基于AHB总线的RISC-V微处理器设计与实现
2020-10-19郝振和焦继业李雨倩
郝振和,焦继业,李雨倩
1.西安邮电大学 计算机学院,西安 710121
2.西安邮电大学 电子工程学院,西安 710121
1 引言
RISC-V是由美国加州大学伯克利分校设计的一套开源指令集架构,RISC-V 具有低功耗、低成本、灵活可扩展及安全可靠等特性[1-4]。国内外已有众多高校和企业对RISC-V指令集进行研发,阿里平头哥在2019年7月发布了高性能RISC-V架构处理器玄铁910;兆易创新也在2019 年8 月发布了一款基于RISC-V 的32 位通用MCU芯片GD32VF103系列。
嵌入式微处理器是数字信息产品的核心引擎,需要在终端对数据进行简单处理和实时控制[5]。在嵌入式系统中,ARM系列一直占据着很大市场,随着物联网时代的来临,嵌入式终端设备对功耗和性能具有更高的要求,ARM 等主流架构的胜任能力有限,RISC-V 作为新兴架构以其精简的体量,表现出了较强的优势[6]。RISC-V最为重要的一个特点是模块化,用户可以根据具体的应用需求选择不同的扩展来实现差异化设计,这对于追求低功耗小面积的嵌入式应用至关重要[7]。随着RISC-V指令集生态系统的发展,RISC-V 也将被更广泛地应用于嵌入式或者新兴的IoT、边缘计算、人工智能等领域[8]。
同时,基于IP核复用的SoC设计方法逐渐成为集成电路设计的主流技术[9]。总线系统是嵌入式设计中互连各IP应用最广泛的结构,优秀的系统结构可以极大程度地实现IP 共享,提高系统传输效率。目前基于RISC-V的处理器使用的总线各异:Tilelink是伯克利大学Rocket[10]项目中使用的总线协议,该协议较为复杂,其应用并不广泛;蜂鸟E200系列使用的是自定义ICB总线,不适用于做嵌入式开发和应用;另外在RISC-V 处理器中广泛使用的AXI总线协议[11],需要主设备自行维护读和写的顺序,控制相对复杂,且在SoC 中集成不当会造成死锁。在嵌入式应用中RISC-V处理器核若采用自定义总线,一方面增大硬件开销,另一方面会造成负担,影响系统的运行速度,降低稳定性和扩展性。在各类总线中,由ARM 公司提出的AHB 总线因其提供的丰富的IP 资源,得到了广泛的使用[12]。
本文采用哈佛体系结构进行设计,实现了RISC-V ISA 中基本整数指令集及M/A/C 三个扩展指令集。设计采用标准AHB 总线接口,可实现CPU、Cache 等高性能设备互连。完成了指令集测试以及系统级功能测试,最后探讨基于AHB 总线的RISC-V 处理器在应用中的优势。
2 RISC-V指令集
2.1 RISC-V指令集特点
RISC-V 本身是一种指令集标准规范,和C/C++语言规范、POSIX 等系统标准一样[13]。RISC-V 试图通过一套统一的架构来满足各种不同的应用场景,这种模块化是x86 和ARM 架构所不具备的。RISC-V 指令集在小面积低功耗处理器领域具有以下优势:
(1)精简:架构简洁,模块化,指令集数目少,无需向后兼容;
(2)安全:安全系数高,稳定;
(3)开源:免费使用,用户能自由修改,可定制化。
由图1可以看出,RISC-V指令集体系结构在学术界得到了广泛的推广。

