基于篇章上下文的蒙汉神经机器翻译方法
2020-10-19苏依拉仁庆道尔吉
高 芬,苏依拉,仁庆道尔吉
内蒙古工业大学 信息工程学院,呼和浩特 010080
1 引言
机器翻译作为人工智能的终极目标之一,主要研究如何使用计算机将一种源语言翻译成为另一种目标语言[1]。机器翻译的研究能够促进不同民族和国家之间的信息交流,具有重要的科学研究价值。
蒙古族作为我国五十六个民族的重要成员之一,是草原游牧民族的典型代表和草原文化的重要传承者。蒙古语则是我国蒙古族同胞使用的主要语言。在我国经济快速发展与社会不断进步的背景下,蒙古族与汉族之间的交流日益频繁。蒙汉机器翻译的研究能促进蒙汉两种文化的融合和信息共享,对于两种文化的价值观相互渗透,凝聚民族的核心文化,促进良好民族关系的建立具有重要意义。
随着深度学习技术的不断发展,神经机器网络碾压统计机器网络,已成为机器翻译业界的主流[2]。然而,在当前的神经网络机器翻译中,大部分的机器翻译系统还停留在单句范围内进行信息处理[3],以句子级的翻译方式为主,使用平行句子语料库来训练翻译模型。即使翻译一篇篇章也是先将篇章拆分成单个句子,然后对单个句子进行翻译,孤立地进行句子翻译的神经网络机器翻译模型在翻译的过程中仅能利用当前句子的信息,完全忽略了篇章上下文其他有价值的语境信息之间的联系[4]。
“歧义”是自然语言中很常见的一个现象,同一个词根据不同的上下文有两个或者两个以上的词义时,就会产生歧义。蒙古文同形词歧义消除问题是蒙古文信息处理的难点之一。不同的上下文,一个词可能含有不同的意义和解释。国内外一些研究者已经表明通过篇章级上下文可以很好地解决词义歧义和指代消解等问题进而提高翻译质量。
基于篇章上下文方法的机器翻译1994年就有学者提出。2006年,厦门大学的史晓东教授指出“语篇才是人类语言的交际单位,才是翻译的基本单位”[5]。中科院的刘群教授在2012年提出机器翻译需要用到多个层次的知识,包括篇章层面。2018年,中国科学院自动化研究院张家俊教授在“机器翻译前沿动态”报告会上对比近两年ACL 系列文章,指出未来机器翻译的趋势是利用篇章上下文进行翻译。不可否认,以上专家都有共鸣,机器翻译的处理单元必须跨越句子。很显然有些句子直接依靠它本身的信息就能够获得正确的翻译,但是还有一些句子却需要更大的篇章上下文信息[6]。
近两三年,利用上下文信息来提高机器翻译成为了一个趋势。Tiedemann等人[7]研究了扩展上下文在基于注意力的神经机器翻译中的应用。实验以翻译电影字幕为基础,讨论了在单个翻译单元之外增加片段的效果。爱尔兰都柏林大学研究者提出了一种跨句语境感知方法,研究了历史语境信息对神经机器翻译性能的影响[8]。爱丁堡大学(The University of Edinburgh)研究者基于现有的Transformer 模型,构造了源语言编码器(source encoder)和上下文编码器(context encoder),上下文相关的源语言表示是通过两个编码器的输出经过注意力层得到的[9]。莫纳什大学(Monash University)的研究者通过构造记忆网络来存储源语言篇章和目标语言篇章中句子之间的依赖关系来解决篇章级机器翻译的任务[10]。以上文献都表明神经机器翻译需要根据源句定义的上下文跨句来提高译文的连贯性。利用篇章上下文的机器翻译能提取到其他有价值的语境信息之间的联系,有助于提高翻译质量。然而,大型篇章级并行语料库通常稀缺,尤其对于少数民族语言而言。基于此问题,拟参考Zhang Jiacheng等人[11]的思想,利用较为丰富的句子级平行语料库和有限的篇章级并行语料进行机器翻译的训练。并且,此文还研究了蒙汉神经机器翻译的翻译单元粒度。汉语端采用子词作为基本翻译单元,有效解决集外词(OOV)和罕见词(Rare word)问题[12]。蒙古语端以子素、单词、短语为单位对句子进行切割。
本文在Zhang Jiacheng等人[11]的工作基础上,第一,将汉字子词特征融入到蒙汉神经机器翻译的方法,同时,有效地证明了汉字子词特征可以对神经机器翻译模型起到促进作用。第二,蒙古语端使用混合编码器,混合编码器采用三种编码状态混合而成,包括字素、单词和短语三类向量信息。使用混合编码器的好处是利用不同的深度和结构的编码器对源端蒙文句子进行分布式表示。
2 背景知识
本文研究的对象是蒙文到中文的神经机器翻译。其中,中文端以汉字子词(Byte Pair Encoder,BPE)为单位对句子进行切割;子词的全名称是字节对编码,它主要是为了解决数据压缩,它的原理是替换,字符串中频率高的字符被频率低的字符替代的一个层层迭代的过程。BPE 最初2016 年应用于机器翻译,很好地解决集外词和罕见词问题[13]。
蒙古文词的数量庞大,而且可以通过在词干后添加附加成分来构造新词[14],因此翻译模型无法覆盖所有词,故未登录词的问题会一直存在于词级翻译模型中。而蒙古文字符数量有限且数量较少,所有词都由字符序列组合而成,这种字符序列有一定的组合规律,适合神经网络模型去学习,故融合不同粒度的切分方法来预处理语料。
蒙古文端以子素、单词、短语为单位对句子进行切割。使用混合编码器,利用深度和结构不同的三个编码器即对源端蒙文句子进行分布式表示。混合编码器的三个编码器的其他参数独立分布,只是共享词向量矩阵。在机器翻译中,当输入源端句子时,词向量将输入句子数学化,输入的词或字符经过词向量映射为向量矩阵。如图1所示,混合编码器的目的是利用深度和结构不同的多个编码器对源端蒙文句子进行分布式表示,不同深度的编码器对源端句子具有不同的分布式表示能力,不同结构的编码器对句子表示过程中关注的句子特征的权重不同,然后源端蒙文句子的最终表示是将多个分布式的表示融合起来。期望通过这种方式能得到一个对源端句子更全面的表示,增强模型能力。

