双参卷积理论模型预测交通通行时间
2020-10-19金楠森刘美玲谷欣然韩雨彤
金楠森,刘美玲 ,2,谷欣然,韩雨彤
1.东北林业大学 信息与计算机工程学院,哈尔滨 150040
2.哈尔滨工程大学 计算机科学与技术学院,哈尔滨 150001
1 引言
智慧交通是以大数据、云计算、卫星导航等新兴IT技术产业为基础,具有更方便公众出行的,优化的交通运输管理体系,通过数据的积累和传递,更好地开发和利用数据的一种绿色、便捷、安全、畅通的交通模式。
随着城市经济的发展和人们生活节奏的加快,我国整体道路运输的高速发展,机动车增速过快,交通拥堵已经成为“不治之症”,如何缓解交通拥堵问题迫在眉睫。人们无法掌握出行路段的实际情况,不能合理地选择出行方式和安排出行时间,导致某时间段内人车流密度膨胀,是造成交通拥堵的一大成因,要想解决拥堵问题,首先要对活动人口和车流进行有效处理。此时,能够对行驶路线进行有效的时间预估就显得尤为重要。
时间预测看重的主要是精确度和实效性,现有的一些传统方法存在一定的缺陷,如对车辆进行时间预测时,通常利用的都是历史通行时间数据或假设情况来建立算法;忽略车辆的运行状态以及道路在某时刻的真实情况。
国外在二十世纪五六十年代,开始在城市周边布设检测装置,收集道路信息,20世纪90年代开始对浮动车系统有了一定的研究。我国从2000 年开始,由于浮动车数据日趋增加,对浮动车系统的一系列研究也已经成为热点问题。有效地预估车辆的通行时间对交通出行有极大的好处,目前对时间预测的研究常用的有以下方法:
基于历史数据的预测模型。Smith 等人[1]提出了基于历史数据的预测模型用来预测车辆的到达时间,主要是使用大量的历史数据,并假设交通模式为循环变化,以车辆的第一次达到时间为基础在固定位置进行测算;Lin 等[2]主要是根据真实到达时间和公交汽车提供的时刻表之间的误差校对,针对郊区出行者,对公共汽车的到站时间进行实时预测;涂丽佳[3]利用历史数据建立后缀索引树的存储结构,根据历史数据提供的通行时间的结果,在该种存储结构下可以快速地获取子路径序列和相应的轨迹通行时间。
变量衰减预测模型。Chien等人[4]通过大量由独立变量构成的函数建立多变量模型,估算出非独立变量的值,即根据车辆的始终点的距离、时间差、中途滞留的时间等变量作为独立变量,由衰减模型的原理,建立预测模型。
基于人工神经网络的预测模型。常见的神经网络有BP、RBF、AML等多种类型。早有研究证明了利用神经网络得到的结果与其他的预测算法相比准确度更高。基于人工神经网络的预测模型需要经历训练和预测两个阶段,在训练阶段的有监督学习模式下,神经网络重调连接在每层的权值来获取理想的输出期望。Lin和Yang 等人[5]针对于不同时间窗口下的车辆运行特征和交叉路口信号灯对车辆的影响建立了两层的神经网络进行研究;蒋渭忠等人[6]建立3 层BP 神经网络模型,利用MATLAB软件确定隐含层神经元数目为9个,并利用预测样本验证了模型的可行性,得到误差在10%之内的结果。
Kalman滤波模型。Kalman滤波模型属于一种优化的自回归算法,因为其高效率、用途广等特点已经被广泛应用了几十年。Wall 等人[7]利用Kalman 滤波对西雅图市的车辆进行追踪记录,结合历史数据和实时数据,通过统计学的知识预测时间,获得时间分布状态。
基于隐马尔可夫模型的预测模型。欧阳黜霏[8]用非参估计方法将隐马尔可夫模型扩展为无限状态模型能够对实时的数据进行在线预测。
基于支持向量机的预测模型。主要用来解决非线性的问题,避免了人工神经网络里的结构问题。Yu 和Yang[9]利用支持向量机,结合了天气、时间等5个因素,用前车的行驶速度预测之后路段上车辆的行程时间。
除了以上方法,唐俊[10]还利用地图匹配技术,提出经验模态分解与SVR结合的时间预测方法;朱国华[11]将数据分为静态行程时间数据、历史监测数据和无检测器路段数据,划分时间间隔,并给第t个时间间隔设施权值计算行程时间;李勍等人[12]用K临近法结合历史数据预测时间,并用时间协方差对预测的时间进行校准;邢雪等人[13]则引入预测强度并基于预测强度进行聚类预测时间;以及部分针对公共汽车进行预测时间的方法。
