高速量子随机数产生中的实时并行后处理
2020-10-28吴明川张江江郭晓敏郭龑强
吴明川,成 琛,张江江,郭晓敏,郭龑强,2
(1. 太原理工大学 a.新型传感器与智能控制教育部重点实验室; b. 物理与光电工程学院,太原 030024;2. 山西大学 量子光学与光量子器件国家重点实验室,太原 030006)
0 引 言
随机数是多种现代应用中的重要资源,如密码学[1-2]、统计学和科学模拟[3]等。量子随机数发生器(Quantum Random Number Generator, QRNG)利用量子物理学的基本原理,理论上可以产生不可预测、不可复现的真随机数,但实际应用中量子信号会不可避免地混入经典噪声,影响随机性和安全性[4],因此需要对原始量子随机数进行后处理。在目前已有的多种后处理方法中,托普利茨(Toeplitz)提取器为信息论可证的随机提取方案,且目前已开展了基于现场可编程门阵列(Field Programmable Gate Array, FPGA)实时后处理的实验研究。
基于FPGA的量子随机数实时后处理方案中,在模数转换器(Analog to Digital Converter, ADC)采样获得原始随机数的同时,需要FPGA实时对随机数后处理。目前基于FPGA硬件已达到了3.36[5]和6.00 Gbit/s[6-7]等较高的量子随机数产生速率,而采用的ADC采样频率达到1 GSa/s[5-7],同时依赖于FPGA对高采样率ADC的支持,实质上造成了QRNG的高成本,阻碍了其实用化。
本文基于量子真空态宽带噪声起伏[8-12]以较低采样率的ADC并行提取3个通道的量子随机数,基于FPGA的后处理设计,充分利用FPGA资源,发挥了FPGA的最大处理性能。在一个中等性能的FPGA中构建了3路并行后处理的Toeplitz哈希提取器。最终,FPGA后处理模块资源占用为61%,其余辅助模块为30%,实现了提取速度为8.24 Gbit/s的3通道量子随机数的实时产生及安全后处理。此外对生成的随机数进行了多项评测以保证随机数的随机性。
1 实验设计与分析
1.1 实验装置
实验方案如图1所示。量子熵源源于真空态的正交起伏,其为能量最低的自然纯态,具有较高的安全性。之前的研究工作中[10-12],基于真空状态QRNG的生成速率受量子边带模式带宽的限制。为了充分利用量子熵源,利用宽带平衡零拍探测器(Balanced Homodyne Detector, BHD)对量子真空态分量起伏进行提取,同时构建3通道并行随机数输出及后处理。
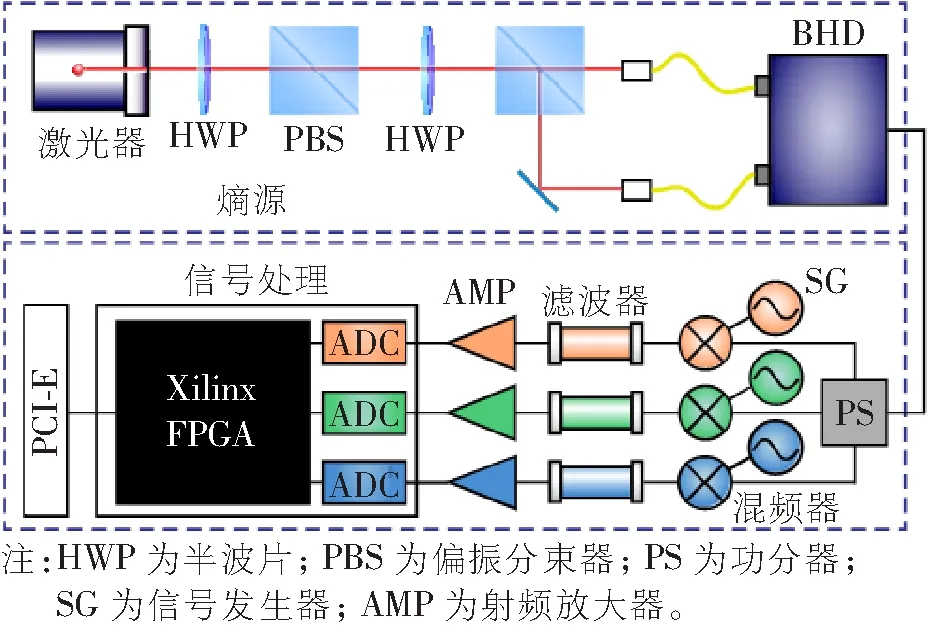
图1 基于真空态量子分量起伏的高速量子随机数产生及实时并行后处理实验方案