图1 混合编码器
混合编码器建模的公式为:

式中,Γ为混合函数,是三种激活函数的集合,ht为词编码器的隐藏状态,htc为字素编码器的隐藏状态,htp为短语编码器的隐藏状态。
词编码器的建模公式为:

式中,ht为词编码器的隐藏状态,φ表示激活函数,C为映射矩阵,wt为词的向量表示。
这里,wt为单字的蒙古语词向量表达形式,由于蒙古语形态多变,单单利用词单位的向量形式无法做到较好的编码效果,蒙古语语义也得不到较为理想的获取,基于神经网络的蒙汉机器翻译系统还将另外构建两种编码器,分别为字素编码器和短语编码器。
字素编码器的建模公式为:

式中,htc为字素编码器的隐藏状态,ψ为激活函数,Cc表示映射矩阵,wtc为字素的向量表示。
短语编码器是将源语言句子中成组出现的短语作为编码器的基本单元进行编码,体现了双语平行对照语料中的一对多翻译的优势,尽可能地保留原始句子的语义特征。对源语言蒙语句子的短语进行短语划分,进而构建短语字典库,然后构建短语编码器。
短语编码器的建模公式为:

式中,htp为短语编码器隐藏状态,γ为激活函数,Cp为映射矩阵,wtp为短语的向量表示。
3 神经机器翻译
3.1 神经网络的seq2seq模型
Seq2Seq[15]的中文名称是序列到序列,序列到序列指的就是输入和输出都是序列。假设有一个蒙语句子“”和一个其对应的中文句子“明天是周末”,那么序列的输入就是“”,而序列的输出就是“明天是周末”,从而对这个序列对进行训练。
Seq2Seq 模型由编码器和解码器两个部分来构成,其中编码器将源句总结为矢量表示,解码器从矢量中逐字生成目标句。使用编码器-解码器以及注意力机制,神经机器翻译在各种语言对上的性能已经超过了传统统计机器翻译的性能。
如图2 所示,在输入句子比较长时,此时所有语义完全通过一个中间语义向量C来表示,会丢失很多细节信息,因此要引入注意力模型。深度学习中的注意力机制核心目标是从众多信息中选择出对当前任务目标更关键的信息。注意力机制的引入使得神经机器翻译由于定长源语言句子向量带来的长距离依赖问题得到缓解。
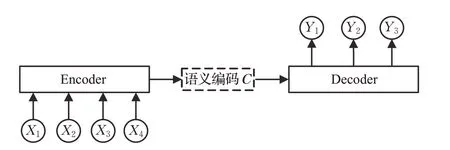
图2 Seq2Seq模型
3.2 带注意力机制的seq2seq模型
2015 年,注意力机制[16]的提出,是自然语言处理的一大里程碑。
注意力机制函数的本质是对Source中元素的Value值进行加权求和,而Query 和Key 用来计算对应Value的权重系数,如图3所示。

