管道环焊缝缺陷智能识别技术探究与实现
2020-11-05周永涛程海龙
费 凡,周永涛,周 顺 ,程海龙
(1.中国石油北京天然气管道有限公司 北京 100101;2.中国石油管道有限责任公司 北京 100000)
0 引 言
X射线检测作为焊缝缺陷的无损检测技术之一,是保证焊接结构件质量的重要手段。人工评定射线胶片存在很大的主观性,易产生较多的误判和漏判[1]。对数字化胶片的实时检测和缺陷自动识别一直是无损检测方向的研究热点,实现方式多为特征工程及传统机器学习[2-3],效率及稳定性仍有不足。近年来,伴随人工智能技术的发展,基于深度学习的图像检测技术趋于成熟,国外已经利用深度学习的方法进行数字化胶片的实时检测和缺陷自动识别[4],证明了技术的可行性。本文将利用基于深度学习的图像识别技术构建管道环焊缝缺陷智能检测分析框架,从焊缝胶片底片数字化开始,经过图像预处理、训练神经网络模型等步骤,最终通过算法智能识别存在缺陷的焊缝胶片并定位标注出疑似缺陷的位置。
1 基于深度学习的管道焊缝缺陷智能检测分析框架
本文基于深度学习构建管道环焊缝缺陷智能检测分析框架,主要包含数字化焊缝胶片、图像预处理、训练智能检测分析模型等步骤。数字化焊缝胶片由专用数字化系统扫描物理胶片获得,用作智能检测分析模型的训练和测试数据。图像预处理通过滤波降噪、图像分割、统一图像灰度、定位焊缝区域等方法,提升图像质量,提取焊缝区域。框架中涉及两个深度学习模型。第一个是利用ResNet网络训练图像分类模型,该算法通过卷积网络对图像进行检索,提取图像特征,实现对特征的有监督的学习,把特征提取和分类器统一在一个模型里,实现识别分类功能[5];第二个是利用Mask RCNN网络训练缺陷标注模型,对存在缺陷的焊缝胶片图像进行定位标注。这两个模型可辅助工作人员快速检出疑似存在缺陷的数字化胶片,并标注疑似缺陷,提升焊缝缺陷筛查效率。管道环焊缝缺陷智能检测分析框架如图1所示。

图1 管道焊缝缺陷智能检测分析框架
2 数字化胶片
数字化图像是管道焊缝缺陷智能检测分析的基础。焊缝射线胶片数字化的方法是:使用专用数字化系统(中晶MII-1000)将物理胶片扫描为16 bit的BMP图像格式文件,扫描时需要根据物理胶片的黑度值调整扫描黑度参数[6]。管道焊缝胶片数字化的效果如图2所示。

图2 数字化后的焊缝胶片
3 滑动窗口处理
卷积网络(CNN)在处理图像时采用滑动窗口机制。焊缝缺陷检测中,整个胶片图像尺寸很大,缺陷特征只是图像的一部分,将胶片图像直接缩小到网络中的尺寸,会导致一定尺度比例的损失,也会使整体的效率降低。滑动的步长不应设置太小,否则会出现较多的无效碎片图像,时间效率和处理性能也会变差,因此采用固定短边,长边固定为690,以步长50的方式进行滑动窗口处理。
4 图像预处理
4.1 降噪处理
物理胶片黑度值过高和过低都会导致数字化胶片中存在大量噪声,容易影响与混淆缺陷特征,需要继续进行降噪处理。降噪处理必须考虑到缺陷特征本身,防止缺陷细节的丢失。滤波器是常用的降噪方法,分为线性滤波器和非线性滤波器。考虑到缺陷细节的重要性与复杂性,选择平滑且细节损失较少的中值滤波器进行5×5的降噪处理,如图3所示。
图3 降噪处理后图像
4.2 提取焊缝区域
提取焊缝区域目的是将图像的焊缝区域和其他元素进行分割。这样可以大幅减少训练量、清除干扰因素,提高识别效果。提取焊缝区域的第一步是用最佳阈值法将灰度图像转为二值化图像,将感兴趣区域与背景分离。最佳阈值的选择,采用大津法(OTSU算法)[7],这是一种使用最大类间方差作为衡量前景和背景标准的方法,计算简单,不受图像亮度和对比度的影响。提取焊缝区域的第二步是根据二值化后的直方图分布确定区域,裁剪出合适的焊缝区域。图4、图5为提取过程示例。

