多目标肉牛进食行为识别方法研究
2020-10-29张宏鸣李永恒李书琴王红艳宋荣杰
张宏鸣 武 杰 李永恒 李书琴 王红艳 宋荣杰
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.宁夏智慧农业产业技术协同创新中心, 银川 750004;3.西部电子商务股份有限公司, 银川 750004)
0 引言
近年来,我国牛肉需求量大幅增加,国内肉牛养殖行业发展迅速[1],大规模肉牛养殖对养殖场信息化水平提出了较高要求。肉牛进食行为能够反映其健康状况,同时也影响肉牛的进食量,进而影响其自身的发育及牛肉的质量和产量。准确识别肉牛进食行为能够帮助管理者及时了解肉牛个体进食量,对肉牛养殖具有重要价值。
目前,众多学者开展了关于动物行为监测的研究工作。利用可穿戴设备监测动物状态、获取动物行为数据,借助统计[2-3]、机器学习[4-9]、深度学习[10-11]等方法分析数据,实现对动物多种行为的监测。但可穿戴设备需要根据不同的监测对象,在设备的定制、佩戴、维护上成本较高。近年来,利用获取视频数据,采用非接触式方法监测动物行为的研究较多。文献[12-16]通过提取监测动物目标,并分析建模,采用聚类或分类算法实现对动物行为的分类识别。文献[17-21]通过目标检测获取动物图像,利用图像识别算法实现对动物行为的监测和识别。这些方法大部分需要依赖搭建的实验场地或特定的监控视角,个别方法可以利用监控设施实现行为识别,但每次仅能识别一个目标行为。随着Fast R-CNN、YOLO等目标检测算法的出现,目标检测在果实识别[22-24]、动物行为检测与个体识别[21,25-27]领域得到了一定的应用。但有关肉牛多目标行为识别和监测研究尚未见报道。
本文提出一种基于YOLOv3模型和卷积神经网络的肉牛进食行为识别方法,利用实际养殖场监控视频构建数据集,训练YOLOv3目标检测模型检测肉牛目标,通过填充、丢弃操作构建卷积神经网络、训练图像识别模型,以实现对养殖场监控视频观测范围内肉牛进食行为的识别。
1 材料与方法
1.1 肉牛视频获取
肉牛视频数据于2019年4—7月在宁夏回族自治区银川市犇旺生态养殖公司肉牛养殖场采集。每段视频时长35 min,肉牛视频格式为mp4,分辨率为1 920像素(水平)×1 080像素(垂直),视频帧率为24 f/s。本文目的是对肉牛进食行为进行监测和识别,故筛选出处于室内牛栏的监控视频作为实验数据,养殖场监控视频场景如图1所示。

图1 养殖场监控视频Fig.1 Farm monitoring video
1.2 技术路线
本研究旨在使用机器视觉方法对监控视频进行分析,实现对肉牛进食行为的识别。识别技术路线如图2所示,包括3个环节:
(1) 构建数据集:提取监控视频关键帧,对关键帧进行标注、截取,构建肉牛目标检测数据集、肉牛行为数据集。
(2) 进食行为识别:利用肉牛目标检测数据集和肉牛进食行为数据集,训练YOLOv3模型用于肉牛目标检测,训练卷积神经网络用于肉牛行为图像识别,最终实现对多目标肉牛进食行为的识别。
(3) 结果分析:将特征图可视化并分析;在测试集上对进食行为识别方法进行评估。

图2 技术路线图Fig.2 Technology roadmap
1.2.1数据集构建
构建2个数据集,分别用于训练目标检测模型和图像识别模型。监控视频中肉牛个体众多,花色多样,姿态复杂,给检测肉牛目标、识别肉牛进食行为增加了一定的难度。为了避免数据的单一性,增强数据集的丰富性,对筛选的视频进行关键帧提取。使用LabelImg软件标注关键帧中的肉牛目标,利用标注的关键帧图像和标注文件,共1 233组,构建肉牛目标检测数据集。通过读取标注文件,对关键帧进行截取,获得肉牛个体图像。肉牛个体图像可分为进食和非进食两类。为了使训练模型的鲁棒性更好,选取进食和非进食行为下不同姿态肉牛的图像,构建肉牛行为数据集。本文构建的肉牛行为数据集,包括肉牛进食行为图像846幅,非进食行为图像1 000幅。肉牛进食行为数据集中,具有代表性的肉牛进食行为图像如图3a所示,肉牛非进食行为图像如图3b所示。

