改进EAST算法的游戏场景文本检测
2020-10-20赵逢禹
池 凯,赵逢禹
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
视频游戏中蕴含着丰富的文本信息,而这些文本信息往往渗透着对游戏制作及全局规划的理解;因此从游戏场景中提取所包含的文本信息,对视频游戏的分析与处理都具有重要的意义.
然而游戏场景中图像变换速率较快,且具有复杂的背景和多样的特殊字符;相较于自然场景,游戏场景的色彩和光影效果较强,部分场景物体具有虚化现象,容易产生视觉深度;与此同时,游戏场景中长文本较多且文本之间具有联系性,对检测算法的感受野要求较高;这一系列的特殊性质给游戏场景文本的检测造成了较大的困难,使得从游戏场景中提取文本信息具有一定挑战性.目前众多学者在场景文本检测方面做了大量的研究并取得了相应的进展.尹芳等人利用迭代算法(Adaboost)将场景中文本定位问题转化为二分类问题[1],将多个弱分类器组合成一个强分类器,实现了对场景中文本的定位检测;王梦迪等人提出了一种基于多方向边缘检测和自适应特征融合的自然场景文本定位方法,利用三通道八方向的边缘检测通道提取出备选文本域进行特征提取与融合从而定位文本[2];Xiang Bai等人提出由粗到精的方法对自然场景中文本进行检测,使用全卷积的神经网络来训练和预测不同方向的语言和字体,将局部信息和全局信息结合起来[3];而Zhou X等人提出的EAST[4]文本检测算法在全卷积网络的基础上采用了端到端的文本定位方法,使用单个轻量级的神经网络直接对整个图片进行高效快速地预测,消除了复杂步骤;并且EAST算法允许端到端的训练和优化,优化了中间组件也省去了复杂步骤,其中高效的算法和精简的网络结构提高了检测精度与效率.
在上述研究中为了达到较高水准的文本检测水平,采用了复杂文本检测通道与文本提取算法,导致文本定位速率较慢、检测效果不佳.经典的EAST文本检测算法由于网络结构的限制导致文本感受野较小,存在对长文本以及复杂背景文本检测不佳的问题.因此本文针对游戏场景的文本定位识别问题选取EAST 作为基础文本检测算法,对EAST算法网络结构提出了相应的改进,加强了特征筛选并且在网络结构中加入了BLSTM层,使得EAST文本感受野长增加;同时针对shrink_poly(收缩文本框策略)提出比例权重更改,从而改善了EAST的文本检测效果,提高了算法性能.
2 EAST文本检测算法
EAST检测算法采用二阶段(two-stage)文本检测的方法并基于全卷积网络(FCN)直接对文本内容进行检测,该算法检测通道结合了密集检测框(DenseBox)和分割网络(Unet)中的特性,利用单个神经网络进行文本特征提取,并从整幅图片中预测任意方向的四边形文本行[4].
2.1 网络结构
EAST神经网络层采用U-shape的思想逐步合并特征图,并且每层网络保持对上层的较少采样;既利用不同级别的特征值,又节约了一定的计算成本,减少了网络层中参数的数量[4].EAST整体网络结构分为3个部分,如图1所示,分别为特征提取层,特征融合层以及输出层.

图1 EAST网络层的结构Fig.1 Structure of the EAST network layer
特征提取层:采用VGG16模型中pooling-2 - pooling-5阶段作为特征提取阶段的基础网络结构模型[4];首先输入一张图片,然后经过四个阶段的卷积层处理,并分别从四个阶段(stage1,stage2,stage3,stage4)得到f4、f3、f2、f1,每个特征图大小分别为输入图像的1/32,1/16,1/8和1/4.
特征融合层:采取逐层合并的方式从后往前做上采样,将第一步抽出的特征图输入到池化层(unpooling)进行扩展,再使用连接函数(concact)对上下层特征图(记为hi)进行连接;并通过卷积运算(conv1×1 bottleneck)减少通道数量和计算量,最后将得到的h4特征图通过三层卷积核运算(conv3×3)生成最终的特征图.
输出层:输出得分图(score map)和4个旋转文本框(RBOX)以及文本框角度信息,表示从像素位置到矩形的顶部,右侧,底部,左侧边界的4个距离值;或者输出得分图和四边形(QUAD)中8个文本坐标信息,分别表示从矩形的四个顶点到像素位置的坐标偏移.
