非整倍体胎儿羊水质谱多肽初步筛选
2020-10-29宿进江张春斌陈晓杭李冬雪罗小金杨洁霞尹爱华高玉山魏凤香
宿进江,张春斌,陈晓杭,李冬雪,罗小金,杨洁霞,尹爱华,高玉山,魏凤香
(1.黑龙江省佳木斯市佳木斯大学生物学教研室,黑龙江 佳木斯 154007; 2.广东省深圳市龙岗区妇幼保健院中心实验室,广东 深圳 518172; 3.遵义医科大学基础医学院病原生物学教研室,贵州 遵义 563006; 4.广东省妇幼保健院医学遗传中心,广东广州 510000; 5.广州妇幼保健院产前诊断中心,广东 广州 510000; 6.深圳市龙岗区妇幼保健院产科,广东 深圳 518172)
许多家庭随我国二胎政策的实施纷纷选择生育二胎,其中不乏年龄较大的孕妇,而高龄孕妇(35岁以上)随年龄的增长易出现染色体异常,其中唐氏综合征患者高达2%。染色体疾病大多是由染色体异常所导致,而染色体异常是导致胎儿复发性流产及出生缺陷的主要因素,其中染色体非整倍体占首要地位,给家庭和社会带来沉重的负担[1]。目前,针对高危孕妇可通过羊膜腔穿刺、脐血管穿刺等介入性手段进行胎儿细胞染色体核型分析,可有效诊断非整倍体[2-3]。但由于检测时间窗窄、诊断周期较长,需要更早期、快速、精准的分析方法。近年来,随着蛋白质组学质谱技术和生物信息学的不断发展成熟,应用多肽质谱检测不同类型疾病的多肽表达差异,为非整倍体诊断和预后标志物筛选提供了新思路[4-5]。因此,本研究应用国产基质辅助激光解吸电离飞行时间质谱系统(Clin-TOF质谱系统)分析正常对照组及非整倍体组胎儿羊水多肽表达是否存在差异并建立理想模型,现报道如下。
1 资料与方法
1.1 临床病例资料
收集2015年6月至2016年6月期间来深圳市龙岗妇幼保健院产前诊断中心进行介入性产前诊断的三体胎儿羊水样本96例,根据染色体核型分析结果将其分为50例正常对照组,46例21、18、XXY、XYY 、X 5种染色体非整倍体组。所有孕妇均已签署知情同意书。具体病例资料见表1。
1.2 样本采集和预处理
经超声引导下穿刺抽取孕妇羊水5 mL,4 ℃ 3 500 r/min离心10 min。将羊水按照500 μL/离心管分装,放入-80 ℃冰箱短期保存,避免反复冻融。