图3 行为识别数据集部分样例Fig.3 Some examples of behavior recognition data sets
为了验证本文提出的肉牛进食行为识别方法的有效性,选取不同光照情况下、不同时段的监控视频8段,每段视频30 s,共5 760幅图像作为测试集。测试集中的视频场景具体情况如图4所示。

图4 测试集场景Fig.4 Scence of test sets
1.2.2方法设计
本文提出的肉牛进食行为识别方法基于先检测肉牛目标,后识别个体行为的思路。
1.2.2.1肉牛目标检测
YOLOv3模型借鉴了残差网络结构,将生成的特征图和输入叠加起来,叠加后的特征图作为新的输出输入到下一层网络,减小了梯度爆炸的风险,增强了网络的学习能力。利用多尺度特征进行目标检测,在保证检测速度的同时,提升了检测精确度。采用方差加二值交叉熵的损失计算方法,损失函数包括坐标误差、交并比误差和分类误差3部分。使用反向传播算法,不断调整参数,更新模型,使损失不断减小。在多个公开数据集上取得了优异的效果[28]。
本文选用YOLOv3模型作为肉牛目标检测算法,通过目标检测,获取观测范围内肉牛目标位置,对肉牛目标进行截取,进而对肉牛进食行为进行识别。
1.2.2.2肉牛进食行为识别
参考LeNet-5网络结构[29],构建的卷积神经网络包括4个卷积层、4个池化层和3个全连接层,并在前两个全连接层中采用丢弃操作。本文卷积神经网络结构如表1所示,并进行改进:

表1 卷积神经网络结构Tab.1 Convolutional neural network structure
(1) 在卷积操作时采用填充
肉牛牛头的位置和肉牛与进食槽的距离是判断肉牛是否处于进食行为的重要依据。通过观察YOLOv3模型获取的肉牛行为图像可以看出,大多数图像中牛头、进食槽处于图像边缘位置。填充操作通过对特征图边缘进行填充,能够提高图像边缘的特征被卷积核提取的次数,从而尽可能保留图像边缘的细节特征,填充操作的原理如图5所示。

图5 填充操作原理图Fig.5 Schematics of padding
(2) 在全连接层中加入丢弃操作
由于肉牛姿态多样,部分非进食行为的肉牛图像与进食行为的肉牛图像相似度较高,导致模型训练过程中容易出现过拟合。丢弃操作通过使卷积神经网络全连接层的神经元随机失去活性[30],降低神经元之间的依赖,从而提高网络模型泛化能力,丢弃操作的原理如图6所示。