图1中,单模激光器工作的中心波长为1 550 nm,在BHD(1.6 GHz,BPD480C-AC)的零拍探测带宽内提取3个独立的量子边带模式。随后,利用混频器和低通滤波器从零拍信号中提取3个带宽为120 MHz、中心频率分别为200、600 MHz和1 GHz的量子边频带模式。混频滤波中的参考信号由SG提供。3个ADC的采样频率均为240 MHz,采样精度均为16位,分别对相应频率模式下的信号进行采样,3路采集获得的原始随机比特分别在硬件FPGA(xc7k325t-2ffg676)中进行实时并行后处理,最终将3个通道生成的随机数通过高速串行计算机扩展总线标准接口(Peripheral Component Interconnect Express, PCI-E)实时输出。
1.2 FPGA实现Toeplitz后处理的资源占用分析
本文利用集成处理环境(Integration Software Environment, ISE)在一个FPGA(xc7k325t,Xilinx Inc,California,USA)中实现了3路Toeplitz 实时安全量子随机数后处理。因为Toeplitz矩阵运算中不同列之间的运算完全独立,而且随机数后处理仅涉及二进制比特的逻辑运算,FPGA的特性使其非常适合多路量子随机数生成的并行后处理,但Toeplitz后处理算法涉及大规模矩阵运算,会占用FPGA中大量的逻辑资源,所以有必要分析并优化其硬件资源。
本文优化了FPGA内部的逻辑资源,以实现3个Toeplitz矩阵的并行计算,并使硬件逻辑资源的利用达到最大化。本文选择的FPGA芯片为Kentex7-325t,可提供约203 800个查找表(Look-Up Table, LUT)。ADC控制和高速输出控制等其他模块所需使用的LUT约占总硬件资源的28.4%。根据信息论对后处理安全性的分析[13],Toeplitz矩阵的行数m和列数n至少应为102量级,这就会导致剩余的资源不足以构建相应规模的Toeplitz矩阵。为了减少资源的使用,将整体规模较大的Toeplitz矩阵与原始随机数序列之间的处理分解为多个Toeplitz子矩阵与较短的原始随机数子序列之间的处理,同时增加整体后处理所需的时钟周期数,进而构建可即时处理ADC所生成随机比特的随机提取器,最终实现QRNG后处理的实时性。
m×nToeplitz矩阵被划分为行列数分别为m和k的n/k个子矩阵(n为k的整数倍),因此整个Toeplitz矩阵处理被分为n/k个步骤。每个步骤都是对m×k个子矩阵和k位原始随机数序列的乘法计算,该过程占用一个时钟周期,具体拆分过程为