表1 正常对照组和非整倍体组临床信息
1.3 试剂
弱阳离子磁珠试剂盒购自毅新兴业(北京)科技有限公司。
1.4 主要仪器
Clin-TOF-Ⅱ质谱系统分析平台(北京毅新博创生物科技有限公司)。
1.5 磁珠法提取多肽
样本多肽提取过程参见文献[6]。
1.6 Clin-TOF-II质谱分析
取1 μL多肽洗脱液样品滴在ClinTOF靶板上,自然晾干,再取1 μL基质覆盖到样品上,自然晾干。校正仪器,进行样品检测。每例样品进行3次生物学重复,获得原始的质谱数据。将原始数据转换为.txt格式的文件导入到BioExplorer软件,对于每例样品的3个实验重复求得算数平均后即得到了该例样品的信号处理数据。
1.7 统计学方法
对于BioExplorer处理后数据主要进行了t检验、ANOVA检验(f检验)、 Wilcoxon检验、Krμskal-Wallis检验及Anderson-Darling检验等统计学分析。对于不同的分组分别进行确切概率Fisher、K-近邻KNN、线性支持向量机Linear SVM、径向基函数网络RBF等模型。
2 结果
2.1 羊水多肽质谱图的检测
96 例信号处理数据的原始质谱图如图1A和1C所示。对原始图谱中存在的化学噪音和电信号噪音需在进行分析前通过数据校正和归一化等消除噪音。处理结果如图1B和1D所示。后文所有的分析是建立在96例信号处理数据的基础上。
2.2 正常对照组与非整倍体组多肽组学表达差异
对于处理后的96例数据进行了t检验、ANOVA检验、Wilcoxon 检验、Kruskal-Wallis 检验及Anderson-Darling 检验等相关统计学分析。经统计分析后,得到124个差异多肽峰,其中显著性差异多肽峰95个,极显著性差异多肽峰29个。前10名极显著差异多肽峰列表如表2所示。其中2 245.8m/z多肽峰和1 028.7m/z多肽峰差异重现性最好,2 245.8m/z多肽峰和1 028.7m/z多肽峰峰值位点分别如图2、图3所示。所有样本在这2个差异峰上的分布如图4所示。
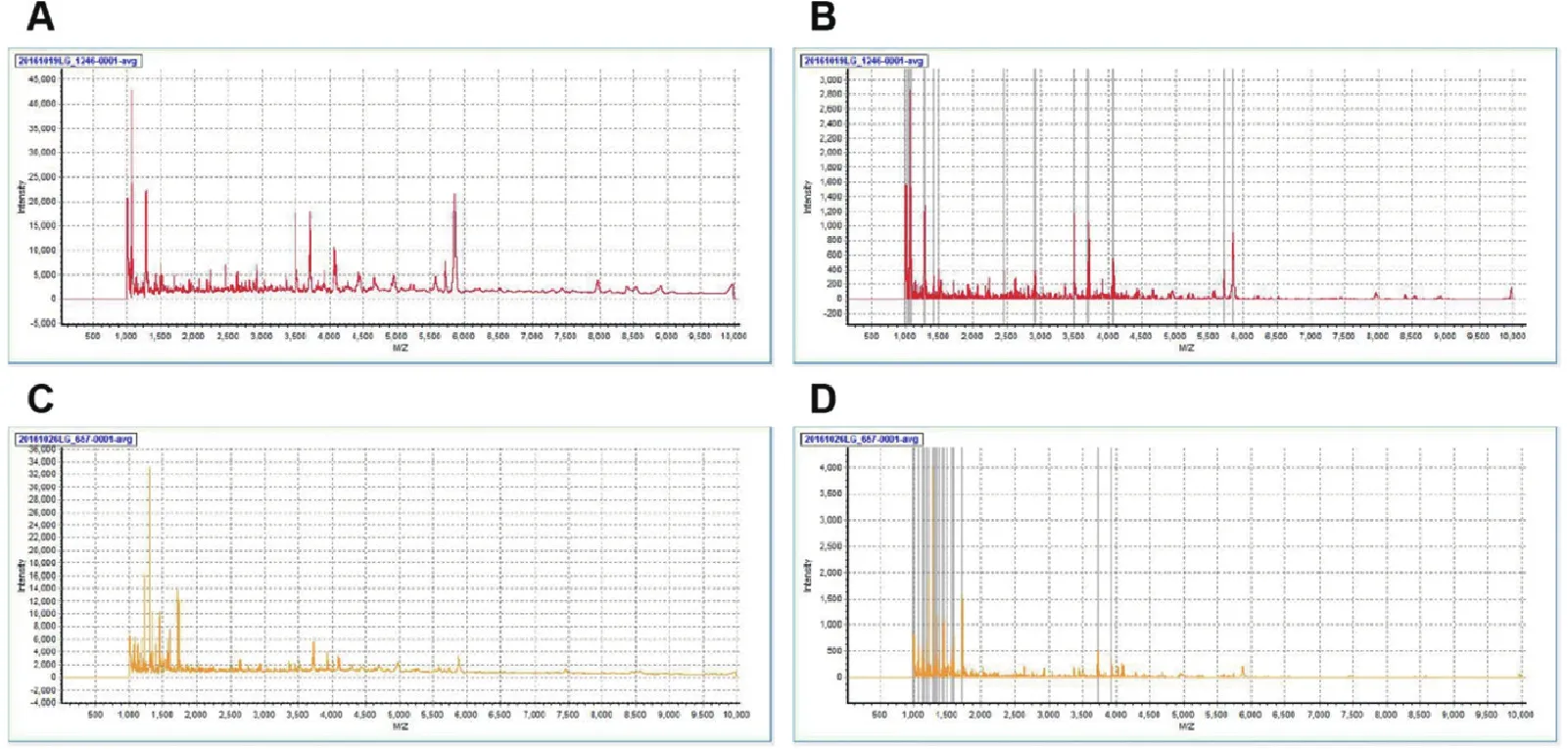
注: 正常对照组原始(A)及处理后(B)质谱图;非整倍体组原始(C)及处理后(D)质谱图。

表2 2 245.8 m/z和1 028.7 m/z多肽峰极显著差异多肽峰列表 Table 2 List of significantly differentiated peptide peaks