图6 丢弃操作原理图Fig.6 Schematics of dropout
1.2.3评价指标
1.2.3.1目标检测评价指标
对于一个目标检测算法,通常从每秒处理的帧数、目标检测的准确度等方面评估其效果。由于本实验的目的是尽可能多地识别视频中的肉牛目标,故本实验更关注训练得到的YOLOv3模型对肉牛目标检测的准确度。
本文中,需要比较YOLOv3模型在验证集上对肉牛目标检测的坐标与真实标注坐标的差距。在评估时,首先需要计算模型所预测的检测框坐标和真实框坐标的交集与并集之间的比例,该比例又称为交并比(IoU)。目标检测数据集使用Pascal VOC数据集格式。利用交并比判断检测是否正确,使用Pascal VOC数据集评估目标检测算法效果时,设置阈值为0.5,即如果预测的检测框坐标和真实框坐标的交集与并集之间的比例大于0.5,则认为检测正确,否则认为检测错误。
采用验证集全部视频帧上的平均精确度VAVE(验证集中全部视频帧图像中肉牛被正确检测的百分比)来评价目标检测的效果。VAVE的计算公式为
(1)
式中A——正确检测肉牛目标的次数
B——验证集中的每幅视频帧图像中实际肉牛目标的个数
S——验证集包含的视频帧总数
1.2.3.2图像识别评价指标
图像识别样本分为4种类型:真正例(True position,TP)表示模型对正例进行正确分类;假正例(False position,FP)表示模型对正例进行错误分类;假反例(False negative,FN)表示模型对反例进行错误分类;真反例(True negative,TN)表示模型对反例进行正确分类。真、假正例的总称是正例(Position,P),真、假反例的总称是反例(Negative,N)。本实验中预选出3个评价标准,对模型进行效果评价。
(1)精确度(VP)表示模型正确分类的肉牛进食行为图像样本数量占分类为肉牛进食行为图像样本数量的比率,计算公式为
(2)
式中ATP——肉牛进食行为图像正确识别的个数
AFP——肉牛进食行为图像错误识别的个数
(2)召回率(VR)表示模型正确分类的肉牛进食行为图像样本数量占实际肉牛进食行为图像样本数量的比率,计算公式为
(3)
式中AFN——肉牛非进食行为图像错误识别个数
(3)准确率(VACC)表示通过模型识别,最终分类正确(包括肉牛进食行为图像样本和肉牛非进食行为图像样本)的图像样本数占总样本数的比率,是评价模型整体性能的评价指标,计算公式为
(4)
式中ATN——肉牛非进食行为图像正确识别个数
AP——肉牛进食行为图像总数
AN——肉牛非进食行为图像总数
1.3 实验平台
实验执行环境为64位Windows 10系统,AMD Ryzen 3500X 6-Core CPU 4.0 GHz,NVIDIA GeForce RTX 2060 SUPER GPU,16 GB内存,编程语言为Python 3.7.4,使用Tensorflow 1.15、Keras 2.1.5进行网络搭建、训练和测试,开发工具为PyCharm 2019。
1.4 模型选择
1.4.1YOLOv3模型
训练YOLOv3模型时,设置批尺寸为5,迭代次数为500,以8∶2的比例划分训练集和验证集。为了选择出合适的初始学习率,在不同量级下进行学习率测试,将初始学习率设置为0.000 01、0.000 1、0.001、0.01、0.1、1、10分别进行模型训练,同时为了避免学习停滞,在迭代150次和迭代300次时,设置学习率衰减为之前的1/10,经过多次训练,分别对模型进行评估,保留效果最好的模型供后续实验使用。
经过评估,不同初始学习率下训练得到的模型,在测试集上对肉牛目标检测情况和平均精确度如表2所示。从表2可以看出,当初始学习率设置为0.1时,模型正确识别肉牛个数最多,在196幅图像、共计734个肉牛目标的测试集中(包含多个肉牛个体的多种姿态和行为),该模型正确识别683个肉牛目标,51个肉牛目标未识别,错误识别30个肉牛目标;模型平均精确度最高,在测试集上的平均精确度为92.5%。该模型经过500次训练迭代后,训练集上的损失函数变化曲线如图7所示。当训练达到300次以上时,随着迭代次数的不断增加,训练损失趋向稳定,网络模型达到较好的训练效果。

表2 不同学习率下YOLOv3检测情况和平均精确度Tab.2 Detection and average precision of YOLOv3 at different learning rates
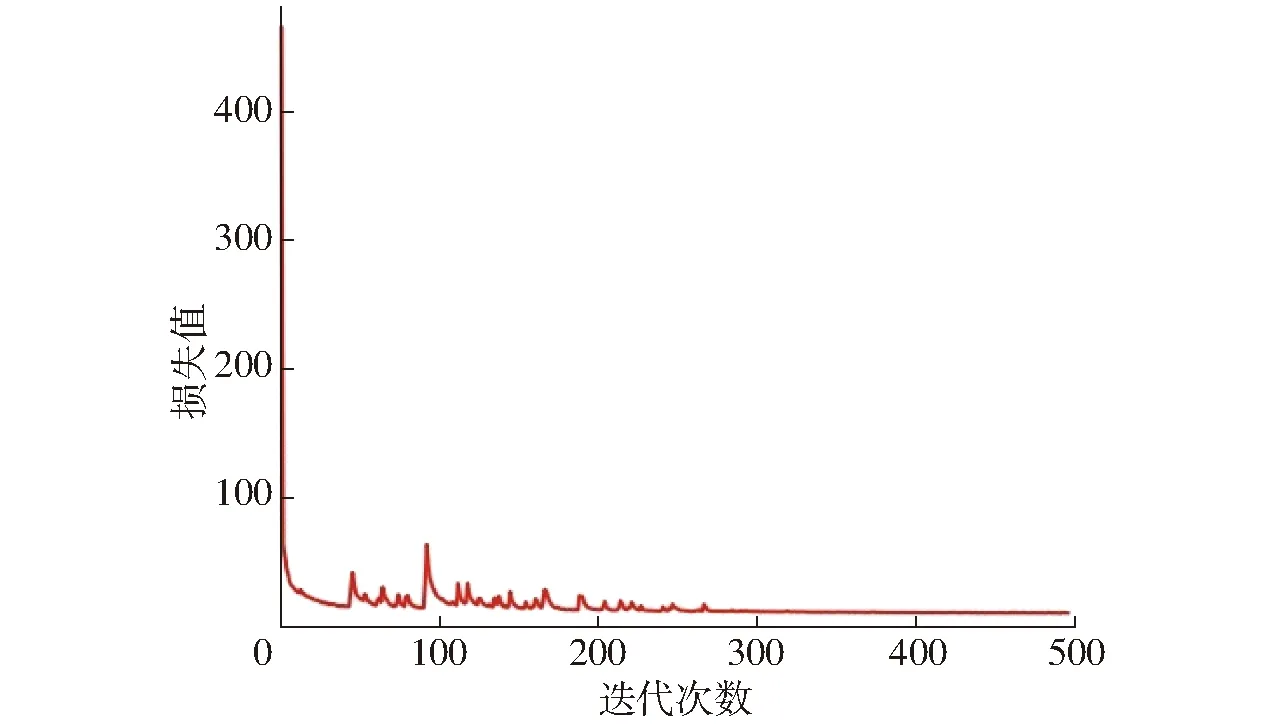
图7 YOLOv3损失值变化曲线Fig.7 Loss change curve of YOLOv3
1.4.2卷积神经网络模型
在不同量级下进行初始学习率的测试,将学习率设置为0.000 01、0.000 1、0.001、0.01、0.1、1、10分别进行模型训练,其中当学习率大于等于0.1时,模型发生过拟合,不同学习率下卷积神经网络模型的效果如图8所示。丢弃操作会使神经元按照一定比例失去活性,当丢弃率太低时,难以起到效果;当丢弃率太高时,容易导致模型欠学习。将丢弃率分别设置为0.1、0.2、0.3、0.4、0.5、0.6,不同丢弃率下卷积神经网络模型的效果如图9所示。经过评估,最终选取学习率为0.000 1、丢弃率为0.5的模型对肉牛进食行为进行识别。

