基于敏感特征选取与改进NPE的滚动轴承故障诊断方法
2020-10-21田媛媛黄雅玲丁恩杰
田媛媛,黄雅玲,董 飞,丁恩杰
(1.中国矿业大学信息与控制工程学院,江苏 徐州 221008;2.中国矿业大学物联网(感知矿山)研究中心,江苏 徐州 221008)
1 引言
滚动轴承作为旋转机械的关键部件之一,其工作状态会直接影响到整个旋转机械的运行状态,研究滚动轴承智能故障诊断技术对于保障设备安全稳定运行,减少突发事故的发生以及减少设备维护成本,具有重要的经济和现实意义与工程价值[1]。近年来,随着信号处理、数据挖掘以及人工智能的快速发展,基于数据驱动的方法在滚动轴承故障诊断中变得越来越重要,其主要可分为四个步骤:信号处理,特征提取,特征降维和故障模式识别[2-4]。
滚动轴承振动信号能够及时准确的提供设备状态特征信息,且可被永久或间歇监测,因此被广泛用于滚动轴承故障诊断[2]。小波变换是分析非线性、非平稳振动信号的有效方法,但小波变换没有对信号的高频部分做进一步的分解,易导致高频部分故障特征信息的丢失。针对此问题,小波包变换被提出,它能进一步分解信号在高频区的细节系数,提供更详细、更全面的时频面,因此在滚动轴承故障诊断方面得到许多应用[2,5,6]。振动信号经小波包分解后,进行特征提取,构建原始特征集,其中会存在干扰以及冗余信息,可能会影响故障诊断的准确度,因此,需要从原始特征集中提取出有利于故障状态识别的敏感特征;提出一种基于ReliefF与标准差的故障敏感特征选择方法(Features Selection Based on ReliefF and Standard Deviation,FSRSD),实现对原始特征集中各统计特征故障敏感度的量化分析,选取故障敏感度高的统计特征用于故障模式识别。
对于高维特征集,需进行降维,得到判别性能更好的低维特征集,从而更有利于故障模式识别与分类。领域保持嵌入(Neighborhood Preserving Embedding,NPE)是一种无监督的线性降维方法,其主要目标是保持数据流形中的局部结构。LDA 作为一种经典的线性降维方法,其将故障的类别信息考虑到特征降维过程中。文献[8]对LDA 中的类间散度矩阵和类内散度矩阵表达式进行了改写,并在此基础上提出了改进的LDA 方法,局部Fisher判别分析(Local Fisher Discriminant Analysis,LFDA)。