本采集与实验数据
本实验所用材料由广州讯动网络科技有限公司提供的1 245枚柑橘叶片。使用实时荧光定量PCR技术确定柑橘叶片是否染病。按照PCR国家标准[16],循环阈值(Cycle threshold,CT)大于35为健康,小于30为患病,在30~35之间时需要复测来确定是否患病。最终测得患有黄龙病的叶片406片和未患黄龙病的叶片839片。使用傅里叶变换近红外光谱仪采集叶片漫反射光谱,采样间隔为1 nm,测定范围为12 500~4 000 cm-1(780~2 500 nm);每个样本的测量点为直径5 mm的圆形区域,为减小误差,最终选取测量32次的平均值;每条光谱有701个光谱点,光谱波数范围为10 526~6 061 cm-1。
2.2 数据预处理
由于傅里叶变换近红外光谱仪测得的光谱存在噪声和基线漂移,因此有必要通过OPUS软件对光谱进行紧凑预处理,从而得到柑橘叶片的一致性光谱,光谱的波长范围为960~1 650 nm,如图1A所示。
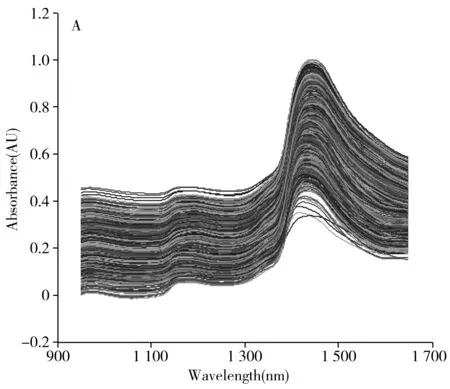
从图1A可以看出,未经预处理的柑橘叶片光谱之间存在严重的信息重叠且相似度较高,此外还包含一些与待测样品性质无关的因素带来的干扰,因此必须对原始光谱进行预处理。本实验首先按列L2范数对光谱数据单位化;然后采用小波变换对光谱数据预处理。预处理后的光谱数据如图1B所示。
2.3 KELM(RBF)隐含层神经元个数确定
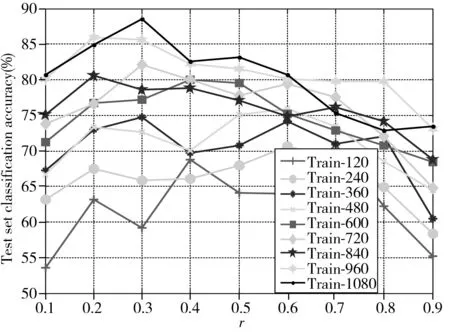
图2 不同隐含层神经元比例下不同训练集 的分类准确度Fig.2 Classification accuracy of different training sets under different hidden layer neuron ratios
合适的隐含层神经元数目对KELM(RBF)算法有至关重要的作用,而隐含层的选择过程会耗费大量时间,因此需要谨慎选取隐含层个数。在KELM(RBF)算法中,将t表示为训练集的数目,r表示比例参数,N为隐含层神经元的个数,那么:
N=t×r
(12)
通过上述采集到的数据,将训练集个数依次递增进行实验,实验结果如图2所示。
从图2可以看出,随着训练集的大小递增,当r在0.2~0.5之间时,分类准确度较高,当r=0.3时,准确度基本达到最高。
2.4 实验环境
本次实验的硬件环境为Inter(R) Core(TM) i7-6700 CPU,采用MATLAB2014a作为编码工具,操作系统版本为Window 10 专业版。LAR-KELM(RBF)鉴别模型中,网络结构设置为:400-t*r-2(t)为训练集样本个数,r为隐含层神经元比例,通过网格寻优获取最优C=1,γ=1,迭代次数设置为1,隐含层节点个数设置为t*0.3。
2.5 对比实验参数设置
对比实验采用的方法有:SVM、BP(2层)、SWELM、ELM、KELM(RBF)模型,其中SVM选取的参数C为1.0,ε为0.3;BP算法采用两层网络结构,具体为701-300-100-2,dropout值为50,学习率均设置为0.05;ELM和SWELM的网络结构均为701-t*0.4-2,dropout值为100,隐含层神经元节点个数均为t*0.3,ELM激活函数采用sigmoid。
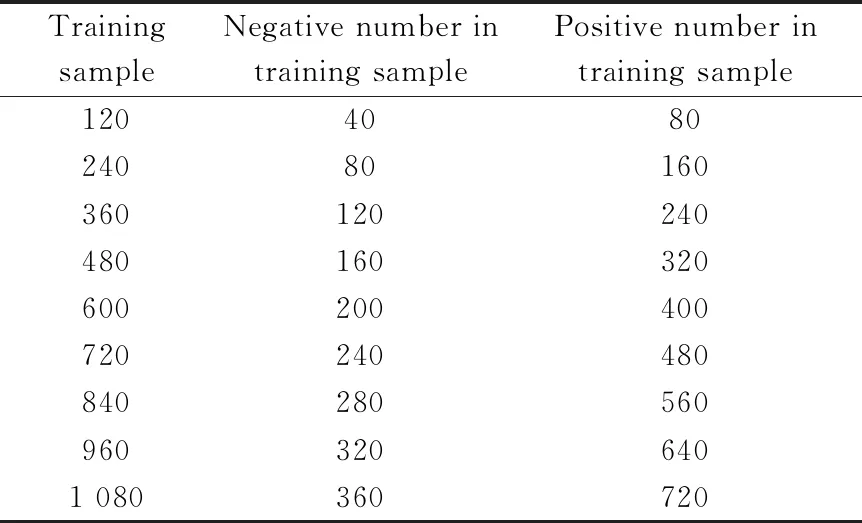
表1 柑橘叶片近红外光谱数据集划分Table 1 Near infrared spectral data sets of citrus leaves
3 结果与讨论
3.1 数据集划分
采用柑橘叶片近红外光谱数据进行相应的分类实验。为了验证不同规模训练集对LAR-KELM(RBF)模型鉴别能力的影响,将训练集依次递增120,如表1所示。
3.2 对比实验
实验采用相同的光谱预处理方法,取10次实验结果的均值评估各个鉴别模型分类准确度、训练时间以及算法稳定性3个方面的性能。
