基于神经网络的多注意属性情感分析
2020-11-03陈闰雪
陈闰雪,彭 龑,徐 莲
(四川轻化工大学 计算机学院,四川 自贡 643000)
0 引 言
情感分析又称意见挖掘,是对文本进行处理、分析、抽取来挖掘文本的情感倾向。属性情感分析属于细粒度的情感分类任务,主要目的是识别上下文中某个属性的情感极性,如积极、消极的情感。句子“the food is usually good but it certainly isn’t a relaxing place to go”中“food”属性是积极的情感,而对于“place”是消极的情感,通过提取用户对特定方面的反馈,反馈的信息有助于企业发现产品的具体缺陷,促使企业对产品的改进。传统的情感分类算法难以从同一文本中不同方面提取不同的特征。由示例句子可知,距离目标近的词对目标的影响较大,与目标相关联的意见表达以块的结构形式出现。当句子中包含多个目标时,准确的建模和提取这类结构信息是非常关键的。
1 相关工作
属性情感分类[1]需要同时考虑句子的上下文和目标属性的信息。传统的机器学习方法是将情感分析作为一个文本分类任务,设计有效的特征提取方法训练分类。Manek等[2]提出基于基尼系数的支持向量机特征选择的情感分析方法,到达较好的效果。Vo等[3]设计具体的情感词嵌入和情感词汇来提取特征,最后进行预测分析。这些方法依赖特征工程的有效性,易达到性能的瓶颈。
近几年,基于神经网络的方法可直接将原始特征编码为连续和低维向量,而不需要复杂的特征工程。Tang等[4]提出TD-LSTM模型,采用LSTM对方面的左上下文和右上下文进行建模,最后将左右的输出拼接起来作为最后的预测输出。该方法没有考虑目标实体的属性,当句子中存在多个目标实体时,难以对其进行精确的分类。
Chen等[5]加入注意力机制来加强各目标属性对分类的影响,关于注意力机制普遍采用求向量的均值来学习上下文的注意力权重。Ma等[6]在注意力机制的基础上进一步提出了双向注意力机制,该机制额外学习注意力权重和上下文词之间的关系。这类方法没考虑到目标属性,会导致一些目标属性和上下文关联的信息丢失。
