一种基于Python的机器学习情感分析方法研究①
2020-10-26薛涛
薛 涛
(运城师范高等专科学校数计系,山西 运城 044000)
0 引 言
情感分析是自然语言处理(NLP)的关键任务之一,对计算机理解文本具有重要意义[1]。 与图像和音频相比,文本是一种高度抽象的信号,计算机很难对其进行理解和处理。情感分析主要集中在文本的情感表达上,以预测文本所表达的情感积极的(如同意)还是消极的(如不同意、贬义)。在现实生活中,情绪分析可以应用于许多场景,例如分析财务新闻以预测股票市场的动向;分析电影的评价以预测其票房。社交媒体作为一种免费共享的工具,其用户可以表达自己的观点,共享知识并在社交网络上创建内容[2-3]。对社交媒体的文本进行情感分析,量化情感并挖掘分布或规律性,可以从中获得有价值的信息。本文以新浪微博为研究对象,以Python编程语言[4]为基础,探讨基于机器学习技术的中文情感分析方法。
1 情感分析流程
所设计的情感分析方法的主要流程如图1所示。首先,通过网络爬虫从微博网页获得微博文本。将微博的评论作为语料库,将每个评论视为文档。在完成预处理后,将所有经过预处理的文本输入到连续词袋(CBOW)模型[5]中进行词嵌入。接下来,将词嵌入后的向量作为堆叠双向长期短期记忆网络(SBLSTM)的输入。最后,采用softmax分类器从最后一个隐藏层中提取信息,并对标签文本进行情感分析。

图1 情感分析流程
1.1 数据获取与预处理
采用微博提供的API来进行爬虫,从网页抓取评论(部分代码如图2所示)。抓取到的数据为JSON格式(主要字段如图3所示),对其进行解析后就可以得到评论的原文[6]。从JSON文件中获取原始文本后,首先使用Python的PyQuery库对原始文本进行解析以删除原始文本中的html标签,然后对这些文本进行预处理。微博文本通常会包含噪音,如哈希标签、回复符号以及引用符号。因此预处理过程会将数据中的噪音清除,以提高数据质量,从而提高情感分析的准确性。同时,还通过删除与主题无关的评论,以减少不相关的特征。预处理后,使用Python的中文分词库jieba对评论进行分割,并删除停止词。

图2 通过API获取微博部分Python代码
图3 微博JSON格式
1.2 单词与文档表示
词表示模型的基本思想是将单词映射成向量。空间中词向量的距离取决于它们的语义或上下文相似性。采用CBOW模型来进行词嵌入,并将词嵌入到100维的空间中文档表示模型能根据上下文信息捕获文档的特征。首先对网络输入的长度进行归一化:当句子的长度大于K时,会将多余的单词去除;否则,使用零对输入进行补充。然后,通过使用嵌入向量替换评论中的词,得到了顺序词向量。接下来,采用SBLSTM模型学习顺序词向量的特征。最后,提取最后一个隐藏层的值来表示文档。由于模型的输入是词嵌入的向量,最终的文档向量会包含语义信息和上下文信息。
1.3 情感分析
然后,将softmax分类器应用到SBLSTM模型的输出来进行情感分析。使用交叉熵来评估预测值和实际值之间的差异,并为每个评论计算损失值。基于损失值,使用Adam优化器[7]来优化模型的参数。
2 基于SBLSTM的情感分析
介绍基于SBLSTM模型的情感分析。图4展示了用于情感分析的2层堆叠式双向LSTM网络的基本结构。给定N条评论,每条评论都包含了K个单词。令X={X1,...,XN}表示N条评论的集合,令Xi={X1,...,XK}表示评论Xi的单词集合。该模型的目标是预测每个评论的情感Y。对于评论Xi,其情感Yi只能是消极(用(1,0)表示)或者积极(用(0,1)表示)。因此,将输入中客观中立的评论删除。使用SBLSTM模型进行情感分析包括三个步骤:首先对输入进行预处理;然后建立SBLSTM模型,提取上下文特征来表示文档;最后将输出放入softmax分类器中以进行情感分析。

