图书推荐服务用户隐私保护方法研究
2020-10-20吴宗大赵又霖王瑞琴卢成浪
吴宗大,赵又霖,王瑞琴,卢成浪
1(绍兴文理学院计算机系,浙江 绍兴 312000) 2(南京大学 信息管理学院,南京 210023) 3(湖州师范学院 信息工程学院,浙江 湖州 313000) 4(浙江机电职业技术学院,杭州 310053)
1 引 言
随着网上信息量急剧膨胀,引发了严重的信息超载问题[1,2].推荐服务通过分析用户兴趣偏好,引导用户发现其真正感兴趣的目标数据,是解决信息超载的有效工具[2].完整的推荐服务通常由三个模块组成[2,3]:用户行为记录、用户偏好分析和推荐算法,其中,推荐算法是推荐服务的核心模块,典型的有协同过滤推荐[4]、基于内容推荐[5]等.为了确保准确性,推荐算法需掌握大量的用户偏好信息.然而,随着云计算等新技术发展,服务器端变得越来越不可信,它对用户偏好信息的大量收集势必会对用户隐私安全构成严重威胁[6].如果不能加强用户隐私保护,推荐服务将失去用户的信任和支持.随着人们维权意识的增强,用户隐私安全问题已成为限制推荐技术进一步发展与应用的主要障碍[7].
社会科学领域学者更多从法律角度研究网络用户隐私保护问题[7].但制定隐私权相关的法律法规并不能根本上解决问题,它更多地需要采用技术手段加以解决[8,9].针对不可信网络环境下的隐私保护问题,信息科学领域学者给出了许多有效的方法,代表性地有:隐私加密、掩盖变换、匿名化等.以下简要介绍这些方法的技术特点,并分析它们在推荐服务中应用局限性.
1)隐私加密是指通过加密变换,使得用户服务请求数据对服务器端不可见,从而达到用户隐私保护的目的,代表性地有隐私信息检索技术[10-12].该类技术不仅要求额外硬件和复杂算法的支持,而且要求改变服务器端已有的信息服务算法,从而引起整个平台的改变,降低了该类方法的实际可用性.
2)敏感数据掩盖是指,通过伪造数据或者使用一般数据,掩盖涉及用户敏感偏好的行为数据[13-16].由于改写了用户数据,该类方法会对准确性造成一定的负面影响,即其隐私保护需以牺牲服务质量为代价,难以满足推荐服务的应用需求.
3)匿名化是一类广泛使用的用户隐私保护方法,它通过隐藏或伪装用户身份标识,使得用户能以不暴露身份的方式使用信息服务[17,18].
然而,许多推荐服务(如数字图书馆)要求用户必须实名.综上,隐私安全的推荐服务需要满足以下要求:
1)改善用户敏感偏好(即用户不愿意暴露的偏好主题)的安全性.具体地,要求攻击者不仅难以从描述用户兴趣偏好的配置文件中识别出用户偏好(数据掩盖和隐私加密可达到该要求),而且也难以通过分析推荐算法的推荐结果,倒推出用户敏感偏好(隐私加密由于需保证准确性,无法达到该要求);
2)确保推荐结果准确性,即对比引入隐私保护方法的前后,用户获得的最终推荐结果保持一致;
3)不损害推荐服务的可用性,即方法不改变已有推荐算法,不需要额外硬件支持,也不会对服务执行效率构成显著影响.
数字图书馆是知识经济社会的重要信息保障.为此,本文以数字图书馆为例,基于内容推荐算法,设计实现了一个用户隐私安全的图书推荐服务.本文贡献包括三方面:
1)设计用户隐私安全的图书推荐体系框架.基于客户端的体系结构,将行为收集和偏好分析模块转移到可信客户端,由客户端构造生成用户配置文件.然后,由客户端构造生成一组假冒配置文件,连同用户文件,以随机次序逐个提交给服务器端进行图书推荐.最后,客户端再从中过滤出对应用户配置文件的推荐结果.