针对以上问题,本文提出一种基于神经网络的多注意属性情感分析模型。采用双向长短时记忆网络来提取上下文和目标属性的关联,加入了一种位置编码机制来捕捉与目标相邻词的重要信息,结合位置编码和内容注意力来更好提取上下文和目标属性的情感分类。
2 情感分析模型
本文提出的模型结合了位置编码和内容注意力更加充分地学习不同属性的情感特征信息。整体架构如图1所示,模型主要由输入层、上下文层、多注意层和输出层4部分组成。
2.1 任务定义
给出一个由n个词组成的句子S={s1,s2,…,sn}和属性方面列表A={a1,a2,…,ak}以及每个方面对应的句子子序列ai={si1,si2,…,sim},m∈[1,n],多属性情感分析是对句子中多个特定属性进行情感极性分析。
2.2 模 型
2.2.1 输入层
输入层将数据集中的单词映射到低维、连续和实值的词向量空间,所有的词向量被堆叠到一个嵌入矩阵Lw∈Rd*|V|,其中d为词向量的维数,|V|为词汇量。使用预先训练好的单词向量“Glove”[7]来获得每个单词的固定嵌入。
2.2.2 上下文层
通过输入层将单词向量化,并将其作为上下文层的输入。在上下文层使用双向长短时记忆网络[8](bidirectional long short-term memory,BiLSTM)来提取上下文和目标的关联,标准的RNN会遇到梯度消失或爆炸的问题,其中梯度可能在长序列上呈指数增长或衰减。所以用BiLSTM单元作为转换函数,可以更好模拟序列中的长距离语义相关性。与标准的RNN相比,BiLSTM单元包含3个额外的神经门:输入门、遗忘门和输出门。这些门可以自适应记住输入向量,忘记以前的历史,生成输出向量。BiLSTM的更新过程如下
(1)
(2)
(3)
(4)
(5)
(6)
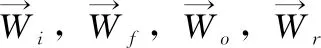
2.2.3 多注意层
注意机制[9]是捕捉上下文和目标词之间相互作用的一种常用方法,普遍采用粗粒度注意机制来学习上下文和目标方面的注意权重,简单的求均值会带来一些信息的损失,特别是对于多个目标方面的句子。对此本文提出了一种细粒度的注意机制,通过BiLSTM网络学习上下文和特征权重,结合位置权重来相互作用。实现步骤如下:
(1)上下文和目标方面特征提取