图4 二值化后的图像

图5 焊缝区域图像
4.3 增强处理
经上述图像预处理后,焊缝图像存在对比度低、关键细节特征不明显、灰度值分布集中等问题。这些问题的出现使得缺陷特征视觉效果较差,导致后面模型检测识别产生较大的误差。为此采用曝光融合算法框架[8]对图像的对比度进行增强,图6为增强处理后的图像。
图6 增强处理后的焊缝区域图像
5 深度学习模型
5.1 数据收集
实验中原始射线胶片数据来源于陕京三线,经过扫描数字化处理、整理和挑选,总共含有1 000张正常的胶片图像和300张存在缺陷的胶片图像(主要以气孔、烧穿、条渣与未熔合4类缺陷为主),作为后期实验的训练集与测试集。收集的数据中缺陷类型具体分布见表1。
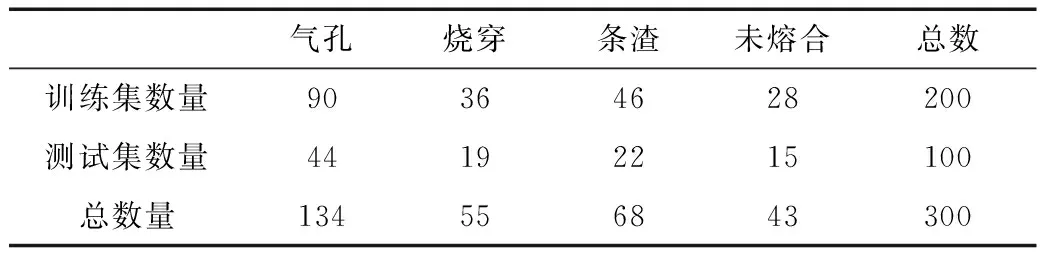
表1 数据分布 个
基于深度学习图像特征分类方法选择合适的数据用于模型训练。需要筛选特征突出、没有其他干扰信息的数据,降低可能出现过拟合问题的概率。焊缝缺陷识别不同于一般的图像分类任务,缺陷特征的复杂多样性是难点。比如说,同一种缺陷可能存在着多个不同的特征,同一个缺陷可能被不同的评片人员分到不同的类别中,有些缺陷特征存在但细节不清晰等等。实验通过人工筛选出有效、高质量的图像。
实验注重胶片图像的质量和缺陷的细节特征。对于数据集里的所有胶片图像,进行降噪、焊缝区域提取以及图像增强等预处理工作,提升图像本身的质量,使缺陷细节可以更加突出,为模型的高准确率提供保障。存在缺陷的焊缝图像部分样例如图7所示。