LFDA 在降维过程中,既能够保持数据的局部流形结构,同时还考虑了样本数据的标签信息,从而使得降维后的数据更有利于分类[8]。因此,可以结合NPE 与LFDA 各自的优点,提出一种改进NPE 的特征降维方法(Modified Neighborhood Preserving Embedding,MNPE),以此来提高低维特征集的判别性能,提高故障诊断的准确率。在故障模式识别方面,采用支持向量机(Support Vector Machine,SVM)作为故障模式识别分类器。SVM 是一种比较优秀的模式识别方法,具有良好的泛化能力,非常适合解决小样本与高维非线性模式识别问题[9],在滚动轴承故障诊断领域也取得了广泛的应用。
首先利用WPT 分解振动信号,对得到的终端节点进行单支重构,得到不同频率范围的重构信号,计算重构信号及其希尔伯特包络谱的统计参数,构成原始特征集。然后利用FSRSD 方法进行故障敏感特征选取,对于高维特征集,利用提出的MNPE 进行降维,将得到的低维特征集作为SVM 的输入,构建故障诊断模型,进行故障模式识别。最后,利用美国凯斯西储大学轴承故障数据对所提出方法的有效性与适应性进行实验验证,实验结果表明,所提出方法能够提升故障诊断准确率,并且具有良好的适应性。
2 基于ReliefF 与标准差的故障敏感特征选取
2.1 ReliefF 算法
ReliefF 算法是目前广受好评的特征有效性评估方法[10],很多研究者将ReliefF 算法应用在降低特征集冗余度,从中选取出更利于分类的特征[10-11]。ReliefF 算法主要根据特征在同类样本中以及相近的不同类样本中的区分能力来评价特征与类别的相关度,并对特征进行加权[11]。算法输出各特征的权重值向量,权重值越大,则特征与类别的相关程度越高,分类能力强;权重值越小,则特征与类别的相关程度越低,分类能力弱[11]。假设共有X 个特征,ReliefF 算法的输入为训练样本集D,输出为特征权重向量W。
2.2 故障敏感特征选取
假设在共有M 种故障类型的样本数据集中,每种故障类型有N 个样本,每个样本有K 种统计特征。故障敏感特征选取的目标是从K 种统计特征中选取对故障状态敏感度高的特征构建敏感特征集,用于故障模式识别。在本节中,从两个角度对统计特征的故障敏感度进行评价,即特征与类别的相关程度和特征的类别聚合度。利用ReliefF 算法评价统计特征与类别的相关程度,得到特征的权重值(Weight Value,WV),权重值越大,代表特征与类别的相关度越高,越有利于分类。