近些年来对时间预测有了更深参层次的研究,曹天扬和申莉[14]以路阻函数为基础,提取了流量和车速与路段行驶时间之间的数学关系,建立了适用于最小二乘法求解的预测函数;尹纪军、王栋梁等人[15]通过采样周期计算量历史旅行时间值、实际旅行时间值与平滑系数的关系,确定了短期旅行时间的预测值,吕路[16]从事件状态下交通流统计特性出发,建立了波动理论-BP神经网络事件状态下快速路行程时间预测组合模型计算行程时间。
现有的研究在智慧交通预测时间[17]方向已经取得了一定的成果,但是由于非传感器记录的车辆信息中变量较少及它的不确定性等因素,预测通行时间的研究方法并不能很好地得到所需要的结果。本文考虑到车辆特征状态这一影响因素,并结合车辆行驶速度构建双参卷积速度理论模型,利用分割轨迹后车辆的加速度计算通过时间,为城市居民出行安排提供了合理的理论依据。
2 基于密度划分的双参卷积理论模型分析与研究
2.1 模型成立分析
(1)数据预处理:对数据集中重复、不稳定等数据进行筛选清洗,定义数据抽样规则并将数据集分为训练集和测试集两部分。
(2)模型建立前参数准备。路段中各车辆相邻轨迹点间的距离和行驶速度是建立实验模型、预测结果的必要条件,通过分析建立公式来计算待测变量。
(3)速度突变值处理:由于对待测变量的研究使结果中出现异常的突变值,通过箱线图结合R语言对数据结果进行范围规划,去除异常突变值。
(4)基于皮尔逊的载客相关性研究:利用皮尔逊相关系数研究车辆载客情况和行驶速度之间的相关性,根据结果特征建立速度模型。
(5)基于密度划分的双参卷积理论模型:结合车辆载客情况和行驶速度,调整设置合适的卷积模板,建立双层卷积理论速度模型。
(6)设置修正因子:因为只使用双参卷积理论模型得到的结果有一定的误差,所以设置特征修正因子,提高实验结果的精确度。
(7)预测通行时间:将实验长路段进行轨迹分割,使用双参卷积理论模型得到相应的理论均值速度,利用速度-加速度模型预测车辆的初始通行时间,最后使用修正因子进行修正得到最终的道路通行时间。
2.2 双参卷积速度理论模型的分析建立
2.2.1 数据预处理
本文使用的是成都市1.4万辆出租车,将近14亿条的GPS轨迹数据,数据中包含有出租车ID,经度,纬度,载客状态(0 表示无载客,1 表示载客),时间这5 个参数。清洗掉其中重复和异常的记录,忽略了00:00:00—05:59:59这一时间窗口内的数据。本文中,实现的是预测某路段的通行时间,为了更有利于实验的进行,定义了如下实验道路的抽样规则:
(1)不选取含有异常车速(如时速极高或突变)的路段;
(2)在实验路段的起点和终点,保证车辆不会有停留时间。
将所有的数据集分为训练集和测试集两部分。对实验数据做如下基础定义:
(1)假设车长对车辆速度的计算没有影响;
(2)司机的驾驶行为均良好,没有交通异常事件发生;
(3)不考虑天气因素和车辆自身状态因素以及乘客在上下车时的停留时间。
2.2.2 基础均值速度
本部分主要介绍建模准备阶段的参数的求解过程。
根据数据中的已知变量,即轨迹点的经纬度,使用坐标转换法把经纬度投影到二维坐标系中。由于数据集的数据记录间隔是1 s,所以两个连续轨迹点之间的距离可以认为是直线距离。最后结合欧式距离计算公式计算得到某一路段上同一车辆每两个相邻轨迹点间的车辆距离。
将训练集和测试集一同使用上述坐标转换法进行处理,并将处理后的训练集数据进行筛选,得到实验路段的各车辆数据设为矩阵P:
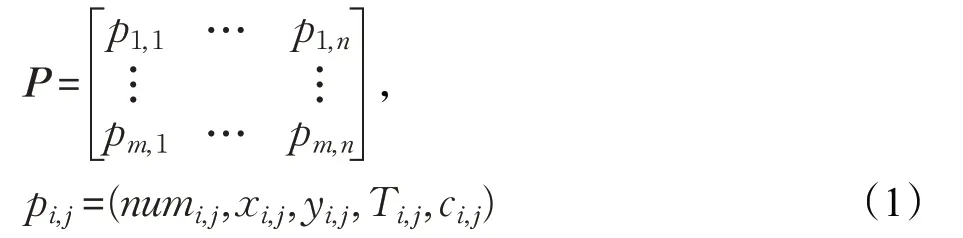
其中,m代表着路段有m辆车,实验路段各车辆轨迹点最多的轨迹点个数记为n。角标i,j代表的是这一路段第i辆车的第j个记录,即第i辆车的第j个轨迹点。Numi,j代表的是第i辆车的序号,xi,j代表的是投影后的x坐标,yi,j代表的是投影后的y坐标,Ti,j代表的是记录时间,ci,j代表的是该车辆的载客状态。
计算前一个轨迹点和后一个轨迹点之间的距离和时间Li,j和Ti,j:

本文利用大量数据验证得出较好的时间间隔,规定:

根据相邻的两个轨迹点间的相关数据,由公式(5)计算基础均值速度为:

实验得到的基础均值速度Vi,j可构成速度数据集。
2.2.3 速度突变值处理
在上述实验设计中,为了计算简便,将车辆数据集中,因此必然出现相邻的两个轨迹点分属于不同的车辆,即前一辆车的最后一个轨迹点数据和后一辆车的第一个轨迹点数据被作为同一辆车的数据处理计算,此类情况计算得到的基础均值速度会出现异常(速度突变),为了消除该种情况对实验结果的影响,通过箱线图来辅助去除速度数据集中的异常速度。
将边界值定义为Di,其对应位置定义为Wi,N代表的是数据集序列中包含的项数。
(1)定义下四分位数、中位数、上四分位数分别为D1、D2、D3,它们所对应位置的数值分别为W1、W2、W3。
①边界值对应位置:

②边界值的数值:
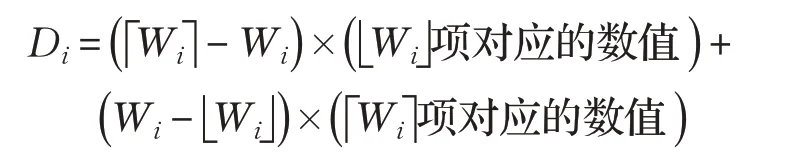
(2)将上限和下限以及四分位数分别定义为D4、D5、W。
①四分位距W:

②上限D4:

③下限D5:

由以上限界值构建箱线图去除异常值。
2.2.4 皮尔逊系数分析研究载客相关性
皮尔逊相关系数r描述的是两个变量间相关性强弱的程度,r的绝对值越大,表明相关性越强。
通常情况下通过表1 中相关系数取值范围判断变量的相关强度。
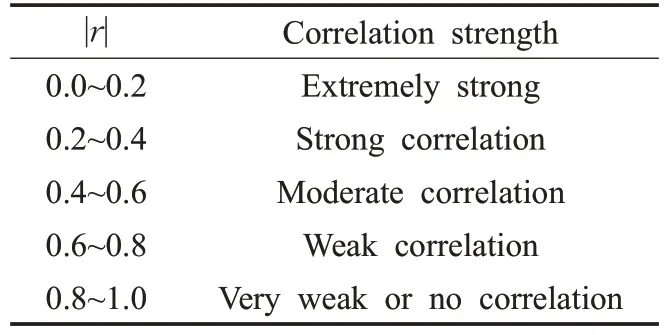
表1 皮尔逊相关系数
为了充分利用车辆的部分特征状态,本文实验选择将车辆的载客情况作为影响因素之一,判断载客情况与基础均值速度之间是否有相关性。

其中,r表示所求的两个变量之间的相关系数,n表示轨迹点数,Vi,j表示速度数据集中的基础均值速度值,表示数据集中所有速度的平均值;Ni,j表示载客情况,值为0或1,表示载客情况值的平均值。
2.2.5 双参卷积理论模型
实验证明速度与载客情况之间的相关性存在,则利用这两个参量来建立以下的双参卷积理论模型。建模结果定义为理论均值速度,分别为载客时的理论均值速度v1和不载客时的理论均值速度v2。
(1)将速度数据集中的基础均值速度分为载客和不载客两种情况,分别设置为载客速度矩阵z1和不载客速度矩阵z2。实验路段中每个车辆都有一个z1和z2。

z矩阵中的元素都是车辆速度,根据相应车辆载客与否的轨迹点数来确定相应的矩阵大小n1、n2,比如实验路段中第i号车拥有15 个载客的轨迹点数,拥有25个不载客的轨迹点数,那么相应的n1、n2为4 和5,矩阵元素空缺用均值来填补。
(2)设置动态自适应3×3的卷积核模板A:

以载客速度矩阵z1为例进行卷积运算,假设n1=5,则可以形成9个3×3的矩阵序列X:

对9个矩阵序列X分别进行中值滤波运算,每个矩阵得到一个输出值Pa(a=1,2,…,9),则A矩阵中的值为:
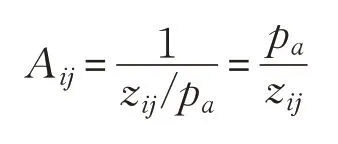
最终计算得到9 个3×3 的卷积模板A,分别对应着9 个矩阵序列X。
(3)依次使用9个卷积模板A与和其对应的矩阵序列X,进行9 次计算,设每次计算得到的结果为x,最后得到 9 个x的值。
(4)9个x最终构成一个新的3×3的矩阵X*,这样就达到了降维的效果,并设置新的卷积核模板A:
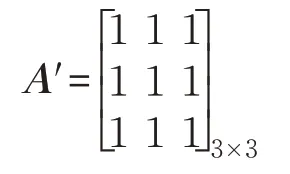
用X*矩阵和卷积核模板A进行卷积运算,得到某一辆车的载客理论均值速度v1。
(5)对于不载客速度矩阵z2,假设n2=5,同理计算得到对应车辆的不载客理论均值速度v2。
(6)最后对于实验路段所有车辆的z1和z2求平均得到各路段最终的载客理论均值速度和不载客理论均值速度。
2.2.6 实验路段时间预测
实验将所选实验路段进行轨迹分割,分为上、中、下游三段,并分别对三段道路上的车辆进行速度计算,得到载客时的理论均值速度VZ1、VZ2、VZ3 和不载客时的速度VnZ1、VnZ2、VnZ3。利用理论均值速度结合加速度计算得到通行时间。
2.2.7 设置修正因子
经过测试集测试,实验使用双参卷积模型计算得到的时间与车辆通行的真实时间之间存在一定误差,为了使预估结果更接近真实情况,本文通过定义修正因子来提高精度,减小误差。
由于实验道路长度为1.4 km,每辆车的行驶轨迹始末点的距离都不一样,因此按照行驶轨迹始末点的距离,分为14种不同情况。例如,当某辆车的轨迹始末点的距离在0~100 m 之间时,将这辆车划到第一种情况;当某辆车的轨迹始末点的距离在100~200 m之间时,将这辆车划到第二种情况;当某辆车的轨迹始末点的距离在1 300~1 400 m之间时,将这辆车划到最后一种情况,且每种情况里包含的相关数据构成一个数据集,并根据修正因子分别对由每个数据集算出来的时间进行修正。
在针对整段长为1.4 km的路段时,某辆车通过的时间T使用对应的修正因子Flag修正。
修正后时间T′:
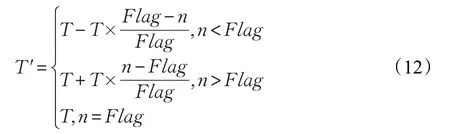
n为这辆车通过这段路时被记录的轨迹点的个数。
对最终结果评价指标,采用绝对百分比精度公式计算结果精确度:
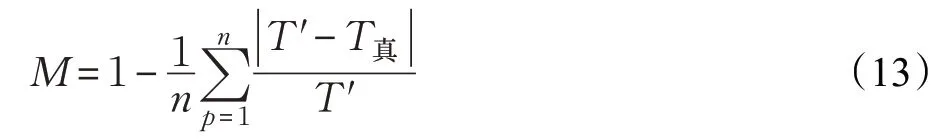
M代表百分比精确度,n代表实验路段的车辆数,T代表实验经过双参卷积模型和修正因子处理后得到的最终预测时间,T真代表测试集中两轨迹点间的真实时间。M的值越大代表精度越高,结果更加接近测试集里的真实时间。
3 实验结果分析
3.1 速度异常调整
图1 为箱线图的结果,纵坐标代表速度值,由图可以明显看出,箱线图的上下限控制在0~80 km/h,因此将速度值大于80 km/h的定义为异常值并去除。
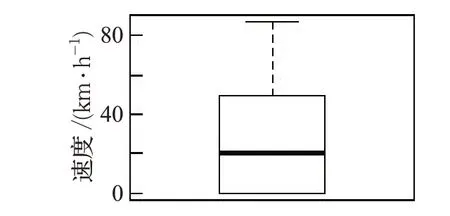
图1 实验路段速度值的箱线图结果分析
3.2 路段处理及分割依据
本文实验在特定时间窗口内的实验路段的GPS 轨迹点投影如图2所示。
由图2 可以看出在选定道路上,车辆密度较大,车辆轨迹点分布密集且均匀,因此将此路段按照上、中、下游进行轨迹分割。保证路段上的轨迹点数目被平均分配,即三段路包含的轨迹点数目相同。
3.3 皮尔逊系数分析研究载客相关性
车辆行驶速度与载客情况的相关性分析如表2所示。

图2 实验路段的车流密度投影及子路段划分
第一列为车辆编号,第二列为两个变量,分别是速度(speed)和载客情况(cp)。每辆车速度变量后对应的5个数值为不同载客情况下的速度值,而载客变量后对应的5 个数值表示的是车辆是否载客(0 表示不载客,1表示载客)。最后一列数据r表示的是相关系数。
由车辆行驶速度与载客情况之间的相关性,分析得到以下结论:
当r>0 时,表示载客(cp=1)的平均速度比不载客(cp=0)时的平均速度大,且r绝对值越大,相差越明显。
当r<0 时,表示不载客(cp=0)的平均速度比载客(cp=1)时的平均速度大,且r绝对值越大,相差越明显。
当载客情况一致时,即选取的车辆的5 组值均为0或1时,r的值为0。
3.4 模型建立及结果实现
利用基于密度划分的双参卷积理论模型算出的速度结果如图3所示。
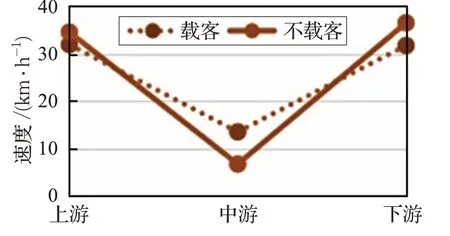
图3 不同载客情况下实验路段的速度结果显示
对实验路段进行中心点标记,如图4所示。
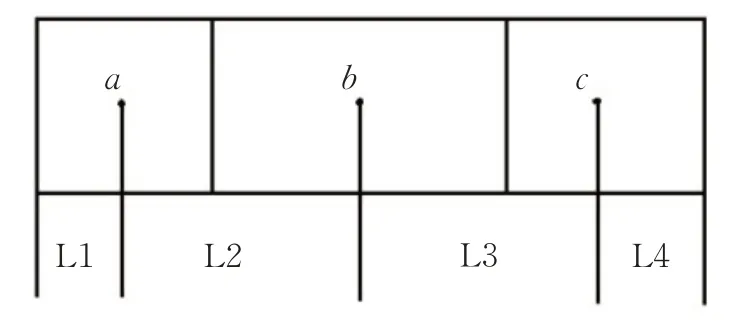
图4 预测道路划分情况显示
令路段中心点a、b、c的速度为已知的载客(不载客)理论均值速度VZ1、VZ2、VZ3(VnZ1、VnZ2、VnZ3),根据车辆行驶的情况,计算每段路的加速度并计算通行时间。