图2 62号差异峰位点-峰值图Figure 2 Site-to-peak plot of difference peak 62

图3 3号差异峰位点-峰值图Figure 3 Site-to-peak plot of difference peak 3
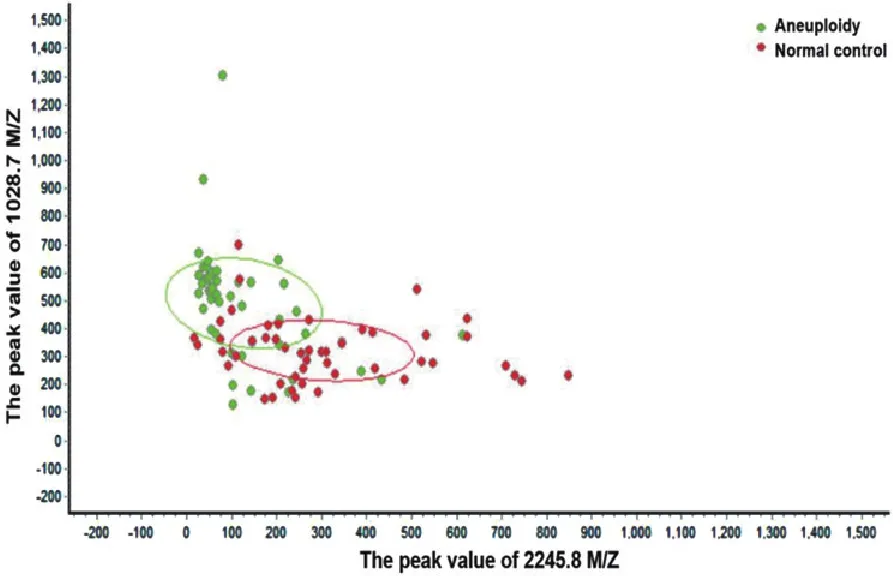
图4 正常对照组和非整倍体组在差异峰上的分布
2.3 非整倍体组多肽组学诊断模型的建立及验证
根据极显著差异多肽峰2 245.8m/z和1 028.7m/z,对于正常对照组和非整倍体组进行模型建立,并计算模型的准确率如表3所示。4种模型中,RBF模型能较为准确地区分正常对照和非整倍体。

表3 根据2 245.8 m/z和1 028.7 m/z多肽峰建立分组模型Table 3 Establishment of models based on 2 245.8 m/z and 1 028.7 m/z peptide peaks
3 讨论
非整倍体是产前诊断最常见的染色体数目异常类疾病,其中21、18、13三体会导致严重的胎儿结构异常和智力障碍等,性染色体数目异常可导致患儿不育和发育异常[7-9]。针对非整倍体尽早筛查诊断,有利降低出生缺陷,提高全民身体素质。羊水作用之一是调节胎儿与母体的动态平衡,它包含的每一种蛋白质和小分子多肽表达均能反映胎儿的生理或病理状态,一旦胎儿在整个怀孕期间出现异常,这种平衡就会被破坏[10]。因此,为了孕妇母体及胎儿的健康,寻找这种蛋白质或多肽的失衡,有助于疾病的早期发现。多肽质谱技术除了应用于产前诊断筛查外,主要集中在羊膜过早破裂的检测和羊膜内感染的诊断上[11-13]。但到目前并未找到更为廉价且诊断率高的差异性蛋白作为产前诊断的特异标志物。
蛋白质组学技术直接以蛋白质为切入点在整体水平上研究差异性蛋白质功能的调控规律,结合质谱技术,可高效地捕获体液中的小分子和低丰度蛋白,并对筛选出的差异性蛋白或多肽进行序列鉴定[14]。本研究应用Clin-TOF-Ⅱ质谱系统对非整倍体胎儿羊水进行初步多肽质谱分析。对96例羊水样本进行质谱分析,如图1可知,去噪音处理后的图像与原始图相比,峰值集中,波动稳定。结合统计学分析发现,得到124个差异多肽峰,其中显著性差异多肽峰95个,极显著性差异多肽峰29个。由此可知,实验数据符合统计学意义,差异性峰值可观。其中对排名前10的2 245.8m/z和1 028.7m/z多肽峰进行峰位点筛查,结合图4,正常对照组峰值集中在300,非整倍体差异性极显著的2 245.8m/z峰值集中在100,1 028.7m/z多肽峰集中在500,与对照组相比,重现性及差异性多肽显著。最后,根据极显著差异多肽峰2 245.8m/z和1 028.7m/z,对于正常对照组和非整倍体组进行模型建立,发现Fisher、KNN、Linear SVM、RBF等模型中,RBF模型可区分正常对照组与非整倍体患者。
综上所述,2 245.8m/z和1 025.7m/z多肽峰所建立的RBF理想模型,可作为区分正常对照组与非整倍体患者的理想模型。2 245.8m/z和1 028.7m/z多肽峰中所含的差异性多肽,可能是潜在的非整倍体患儿羊水多肽标志物。但是,由于样品量的限制,尚未鉴定出差异性多肽和它的功能。下一阶段,将需要扩大羊水样本量,筛查差异性多肽。这对于探索非整倍体染色体异常疾病的发病机制,寻求临床有效的防治手段有重要的指导意义。