利用每种统计特征在各种轴承状态下样本数据的标准差(Standard Deviation,STD)来描述特征的类内聚合度,标准差越小,则说明数据集的离散程度低,数据就越集中,说明该统计特征的类内聚合度越好。最后,提出一种基于ReliefF 与标准差的故障敏感特征选择方法(FSRSD),利用WV与STD 的比值表征统计特征对故障状态的敏感度,选取故障敏感度高的统计特征用于故障模式识别。FSRSD 的具体步骤描述如下:
(1)经信号处理和特征参数计算,可以得到原始特征集[FS1,FS2,…,FSK],其中FSk如下所示:

(2)利用ReliefF 算法评价每个统计特征,得到对应的特征权重值,可以构成特征权重值序列SWV={WV(1),WV(2),…,WV(K)}。计算各统计特征样本在M 种轴承故障类型下的标准差,得到每个统计特征在各轴承故障类型下的标准差序列:

(3)构建统计特征对轴承故障敏感度的评价指标WSDR,并得到K 个统计特征的WSDR 值,构成序列WSDR={WSDR(1),WSDR(2),L,WSDR(K)},WSDR 的定义是WV 与SSTD 的比值。WSDR(k)的表达式如下:

当WSDR 值越大时,对应的统计特征一方面其与类别的相关度越高,越有利于分类;另一方面其样本数据的离散程度低,数据集中,说明该统计特征的类内聚合度好。所以,WSDR 值越大,说明该特征对于轴承故障敏感度越高,有利于进行故障模式识别。
3 改进NPE 的特征降维方法
本节提出了一种改进NPE 的特征降维方法MNPE,该方法的目标是保持数据局部几何结构不变的同时,融合LFDA 的优化目标,构建出一个新的优化目标函数,使得在降维过程中充分考虑样本类别信息,提升降维后低维特征集的判别性能,更有利于故障模式识别与分类。
令训练样本为X={x1,x2,…,xn},其中xi∈Rm,n 训练样本的个数,m 为训练样本的维数。每个样本对应的类别为label(xi)∈C,其中C={c1,c2,…,cn}表示类别集合。寻找一个映射矩阵A={a1,a2,…,an},其中ai∈Rm,d 为将训练样本进行映射之后的维度,将Rm空间的数据映射到一个相对维度较低的特征空间Rd(d<m)中。数据点xi在Rd中的表示为yi,且yi=ATxi。
