语义分割图像自适应编码方法
2020-11-05陈鸿翔梁晨光宫久路
陈鸿翔,梁晨光,李 蒙,宫久路
(1.北京理工大学机电学院,北京 100081;2.北京宇航系统工程研究所,北京 100076;3.北京航天控制仪器研究所,北京 100039)
0 引言
语义分割是对图像中的每个像素都标注出其所属类别,实现图像在像素级别上的分类[1]。语义分割是探测与识别的基础性技术,主要用于红外探测、雷达探测、目标识别与分类等任务,在无人系统、国防军事等领域具有广泛的应用[2-5]。语义分割图像的存储和传输都占用了较多资源,因此,需要对语义分割图像进行高效无损压缩。
图像的语义分割结果一般表示为按类别划分的多幅图像,每幅语义分割图像只包含其对应类别的像素,是一种二值图像。常用的二值图像无损压缩方法主要为边界编码、混合编码等,不同类型的二值图像通常需要不同方法才能达到最好的压缩效果。文献[6]针对边缘图像利用Logistic回归建立分类器对其进行自适应编码,与边缘打包法相比提高了压缩比5%左右。文献[7]针对图形图表类型的二值图像提出了一种基于分割的编码方法,将图像的黑色区域分割为矩形,对每个矩形的顶点坐标进行编码,该算法相比于其他分割方法平均效率提高了32%左右。不同于上述二值图像,语义分割图像中的目标像素均为同一种类别,多为连续分布,相邻像素间具有很强的相关性,适于采用基于上下文的编码方法。文献[8]针对黑白散斑图像设计了一种基于上下文的无失真编码器,与JBIG相比,该编码器的压缩性能提高了58%左右。
本文针对语义分割图像压缩性能不足、占用资源较多的问题,提出了基于上下文与二进制算术编码的自适应编码方法。
1 二进制算术编码与上下文模型
二进制算术编码是一种熵编码方法,其基本原理是根据符号出现概率将输入序列转化为[0,1)之间的一个区间[C,C+A),并将该区间中的一个值作为最终的编码输出。
二进制算术编码输入序列中的符号分为大概率符号(more probable symbol,MPS)和小概率符号(less probable symbol,LPS),并根据实际情况进行调整。如果当前输入的二进制序列中的0较多,1较少,那么MPS为0,LPS为1;否则MPS为1,LPS为0。若当前编码符号为MPS,则二进制算术编码迭代公式为:
(1)
若当前编码符号为LPS,则二进制算术编码迭代公式为:
(2)
式(1)和式(2)中:C表示区间索引,初始化为0;A表示区间间隔,初始化为1;P表示LPS在当前已输入序列中出现的概率;MPS,LPS和P根据统计进行更新。