图3 注意力机制函数
基于注意力机制的神经机器翻译模型在生成每个单词的时候,如图4 所示,即由固定的中间语义表示C会被替换成根据当前输出单词而不断变化的Ci。基于注意力机制的神经机器翻译模型中编码器为每个源语言词生成包含全局信息的向量表示,在生成每个目标语言词时,解码器会动态寻找和当前词相关的源语言上下文信息。
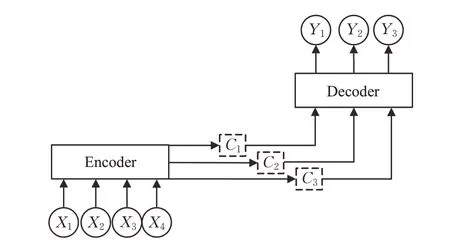
图4 加入注意力机制的Seq2Seq模型
3.3 纯注意力机制的seq2seq模型
通常使用循环神经网络或卷积神经网络[17]来处理变长序列得到一个相同长度的输出向量序列。然而,不管是对于循环神经网络还是对于卷积神经网络,其实都是属于对变长序列的“局部编码”。循环神经网络因为梯度消失只能建立短距离依赖,而卷积神经网络是基于N-gram的局部编码。
如果要建立输入序列之间的长距离依赖关系,通常有两种方法,其一是通过加深网络层数去获取长距离的依赖关系,其二是应用全连接网络。如图5 所示,全连接网络是一种直接的建模远距离依赖的模型,但由于不同的输入长度,其连接权重的大小不同。故全连接网络无法应对变长的输入序列。这时可以利用自注意力机制,如图6所示,动态地生成不同连接的权重,从而处理变长的信息序列。
图5 全连接模型

图6 自注意力模型
2017年末,Google提出的Transformer[18]是自然语言处理的又一大里程碑。Transformer 完全由纯注意力机制组成,更准确地说,Transformer 由且仅由自注意力机制[19]和前馈神经网络组成。
Transformer使用自注意力机制,将序列中的任意两个位置之间的距离缩小为一个常量;其次它不是顺序结构,因此具有更好的并行性,自注意力机制的核心内容是为输入向量的每一个单词学习一个权重,多头注意力的不同之处在于进行了h次计算而不仅仅算一次,这样的好处是可以允许模型在不同的表示子空间里学习到相关的信息。
如图7所示为传统的Transformer结构简图。

图7 Transformer结构简图
4 篇章上下文方法
本文拟采用融合篇章级语义信息的策略来解决蒙古文同形词歧义问题和指代消解问题,提高蒙汉神经机器翻译的质量。由于大型篇章级并行语料库通常不可用,因此拟利用较为丰富的句子级平行语料库和有限的篇章级并行语料库。由于篇章上下文通常包含多个句子,因此捕获远程依赖关系并识别相关信息非常重要。使用多头自注意力来计算篇章级上下文的表示,能够减少远程依赖关系到O(1)之间的最大路径长度并确定上下文中不同位置的相对重要性。
如图8 所示,在传统的Transformer 框架基础上,通过自注意力模型上添加模块来融合篇章上下文信息,并且使用多头自注意力机制将得到的篇章上下文的隐层表示同时融入到源端编码器和解码器中。上下文编码器的输入是源端待翻译句子与同一个篇章中的前k个句子。上下文编码器类似于Transformer 的编码器,是一个多层结构,每一层都包含一个自注意力层和前向反馈层,并且利用多头上下文注意力(context attention)将篇章上下文的隐层信息输入到源端编码器和解码器中。

图8 篇章上下文语境方法的结构框架
将篇章语料编码成篇章向量,使用多头自注意来计算篇章级上下文的表示,自注意编码器的输入是一系列上下文字嵌入,表示为矩阵。篇章级训练多头注意力,更能获取不同子空间的语义信息,提高语义消除歧义能力,提高翻译质量。
采用两步训练法:
(1)训练一个标准的自注意翻译模型(句子级别和篇章级别语料);

(2)训练新加入的模块(篇章级别的语料训练)。

图8 左侧列上下文编码器端第一个子层是多头自注意力:

第二个子层是前馈神经网络:
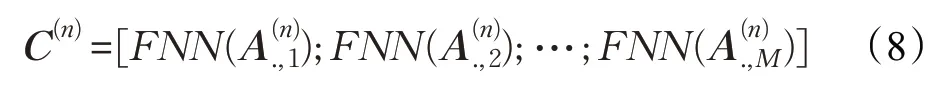
图8中间列的编码器端第一层是多头自注意力:

第二层是上下文注意力,将篇章上下文集成到编码器:
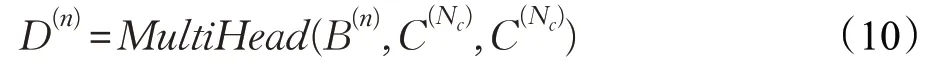
第三层是前馈神经网络:

图8右侧列的解码器用来计算目标端的表示:
第一层是多头自我注意力:
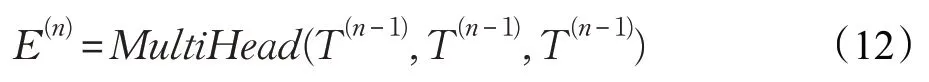
第二层是上下文注意力,将篇章上下文集成到编码器中:

第三层是编码器-解码器注意力:
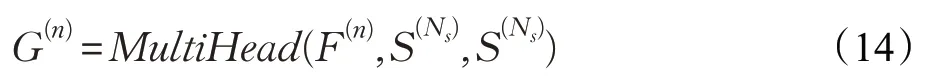
第四层是前馈神经网络:

式中,n=1,2,…,Nt;Y∈RD×j;T(0)=Y。
5 实验
5.1 数据预处理
通过BLUE 值来证明篇章上下文语境方法能够提高蒙汉翻译性能。本文采用了两个数据集来进行实验验证。
(1)内蒙古大学开发的67 288句对蒙汉双语平行语料,数据集划分如表1 所示,随机选取1 000 句为验证集,800 句为测试集。从65 488 句训练集里选择具有上下文关系的篇章语料库,如表2 所示,在本文使用的语料库里共选择出35 个具有上下文关系的篇章语料库,涉及到小说、对话等,其中篇章上下文语料共有34 784句对。

表1 数据集1语料库的划分

表2 篇章上下文数据
(2)CWMT 去重校正后的118 502 句对蒙汉平行语料划分如表3所示,随机选取1 500句为验证集,1 000句为测试集。从116 002句训练集里选择具有上下文关系的篇章语料库,如表2 所示,在本文使用的语料库里共有37个具有上下文关系的篇章语料库,涉及到小说、对话等,其中篇章上下文语料共有29 702句平行语料库。

表3 数据集2语料库的划分
5.2 实验配置
本文使用谷歌开源系统库Tensor2Tensor的Transformer的神经机器翻译系统作为实验的基准系统。篇章级机器翻译选用清华大学自然语言处理小组开发的机器翻译库THUMT。本文使用系统为Ubuntu 16.04,语言为python 2.7.0,TensorFlow 版本为1.6.0。参数设置如下:隐藏层大小设置为512,多头注意力的头数设置为8,编码器解码器的层数设置为6层,上下文编码器的网络层数设置为1层,使用Adam进行参数优化,本文还对输出层采用dropout方法以加强神经网络的泛化能力。本文采用批量式方法对参数进行更新,大小设置为120,本文将束搜索的大小设置为10。迭代步数设置为100 000步,batch-size 设置为 6 250,用 mult-bleu.per 脚本评测翻译性能BLUE值。
5.3 实验结果
为了验证篇章上下文方法能提高翻译的质量,分别选用两个数据集来进行对比实验。实验结果如表4所示。
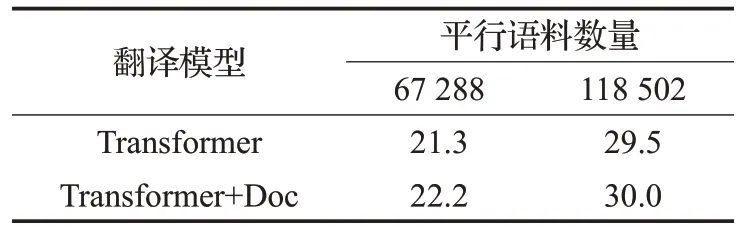
表4 BLUE值
如表4 所示,在67 288 句平行语料库里,在测试集上句子级别的翻译模型BLUE值为21.3,加入篇章上下文语境以后 BLUE 达到了 22.2,提升了 0.9 个 BLUE 值。在118 502 句对平行语料库中,句子级别的翻译模型BLUE 值为29.5,加入篇章上下文语境以后BLUE 达到了30.0,提升了0.5个BLUE值。
用一个例子来说明加入篇章上下文语境以后如何帮助翻译。例如英文单词“address”,如果没有上下文,很难消除“address”的歧义,而加入篇章上下文语境以后,“address”可以很好地从上下文的“speech”推断出来是“演讲”的意思。这个例子表明本文的模型通过整合篇章上下文来学习解决词义歧义问题进而帮助翻译。
6 结束语
通过本文实验表明,在两种语料中,加入篇章上下文方法的蒙汉神经机器翻译相比于句子级别的蒙汉神经机器翻译BLUE值确实有提升,证明篇章上下文方法确实能够提升机器翻译的效果,但是提升效果不是特别明显,大概提升了0.5~1个BLUE值,对此认为并不是加入篇章上下文语境技术后对翻译结果提升效果小,而是由于在蒙汉平行语料中,篇章上下文语料数据太少,如果句子级平行语料数据和篇章级语料数据有数量级差或者主题存在差异时,训练会不太稳定。故下一步拟爬取数量更多、质量更好的蒙汉篇章上下文并行语料库来进一步提升翻译效果。