图7 存在缺陷的焊缝图像
5.2 基于深度残差网络(ResNet)的图像分类模型
在图像分类任务上有许多卷积网络已被证明可以获得很好的结果,比如AlexNet[9]、VGGNet[10]等。实验采用较新也较稳定的深度残差网络。深度残差网络由微软研究院的Kaiming He等4名华人提出。通过使用ResNet Unit成功训练出了152层的神经网络,这一结果赢得了SVRC2015分类任务第一名,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。深度残差网络结构可以加速神经网络的训练,模型的准确率有比较大的提升。同时网络的推广性非常好,甚至可以直接用到谷歌的深度学习网络中[11]。
深度残差网络中增加了直连通道,解决因为网络层数过深而导致误差增大的问题,即Highway Network的思想,并允许原始输入信息直接传到后面的层中。
采用构建50层ResNet50网络结构模型,将每一层的参数减半,减少训练时间,并在分类准确性和时间效率上做到相对折中。利用深度学习框架PyTorch构建网络模型,构建的模型共有约450万个参数,网络中的神经元连接总数近10亿个。对比AlexNet的约6 000万个参数,该模型在网络层数、训练参数上都有着很大的优势[12]。由于我们的框架输出分类为2类,所以将网络最后的全连接层的神经元个数设置为2个,优化算法使用Adam,考虑到模型的层数,学习率设置为0.01。模型的输入为224×224大小的两通道图像,第一个卷积层conv1的参数是64个7×7的卷积核,卷积核的步长为2,每一次卷积过后都会接一个批量标准化层,使得模型的容纳能力增加。激活函数使用的是线性整流函数算法,并且通过最大池化层进行下采样。网络的最后一层是归一化指数函数(softmax)回归层,用于输出图像分到哪一类别的概率[12]。回归表现形式为:它将多个神经元的输入映射到(0,1)区间内,形成一个概率的概念,从而进行分类任务。
5.2.1 模型训练
实验的环境,使用一块10 GB显存的GTX1080TI显卡,centos 7操作系统,网络模型基于深度学习框架PyTorch搭建,编程语言使用的是Python3.6。从收集到的数据中随机挑选图像分别作为训练集和测试集,分布数量见表2。
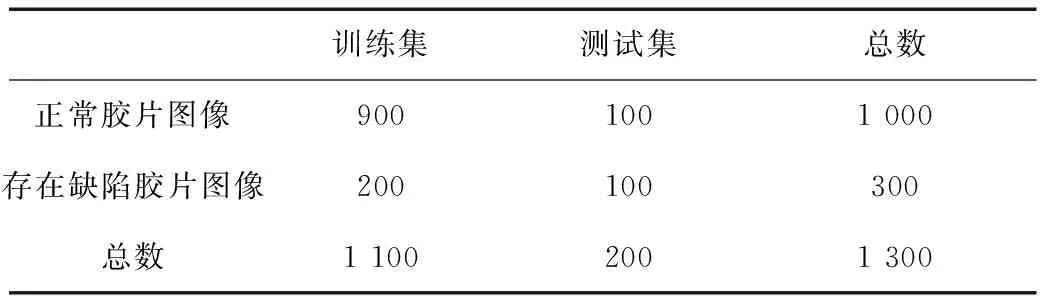
表2 构建的数据集 个
实验过程中使用了数据增广技术,增大数据集的容量。没有采用常用的随机裁切的方法,因为随机裁切产生的图像碎片,可能已经改变其属性特征,产生错误的数据分类。而是采用了旋转和翻转的方式进行图像增广,并对图像进行归一化处理。
实验基于ImageNet1000数据集的预训练模型进行迁移训练。权值的基础学习率设置为0.01,动量为0.9,权值衰减为0.000 5,保留每一次epochs产生的权重,并对验证集实时验证,直至网络收敛[12]。最终模型大小约为97 MB。
为了比较ResNet50与VGG16、AlexNet等网络的效果,我们使用相同的数据集,在没有任何调整的VGG16与AlexNet上也进行了训练。这3个网络在模型大小、检测时间和数据召回率等方面的比较见表3。ResNet50网络参数比其他网络都小了很多,训练用时也低很多,检测时间和召回率都更加优越。

表3 模型性能比较
5.2.2 模型评估
在深度学习图像分类领域,针对一个模型最终好坏的评估标准有很多,例如精确率(precision)、召回率(recall)、准确率(accuracy)等性能度量概念。
模型经过对测试集的检测识别,根据分类时预测与实际的情况,作出混淆矩阵,见表4、表5, P代表预测数,A代表实际。