2)基于该隐私框架,定义用户隐私模型.它形式化描述了客户端构造的假冒文件应满足的条件约束,即:与用户文件特征相似,但与用户敏感偏好主题无关.特征相似使得服务器端难以识别出用户文件.敏感主题无关使得假冒文件能有效地降低用户敏感偏好在服务器端的暴露度.
3)基于隐私框架,借助图书分类目录结构,给出用户隐私模型的实现方法.它运行在客户端,能为用户文件构造生成一组满足隐私模型条件约束的假冒文件.最后,实验评估验证了用户隐私模型和及其实现算法的有效性.
2 体系框架
本文建立在基于内容图书推荐算法基础上.基于内容推荐算法分别对用户和物品建立配置文件,通过计算比较配置文件之间的相似度,向用户推荐与其配置文件相似物品.在本文方法中,图书推荐算法运行在服务器端,其输入是:来自客户端的用户配置文件(由一组表征用户兴趣偏好的图书关键词组成)以及来自服务器的图书配置文件(由一组描述图书内容特征的关键词组成).
定义1.(用户配置文件)包括两个部分:图书关键词集合、以及用户对关键词的偏好评分.让表示图书关键词空间,mark(ki)表示用户对关键词ki∈的偏好程度评分(或ki对用户的重要程度),则用户配置文件可表示为:
P0={k1,k2,…,kn|ki∈∧mark(ki)≠0}
定义2.(配置文件相似度)让P0和B0分别表示用户配置文件和图书配置文件,则配置文件间的相似度可通过夹角余弦计算如下:
所谓用户敏感偏好就是用户不希望被攻击者获知的偏好图书主题.图书推荐服务器端是攻击者的主要目标,因而是不可信的.图1展示了本文采用的用户隐私安全的图书推荐框架,其数据处理过程如下:
1)采用基于客户端的体系结构,将图书推荐服务中的用户行为收集和偏好分析模块转移到可信客户端,即由客户端收集和分析用户行为,生成用户配置文件P0.
2)在客户端新增配置文件伪造模块,通过分析P0,结合预设的阈值参数,综合考虑安全性、准确性和高效性,构造生成假冒文件P1,P2,…,Pn,然后,将假冒文件连同用户文件P0,以随机次序提交给服务器用于图书推荐.
3)客户端的推荐结果筛选模块,它从服务器端所返回的推荐结果R0,R1,R2,…,Rn(Ri是推荐算法以Pi为输入所得到的推荐结果)中筛选出对应P0的推荐结果R0(同时抛弃其他结果)返回给用户.

图1 用户隐私安全的图书推荐体系框架Fig.1 A privacy-preserving book recommender framework
从图1可看出:一方面,推荐算法模块输出的推荐结果不再是真实结果,使得服务器端难以根据这些结果,倒推出用户敏感主题;另一方面,推荐算法模块返回结果必然是真实结果的超集,保证了用户能最终得到准确结果.此外,该架构不改变服务器端现有推荐算法,具有良好的实用性.还可看出:配置文件伪造模块所生成的假冒文件对整个架构至关重要,其构造质量是隐私保护的关键.通常,随机假冒文件很容易给攻击者识别出来.因为,用户文件所蕴含的偏好主题是富有规律性特征的(如某段时间内特别偏好某类图书关键字或图书主题);而随机生成的配置文件无法体现这种特征.假冒文件还不能与用户敏感偏好主题相关.如假定用户敏感偏好主题为“犯罪心理”,那么如果生成的假冒文件也涉及“犯罪心理”或与之高度相关主题,显然不合适.为此,假冒配置文件需要满足以下约束:“真假难辨”,应与用户文件拥有高度相似的特征分布,使得攻击者难以识别排除假冒文件,以有效地隐藏用户配置文件;“以假乱真”,能有效地掩盖用户敏感偏好主题,即假冒文件必须能够有效地降低用户敏感偏好主题在服务器端的暴露度,从而使得攻击者难以从中分析出用户敏感偏好.