3.2.1 分类准确度分类准确度是LAR-KELM(RBF)模型性能的重要衡量指标,较高的分类准确度说明该模型对柑橘黄龙病的鉴别更为可靠。采用如表1所示不同规模的训练集,以BP(2层)、SVM、SWELM、ELM、KELM(RBF)及其与LAR算法的融合模型进行相应的分类实验,实验结果如表2所示。
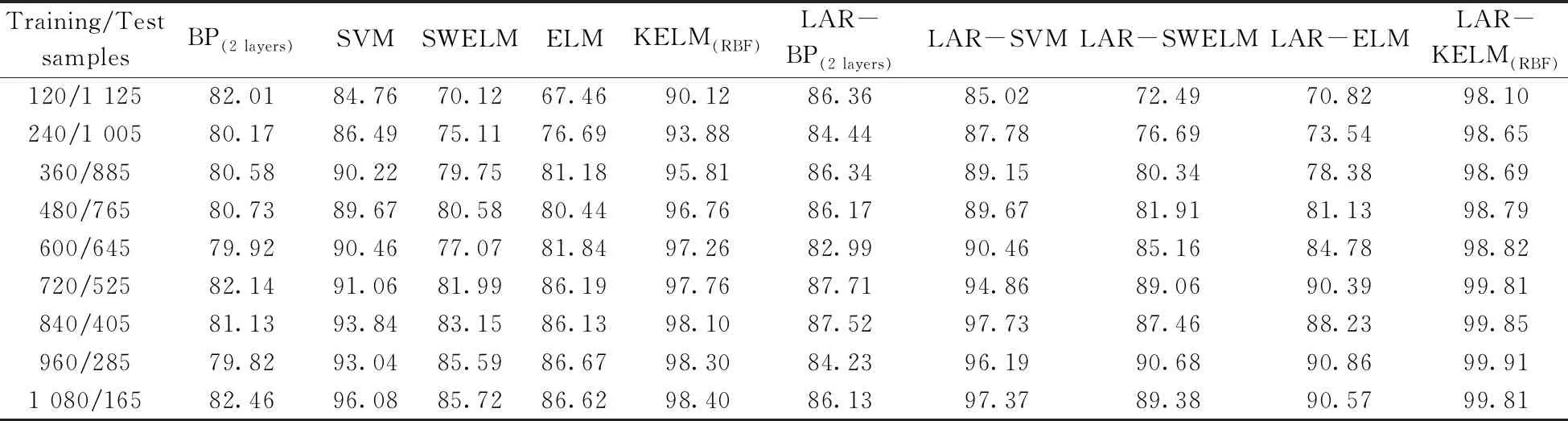
表2 在不同规模样品数据集下不同分类模型的分类准确度Table 2 Classification accuracy of different classification models under different scale sample data sets (%)
从表中可以看出,在不同规模的训练集下,KELM(RBF)均能保持较高的分类准确度,这是因为KELM(RBF)在ELM模型中引入了径向基(RBF)核函数,增强了ELM的非线性建模能力,提高了模型的分类准确度。通过采用LAR特征波长筛选,LAR-KELM(RBF)分类准确度比KELM(RBF)高,且在训练集增加到960时达到99.91%。通过表2可以看出,LAR-BP(2层)、LAR-SVM、LAR-SWELM、LAR-ELM和LAR-KELM(RBF)的分类准确度均得到了一定的提升,这是由于波长选择能够简化模型并剔除不相关的变量,进一步说明变量筛选能够提升近红外光谱鉴别模型的性能。无论数据集规模大小,SWELM和ELM的分类准确度均极为相似,说明激活函数对模型性能影响不大。BP(2层)的效果不太理想,可能是由于其在本实验中提取高维度光谱数据特征方面的能力有限。
3.2.2 训练时间在训练时间方面,BP(2层)、SVM、SWELM、ELM、KELM(RBF)和LAR-KELM(RBF)模型针对表1中不同规模柑橘叶片光谱数据的训练时间如表3所示。
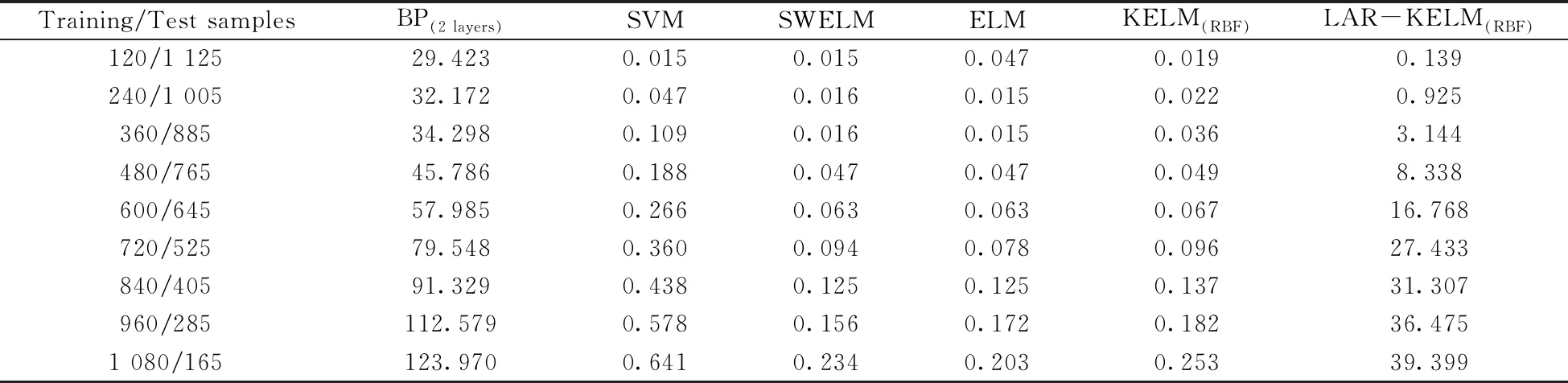
表3 在不同规模样品数据集下不同分类模型的训练时间Table 3 Training time of different classification models under different scale sample data sets