2.2 损失函数
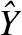
L=LS+λgLg
(1)
(2)
Lg=LAABB+λθLθ
(3)
(4)
Lθ(θa,θb)=1-cos (θa-θb)
(5)
在LS与Lg的计算中,以平衡交叉熵函数(cross_entrop)作为 score map损失函数来解决样本不平衡分布的问题,既避免了复杂参数也对目标数据进行了分布处理,提高了网络性能.通过交叉熵函数尽可能地使模型输出的分布与训练样本的分布一致;交叉熵(cross_entrop)主要呈现出的是实际输出(概率)与期望输出(概率)的差距,两个概率分布越接近则交叉熵的值就越小.假设H(p,q)为交叉熵,p为期望输出概率分布,实际模型输出概率分布为q,则:
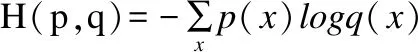
(6)
3 改进EAST检测算法
3.1 网络结构优化
EAST原始网络模型为了扩大输出单元的感受野在池化层阶段采用了大量计算复杂度较小的下采样,然而较多池化层提取使得特征样本尺寸减少,使得上采样阶段回复分辨率的难度增加,导致部分输出特征映射感受野较小,不能编码更多尺度信息;因而存在实际检测中长段落边缘检测效果略差的问题.因此本文针对EAST段落边界检测不佳的问题,简化卷积层结构并扩大了卷积核通道数从而加强了对特征值的提取筛选,在特征融合的基础上加强了对特征样本的序列化处理,在EAST原先网络模型中加入BLSTM[5](Bi-directional Long Short-Term Memory)神经网络层,改进过的网络结构如图2所示.
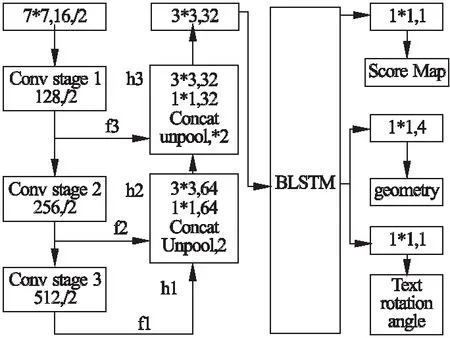
图2 改进EAST网络层的结构Fig.2 Improved structure of the EAST network layer
EAST在基于VGG16的基础上提取了四个级别的特征图,分别为输入图像的1/32,1/16,1/8,1/4;考虑到原先网络感受野较小的问题以及游戏场景的特殊性(无旋转字体以及较小文本),在本文中修只改为提取三个阶段的特征图,在保持参数数量的基础上增加卷积核的通道数从而大量有效地筛选的更多特征,使得特征层输出更大尺度的有效感受野.
本文加入的BLSTM是一种特殊的循环长短期记忆神经网络,由双向LSTM[6]神经网络组成;BLSTM具有学习长期依赖的能力,能将每个特征的前后序列呈现为两个单独的隐藏状态,以分别捕获序列过去和未来的信息,然后再将两个隐藏的特征序列连接起来形成一个新的特征样本进行最终输出[7](如图3所示).本文将经过特征融合所得到的序列样本(feature map)放入BLSTM中进行循环特征连接,使得到新的序列样本更加合理均匀且具有联系性;然后再经过1*1的卷积输出ROI(region of interest-proposal)所对应的score map和相应的几何信息.
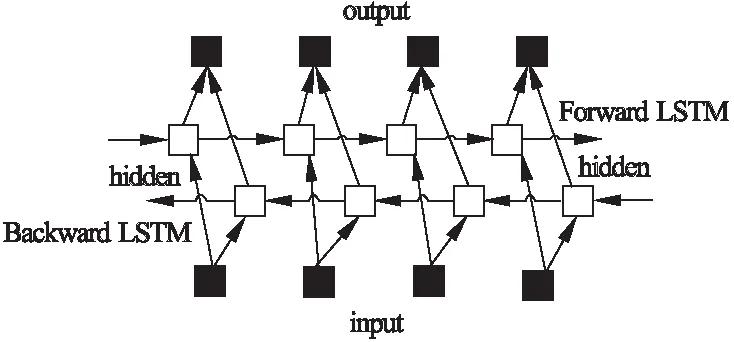
图3 BLSTM网络传输结构Fig.3 BLSTM network transmission structure
3.2 shrink_poly(收缩矩阵)改进
EAST在制作预测四边形文本框(polygon)时采用了收缩矩阵(shrink_poly)的策略,而收缩矩阵在一定程度上能够减少人工标注带来的误差.