3 方法实现
3.1 隐私模型
本节描述面向图书推荐服务的用户隐私模型.首先,模型定义用户配置的关键词特征向量(定义3)和主题特征向量(定义6),以捕获用户文件的规律性特征;然后,据此定义关键词特征相似性(定义4)和主题特征相似性(定义7),以度量假冒文件关于用户文件的相似程度(“真假难辨”效果).然后,定义用户主题关于配置文件的暴露度(定义8和定义9),以度量假冒文件对用户敏感主题的掩盖效果(“以假乱真”效果).最后,基于上述度量,进一步定义客户端生成的假冒文件应满足的约束(定义10).
定义3.(关键词特征向量)定义在用户配置文件P0上的关键词特征向量,由各个图书关键词的用户偏好评分值按从大到小顺序排列后组成,即:
KF(P0)=(mark(k1),mark(k2),…,
mark(kn)|ki∈P0∧mark(ki)≥mark(ki+1))
定义4.(关键词特征相似度)对于用户配置文件P1和P2,记它们的关键词特征向量分别为KF(P1)和KF(P2),则P1和P2之间的关键词特征相似性可度量如下:
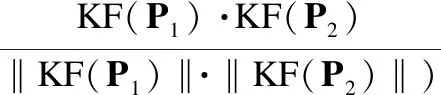
服务器端图书资料库通常会使用一个分类树(如中图法的图书分类目录)组织图书,它将图书按其学科内容分成几大类,大类下分小类,小类下再细分小类.我们选择在图书分类目录中处于次顶层的209个类别(如B0哲学理论、B1世界哲学等)组建图书主题空间.
定义5.(主题偏好评分)让表示图书主题空间,让(u)表示属于主题u的图书关键词集合.用户对任意图书主题u∈的偏好程度(或主题对用户的重要程度)可定义为:
mark(u)=∑ki∈(u)mark(ki)
定义6.(主题特征向量)记用户配置文件P0背后蕴含的用户偏好图书主题集为U0,即U0={u1,u2,…,un|ui∈∧mark(ui)>0},则定义在用户文件P0上的主题特征向量由P0蕴含的图书主题的用户偏好评分值,按从大到小的顺序排列后组成,即:
UF(P0)=(mark(u1),mark(u2),…,
mark(un)|ui∈U0∧mark(ui)≥mark(ui+1))
定义 7.(主题特征相似度)对于给定的用户配置文件P1和P2,记它们的主题特征向量分别为UF(P1)和UF(P2),则P1和P2之间的主题特征相似性可度量如下:
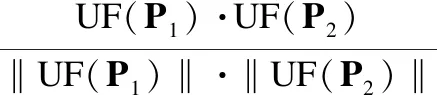
所谓用户敏感偏好就是用户不希望被攻击者获知的偏好图书主题.用户需要预先设定自己的敏感主题集合*(显然有*⊆).给定用户配置文件,根据定义3.3可计算出用户对任意图书主题偏好值.以此作为中间参考,可进一步计算出用户主题关于配置文件的暴露程度.
定义8.(主题关于配置文件的暴露度)对于给定用户配置文件P0以及给定的图书主题u*∈,则图书主题u*关于配置文件P0的暴露度可定义为:
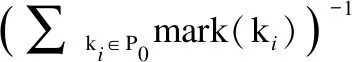
定义9.(主题关于配置文件集的暴露度)对于给定的图书主题*∈和若干个配置文件={P1,P2,…,Pn},则图书主题u*关于配置文件集的暴露度可定义为:
exp(u*,)=mark(u*)·
用户敏感主题是隐私保护的关键.根据图1可知,当攻击者无法区分用户文件P0时,他只能通过分析客户端提交的配置文件集P0,P1,…,Pn猜测可能的用户敏感主题.即敏感主题关于配置文件集的暴露度越高,则攻击者猜测出敏感主题的可能性就越大.为此,可以用敏感主题暴露度来度量用户敏感主题的泄露风险.