对于输入序列S={s1,s2,…,sn}通过BiLSTM提取目标的上下文H∈2d*N和目标属性Q∈2d*M,如下所示
(7)
(8)
(2)上下文H更新
通过加入位置编码机制对上下文H进行更新,将式(7)联合式(17)求出更新后的权重,捕捉位置信息和上下文之间的关联
H=[H1*w1,H2*w2,…,HN*wN]
(9)
(3)求取上下文和目标方面的交互矩阵
将BiLSTM提取的上下文和目标方面的信息进行矩阵的乘积,提取上下文目标方面的关联
I=H·QT
(10)
(4)对交互矩阵的行和列分别添加注意力分别得到α和β,然后在对它们求平均使其更加关注中心部分。计算公式如下所示
(11)
(12)
(13)
(14)
2.2.4 输出层
将得到的注意力矩阵做内积为m,然后将其输入到一个确定情感极性的softmax层作为最终的输出,计算如下所示
(15)
p=softmax(Wp*m+Bp)
(16)
其中,p∈C是目标情感分类的概率分布,Wp,Bp分别是权重矩阵和偏置矩阵。其中设置C=3,代表积极、中性和消极。
2.3 多注意机制
2.3.1 位置编码机制
本文加入了位置编码机制来模拟观察,如上下文单词的权重wt和目标属性方面的距离为l,lmax表示句子的实际长度。计算公式如下
(17)
先将目标属性方面的单词的权重设置为0,然后根据位置编码机制[10]对上下文进行初始化,这样得到上下文输出H=[H1*w1,H2*w2,…,HN*wN]。
2.3.2 强注意力机制
注意力机制主要是通过让模型自动的学习上下文和当前属性的关系,能够挖掘出重要的特征属性,为了更好学习上下文和目标属性的信息,本文提出一种强注意力机制。强注意力机制在注意力机制的基础上再添加注意力,如式(11)~式(14)所示,分别再对行和列添加注意力机制,可以更加关注重要的部分。
2.4 模型训练
本文情感分析模型采用交叉熵损失函数,使用L2正则化避免过拟合问题。通过最小化损失函数来优化模型对文本进行属性级情感分析任务,如下所示
(18)
其中,λ是L2正则化参数,θ是线性层和LSTM络的权重矩阵,使用dropout以避免过度拟合。使用小批量随机梯度下降算法来最小化模型中权重矩阵。
3 实验结果及分析
