一类新的灰色耦合模型及其应用
2020-10-28谢丽华
王 安,杨 雨,谢丽华
(1.平顶山学院 数学与统计学院,河南 平顶山 467036;2.平顶山学院 计算机学院,河南 平顶山 467036;3.平顶山学院 化学与环境工程学院,河南 平顶山 467036)
0 引言
对于少样本贫信息的研究对象,GM(1,1)模型表现出优越的预测效果,因此GM(1,1)模型成为学者们研究的热点内容.邓聚龙教授首次建立灰色理论以来,学者们改进模型的结构[1-3],智能方法优化参数[4-5],研究GM(1,1)模型的应用条件[6],以及数据规模对GM(1,1)模型预测效果的影响[7],这些研究都提高了模型的预测精度和拓展了模型的应用范围.这些方法都是从改进模型结构和优化模型参数的角度出发,并没有在充分利用有限的数据方面改进.
GM(1,1)模型是利用最小二乘法原理,求解一阶微分方程,对动态数据的趋势进行预测.为了充分利用有限的数据,范国锋等[8]构建了基于遗传算法的灰色组合模型,王安等[9]设计了基于最小二乘法的灰色预测模型,这些改进方式都是通过整合多种模型的优势,使组合模型的精度和适应范围得到提升.在大数据时代,如何高效地利用有限的数据,设计适应范围更广的数学模型已成为当今研究的重要课题,笔者提出了一种新的灰色耦合模型,该方法是一种解决小样本贫信息的灰色预测模型处理大数据的尝试,通过算例验证了该模型的有效性.
1 模型的建立与检验
1.1 灰色耦合模型
灰色耦合模型是用少量的时间数据序列建立系统的动态模型,先把原始数据序列分解成分解因子,然后对分解因子逐个累加生成生成规律性较强的序列.然后对分解因子累加生成序列建模,再进行累减生成还原成分解因子预测值,最后对分解因子的预测值进行累加,合理地构建分解因子,使得对分解因子的预测值进行累加过程误差得到了相互抵消,使得灰色耦合模型精度得到提高,模型的适应范围更广.具体的灰色耦合模型的建立过程如下:
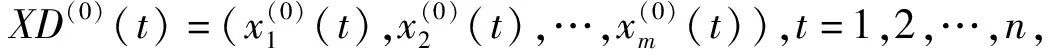

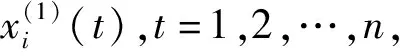
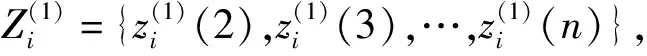

i=1,2,…,m.
(1)
灰色耦合模型NGCM(1,1)的白化形式为:
(2)
其中ai为发展系数,bi为灰色作用量.
则灰色耦合模型可表示为:
Yi=Biui.
(3)
使J(u)=(Yi-Biui)T(Yi-Biui)取得最小值,利用最小二乘法得到参数的估计:
(4)
于是得到白化微分方程的解:
(5)
利用
(6)
得到第i个分解因子预测值序列:
(7)
最后得到灰色耦合模型对原始数据的模拟值和预测值:
(8)
1.2 模型检验
k时段的相对误差,其定义如下[10]:
(9)
平均相对误差定义如下[9]:
(10)
利用平均绝对误差检验模型的准确性,利用平均绝对误差检验模型的模型精度,常用的模型精度等级检验表[11]如表1所示.

表1 模型精度等级检验表
根据灰色耦合模型的原理,灰色耦合模型算法流程图见图1,算法步骤可概括如下:

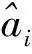

step4计算分解序列的模拟值和预测值,
step5利用灰色耦合模型,计算原始序列的模拟值和预测值,
2 算例分析
根据2019中国统计年鉴中2000—2018年的人口数据(各省的人口数量见表2和表3),利用构建的灰色耦合模型和经典的GM(1,1)模型,得到中国人口预测值与真实值对比图(图2).
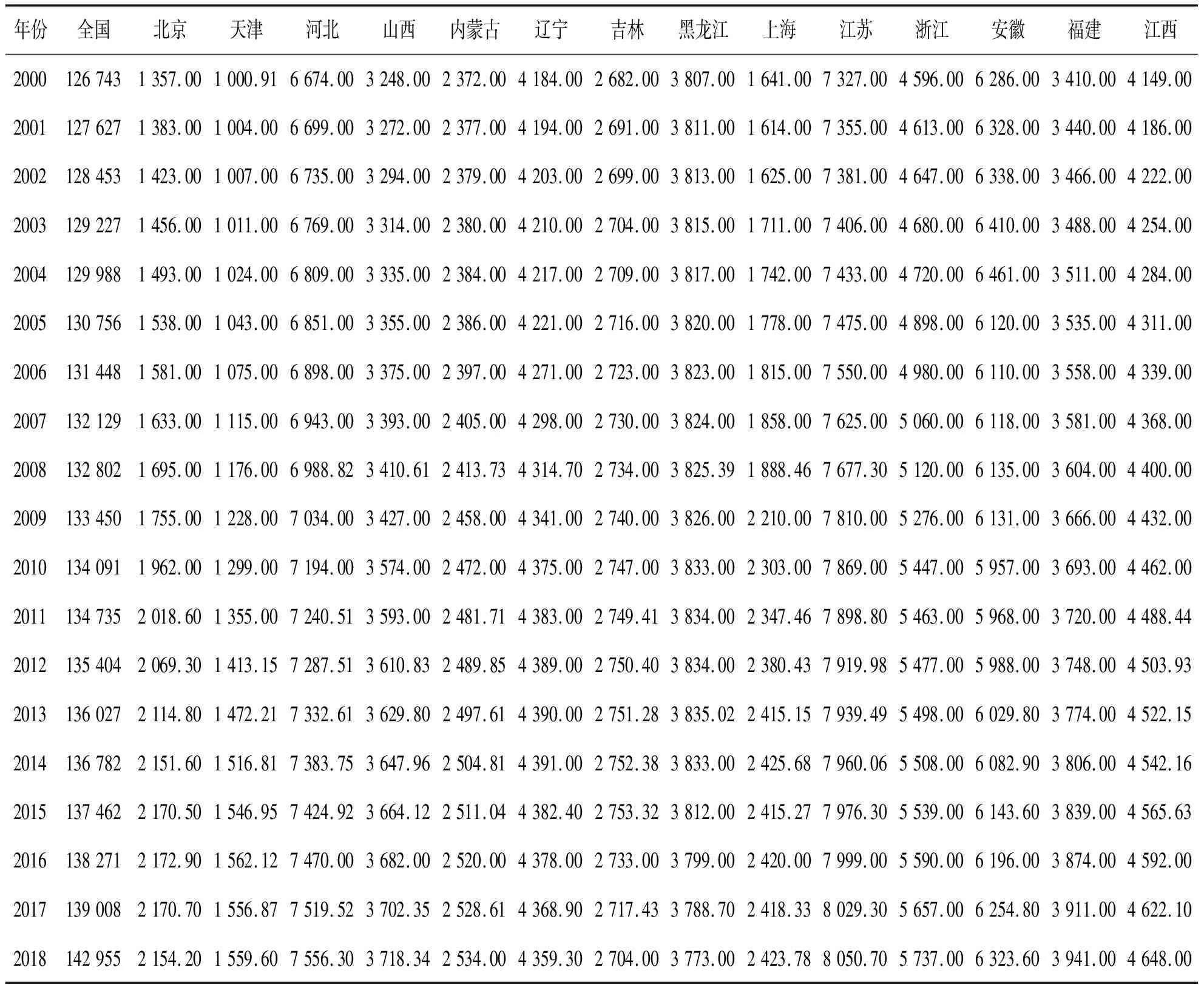
表2 各省的人口数(I) 万
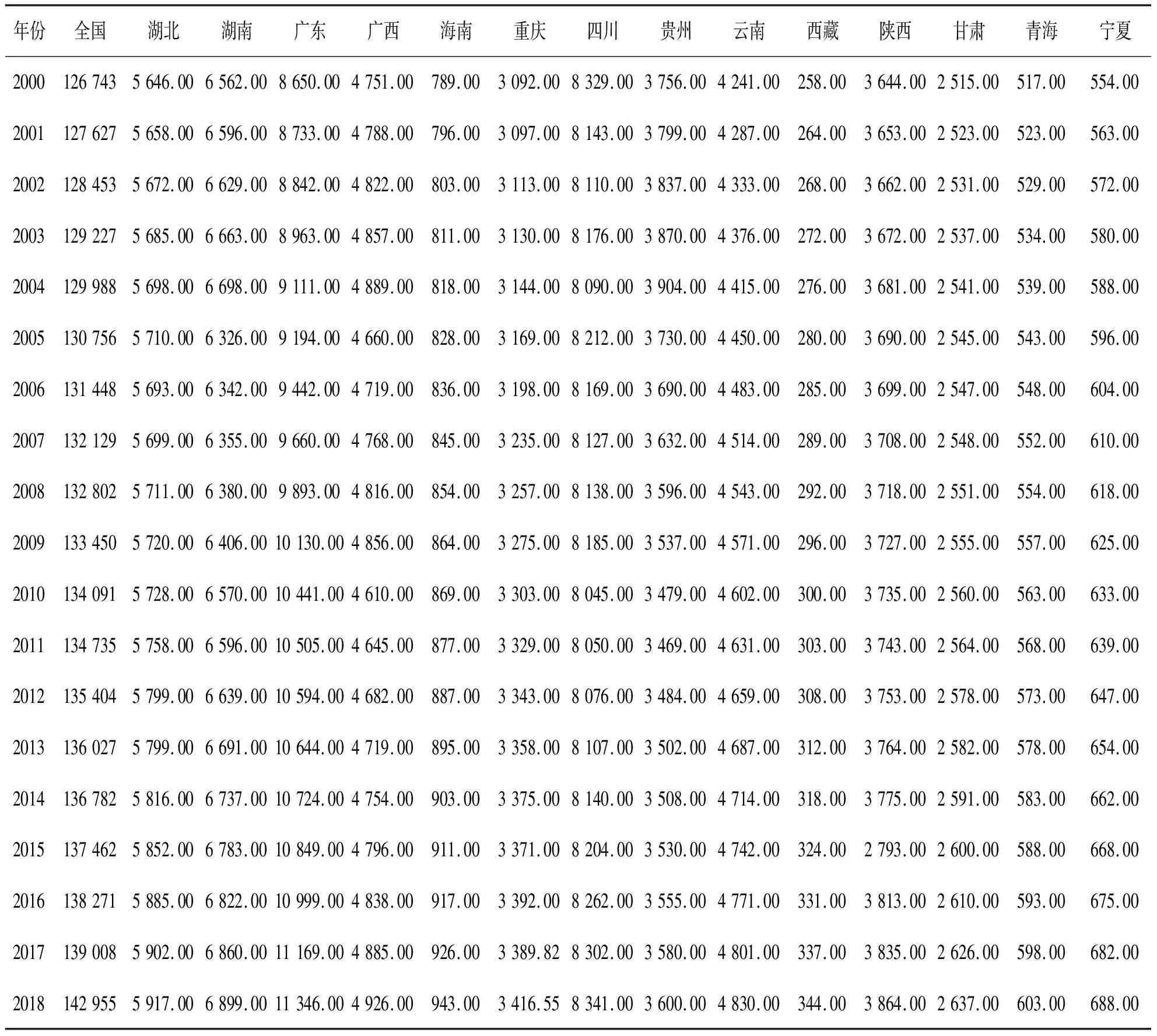
表3 各省的人口数(Ⅱ) 万
对中国总人口按照省和直辖市,利用灰色耦合模型进行预测,结果与GM模型进行对比,由图3和表4可知,灰色耦合模型不仅预测值与真实值更接近,而且相对误差和平均相对误差更小.

表4 误差分析表
由上述计算结果,GM(1,1)模型的平均相对误差为0.276 5%,而灰色耦合模型NGCM(1,1)的平均相对误差为0.261 4%,因此构建的灰色耦合模型NGCM(1,1)是有效的,另外如果能够更好地设计分解因子,精度还可以进一步提升,模型的适应范围更广.
3 结论
构建了灰色耦合模型NGCM(1,1),通过算例发现,相对传统的GM(1,1)模型,灰色耦合模型的预测结果精度更高,模型的适应范围更广.
灰色耦合模型从一个全新的角度出发,对原始数据分解建模,使得整合后的误差相互抵消.笔者仅将中国人口按照地域分解整合,预测精度就得到了明显提升,选择合适的分解因子,模型的预测精度肯定可以进一步提升.因此针对原始数据分解算子的构造,以及分解后的误差相消的比较和耦合效果等问题,值得进一步研究.