式中:s1,s2,…,sm+n-1为Toeplitz矩阵元;d1,d2,…,dn为ADC的输入。k值越大,则每个步骤所需的逻辑资源越多。在给定的时钟频率下,由于实时性的要求,不能将k的值设置得太小——在一段时间(多个时钟周期)内,对于每个通道,FPGA中的后处理位数必须等于ADC读取的位数。本文中ADC采样和FPGA后处理的时钟频率均为240 MHz,k的值设置为16,等于ADC的分辨率。
在确定了子矩阵列数后,需要确定3个Toeplitz矩阵的规模。根据信息论,后处理的提取比例受剩余哈希引理的约束[14]:
式中:l为可提取的随机比特长度;Hmin为需要进行提取的原始随机数序列的原始最小熵含量;ε为安全参数。最小熵表征了测量结果统计分布中可提取的随机数的下限,用于衡量量子随机数的随机性,其定义为
式中:Pr[X=V]为样本空间X中二进制元素V的统计概率;δ为ADC分辨率。在前期真空QRNG熵含量最大化研究的基础上,实验实现了3路子熵源的最优化采样范围设置。基于3路原始数据采样(80 Mbits)分析得出各路信号的经典及总的统计分布方差[15],基于下式计算得出每一路各自的最小熵含量为
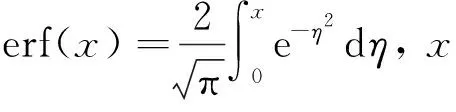
本文中FPGA的LUT总数为203 800。比较使用不同数量通道后处理时的逻辑资源占用情况,可以发现随着并行通道数量的增加,PCI-E控制模块和其他功能模块所占用的LUT数量变化幅度不大,约占FPGA中所有LUT的28.4%,平均每个通道的Toeplitz矩阵后处理约占总硬件资源的20.3%。显然,多个真空边带模式提取的原始比特仅在一个FPGA中并行独立地进行后处理,同时具有较高的FPGA逻辑资源利用率。
不同通道数后处理时FPGA的逻辑资源占用情况如表1所示。
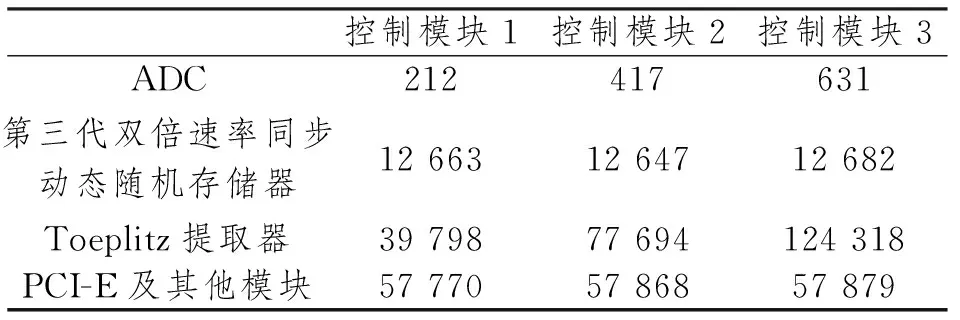
表1 不同通道数后处理时FPGA的逻辑资源占用(LUT占用)
1.3 并行Toeplitz后处理算法的时序设计
基于FPGA的并行处理性能,构建了双层并行结构,以实现对3个不同量子边带模式的3组原始随机比特的Toeplitz哈希后处理。在外层,3个子熵源的Toeplitz提取器是独立构建的,并且同时运行;在内层,对于每个量子边带模式, Toeplitz实时后处理都是在流水线算法中实现的,FPGA中各个数据信号随时钟信号进行并行的硬件处理。3个通道的ADC采集和FPGA中的实时并行处理由同一个240 MHz的时钟控制,随后将3个通道产生的随机数每16位交替混合,并实时输出。