图8 不同学习率下卷积神经网络模型的效果Fig.8 Effect of convolution neural network model at different learning rates

图9 不同丢弃率下卷积神经网络模型的效果Fig.9 Effect of convolutional neural network model at different dropout rates
2 结果与分析
2.1 特征图可视化
本文利用反卷积和反池化,将输入图像的激活特征实现可视化[31],可以清晰地看到卷积神经网络提取的图像特征以及提取特征的特点。
通过对比第1次卷积操作和第4次卷积操作后提取的图像特征,能够发现浅层卷积层重点提取图像中肉牛的轮廓特征,可以分辨出特征图中的肉牛目标,如图10所示。随着卷积层的加深,得到的特征越来越抽象,但是通过仔细观察特征图,可以发现经过多次卷积操作提取到更多位于图像边缘的特征,如图11所示。
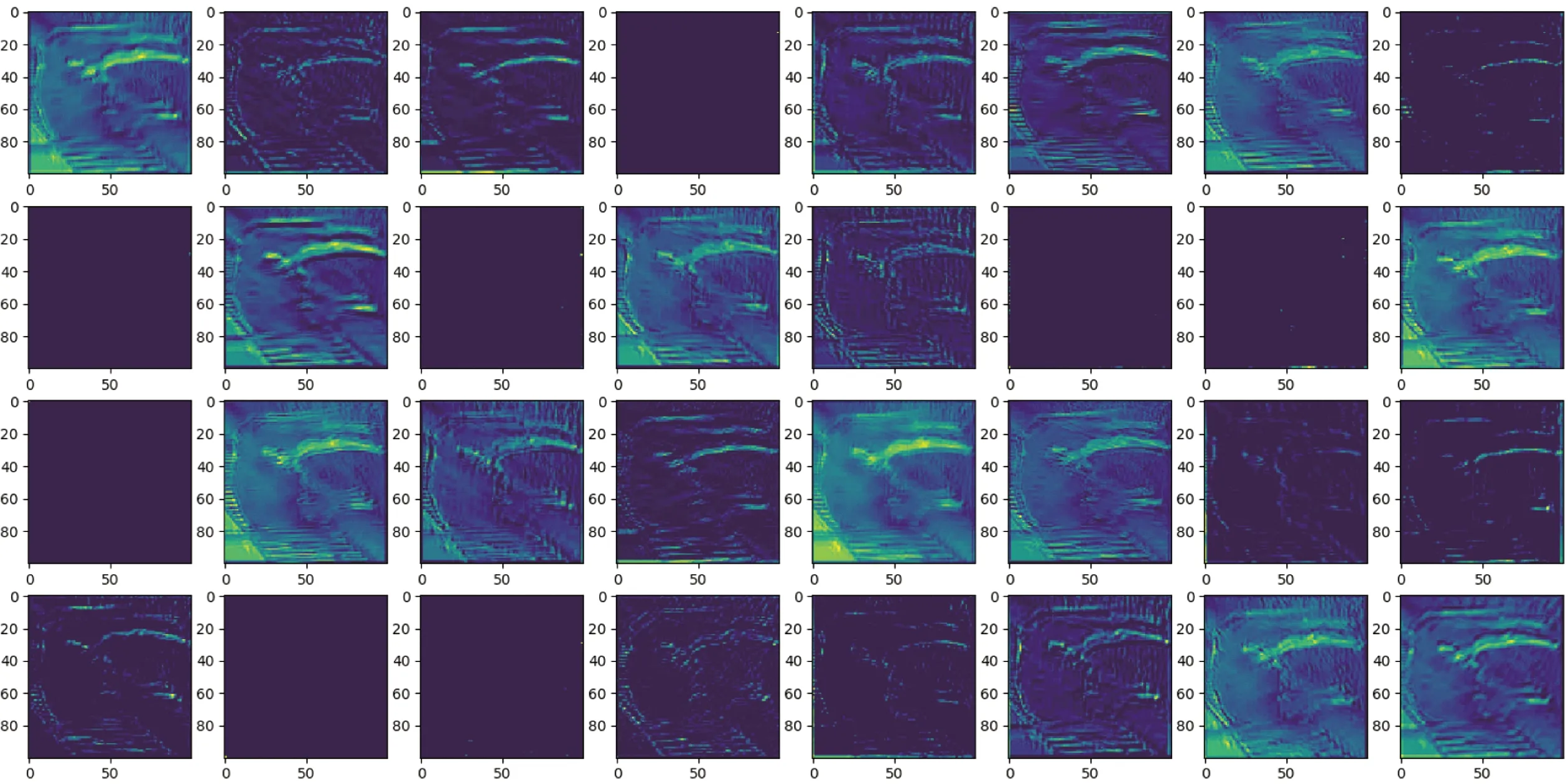
图10 第1次卷积操作输出的特征图Fig.10 Characteristic graph of the first convolution operation output