从表中可以看出,SVM、SWELM、ELM和KELM(RBF)在训练时间方面具有明显优势,这是因为这4个模型在预训练阶段不需要进行多次循环迭代和反向微调模型参数。由于模型的预训练阶段需采用LAR算法进行特征波长的筛选,增加了模型的时间消耗,因此LAR-KELM(RBF)的时间消耗较SVM、SWELM、ELM和KELM(RBF)大。相比其它几种模型,BP神经网络的时间消耗较大,这是因为在模型运行过程中需要不断反向微调参数,实现网络的优化。
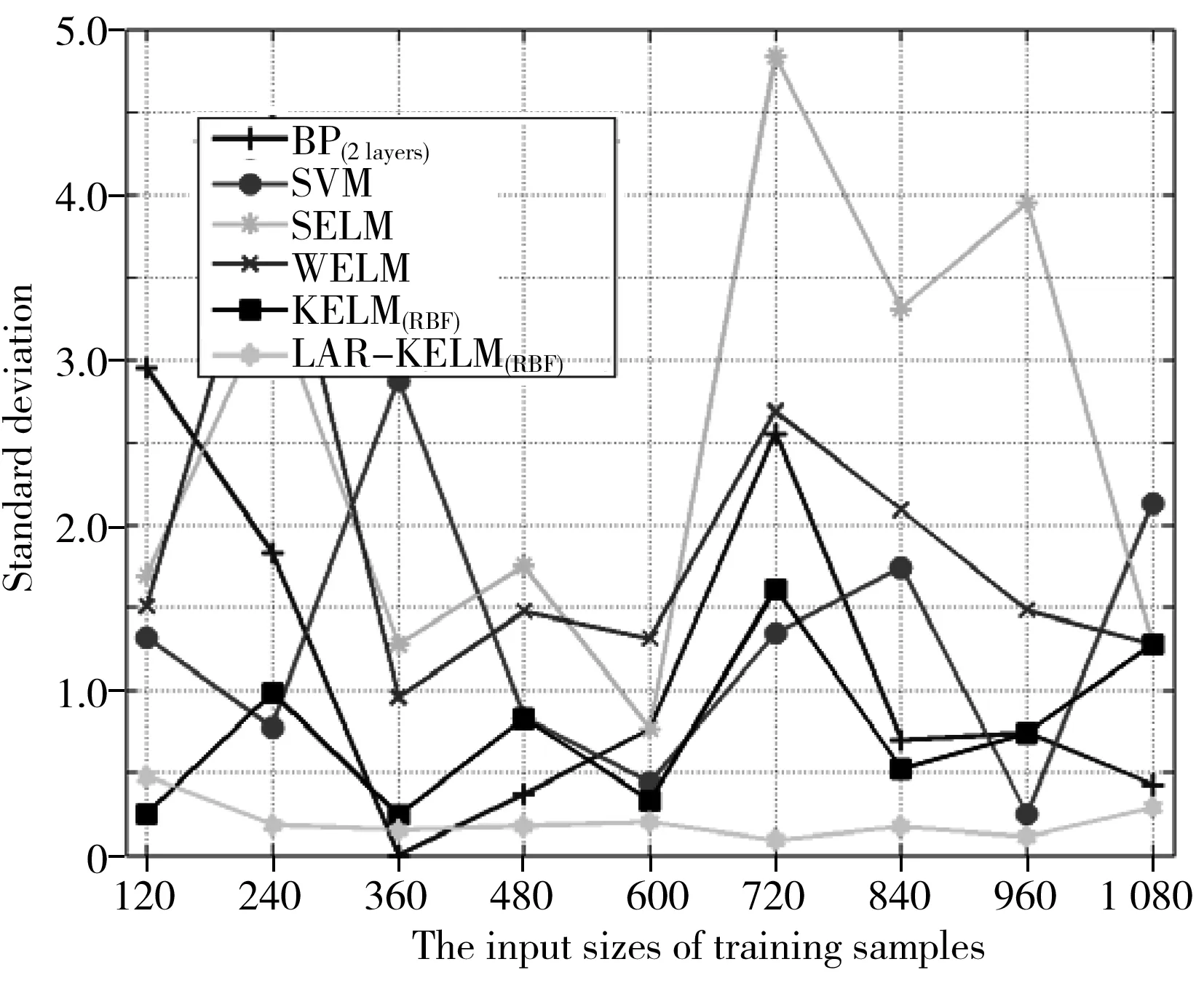
图3 在不同规模样品数据集下不同分类模型 准确度的标准偏差Fig.3 Standard deviation(STD)of accuracy of different classification models under different scale sample data sets
3.2.3 算法稳定性模型的稳定性决定了模型的推广能力和实际的应用能力,本实验以标准偏差为模型稳定性评价指标,各模型在不同规模数据集下的标准偏差结果见图3。
从图3可以看出,相对于其它几种算法,当训练集增加到720后,LAR-KELM(RBF)模型的标准偏差仅为0.091,且一直保持较低值,表现出最优的稳定性,表明LAR-KELM(RBF)模型具有较好的实际应用能力。
4 结 论
近年来近红外光谱分析技术在黄龙病检测行业有着广泛的应用。本文提出的LAR-KELM(RBF)模型实现了柑橘黄龙病的鉴别。利用LAR对柑橘叶片的近红外光谱数据进行特征波长点筛选,使样品的光谱矩阵维度降低,然后采用KELM(RBF)模型进行筛选后光谱数据的分类鉴别。最后,使用傅里叶变换近红外光谱仪测得近红外漫反射光谱数据,并对LAR-KELM(RBF)模型的性能进行评估。实验结果表明LAR-KELM(RBF)模型较其他模型具有分类准确度高、算法稳定性强等优点,能够实现柑橘黄龙病的早期筛查。