ri=min(D(pi,p(imod4)+1),D(pi,p((i+2)mod4)+1
其中pi表示4个顶点,ri表示矩形4条边的长度,i=0,1,2,3;并直接计算出矩形相邻两点之间的L2距离,取其中较小的一个.实际计算矩形边长时,通过求取向量范数计算相邻两点距离(L2 norm).
考虑到使得收缩更加优化,在计算过程中尝试增加对于特殊边长的权重收缩,并赋予相应的数值权重.其中对于较短的矩形边可以取正常固定值的距离收缩(shrink);而对于较长的矩形边则要采取减少收缩的策略.当矩形长边和短边在相同倍数收缩时会导致训练完成后的四边形矩形框整体收缩过度,出现长边边界预测不准的情况,导致边界效果检测较差.这里对于矩形长边尝试采取0.1倍固定值的收缩,从而改善边界的检测效果,如算法1所示.
算法 1.shrink_poly 策略改进
输入:Four vertices p1 p2 p3 p4
输出:Shrunk vector
1.functionshrink_poly(p1,p2,p3,p4)
2.if np.l.n((p1-p2)+(p2-p3))>np.l.n((p1-p4)+(p2-p3)))
3. np.arctan2((p1,p2),(p3,p4))
4. [ p1,p2]←0.1shrink
5. [ p3,p4]←0.1shrink
6. np.arctan2((p1,p4),(p2,p3))
7. [ p1,p4]←0.3shrink
8. [ p2,p3]←0.3shrink
9. return shrink_poly
10.Else np.arctan2((p1,p2),(p3,p4))
11. [ p1,p4]←0.1shrink
12. [ p2,p3]←0.1shrink
13. np.arctan2((p1,p4),(p2,p3))
14. [ p1,p2]←0.3shrink
15. [ p3,p4]←0.3shrink
16. return shrink_poly
17.End if
18.end function
4 实验及分析
为了更好地验证本次算法的性能,并对实验数据有较好地分析,本次实验平台选择为Matlab 2012b,PyCharm,计算机配置为windows与Linux双系统,处理器Intel corei7,主频3.10GHz,内存16GB,显卡为GTX1070.
4.1 实验步骤
本次实验主要分为两个个步骤:构建图像数据集、文本定位训练与验证,流程如图4所示.

图4 模型训练与验证实验流程图Fig.4 Model training and verification experiment flowchart
4.2 构建图像数据集
本次实验首先从游戏视频中通过人工逐帧截取的方式获取大量场景图像[8],由于游戏场景中的文本信息较少,不利于制作游戏场景训练集,因此需要对游戏场景进行人工填充数据,而人工合成数据可以准确知道文本的标签(label)信息,省去了人工标注数据的时间;采用VGG提出的Synthetic Data[9]技术将数据自然排列进游戏场景空白处,从而快速生成大量符合有利于实验要求的标签化数据,制作出游戏场景专属的训练集.
游戏场景(pubg)中的大部分文本是集中在区域内出现的,因此要把背景图像分割成连续的区域,再将要填入的游戏文本字体嵌入其中相应区域.当放入文本的位置、方向确定后,再对文本赋予一些相应的颜色.Synthetic Data会把文字和背景图像的像素分为两个集合,其中一个集合是文字的颜色,另外一个则是背景的颜色,因此数据填充会根据游戏场景的设定,设置相匹配的颜色.由于游戏场景中的文字浮于图像的表面,所以无需进行太多的深度测试和筛选,因此在这里将深度筛选部分设为固定值,将文字更符合要求地排入游戏场景中,从而满足游戏场景的特殊性质.数据填充流程如表1所示.
经过人工合成数据后,游戏场景图像中的文本得到了有效地填充,其中效果如图5所示.