本文提出的模型在SemEval 2014数据集和twitter数据集进行实验,通过引入预训练的Glove词向量进行词嵌入,其中字典大小和训练的维度分别是1.9 MB和[25~300]维度。使用显卡型号为Tesla T4,驱动版本SIM为410.79,CUDA版本为10.0,显存为15 G,Linux系统服务器,深度神经网络框架为Pytorch 1.1.0。
3.1 实验数据和参数配置
laptop、restaurant和twitter数据集分为积极、中性和消极3类标记,按情绪极性分类的分布情况见表1。

表1 实验数据集
参数配置:从均匀分布U(-e,e),e=0.0001随机初始化权重矩阵,并将所有的偏置项设置为0,L2正则化系数设置为0.0001,dropout设置为0.2,将每个英文词汇训练成25~300维的向量。
3.2 方法对比
将本文的算法和以下4种模型在SemEval 2014和twitter数据集进行实验,主要用准确率来度量性能。
(1)LSTM模型主要用LSTM网络对句子进行建模,将最后一个隐藏状态作为句子的最终分类。单一的LSTM模型对于一些特别的情感分类可以达到一定的效果,但是没有考虑到上下文和目标信息的关联。
(2)TD-LSTM[3]模型使用两个LSTM网络进行建模,分别提取句子的方面和上下文。然后将两个LSTM网络的隐藏状态连接起来预测情感极性。
(3)AT-LSTM[11]模型主要是通过注意力机制来获取上下文信息,在LSTM模型中加入注意力机制进行语义建模对情感进行分类。
(4)ATAE-LSTM[11]模型是AT-LSTM模型的扩展,主要是在计算注意力权重的时候引入了特定目标信息。
本文提出一种多注意神经网络模型,通过联合注意力机制和位置编码机制来挖掘上下文和目标属性的关联,使模型能对多个目标进行情感分类。
3.3 实验结果分析
将本文提出的模型与4个基本模型(LSTM、TD-LSTM、AT-LSTM和ATAE-LSTM)进行实验对比,将模型分别在SemEval 2014和twitter数据集上进行训练和交叉验证。在本文的实验中,将文本映射成25~300维度词向量,将SemEval 2014数据集(laptop和restaurant)和twitter数据集的实验结果分别画成柱状图如图2~图4所示,实验结果分别记录见表2~表4。