上下文模型是一种概率模型,定义了上下文选取方法,存储了特定上下文中“0”或“1”的概率,根据选取的上下文位数,可分为0、1、2或n阶。0阶上下文模型表示统计的符号概率是符号在已输入序列中出现的概率,不考虑上下文信息;多阶上下文模型统计的符号概率为该符号在特定上下文后出现的条件概率。根据Shannon信息论[9],若某一符号出现的概率为P,则编码该符号的最佳比特位数为-lbP。例如已经编码了100位二进制符号,其中0和1各出现了50次,使用0阶上下文模型时,编码下一位符号所需的最佳比特位数为-lb(50/100)=1;使用1阶上下文模型时,若刚编码的符号为0,下一位要编码的符号为0,在前面的编码过程中已经统计出符号0后面依然为符号0的情况有40次,则编码下一位符号0所需的最佳比特位数为-lb(40/50)≈0.322。采用多阶上下文模型,使用条件概率对符号进行编码并进行上下文模型的概率更新,一般具有更高的压缩比;然而上下文模型采用的上下文位数越多,上下文种类也越复杂,编码时上下文模型查找和概率更新过程也需要消耗更多时间。
2 自适应编码方法
对语义分割图像进行二进制算术编码时,编码时间和图像压缩比与上下文模型和图像结构有关。为了进一步提高压缩性能,本文通过分析语义分割图像特征与上下文模型的关系,提出了最佳上下文模型的概念和自适应选择方法,根据图像复杂度特征,预测其最佳上下文模型用于二进制算术编码,以实现语义分割图像的自适应编码。
2.1 图像特征与上下文模型
图像经过语义分割后,根据分割类别将得到多幅语义分割图像,每幅语义分割图像只含有两种像素值,如图1所示,遥感图像经过语义分割得到“建筑”、“道路”、“植被”和“水域”四种类别的语义分割图像。

图1 图像语义分割Fig.1 Image semantic segmentation
语义分割图像中的像素分为两类,分别为表示其所属类别的像素(目标像素)和其他像素(背景像素),因此像素多为连续分布、划分明显,相邻像素间具有很强的相关性。利用语义分割图像相邻像素间的相关性,选择合适的邻近像素,定义上下文模型用于二进制算术编码,以取得更好的压缩效果。
对语义分割图像进行二进制算术编码时,常采用逐行扫描法对像素点进行遍历。采用逐行扫描法遍历图像,编码某一像素值时,其上方和左侧的像素值已经输出,可以将这些像素值作为上下文信息来设计上下文模型。
像素间的相关性与其间隔距离负相关,因此,在定义上下文模型时,优先选取相邻像素作为上下文。如图2所示,对于某一像素点X,以其周围的像素L,T,TL,TR,LL和TT作为上下文信息[10-11],选择四种不同阶数的上下文模型:
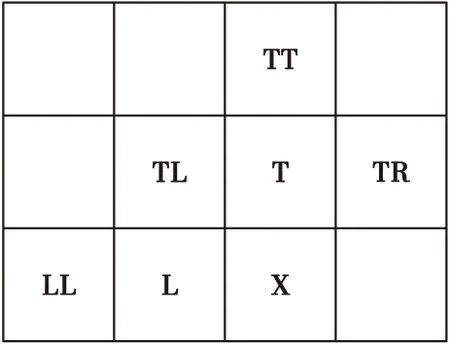
图2 相邻像素示意图Fig.2 Schematic diagram of adjacent pixels