4.3 文本定位训练与验证
本次实验使用经过resnet-50网络模型[10]训练后的模型作为实验预训练模型,将游戏场景图像经过降噪,平移等处理后,将每个bitch size设置为50进行训练;其中模型的初始学习率设为0.001,衰减率为1000倍,并经过对比训练筛选取得较优模型.

表1 数据填充流程Table 1 Data population process

图5 场景数据填充图Fig.5 Scene data fill map
实验中改进EAST算法网络模型是基于VGG-16框架进行构建的,网络模型主要由输入层,特征提取层,融合层,BLSTM层以及输出层组成.配置如表2所示,f表示卷积核的数量,k表示卷积核尺寸,s表示步长,p表示填充尺寸,其中池化层阶段采用了2*2的池化窗口来扩增感受野,而BLSTM层中加入了256个隐藏单元.
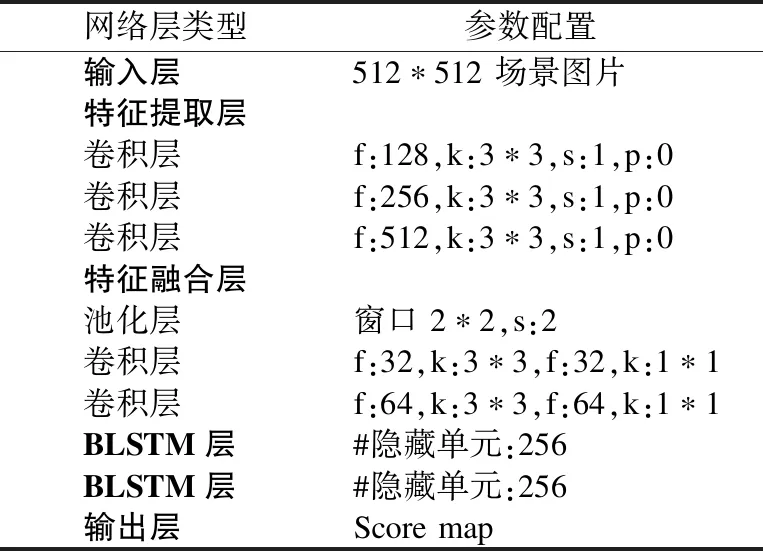
表2 网络参数表Table 2 Network parameter table
为了进一步验证改进EAST算法的性能,本次的实验利用nvdia gtx1080ti显卡在游戏场景的专属训练集上对原EAST算法与改进EAST算法的文本定位效果进行了检测和比较.如表3所示,表中数据显示本文改进算法平均召回率为77.89%,准确率为85.17%,平均F-score为82.76%;从表2中可以看出,本文算法的召回率要优于原EAST算法,比EAST检测算法准确率高;而改进EAST算法的F-score也有所提升,在两个算法执行速度上相差无几的情况下,改进EAST算法在游戏场景上的文本检测性能要优于原EAST算法.其中图6为EAST算法和改进EAST算法在实际游戏场景中的检测效果对比,从图中对比可以看出,EAST算法整体检测效果较好,但是对于长文本的检测有略微缺陷,对长文本检测不够完整;而改进EAST算法对于长文本的检测效果较好,能够较为完整地检测长文本.

表3 改进EAST性能表现Table 3 Improved EAST performance

图6 原EAST算法与改进EAST检测效果对比图Fig.6 Comparison of original EAST algorithm and improved EAST detection effect
在上述实验的基础上,本文选取CTPN等一些优秀的文本定位算法与改进EAST算法在游戏场景数据集中进行比较验证.CTPN算法结合RNN与CNN的特点直接利用卷积在特征图上生成文本区域并进行快速检测[12];PixelLink算法利用像素分割出文本实例并提取文本预测框,处理文字特征上效果明显,具有较好的定位精度[13];MSER算法具有良好的抗噪性和实用性被广泛运用于自然场景的文本检测[14,15];EAST+PVANET是原论文作者对EAST的强化改进,并在ESAT算法中引入了改进的NMS[4];SegLink算法能够快速地对多方向任意长度文本进行检测[7];Wordsup算法能够在文本行和单词标注的数据集上训练出检测模型[5];而TextBoxes算法具有较好的文本感受野,检测速度较快[16].其中在游戏场景数据集上对这几种算法的比较如表4所示.