本文设计了后处理过程中每一通道的信号时序,如图2所示,m×n的Toeplitz矩阵后处理,每处理n位原始随机数需要n/k个时钟周期。在其中的第i个时钟周期,FPGA需要完成以下工作:从m+n-1位的种子中选出m+k-1位(从第(i-1)×k+1位到第m+i-1位)构造出一个子矩阵“sub_tpz”;从ADC读入16位原始随机数作为一个子序列“ADC Input”;利用构造出的子矩阵对读入的子序列进行处理,并将得到的处理结果存入寄存器“sum_reg”中。CLK为控制时钟,n/k个时钟周期过后,FPGA完成所有子矩阵与子序列的处理,所得到的n/k个结果(m位向量)被全部保存,然后将所有m位向量按位异或就能得到整个矩阵的计算结果“ans”。
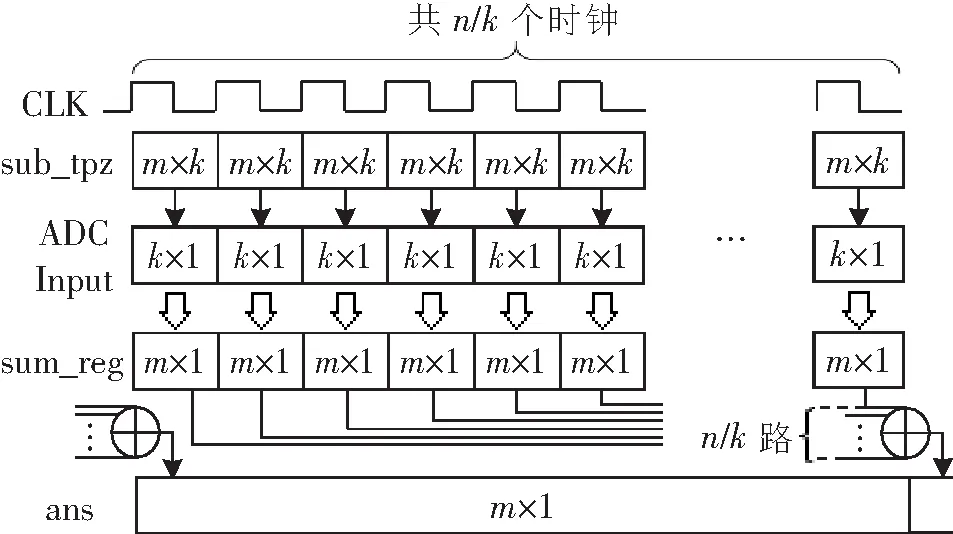
图2 单路后处理中的信号时序设计
图3所示为简化的单个通道子矩阵后处理中的寄存器传输级(Register-Transfer Level, RTL)电路。图中,XOR为异或门;MUX为选通器(Multiplexer),当其S端输入为“1”时,输出端O的值等于I0;当S端输入为“0”时,输出端O的值等于I1。每一个MUX的I0输入端为Toeplitz子矩阵的一列,矩阵元素从种子中选出,I1输入端为0,每一个MUX的S输入端对应ADC输入的一位。总共16个MUX的输出经过4级异或门按位异或以得到子矩阵处理的结果。
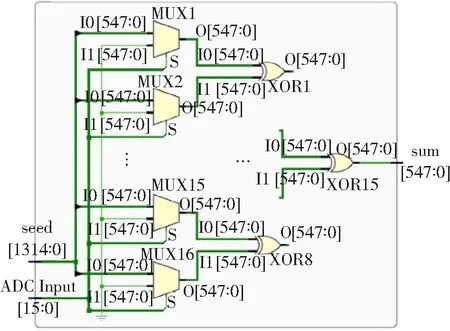
图3 子矩阵后处理的RTL电路
2 实验结果
在ISE中完成了后处理过程的设定后,使用自带的仿真模块对FPGA内部信号进行了行为仿真。如图4所示,本文以其中一个通道的仿真结果为例,图4(a)所示为后处理开始后几个时钟周期内Toeplitz子矩阵的生成情况,该通道子矩阵规模为548×16,sub_tpzj为子矩阵的第j列,该仿真结果可用于判断子矩阵生成逻辑的正确性。图4(b)所示为子矩阵运算的仿真结果。“CLK”为用上升沿控制其他信号变化的时钟信号,其余信号显示每4个比特转化为一位16进制。仿真时使用已采集的随机数代替了ADC的输入“ADC_input1”,每个时钟周期读取16位比特;“sum_reg”为每个Toeplitz子矩阵处理同时钟周期“ADC_input1”所得结果;“ans”为整个548×756的Toeplitz矩阵处理756位输入所得结果,整个矩阵处理一次需要48个时钟周期。由于在一次矩阵计算中需要完成所有子矩阵运算才能得到最终结果,后处理开始后需要运行48个时钟周期才能开始得到结果(“ans”的前48个时钟周期),然而这并不影响后处理的性能和实时性。

图4 ISE软件的仿真结果
理想的随机数序列没有自相关性。对经过多路并行高速实时后处理的随机序列进行了自相关测试,测试时将每个比特作为一个样本,总比特个数为107。测试结果如图5所示,随机数经过后处理后,其自相关系数明显处于较低水平,且维持在10-4~10-7量级,符合高质量真随机数的特征。