1) 1阶上下文模型:以L或T为上下文(文中实验以L为上下文);
2) 2阶上下文模型:以L和T为上下文;
3) 4阶上下文模型:以L,T,TL和TR为上下文;
4) 6阶上下文模型:以L,T,TL,TR,LL和TT为上下文。
图像编码所需的时间随上下文模型阶数增加而增加。而图像压缩比不仅与上下文模型阶数有关,也与图像结构有关。图3为遥感影像的语义分割结果,分别采用1、2、4和6阶上下文模型对这两幅图像进行二进制算术编码得到压缩比的对比,如表1所示。
从表1可以看出,图像压缩比与模型阶数和图像结构有关。对于结构比较复杂的图像,如图3(a)所示,图像压缩比随着模型阶数增加而增加;对于两种像素数量差距较大且结构比较简单的图像,如图3(b)所示。由于二进制算术编码的输出是由编码过程中使用到的各个上下文模型及其编码结果组成,当图像目标像素较少、图像结构简单,且采用高阶上下文模型时,大量上下文结构在编码时出现频率很低,存储这些上下文模型和编码结果需要更多的空间,上下文模型达到一定的阶数后图像压缩比不会进一步提高,反而会出现下降。因此,根据语义分割图像复杂度,选择正确的上下文模型,是实现高效压缩的关键。

图3 语义分割图像对比Fig.3 Semantic segmentation image comparison
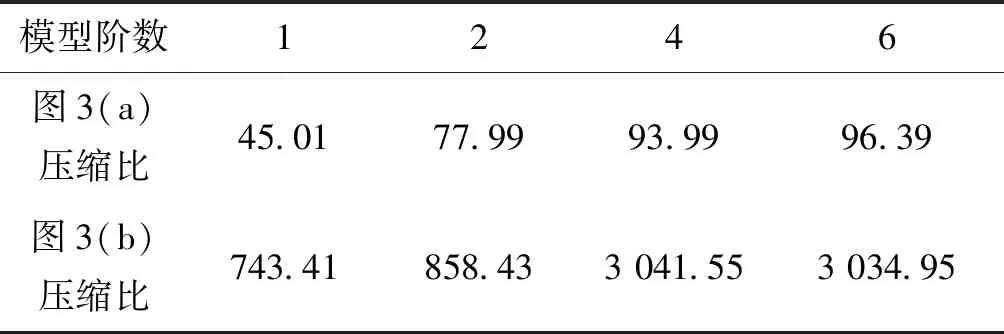
表1 不同上下文模型测试结果对比Tab.1 Thecompression results of different context models
2.2 上下文模型选择
上下文模型的选择与语义分割图像复杂度有关,为了快速自适应地选择最优的上下文模型,本文提出了最佳上下文模型阶数的概念和计算方法,通过SVM[12]方法建立上下文模型分类器,揭示了最佳上下文模型阶数与图像复杂度特征的关系,根据上下文模型分类器选择上下文模型,实现语义分割图像的自适应编码。
2.2.1最佳上下文模型阶数
对语义分割图像进行二进制算术编码,达到最大压缩比时采用的上下文模型阶数,即为最佳上下文模型阶数。然而随着上下文模型阶数的增加,编码时间会显著增长,因此当图像压缩比提升有限时,通常需要考虑图像压缩比与压缩时间的平衡性。定义目标函数如下式:
(3)
(4)
式(3)、式(4)中:i为上下文模型阶数;Si为采用i阶上下文模型进行编码后的编码文件大小;θ为自适应选择阈值,θ≥0;K为最佳上下文模型阶数。
在实际应用中,采用以下步骤计算最佳上下文模型阶数:
1) 对语义分割图像分别采用2.1节中的1、2、4和6阶上下文模型进行二进制算术编码,统计对应的编码文件大小S1,S2,S4,S6;
2) 设置阈值θ(θ≥0);