由表4可以看出,改进EAST算法文本检测的准确率和检测速度要优于其他的对比算法,而在召回率上改进EAST算法略低于处理文字特征较强的PixelLink算法和EAST+PVA算法,同时在F-score上改进EAST算法与pixelLink算法领先于其他算法.可以很直观地感受到改进EAST算法在游戏场景的各项数据中性能表现都是较为出色的,对游戏场景文本检测较快,综合性能与其他算法相比具有一定的优势.这一结果证明了改进EAST算法能够有效地提取游戏场中的景特征值且具有出色的文本感受野,对背景较为复杂的游戏场景图像检测效果相较于其他算法更好[17-19].
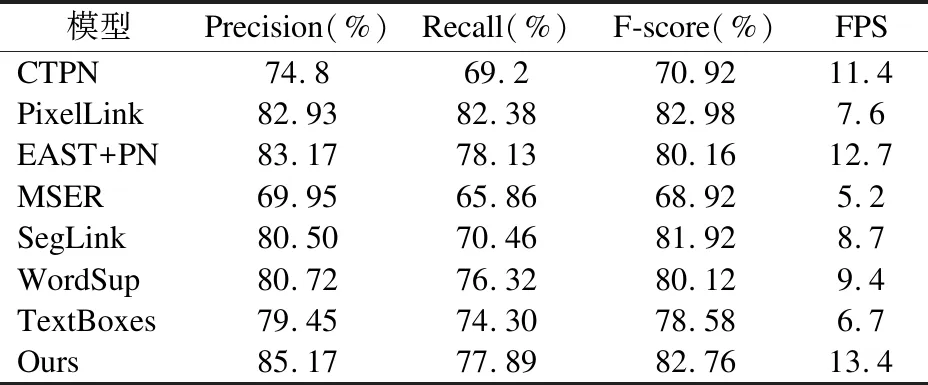
表4 改进EAST与其他方法在游戏场景性能对比Table 4 Improved EAST and other methods in game scene performance comparison
为了进一步验证改进EAST算法的性能,本文选取在上述游戏场景数据集表现较好的算法在ICDAR 2015数据集上进行了对比实验.ICDAR 2015数据集包含1000张训练图和500张测试图,其中文本具有旋转性质和噪声干扰,给检测带来了和很大难度.实验中随机选取了ICDAR 2015的200张图像,其中结果如表5所示.
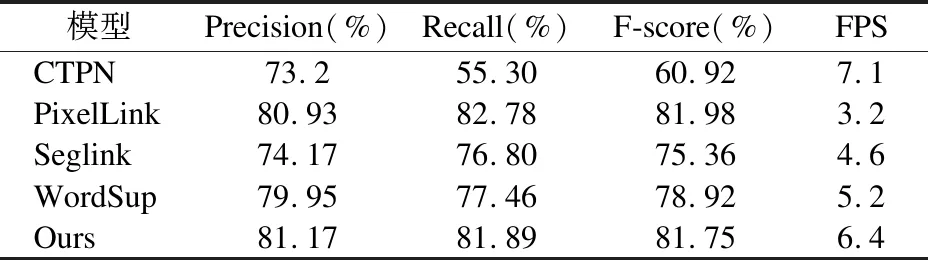
表5 改进EAST与其他方法在ICDAR 2015上性能对比Table 5 Performance comparison between improved EAST and other methods at ICDAR 2015
从表5中可以看出,改进EAST算法在ICDAR 2015数据上的表现也是较为出色的.对比在游戏场景数据集上表现,改进EAST算法在ICDAR 2015数据上检测准确率有所下降,但是仍是最为优秀的;在算法执行速度上领先于检测精准的PixelLink算法.综合而言,改进EAST算法展现出了良好的检测性能,准确率较高.
5 结 语
本文在EAST算法的基础上提出了改进,加入了BLSTM 网络,优化了shrink_poly权重策略,提升了EAST算法的性能.在游戏场景和ICDAR2105数据集上做了大量的对比实验,从而验证了方法的有效性.该方案还仍有提高的可行性,在实验流程上还能对图像预处理的部分再进一步提高完善,加强对图像二值化以及降噪方面的细致处理.同时还要加强数据样本收集,增加数据训练,以达到更好的训练效果.针对以上两个问题,在后续实验研究中将会加大数据预处理的力度,努力搜集样本数据,从而再次提高检测准确率.