表2 laptop数据集上不同文本维度的准确率

表3 restaurant数据集上不同文本维度的准确率

表4 twitter数据集上不同文本维度的准确率
由图2~图4可知,本文提出的模型在SemEval 2014和twitter数据集上都取得了较好的效果。通过增加文本维度可以看出不同的算法呈线性增长,标准的LSTM算法在情感分类中只是对一个句子进行分类,随着文本维度的增加LSTM的分类准确率没有明显的提升。相比LSTM算法,AT-LSTM和ATAE-LSTM算法都加入注意力机制,得到更好的分类精度。对于TD-LSTM算法提取上下文和目标之间的关联,可以挖掘出更多目标的信息,从而得到更好的分类精度。

图2 在laptop数据集上不同文本维度的准确率
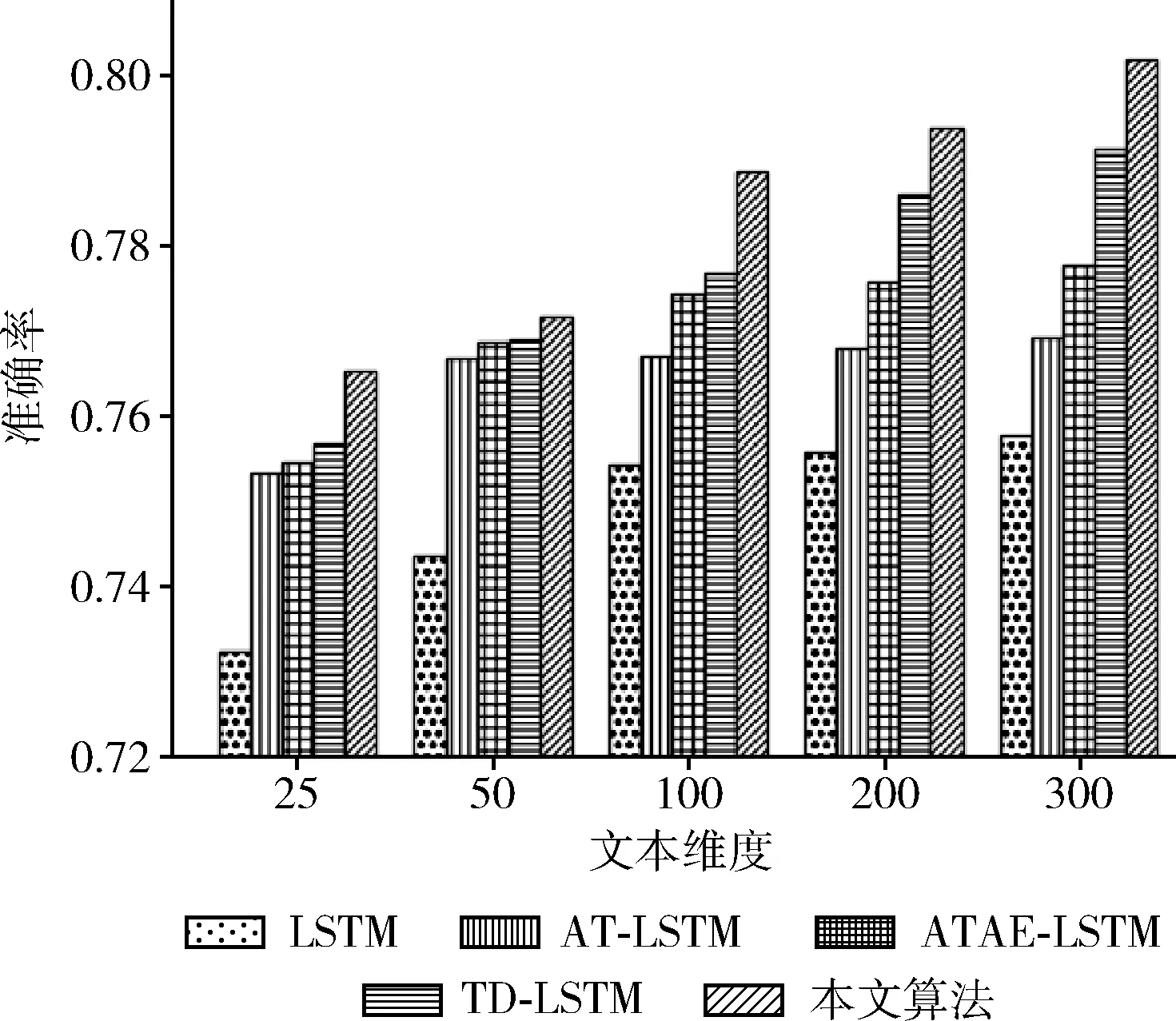
图3 在restaurant数据集上不同文本维度上的准确率
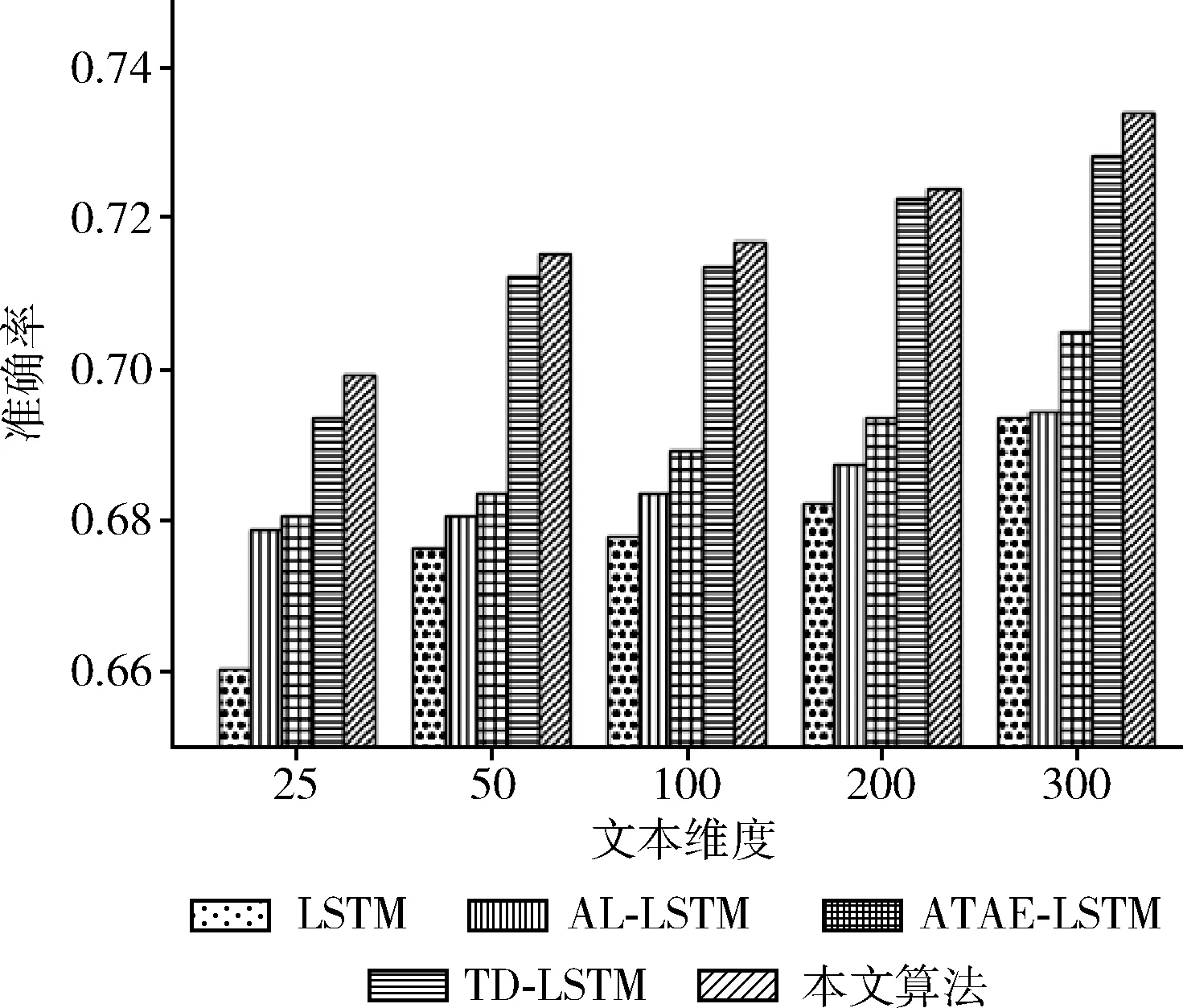
图4 在twitter数据集上不同文本维度上的准确率
本文的模型通过加入位置编码机制和强注意力机制,使模型能够更好捕捉上下文和目标属性方面的关联,并且还可以突出不同位置的单词对属性的影响程度。相对采用单向LSTM模型的ATAE-LSTM,本文采用的是双向长短时记忆模型,这样可以更好提取上下文特征。在SemEval 2014数据集(laptop和restaurant)和twitter数据集不同领域的数据集上进行实验,分类准确率分别到达72.45%、80.17%和73.39%。
如图5所示模型在25维度~300维度上,随着维度的增加基本呈线性增长。加入了注意力机制的AT-LSTM,ATAE-LSTM算法比LSTM算法在不同维度上分类的准确率都要高,加入注意力机制提高了对目标信息的挖掘。相比AT-LSTM,ATAE-LSTM算法,ATAE-LSTM算法加入特定目标的信息,得到更多的上下文和目标的关联,增加了分类的准确率,但是对于多目标分类时准确率较差。LSTM、AT-LSTM和ATAE-LSTM算法都使用单向LSTM,TD-LSTM使用双向LSTM能够更好提取上下文和目标之间的关联,使情感分类的准确率更高。本文的算法使用双向LSTM,添加注意力机制来挖掘上下文和目标之间的关联,添加位置编码机制,挖掘出相邻词汇的重要性。将注意力机制和位置编码机制结合进行建模,解决了对句子中多个目标属性作出比较好的情感分类。