3) 当θ=0时,表示仅考虑图像压缩比。选择min{S1,S2,S4,S6}对应的上下文模型阶数为最佳模型阶数;若有多个对应的模型阶数,则选取最小的阶数为最佳模型阶数;
4) 当θ>0时,表示综合考虑图像压缩比与压缩时间。选择{S1,S2,S4,S6}中的最小值Si,分别计算Si-Sj;当Si-Sj<θ时,Si对应的上下文模型阶数为最佳模型阶数。
2.2.2图像复杂度特征
如前文所述,根据语义分割图像复杂度,选择正确的上下文模型,是实现高效压缩的关键。常见的图像复杂度主要包括颜色复杂度、形状复杂度和纹理复杂度,但图像复杂度并没有统一的定义和计算方法[13]。二值图像特征主要有图像密度、欧拉数、连通域个数和图像的边界长度。图像密度是指二值图像中目标像素个数与总像素数的比值,算术编码中两个基本的要素为信源符号出现的频率和编码区间,它们决定了编码最终的输出数据。对语义分割图像进行算术编码时,图像密度可以反映两种像素出现的频率,连通域个数和边界长度可以反映上下文模型以及其区间的变换次数,因此本文使用图像密度、连通域个数和边界长度来描述图像复杂度。
2.2.3上下文模型分类器
SVM是基于样本点最大间隔的一种分类模型,通过学习已知数据来总结数据之间的规律,泛化错误率低。SVM适用于解决小样本情况下的分类、回归问题[14]。
以图像密度、连通域个数和边界长度作为输入特征,最佳上下文模型阶数作为分类目标,建立SVM分类模型。引入核函数将输入空间样本映射到高维空间实现非线性分类,使用核函数K(xi,xj)和参数C,求解最优化问题。优化目标函数如下式:
(5)
分类决策函数如下式:
(6)
式(5)、式(6)中:α为拉格朗日系数,n为样本数量,x为n×3维的输入特征向量,y为输出。
常用的SVM核函数包括线性核函数、高斯径向基核函数(radial basis function,RBF)、多项式核函数以及Sigmoid核函数。RBF核函数可以将数据从低维空间映射到高维空间,且RBF函数中只有一个变量,SVM训练参数相对较少。因此,本文采用RBF核函数,其表达式为:
(7)
式(7)中:σ表示RBF核函数参数。
SVM分类模型的分类精度与惩罚参数C和核函数参数gamma有关。利用数据集对SVM分类模型进行训练,使用交叉验证寻优方法(cross validation,CV),获取惩罚参数C和核函数参数gamma的最优参数,建立分类器,实现最佳上下文模型阶数的准确预测。
2.3 自适应编码流程
语义分割图像自适应编码流程如图4所示,具体流程如下:
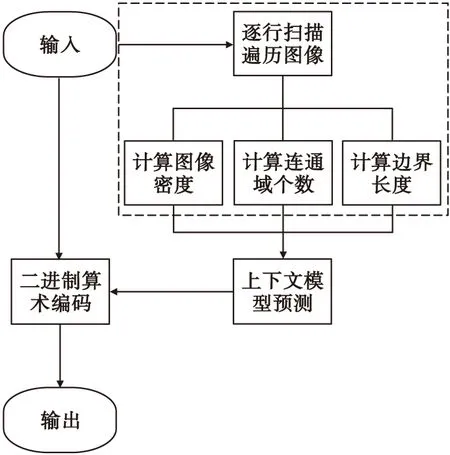
图4 语义分割图像自适应编码流程框图Fig.4 Flow chart of adaptive image compression for semantic segmentation