MNPE 的第一个优化目标是保持数据的局部流形结构,其使用k 最近邻方法在数据样本上构造一张近邻图G,构造近邻图时采用的方法与局部线性嵌入(Locally Linear Embedding,LLE)相同[12-13]。在NPE 中,假定每个局部近邻都是线性的,因此每个数据点xi都可以通过它的近邻点实现线性重构,其优化目标函数为:

式中:Wi,j—近邻图重构权重系数矩阵W 中元素。
MNPE 的第二个优化目标是最大化类间散度和最小化类内散度,同时考虑同类样本间近邻关系,来获得判别性较强的低维空间。类间散度矩阵Sb和类内散度矩阵SW定义如下:
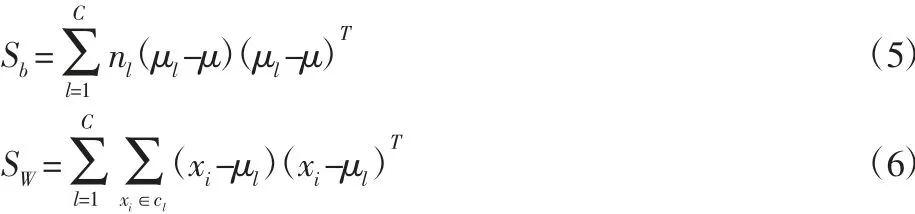
式中:cl—第l 类样本集合;μl—第l 类样本均值;μ—所有样本均值。类间散度矩阵Sb和类内散度矩阵SW的等价形式如下[8]:
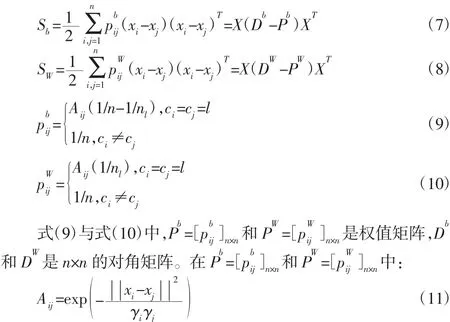

基于MNPE 的两个优化目标,将利用式(4)来保持样本原有的局部几何结构,利用式(12)和式(13)实现在考虑同类样本间近邻关系下最大化类间散度和最小化类内散度,从而提升低维样本的判别性能。MNPE 的优化目标函数如下:
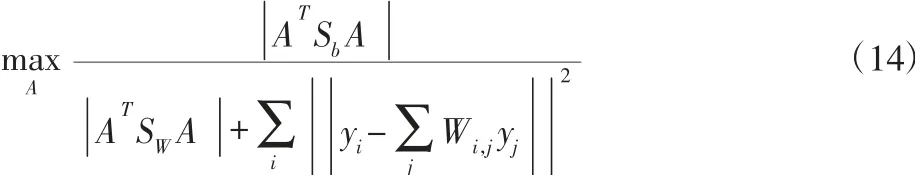
对于此优化问题,结合式(7)和式(8),式(14)可改写成迹比优化形式:
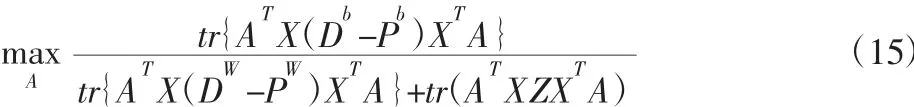
其中,Z=(I-W)T(I-W),I=diag(1,…,1)。最终,MNEP 的优化目标函数可转化为下面的广义特征值求解问题:

4 系统框架
所提出的故障诊断方法系统结构,如图1 所示。整个故障诊断过程有两个阶段,每个阶段有四个步骤:信号处理,特征提取,特征降维和故障模式识别。对于训练阶段,第一步中,用于训练的原始振动信号经WPT 处理,得到终端节点的单支重构信号并计算包络谱,计算重构信号及其包络谱的统计参数,构建原始特征集;第二步中,将原始特征集经故障敏感特征选取方法FSRSD 处理,实现对各统计特征故障敏感度的量化分析,选取故障敏感度高的统计特征用于故障模式识别。第三步中,对于高维特征集,利用MNPE 对其进行降维,得到降维映射矩阵与低维特征集。第四步中,将从训练样本中得到的低维特征集作为故障模式识别分类器的输入,训练故障诊断模型。对于测试阶段,第一步中将用于测试的原始振动信号经WPT 处理,得到终端节点的单支重构信号并计算包络谱,计算重构信号及其包络谱的统计参数,构建原始特征集;第二步中,利用训练阶段得到的敏感特征排序WSDR 直接进行故障敏感特征选取。第三步中,利用训练阶段得到的降维映射矩阵直接进行降维。第四步则采用由训练阶段得到的故障诊断模型进行故障诊断。