图5 在laptop、restaurant和twitter数据集上准确率对比
如图6展示了本文算法在数据集laptop、restaurant和twitter上训练过程中损失函数的变化情况,从图中可以看出模型迭代20 000次以后基本收敛,说明算法的可行性。
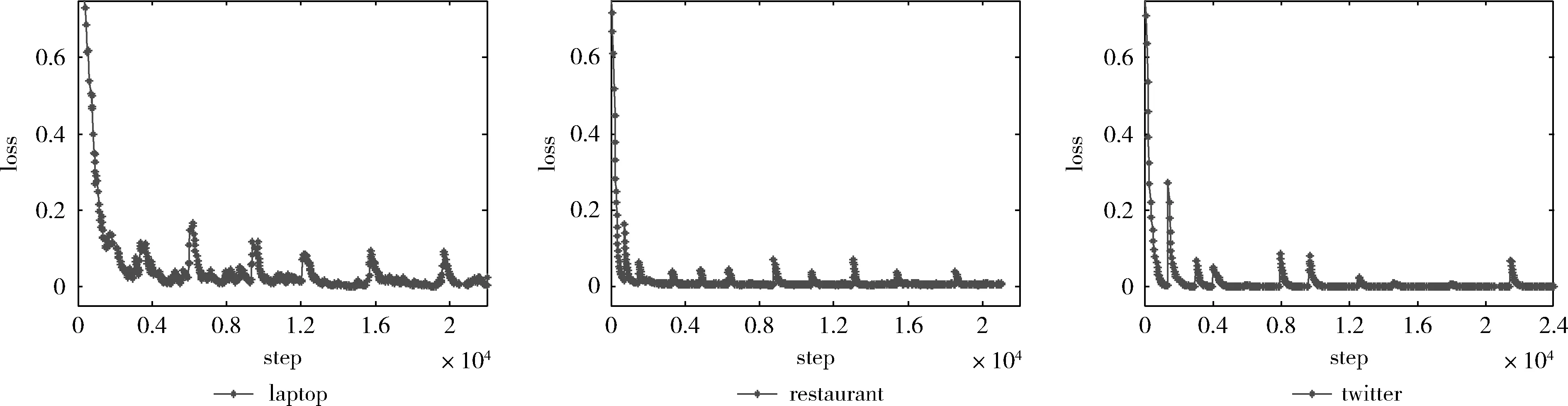
图6 本文算法在laptop、restaurant和twitter数据集上训练的损失函数
3.4 可视化注意力机制
为了更好理解本文提出多属性情感分类的模型。通过对一句话进行权重可视化,其中颜色越深代表权重越大,如图7所示为测试集中的一条句子,其中有两个方面“reso-lution”和“fonts”,每一个方面整个句子中其它词的权重都是不一样的。

图7 可视化注意力权重
4 结束语
在处理序列的问题上,循环神经网络有更好的效果,本文提出的模型加入了双向长短时记忆来挖掘上下文和目标之间的关联,比单向的长短时记忆有更好的效果,通过将强注意力机制和位置编码机制相结合进行建模,可以更好挖掘上下文、目标属性和目标相邻词间的联系,相比一般的模型有更好的分类准确率。
本文在注意力模型中加入了位置信息、上下文和文本内容的关联。使用深度模型(如BiLSTM)隐式地捕捉上下文和内容之间的关联,再结合位置信息捕捉相邻词间的依赖关系,构建出能够对多个目标对象进行情感分析的模型。实验结果表明本文提出的模型在SemEval 2014数据集和twitter数据集效果较好。
本文的贡献:
(1)在模型中加入了位置编码机制,挖掘出与目标词相邻词汇的重要信息。
(2)联合强注意力机制和位置编码机制进行建模,提出一种基于神经网络的多注意属性情感分析模型对多个目标属性进行情感分析。
(3)在SemEval 2014(laptop和restaurant)和Twitter数据集进行实验得到了较好的分类效果。