图5 经后处理后随机比特的自相关测试
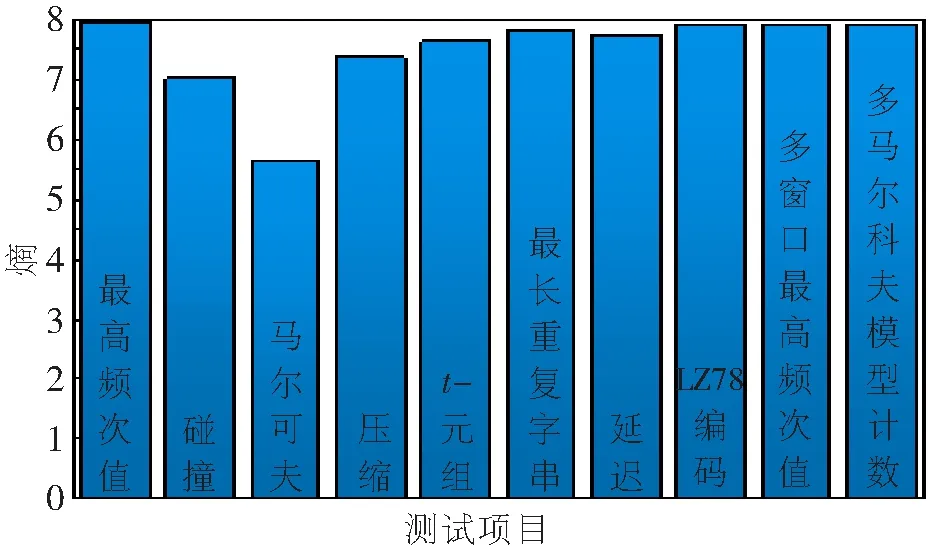
随后本文对后处理产生的随机数进行了Diehard测试。Diehard测试是一个测试随机数生成质量的测试包,其由George Marsaglia发布[17],是目前使用最广泛的随机数测试软件之一。相较于ENT伪随机数测试和美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)数据测试包,Diehard测试是一个更严格的随机性统计测试套件。本文测试时设置显著性水平α=0.01,测试的样本为1 Gbit/s大小随机数bin文件。当Diehard测试的每项测试结果P值满足0.01 图6 实时后处理后对生成量子随机数的Diehard统计测试 此外,熵是随机数发生器的安全性和质量的重要评估标准。NIST的800-90系列建议书[18]给出了在随机数生成过程中10种不同于最小熵评估的熵评估方法,利用该项熵评估标准对本文实验系统的熵源进行进一步评测。将测试包中的非独立同分布(Independent Identically Distribution,IID)测试应用于每一个通道的原始比特串,完成后处理前的熵源评测,3个通道熵值测试结果的平均值如图7所示。本文工作中样本空间的大小为216,根据测试要求,可采用低8位来进行熵值测试,所产生的最小熵取自所有测试项的最小值,即每8位为5.65。表明后处理前的熵源具有较好的随机性,熵源原始的随机性和质量得到了评测和验证。 图7 后处理前对熵源的NIST熵值评估测试 本文实现了QRNG中多通道并行实时后处理,从熵源中提取了3个不重叠的量子边频带模式,并分别分析了各个边带的最小熵。在性能中等的FPGA中设计构建了信息论可证的多通道并行Toeplitz硬件后处理,并充分利用了FPGA的并行处理优势和硬件资源。本文利用NIST 800-90B评估套件测试了后处理前熵源的熵含量,同时分析测试了后处理之后生成量子随机数的自相关性,生成的量子随机数通过了Diehard统计测试。 通过上述量子随机数产生及硬件后处理方法,实现了不同量子边带模式的3组原始随机比特的Toeplitz实时后处理,量子随机数实时生成速率为8.24 Gbit/s。3通道Toeplitz实时后处理占用了约61%的FPGA逻辑资源。这项工作为量子随机数的后处理提供了一种高速安全的方法,在高速量子随机数实时产生中有着重要应用。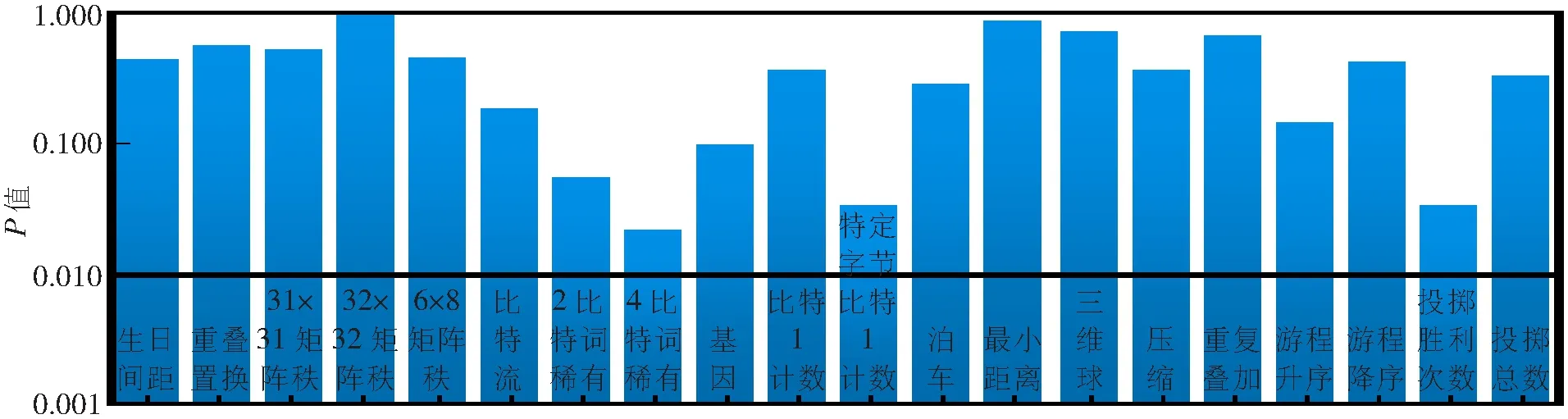
3 结束语