图4 SBLSTM网络的基本结构
首先,为了确保模型可以获得相等大小的输入,需要对评论的长度进行标准化:如果评论的长度大于K(该评论的单词数量超过K个),那么超出的单词会被删除;如果评论的长度小于K,则使用零进行补充,直到其长度达到K。然后,将评论中的每个单词映射为一个D维矢量。如果单词在嵌入模型中没有对应的向量,则将其替换为元素全部为零的D维矢量。
使用两层SBLSTM模型来获取每个评论的文档表示。SBLSTM可以从过去和将来的时间序列中获取丰富的上下文信息,而且SBLSTM具有更多的上层来进行进一步的特征提取。
对于时间序列T,输入序列{x1,...,xT}沿前向{a1,...,aT}进入隐藏层以获得过去的完成信息,并沿反向{c1,...,cT}进行隐藏层以获得将来的完整信息。之后,上层隐藏层将下层隐藏层的输出作为输入,以提取更多特征。具体来说,前向隐藏层的上层是{b1,...,bT}和反向隐藏层的上层为{d1,...,dT}。最后,输出层将两个上层的隐藏向量集成在一起作为它们的输出。图4中的每个隐藏层节点代表一个LSTM单元。LSTM单元的如图5所示。该单元具有一个新的存储器、一个输入门、一个遗忘门和一个输出门。新存储器代表添加新输入后的新候选值,输入门代表存储在单元状态中的新信息,遗忘门意味着从单元状态中转储哪些信息,输出门决定要输出单元状态的哪些部分,控制参数决定信息的存储或丢弃。
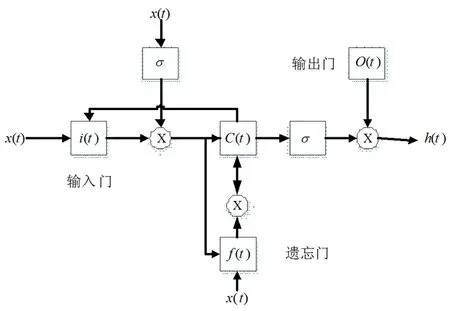
图5 LSTM单元
对于第一个前向传播层,其隐藏状态at由以下的公式决定:
Ca(t)=ia(t)⊙ua(t)+fa(t)⊙Ca(t-1),
a(t)=oa(t)⊙tanh(Ca(t))
(1)
对于隐藏状态b(t)、c(t)和d(t),可以采用类似(1)的方法计算。神经网络最终的输出O(t)是第二个前向传播层和第二个反向传播层的组合,即
O(t)=UOb(t)+WOd(t)+bO
(2)
Softmax分类器将SBLSTM的输出OK作为其输入,预测评论的情感y。预测值y*可以通过以下公式计算:
(3)
然后,使用交叉熵来训练损失函数。损失函数的表达式如下所示:
(4)
使用Adam优化器[7]自适应地调整学习率并优化模型的参数。基于PyTorch开源机器学习平台实现了SBLSTM,主要代码如图6所示。
3 实验评估
实验所采用的数据集由30,000条微博评论构成,其中15,140条微博评论被标注为积极评论,14,860条微博被标注为消极评论。从中随机选择75%的数据作为训练数据集,剩余25%的数据作为测试数据。
图6 基于Python实现的SBLSTM主要代码
实验使用100维的单词嵌入向量作为所有模型的输入,最大句子长度设置为13个单词。使用截断正态分布(均值为0、方差为1)对网络权重进行初始化。在SBLSTM网络中,每一层隐藏层拥有64个节点,每次输入到神经网络的数据大小为300。
选择精度、召回率和F-度量作为性能评估的指标,其计算方式分别如下所示:
(5)
(6)
(7)
其中,Pre是指精度,Rec是指召回率,F是F-度量。TP是指被预测为正样本,实际上也是正样本的数量;FP是指被预测为正样本,实际上是负样本的数量,FN是指被预测为负样本,实际上是正样本的数量。
选择SVM、CNN和LSTM网络作为对比对象,对比结果如表1所示。本文设计的SBLSTM模型具有较高的预测精度。其中,深度学习模型(即CNN、LSTM和SBLSTM)的性能要好于传统机器学习方法(即SVM)。与LSTM相比,SBLSTM拥有更多的隐藏层,具有更好的特征表示能力,因此能获得更好的性能表现。
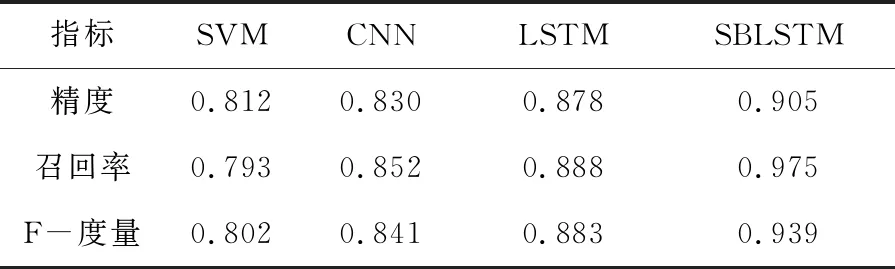
表1 实验结果
4 结 论
采用机器学习技术,以Python高级编程语言为基础,设计了一种情感分析方法。该方法使用CBOW来表示单词的语义特征,利用SBLSTM神经网络模型从顺序的单词嵌入向量中提取上下文特征。实验结果表明,该方法比现有的常用模型具有更好的性能。未来的研究工作将采用注意力机制来进一步提高方法的学习能力,并设计更高效的预处理方法来提高输入数据集的质量。