图1 科学出版物年增数量比较
2.2 模块化组织方式
RISC-V 使用模块化的方式进行指令划分,每个模块使用一个英文字母表示。最基本也是必须要实现的指令集部分有I字母表示的基本整数指令子集[13]。其他指令子集部分均为可选模块。本次设计实现基本整数指令集I以及M/A/C三个扩展指令集:
I:32 位地址空间与整数指令,支持32 个整数寄存器,指令类型包括包括整数运算指令、分支跳转指令、整数Load/Store 指令、CSR 指令、存储器屏障(FENCE)指令、特殊指令。
M:整数的有符号以及无符号乘除法运算,支持整数乘法指令、整数除法指令两种指令类型。
A:原子操作指令集,为同步操作提供必要的支持,可以实现I/O 通信中的总线原子读写,从而简化设备驱动,提高I/O 性能。指令类型包括AMO 指令、Load-Reserved指令和Store-Conditional指令。
C:16 位压缩指令集,是 RISC-V 最通用的 ISA 扩展之一。与ARM的Thumb-2指令集相似,RISC-V标准包含一个压缩指令的规范,压缩指令是主要降低代码密度的一种手段,指令宽度只有16 bit,可以镜像完整的32位指令,压缩指令只对汇编器和链接器可见,避免为处理器核编译器的设计增加负担[14]。压缩指令解码器可以检测这些指令并将它们解压缩成标准的32 bit指令。
3 RISC-V处理器核设计
3.1 流水线设计
流水线本质上可以理解为一种以面积换性能、以空间换时间的手段[15-16]。本次设计根据RISC-V 指令集的特点,设计深度为2级的流水线,如图2所示。传统五级流水线(取指、译码、执行、访存和写回)中每级流水级之间都存在适当的寄存器,流水线级数内部都有各自的组合逻辑数据通路,并且彼此之间没有复用资源,因此其面积开销较大。2级流水线极大程度地减少了硬件逻辑的数量,在保证基本功能的前提下,不仅降低了硬件成本而且降低了功耗。
在流水线第一阶段,PC取指并访问指令存储器,并将取出指令存入IR寄存器。取指阶段会完成简单的译码过程(mini-decode),此处的译码不需要完整译出指令的所有信息,而只需要译出部分指令信息,包括此指令是属于普通指令还是分支跳转指令以及分支跳转指令的类型和细节。另外,在第一阶段还会对跳转指令进行简单的分支预测(Simple-BPU),跳转指令类型如表1所示,判断是否为跳转指令代码如下:
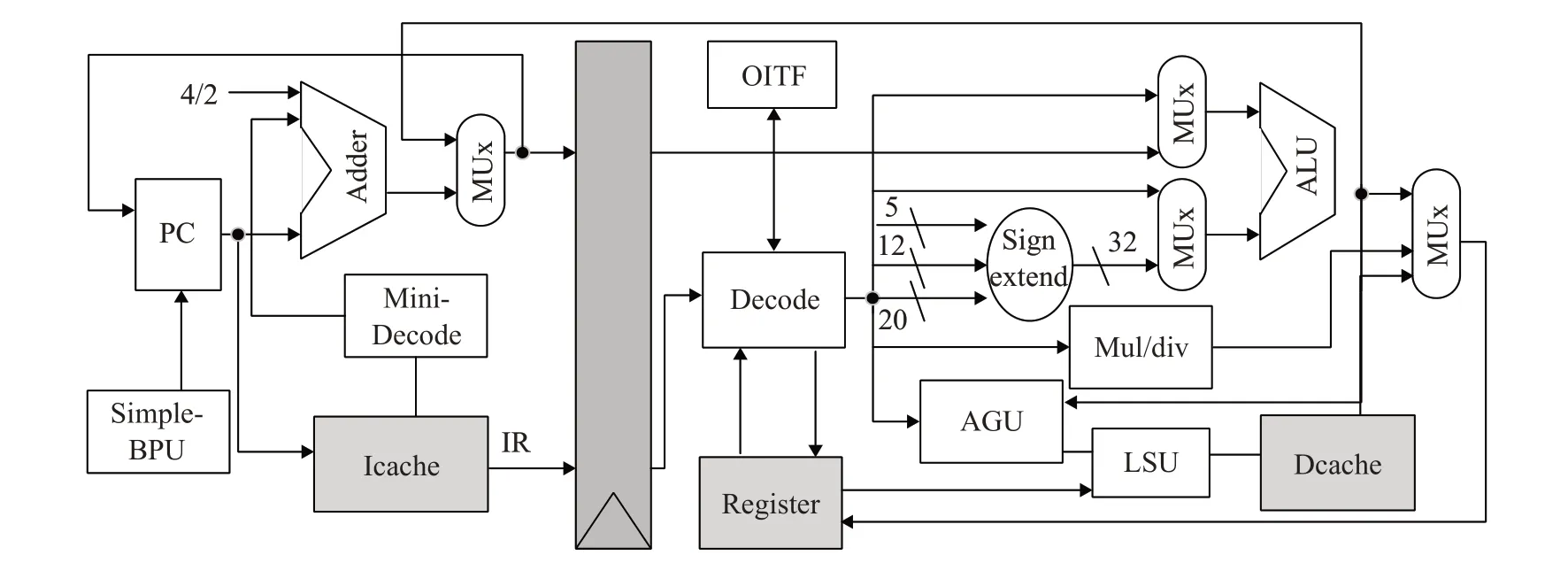
图2 两级流水线实现流程图
assign prdt_taken=(dec_jal|dec_jalr|(dec_bxx & dec_bjp_imm[31]))
(1)对于带条件的直接跳转指令,使用静态预测(向后跳转预测为需要跳,否则预测为不需要跳),按照指令的定义使用其PC 和立即数表示的offset 相加得到其跳转目标地址。
(2)对于无条件直接跳转指令,由于其一定会跳转,因此无须预测其跳转方向,对于其跳转目标地址,Simple-BPU按照指令的定义,使用其PC和立即数表示的offset相加得到其跳转目标地址。
(3)对于无条件间接跳转指令,由于其一定会跳转,因此无须预测其跳转方向,而对于跳转目标地址,指令的跳转目标计算所需的基地址来自于其rs1索引的操作数,需要从通用寄存器组中读取。若通用寄存器索引号为0,则预测为跳转,否则为避免流水线数据冲突,预测为不跳转。