定义10.(图书主题隐私模型)给定用户文件P0和敏感主题集*⊆以及若干假冒文件={P1,P2,…,Pn},如果假冒文件满足以下两个条件约束,则称:它们能有效地改善敏感主题*在不可信服务器端的安全性.
1)特征分布相似性.假冒文件应与用户文件特征相似,以实现真假难辨的效果,即minPi∈simK(P0,Pi)simU(P0,Pi)≥φ(φ为预先设定的相似性阈值参数).
2)敏感主题安全性.假冒文件能有效降低用户敏感主题在服务器的暴露程度,以实现以假乱真效果,即minu*∈*)exp(u*,P0)/exp(u*,{P0}∪)≥ω(ω为预先设定的隐私安全性阈值).
3.2 算法实现
本节描述隐私模型的算法实现(如算法1所示).在算法实现中,预先挑选了图书分类目录中处于次顶层的209个图书目录(如B0哲学理论、B1世界哲学等),组建图书主题空间.然后,我们预先向学校图书馆索取了收藏图书涉及的标题信息(也可通过网络爬虫自动爬取),组建图书标题空间.还利用分词技术对图书标题进行分词,共获得127536个关键词,组建图书关键词空间.由于每本图书都拥有中图法分类号属性,它根据图书所属的各级别图书分类目录自动生成.因此,借助于该属性,可将图书标题空间中的标题,映射为图书主题空间中的主题(即获取标题所属主题).进而,以图书标题空间为中介,获取图书关键词所属的可能图书主题集,也即获取了各图书主题u∈所包含的所有图书关键词,即获得(u).在算法1中,每次WHILE循环均会生成一个假冒文件Pi,通过多次循环,构造输出一组假冒文件,以确保用户敏感主题的安全性(见步骤3的WHILE条件).算法1虽嵌套了多层循环,但实际上,在每次最外层WHILE循环执行过程中(即一次假冒文件的构造过程),最内层的FOREACH循环体(步骤9-12)被执行次数刚好等于用户文件大小,即等于|P0|.因为假冒主题从-*中选取(步骤5),使得假冒文件不包含用户敏感主题,所以,在最外层WHILE循环执行完后(即WHILE循环条件不再满足时),WHILE循环体的执行次数近似等于ω(约产生ω个假冒文件,后文实验也验证了这点).因而算法1时间复杂度为O(|P0|·ω).这是一个较为理想的线性时间复杂度,它对图书推荐效率的影响十分有限.
算法1.假冒配置文件构造算法
输入:用户配置文件P0;用户敏感主题*;安全性阈值ω和相似性阈值φ
输出:假冒配置文件P1,P2,…,Pn
1.获取用户配置文件P0背后蕴含的用户偏好主题集,记做U0;
3.WHILE(∃u*∈*→exp(u*,P0)/exp(u*,{P0}∪)<ω)DO
4. 设置假冒配置文件Pi←∅;
5. 随机生成主题集Ui,要求:Ui⊆-*∧|U0|=|Ui|;/*为主题空间*/
6. 随机配对Ui和U0中的图书主题;/*下文假定ui∈Ui与u0∈U0配对*/
7.FOREACH(u0∈U0)DO
9.FOREACH(k0∈(u0))DO
11. 设置Pi←Pi+ki;/*将假冒关键词ki放入假冒配置文件Pi*/
12.ENDFOREACH
13.ENDFOREACH
15.ENDWHILE
16.RETURNP;/*返回假冒配置文件集合*/
4 实验评估
本文方案对用户敏感主题的保护效果依赖于假冒文件的有效性.为此,本节通过实验评估假冒文件有效性.参考数据集:预先建立的图书主题空间共包含209个主题,关键词空间共包含127536个关键词.用户配置文件:用户文件基于关键词空间和主题空间随机构建,文件包含的关键词数量和主题数量以及敏感主题数量均为可调整的实验参数.参考算法:本文方法将与随机方法进行比较(随机方法中,假冒文件的关键词从关键词空间中随机选取,关键词评分也随机设置,但关键词数量与用户文件保持一致).