表4 不含数据增广算法模型的混淆矩阵

表5 含数据增广算法模型的混淆矩阵
根据所得到的混淆矩阵,实验对焊缝缺陷识别的分类结果采用准确率和召回率进行评估。准确率=正确预测的正反例数/总数,召回率=正确预测到的正例数/实际正例总数。经过数据增广后模型在各项性能度量都有显著提升,根据公式可以得出,分类准确率为72.5%,对存在缺陷的胶片图像的召回率为90%。
由于焊缝特征多样性、缺陷样本数量过少、整体的数据量不足,得到的准确率波动幅度比较大,对于存在缺陷的胶片图像的召回率表现不错,数据量的增大可带来更好的效果。
5.2.3 模型时效分析
在对焊缝缺陷的检测识别过程中,算法的时效性也是一项关键的性能。本文方法对单张测试图像的处理时间小于2 ms,由于网络模型参数较少、模型小、加载快,对比其他方法在时效性上有着很大的提升,时效性对比如表3所示。基于深度学习方法的算法,通过GPU加速可以提升时效性。另外硬件性能的提升和模型网络的优化,可以获得更高的时间效率。
5.3 基于Mask R-CNN的缺陷标注模型
Mask R-CNN[13]是Kaiming He基于以往的faster rcnn架构提出的新的卷积网络,一举完成了对象实例分割。该方法有效地通过增加不同的分支,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务,灵活而强大。Mask R-CNN中最重要的亮点在于ROIAlign。在之前的算法中存在着特征图与原始图像不对准(mis-alignment)的问题,影响着检测精度。而Mask R-CNN提出了RoIAlign的方法来取代ROI池化,RoIAlign可以保留大致的空间位置,其抽象架构如图8所示[13]。

图8 Mask R-CNN抽象框架图
5.3.1 模型训练
本实验是利用Mask R-CNN网络中语义分割功能对存在缺陷的胶片图像进行缺陷的定位标注。实验使用一块10 GB显存的GTX1080TI显卡,centos 7操作系统,网络模型基于深度学习框架PyTorch搭建,编程语言使用的是Python3.6。
模型训练需要对已有数据集进行标注处理,生成标注图像文件和标注位置信息文件,整理成Mask R-CNN需要的COCO数据集样式。焊缝缺陷标注图像样例如图9所示。

图9 焊缝缺陷标注图像
数据整理完成后,针对已有数据对网络结构与训练参数进行调整:1)冻结网络其他功能模块,如分类、检测,只保留分割模块的训练;2)修改预训练模型参数,冻结最后输出层参数;3)修改学习率、训练步长、训练批次等参数;4)保留每一次epochs产生的权重,并对验证集实时验证,直至网络收敛。
5.3.2 实现效果
经过训练获得的语义分割模型,对测试图片进行测试,可以完成缺陷特征的定位标注,如图10所示。目前模型训练数据集中圆形缺陷数据比例大,可以很好地实现对圆形缺陷的标注。
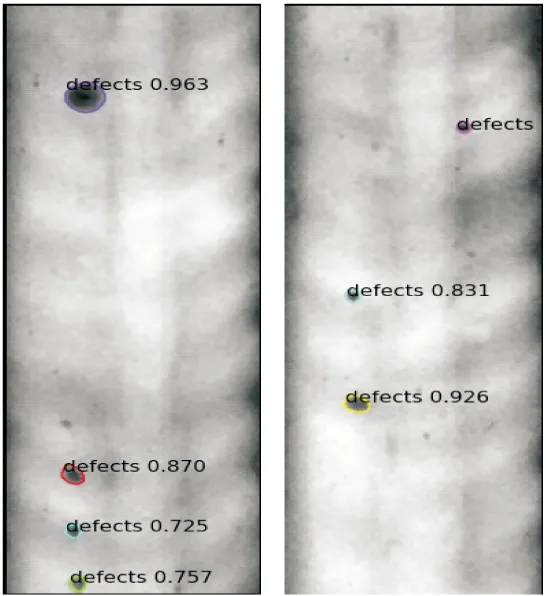
图10 焊缝缺陷标注
6 结 论
本文在人工智能技术高速发展的背景下,提出了基于深度学习的管道焊缝缺陷检测识别框架,阐述了各步骤的具体算法和模型训练方法,通过实验证明了框架的可行性。利用深度学习模型和各种图像处理算法可以完成缺陷智能检测分析工作。实验结果表明,该方法以较短的训练时间可获得较高的焊缝缺陷识别准确率,并能实现圆形缺陷的定位标注。现有焊缝缺陷(尤其横向裂纹、咬边、条渣等缺陷)样本数据量较少,当前模型对横向裂纹等条块型缺陷的适用性较差。接下来将收集更多缺陷样本数据,完善训练和测试数据集,进一步优化深度学习模型算法,提高模型各项指标和适用性。