表2 速度与载客情况的相关性分析结果
在 L1 与 L4 路段车辆为匀速行驶,L2 与 L3 路段车辆进行相应的加速或减速行驶。因为实验数据没有恰好处于两端的车辆轨迹数据,所以根据各车辆起点和终点所在位置使用相应的速度和加速度进行计算,再经过相应的修正因子进行修正得到该车辆从起点到终点所用的通行时间。
3.5 修正因子修正误差
采用绝对百分比精度公式计算可知,①结果的精度在60%左右,但改进后的方法②结合修正因子后得到结果的精确度如图5所示,实验预估的车辆通过某段路的时间与真实时间之间达到了90%左右,精度得到了有效的提高,充分证明本文实验的方法有较高的准确性、可用性和真实性,较准确地接近车辆真实的通过时间。
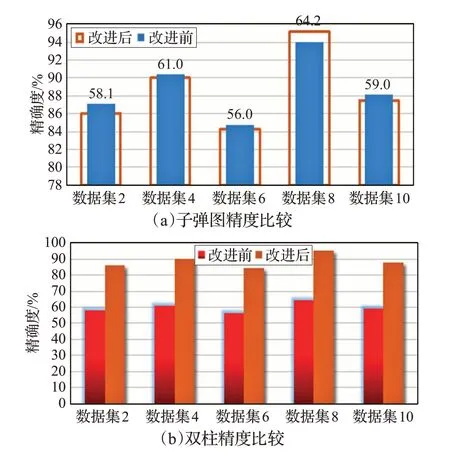
图5 改进前后时间精确度结果对比
4 总结及展望
本文根据原始数据集中仅有的车辆经纬度和点时间数据,建立算法得到必需参量轨迹点间距和车辆行驶速度。基于传统的时间预测研究方法的不足,融入了新的车辆的运行特征:载客情况。在构建速度模型时,将传统的卷积运算设置为双参量,为了适应卷积运算的模板移动,用9 个不同的模板动态实现卷积过程,使模型的有效性和准确性不会受限于车辆行驶速度的多变性。
改进的修正因子考虑了车辆不同时刻轨迹始末点的不同和轨迹的不确定性,对始末点位置进行归类,并在时间预估模型中起到了一定的优化作用,使预测的通行时间与真实通行时间的精确度达到80%以上,有效地提高了车辆出行安排的合理化和层次化。
基于本文基础,下一步将对交通状况更为复杂的可变长路段进行分析建模,尝试考虑将车辆异常点数据融入数据集作进一步研究,并结合天气、驾驶员行为、交通信号灯等不确定因素丰富实验模型,大范围地模拟真实路网,改进对单一路段预测时间的模型为由出发点到目的地之间的时间预测模型。对城市交通道路时间预测研究奠定更扎实稳定的理论基础,具有较强的推动力与发展价值。