第一组实验评估假冒文件关于用户文件特征相似性.实验中,用户文件关键词数量被设定为100到400.实验结果如图2所示,子图标题指示采用相似性度量:子图1为关键词特征相似性,即minsimK(P0,Pi);子图2为主题特征相似性,即minsimU(P0,Pi);子图3为整体特征相似性,即minsimK(P0,Pi)simU(P0,Pi).在图2中,X轴指示用户文件包含的关键词数量;Y轴指示假冒文件关于用户文件的特征相似性;[N]中的N(取值1或3)表示为一个用户文件生成的假冒文件数量.可看出,相比随机方法,本文方法构建的假冒文件表现出更好的特征相似性.具体地,本文方法构建的假冒文件关于用户文件的特征相似值接近于1;并且即使在假冒文件数量、假冒文件包含的关键词数量或主题数量发生变化情况下,这种良好的特征分布一致性也几乎毫无变化.而随机方法生成的假冒文件与用户文件之间的整体特征相似值仅在0.2左右,明显低于本方法,并且随着假冒文件数量增加,以及假冒文件包含关键词数量增加,特征值还会随之进一步降低.此外,图3(X表示评分值区间,Y为配置文件中落在该区间范围内的图书比例)进一步展示了随机假冒文件、本文假冒文件和用户文件的图书评分分布.综上,本文方法产生的假冒文件与用户文件间具有高度一致的特征,使得攻击者难以根据特征排除掉假冒文件,实现“真假难辨”效果.

图2 假冒文件特征相似评估结果Fig.2 Feature similarity evaluation

图3 假冒文件特征相似评估结果Fig.3 Feature similarity evaluation
第二组评估假冒文件对敏感主题掩盖效果.这里使用敏感主题暴露度,即minu*∈*)exp(u*,{Pi})/exp(u*,P0).实验结果如图4所示,子图标题指示用户文件的关键词数量;X轴指示为一个用户文件生成的假冒文件数量;Y轴指示敏感主题暴露度量值.可看出,本文方法生成的假冒文件能有效地降低用户敏感主题的暴露度,且改善效果基本与假冒文件数量正相关,不会随着假冒文件数量、文件包含的关键词数量或敏感主题数量改变而发生明显改变.然而,相比于本文方法,随机方法构建的假冒文件虽然也能降低用户敏感主题的暴露度,但它的稳定性相对较差.更重要的是,第一组实验表明,随机方法构建的假冒文件与用户文件的特征相似性很差,容易被攻击者排除.综上,本文方法产生的假冒文件能有效降低用户敏感主题暴露度,实现“以假乱真”效果.

图4 敏感主题暴露程度评估结果Fig.4 Topic exposure evaluation
5 总 结
本文设计实现了用户隐私安全的图书推荐服务,其基本思想是:在可信客户端为用户文件构造一系列假冒文件,然后,逐个提交给不可信服务器端的推荐算法,分别获取推荐结果,最后,在客户端过滤掉假冒文件对应的推荐结果.首先,定义了一个用户隐私模型,它形式化描述了客户端生成的假冒文件应满足约束.然后,借助图书分类目录,给出用户隐私模型的具体实现算法.最后,理论分析和实验评估验证了本文方法的有效性,即能在不损害数字图书馆平台实用性和图书推荐结果准确性的前提下,有效改善用户敏感主题隐私在不可信服务器端的安全性.本文工作虽然以图书推荐服务为例,但对其他推荐服务同样具有适用性.