5 实验结果分析
5.1 实验设置与案例
使用美国凯斯西储大学(Case Western Reserve University,CWRU)的轴承振动数据,试验台,如图2 所示。利用安装在电机的驱动端和风扇端上侧的加速度传感器进行振动信号采集,信号的采样频率为12kHz。该试验台采用电火花方式在轴承内圈、外圈及滚动体上引入单点缺陷,缺陷的尺寸有0.007 英寸、0.014 英寸、0.021 英寸和0.028 英寸。CWRU 轴承数据中包含在(0~3)hp电机负载下(对应负载下的电机转速为(1790~1730)tr/min)的振动数据。实验使用的振动数据集,如表1 所示。
表1 中滚动体和内圈分别有4 种故障尺寸,外圈有3 种故障尺寸,定义了包含正常情况在内的12 种故障模式。从每种故障模式中提取60 个振动信号样本,训练集包含20 个信号样本,测试集包含40 个信号样本,训练集与测试集中的信号样本均为随机选取,其中每个信号样本由2000 个连续的振动信号采样数据点构成。由于滚动轴承在实际工作环境中,其负载是变化的,处于变工况状态。因此为了验证提出故障诊断算法在变工况状态下的有效性和适应性,设计了两个验证案例。其中,案例1 和案例2 是一组对比实验,其使用相同电机负载(3hp)下的样本作为训练集,使用不同电机负载下的样本作为测试集,案例1 使用3hp 的样本为测试集,案例2 使用2hp 的样本为测试集。
5.2 结果分析
利用WPT 对美国凯斯西储大学轴承振动数据进行处理,在这里的实验中,选用“db5”小波,分解层数为4 层,利用该16 个单支重构信号和相应的16 个Hilbert 包络谱,计算表2 所示的6 种统计参数,可以得到相应的192 个统计特征,构成原始特征集(Original Features Set,OFS)。
利用FSRSD 方法对OFS 进行处理,得到各统计特征的WSDR 值,如图3 所示。利用WSDR 值来量化统计特征对不同故障状态的敏感度,对于故障敏感特征的选取可根据图3 中的WSDR 的降序排列依次选出对应的统计特征,构成特征子集,用于后续的故障识别。