图11 第4次卷积操作输出的特征图Fig.11 Characteristic graph of the fourth convolution operation output
2.2 识别结果分析
肉牛目标检测的目的是识别肉牛个体,进而才能通过图像识别模型对肉牛个体的进食行为做出判断,因此肉牛进食行为识别的准确率在一定程度上能够反映目标检测的准确率。在8段30 s视频共5 760幅图像测试集中对本文提出的多目标肉牛进食行为识别方法进行评估,肉牛目标检测的平均精确度为83.8%;对检测到的肉牛目标进食行为识别的平均精确度为79.7%,平均召回率为73.0%,平均准确率为74.3%,在测试集各视频取得的识别结果如表3所示,各测试视频的识别结果如图12所示。总体来看,本文提出的基于机器视觉的肉牛进食行为识别方法具有较好的准确性,能够为肉牛行为监测提供方法支持。
3 讨论
本文提出的基于YOLOv3模型的多目标肉牛进食行为识别方法识别的肉牛进食行为与肉牛真实行为存在误差,产生这些误差的原因主要有:
(1)目标检测准确性的影响。目标检测算法对于监控视频中距离较远、目标较小的肉牛难以检测、识别;对于出现相互遮挡的肉牛目标,难以完全识别。后续可通过扩充肉牛目标检测数据集或尝试不同的目标检测算法来提升目标检测的准确性。

表3 测试集目标检测和行为识别结果Tab.3 Object detection and behavior recognition results of test sets %
(2)图像识别准确性的影响。利用卷积神经网络进行图像识别时,由于肉牛姿态、花色的多样性,个别肉牛的进食行为识别存在波动;部分肉牛距离进食槽较近时,容易误识别。肉牛个体进食行为准确率仍有很大的提升空间。后续可通过扩充肉牛进食行为数据集,提高肉牛行为多样性、肉牛个体多样性,或通过改善神经网络结构来提高肉牛进食行为图像识别的准确性。

图12 测试集识别结果Fig.12 Recognition results of test sets
4 结束语
通过获取肉牛养殖场的监控视频,建立了肉牛目标检测数据集、肉牛行为数据集;使用YOLOv3模型实现了对监控视频观测范围内肉牛的检测;利用卷积神经网络对检测的肉牛目标进行进食行为识别。在包含8段视频共5 760幅图像的测试集中,肉牛目标检测的平均精确度为83.8%,肉牛进食行为识别的平均精确度为79.7%、平均召回率为73.0%、平均准确率为74.3%,验证了利用监控视频对肉牛进食行为监测的可行性。