1) 像素遍历:对输入的语义分割图像按逐行扫描法进行像素遍历,同时完成以下步骤的计算;
2) 图像密度计算:统计输入图像的目标像素数和像素总数,计算图像密度;
3) 连通域个数计算:通过广度优先搜索算法计算输入图像的连通域个数;
4) 边界长度计算:统计输入图像的边界像素总数;
5) 上下文模型预测:将图像密度、连通域个数和边界长度输入训练好的分类器,输出预测结果,即最佳上下文模型阶数;
6) 二进制算术编码:根据步骤5)得到的上下文模型阶数选择2.1节中对应的上下文模型,进行二进制算数编码,输出编码结果。
3 实验与分析
为了测试语义分割图像自适应编码性能,实验分为上下文模型分类器训练及测试和自适应编码算法测试两部分。本文实验均在Ubuntu18.04 LTS的64位操作系统下进行,CPU为Intel(R) Core(TM) i5-8300H @ 2.30 GHz,内存为16.0 GB。
3.1 分类器训练和测试
3.1.1数据集构建
上下文模型分类器的训练和测试样本为自建语义分割图像数据集。数据集为基于NVIDIA Jetson AGX Xavier平台使用U-Net网络对遥感影像进行语义分割的结果图像,共计360幅语义分割图像,分割类别包括房屋建筑、其他建筑、道路、行人道、植被、树木、农作物、河流、积水区、大型车辆和小型车辆,图像大小为2 048像素×2 048像素。数据集部分图像如图5所示。

图5 数据集部分图像Fig.5 Images of the training set
数据集中的图像大小为2 048像素×2 048像素,像素总数为4 194 304。对每幅图像按逐行扫描法进行像素遍历,统计目标像素总数、边界像素总数和连通域个数,以图像密度、连通域个数和边界长度为输入特征;对每幅图像分别以0、512、1 024和2 048 B为最佳上下文模型阶数选择阈值θ,利用2.2.1节中阐述的方法计算最佳上下文模型阶数为类别标签,构建数据集。以图5中的12幅图像为例,每幅图像的特征计算结果、不同阶数上下文模型的二进制算术编码对应的编码文件大小以及采用不同阈值θ的最佳上下文模型阶数如表2所示。
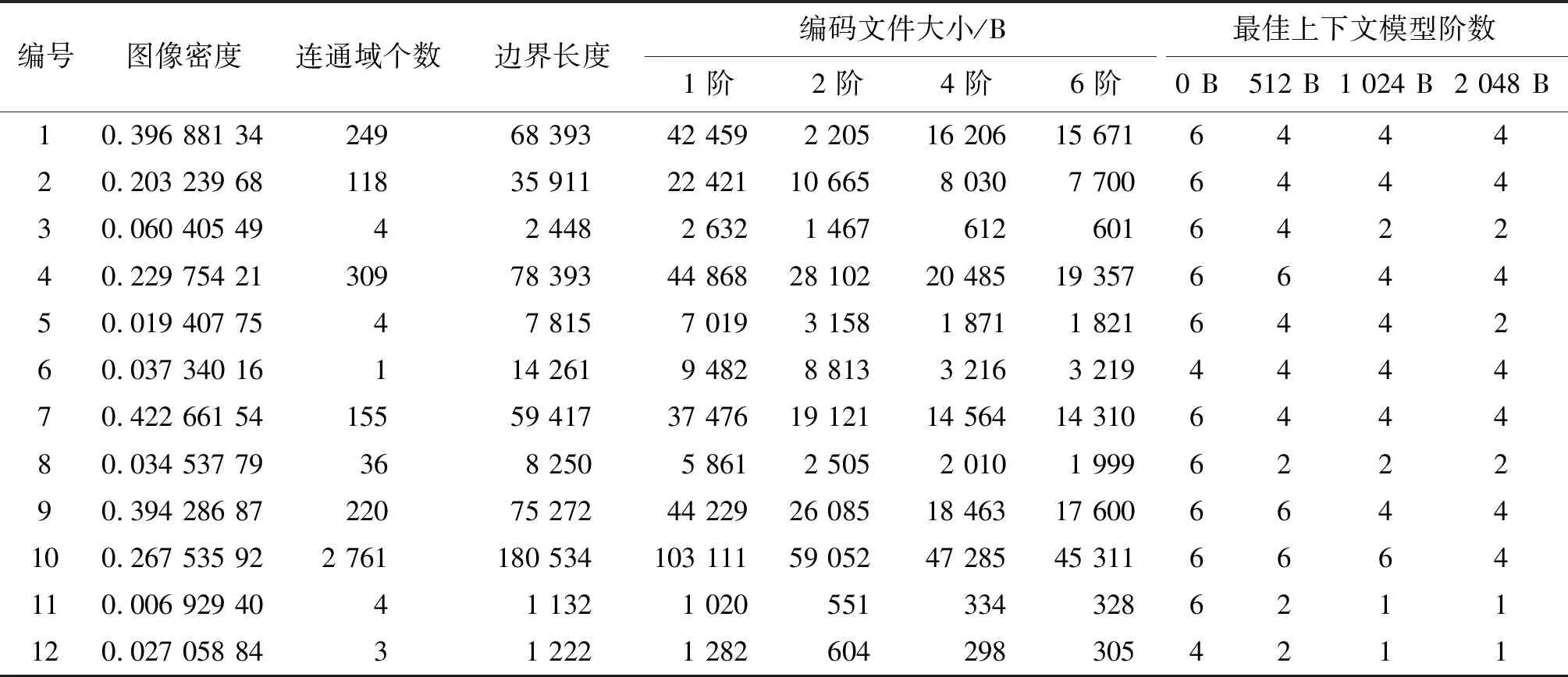
表2 图例数据统计结果Tab.2 Legend data statistics results
3.1.2SVM分类模型训练
利用基于Python语言的scikit-learn机器学习开发包进行SVM模型训练和参数调试。分别以0、512、1 024和2 048 B为选择阈值θ得到的最佳上下文模型阶数为类别标签,采用以下步骤,进行4种上下文模型分类器的训练和测试:
1) 使用3.1.1节中的数据集,以图像密度、连通域个数和边界长度为输入特征,最佳上下文模型阶数为类别标签,构建输入样本,并按7∶3分为训练样本和测试样本。
2) 将训练样本作为输入,建立SVM模型训练分类器。使用交叉验证寻优方法,获取使SVM模型预测准确度最高的惩罚参数C和核函数参数gamma。本文使用网格搜索的方式,对可能的参数组合(C,gamma)进行遍历,通过交叉验证得到预测准确度最高的参数组合(C,gamma),参数搜索列表如下:
C:[1,2,4,6,8,10,12,14,16,18,20],
gamma:[1×10-12,1×10-10,…,1×10-4,1×10-3]。
3) 训练完成后将测试样本输入分类器,对比分类器预测的样本类别标签与实际类别标签,计算分类器准确率。
4种SVM分类模型参数训练过程如图6所示,图中Accuracy表示模型准确度。SVM模型最优参数及实验结果如表3所示。
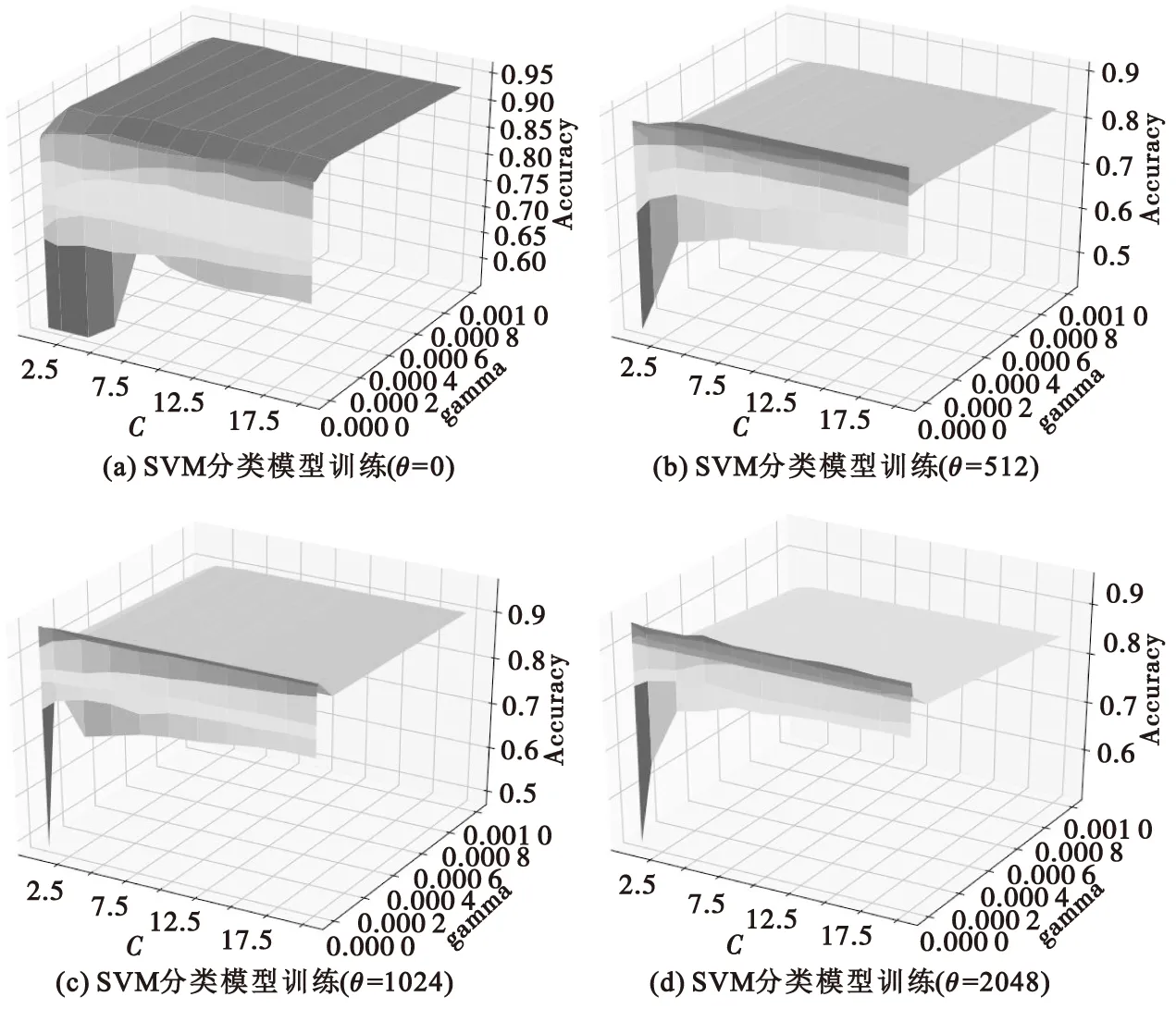
图6 SVM分类模型训练过程Fig.6 SVM classification model training process
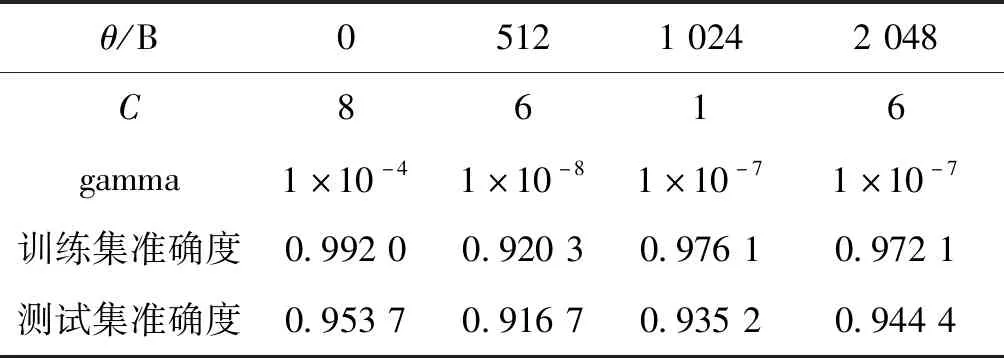
表3 SVM分类模型参数与测试结果Tab.3 SVM classification model parameters and test results
从图6可以看出,SVM分类模型准确度与参数组合(C,gamma)取值有关。从表3可以看出,使用SVM方法进行上下文模型分类器训练,分类器平均预测准确率为93.75%,预测准确度较高,可用于语义分割图像自适应编码时的上下文模型阶数预测。
3.2 自适应编码算法测试
测试采用Kaggle dstl satellite imagery feature detection比赛用数据集,该数据集由英国国防科学技术实验室(DSTL)提供,数据集包含25幅1 m×1 m的高分辨率遥感图像以及每幅遥感图像10种类别的语义分割图像。语义分割类别包括房屋建筑、其他建筑、道路、行人道、树木、农作物、河流、积水区、大型车辆和小型车辆。图像大小为2 048像素×2 048像素。样本图像及其类别标签如图7所示,类别标签示意图为该样本图像10种语义分割图像的合成图像。
测试数据集由上述数据集的遥感影像语义分割图像组成,共计250幅语义分割图像。分别采用JPEG2000,固定阶数上下文模型的二进制算术编码方法和本文提出的自适应编码方法对测试数据集进行压缩,其中自适应编码方法分别采用以0、512、1 024和2 048 B为最佳上下文模型阶数选择阈值θ,使用前文描述的方法训练得到的上下文模型分类器,对测试图像进行压缩。