基于SVM 构建滚动轴承故障模式识别模型,利用训练集样本训练模型,利用已训练模型对测试集样本进行故障诊断。这里为验证所提出方法的有效性与适应性,构建OFS-SVM 模型与OFS-FSRSD-SVM 模型对敏感特征选取方法的有效性进行验证,OFS-SVM 模型是将原始特征集直接作为SVM 的输入,进行故障模式识别与分类,OFS-FSRSD-SVM 是将原始特征集经FSRSD处理后得到的敏感特征作为SVM 的输入。在其基础上,为验证所提出降维方法的有效性,将经FSRSD 处理后得到的敏感特征子集经不同降维方法(PCA,LFDA,NPE 与MNPE)处理后输入到SVM 进行故障模式识别与分类,因此又构建了OFS-FSNB-PCASVM、OFS-FSNB-LFDA-SVM、OFS- FSNB-NPE-SVM 和OFSFSNB-SNPEL-SVM 四种故障诊断模型开展实验分析。
OFS-SVM 模型的故障诊断结果,如表3 所示。根据结果可知,模型对Case 1 的故障诊断准确率明显高于对Case 2 的故障诊断准确率。各故障诊断模型对两个测试案例(Case 1 与Case 2)的故障诊断准确率的对比情况,如图4 所示。图中横轴表示所选取的敏感特征数(sensitive feature number,sfn),纵轴是故障诊断准确率。故障诊断模型中PCA 的降维大小为20,LFDA 的降维大小为11,NPE 与MNPE 的降维大小均为30。根据图4 所示可知,对于Case 1,所有模型的最大故障诊断准确率均能够达到99%以上,高于OFS-SVM 模型的98.54%准确率。对于Case 2,所有模型的最大故障诊断准确率均能达到85%以上,大于OFS-SVM 的83.54%。其中OFS-FSRSD-LFDA-SVM 与OFS-FSRSD-MNPE -SVM 模型的性能最好,在合适的sfn 范围内,最大故障诊断准确率分别能够达到99.58%与100%。从故障诊断准确率的峰值与平稳性来看,OFS-FSRSD-MNPE -SVM 模型均优于其他模型。
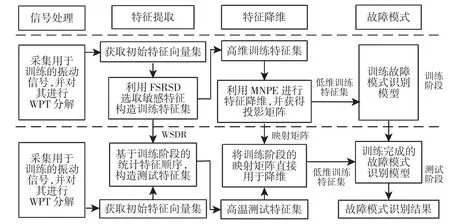
图1 故障诊断方法系统结构示意图Fig.1 System Structure of the Fault Diagnosis Method

图2 轴承故障实验平台Fig.2 Bearing Fault Experimental Test Rig
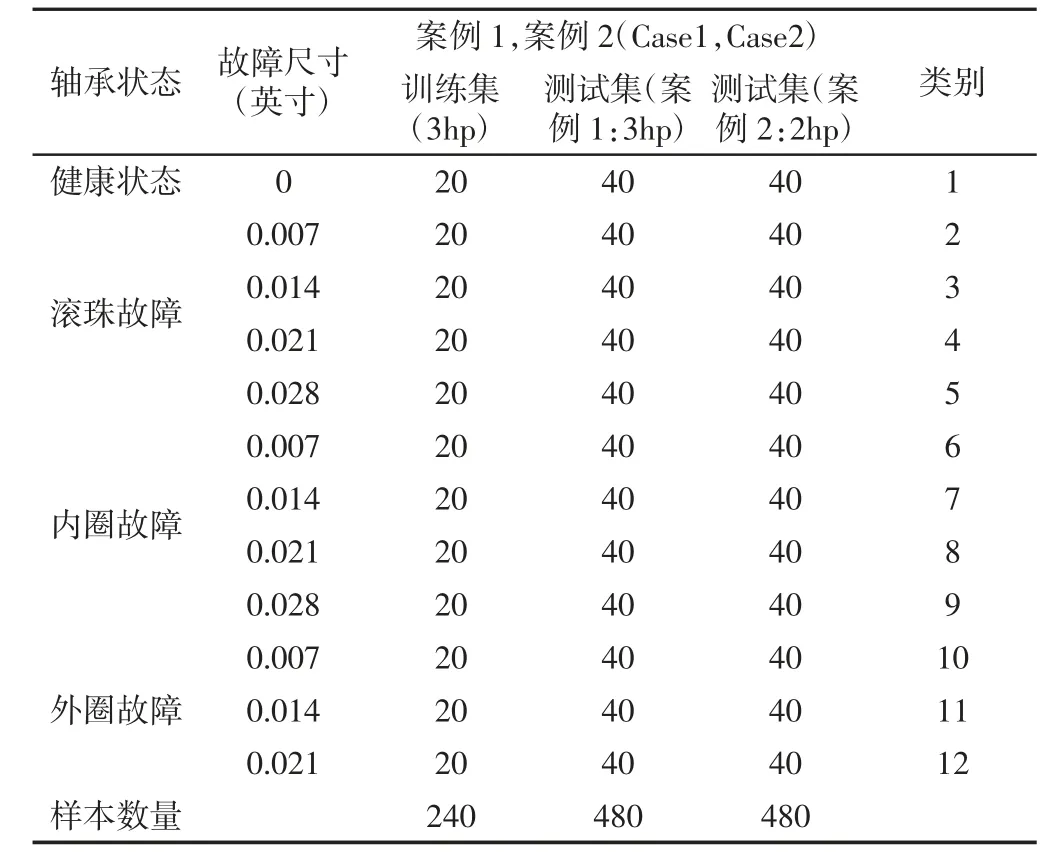