以图8所示的语义分割图像为例,首先采用逐行扫描法对像素点进行遍历,像素点遍历结果示意如图9所示。

图8 语义分割图像Fig.8 Semantic segmentation image
图9 像素点遍历结果示意图Fig.9 Illustration of pixel traversal results
遍历过程中对目标像素数、像素总数、连通域个数和边界像素数进行统计,计算得到图像密度、连通域个数和边界长度,如表4所示。

表4 图例特征计算结果Tab.4 Legend feature calculation results
将图像密度、连通域个数和边界长度分别输入训练好的4种分类器,输出预测结果,即最佳上下文模型阶数。根据得到的上下文模型阶数选择2.1节中对应的上下文模型,对语义分割图像进行二进制算数编码。同时对图例分别采用1、2、4和6阶数上下文模型进行二进制算术编码以及JPEG2000编码,统计对应的编码文件大小,如表5所示。

表5 图例测试结果对比Tab.5 The test results of legend are compared
按上述过程对数据集进行测试,计算不同方法的压缩比,并统计每种方法的处理时间,处理时间为每种方法对整个数据集进行处理对应的程序运行时间,其中自适应编码方法的处理时间包括像素遍历、特征计算、上下文模型预测和二进制算术编码完整过程。测试结果如表6所示。

表6 不同算法测试结果对比Tab.6 The test results of different algorithms are compared
从表6可以看出:自适应编码算法和基于上下文的二进制算术编码压缩比是JPEG2000的10~24倍;为达到最大压缩比,即自适应编码阈值θ=0 B时,自适应编码法比二进制算术编码法处理时间减少了约44%;考虑压缩比与处理时间的平衡性,不要求达到最大压缩比,即自适应编码阈值θ=512 B时,在同样压缩比下,自适应编码法比采用4阶上下文模型的二进制算术编码法处理时间减少了约31%。自适应编码算法可以有效提高语义分割图像压缩比并减少处理时间。
4 结论
本文提出了语义分割图像自适应编码方法。该方法在二进制算术编码的基础上,提出了最佳上下模型阶数的概念和计算方法,并设计了最佳上下文模型选择算法,利用SVM建立分类器,根据语义分割图像复杂度特征,自适应地选择最佳上下文模型对图像进行二进制算术编码。实验结果显示,与JPEG2000无损压缩方法相比,自适应编码算法具有较高的压缩比,与一般的二进制算术编码相比,自适应编码算法能在压缩比不变的情况下减少处理时间38%左右,压缩性能具有显著提高。