表1 实验中使用的振动数据集Tab.1 The Used Vibration Dataset in Experiments
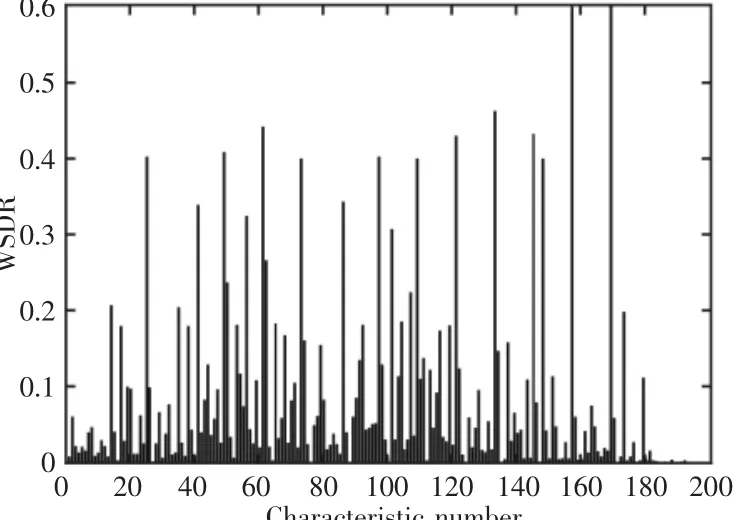
图3 样本统计特征的WSDRFig.3 WSDR of Statistical Features of Samples

表2 统计参数Tab.2 Statistical Parameters

表3 OFS-SVM 模型的轴承故障诊断结果Tab.3 Bearing Fault Diagnosis Results Obtained by OFS-SVM
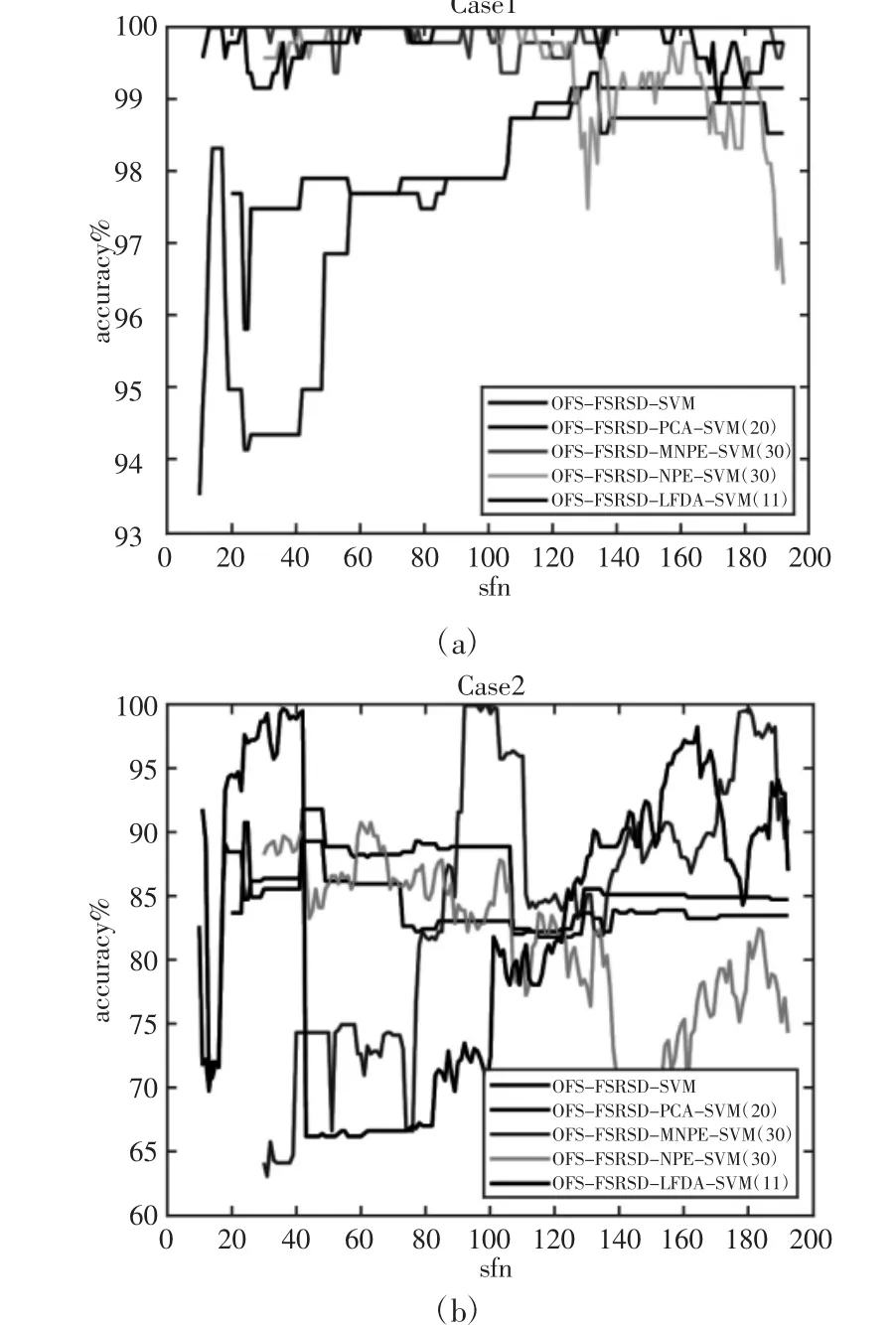
图4 五种故障诊断模型的实验结果Fig.4 Experimental Results of Five Fault Diagnosis Models
6 结论
在对WPT、ReliefF 以及NPE 的研究基础上,提出一种基于ReliefF 与标准差的故障敏感特征选择方法和改进邻域保持嵌入的特征降维方法。为验证所提出方法的有效性与适应性,建立OFS-FSRSD- MNPE-SVM 故障诊断模型,同时还设置其他四种故障诊断模型进行对比(OFS-SVM,OFS-FSRSD-PCA- SVM,OFS-FSRSD-LFDA-SVM 和OFS-FSRSD-NPE- SVM),通过测试案例Case 1 与Case 2 的实验分析,结果表明:(1)提出的FSRSD方法,能够对原始统计特征集中各特征的故障状态敏感度进行量化分析,选取出敏感度高的统计特征用于故障模式识别,在选取合适的敏感特征数sfn 时,可以有效提高故障诊断准确率。(2)提出的MNPE 方法,可以实现在降维过程中,既保持数据的局部流形结构,也能在考虑同类别样本间近邻关系下最大化类间散度与最小化类内散度,从而使同类样本靠近,异类样本远离,提高了低维特征集的判别性能,从而更有利于故障模式识别与分类,提高了故障诊断准确率。(3)建立的OFS-FSNB-MNPE-SVM 故障诊断模型,在选择合适故障敏感特征数量时,对于两个测试案例,均可以取得理想的故障诊断结果,尤其对于变工况下(Case 2)的故障诊断,该模型在诊断准确率的峰值与平稳性上,均优于其他模型。综合实验结果分析,所提出的故障敏感特征选取方法与特征降维方法能够提升故障诊断模型的性能,对于变工况下的故障诊断具有良好的适应性。