表1 RV32IC架构中的分支跳转指令
对于RISC-V 中“C”压缩指令集,取指模块利用一个32位寄存器用来保存当前的PC值,顺序指令下一个PC 通过当前指令的位宽判断,若当前指令为32 位指令时PC+4,若当前指令为16 位指令时PC+2,分支指令采用分支预测模块得到的跳转地址作为新的PC值。
在流水线的第二阶段,主要完成“译码”“执行”“交付”和“写回”等功能。首先将取指阶段保存在IR 寄存器的指令进行译码。在译码模块进行译码时,根据执行指令的运算单元进行分组,根据指令的低两位判断是16 位指令还是32 位指令,之后根据关键编码字段译出其相应的指示信号,生成立即数和最终的操作数寄存器指引。指令判断代码如下:
wire riscv32=(~(i_instr[4∶2]==3'b111)) &(i_instr[1:0]==2'b11)
对32位load和store指令类型进行译码:
wire riscv32_load=rv32_instr[6∶2]==5'b00000&riscv32
wire riscv32_store=rv32_instr[6∶2]==5'b01000&riscv32
指令经过译码且从寄存器组中读取了操作数之后被派发到不同的运算单元执行。根据指令类型的不同,运算模块主要分为“ALU”“Muldiv”“AGU”。ALU主要负责普通ALU指令(逻辑运算、加减法、移位等指令)的执行;Muldiv 为乘除法计算模块,主要负责乘法和除法指令等M扩展指令集的执行。Muldiv包括一个32位整数乘法器和一个32 位整数除法器。Load、Store 以及“A”扩展指令会被派发到AGU 模块执行,AGU 模块通过存取专用单元LSU访问数据存储模块。
执行阶段的一个重要功能是维护并解决流水线冲突。为了能够检测出长指令(包括load 指令、store 指令以及乘除法等指令)的RAW和WAW相关性,本文加入了一个OITF(Outstanding Instructions Track FIFO)模块,如图3 所示,OITF 本质上是一个深度为4 个表项先入先出的FIFO。在流水线的派遣点,每次派遣一个长指令,则会在OITF中分配一个表项,在这个表项中会存储该长指令的源操作数寄存器索引和结果寄存器索引。在流水线的写回点,每次按顺序写回一个长指令之后,就会将此指令在OITF 中的表项去除,即从其FIFO退出完成任务。
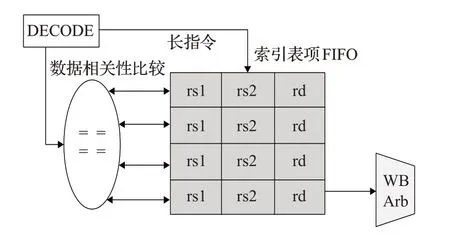
图3 OITF微架构图
在流水线写回阶段,为避免WAW 的数据相关性发生,如果单周期指令和长指令一起写回,多周期指令写回的优先级更高,因为多周期指令一定在单周期指令之前发射。
3.2 总线系统
为了以无缝的方式连接到一些外部IP核,提高系统运行速度和通信吞吐量,本文采用复用性好、扩展性高的标准AHB总线作为内核总线。AHB总线可支持各种处理器、高速设备、片外存储设备等具有高时钟、高性能的模块以及低功耗模块的连接与扩展,具有突发传输、分块处理、单周期总线主机移交、单一时钟沿操作、非三态执行功能等特性[17]。AHB广泛用于高性能、高时钟频率的系统结构。为避免三态总线,AHB 将读写总线分开,写数据总线(HRDATA)用于从master 到slave 的数据传输,读数据总线(HWDATA)用于从slave 到master的数据传输。在传输过程中,AHB 总线传输包括一个地址控制周期和数据周期,数据周期可以通过HREADY信号扩展。如图4所示,对LSU(存取单元)访问BIU(总线控制单元)的地址总线lsu2biu_haddr[31∶0]进行译码,根据不同的地址选择访问不同的外部模块或存储器。

图4 总线地址译码逻辑结构
处理器挂载了一整套典型的MCU外设。内核采用高速AHB 总线,外围采用慢速APB 总线,所以系统在完成数据高效可靠传输的同时兼顾了高性能和低功耗的特性。并且各外设具有AHB 总线接口或APB 总线接口。
系统具有低成本的APB子系统可以访问低频外设的配置寄存器,实现CPU与外围模块的扩展连接,例如WDT、TIMER、UART等模块。如图5所示,CPU作为主设备可以通过AHB 总线访问挂载在AHB 总线上的从设备,包括中断控制、缓存等模块。同时CPU可以通过AHB2APB 总线桥实现对挂载在APB 总线上WDT、UART等外设低速模块的操作。
3.3 哈佛体系结构
传统的冯诺依曼体系结构使用共享的总线和存储单元,无法并行化执行指令和数据访问操作[18-19]。如图6所示本文采用哈佛体系结构,即使用分离的指令和数据存储,通过专用的总线系统分别访问,这样设计既满足CPU并行访问的需求,同时减小了面积。

图5 总线管理系统拓扑图

图6 哈佛结构示意图
使用存取速度较快的一级Cache缓存结构,本文使用分离的Icache 和Dcache 作为缓存单元,大小均为4 KB。与大面积指令或数据紧耦合存储器相比,缓存占用更少的硬件资源。同时设计了两条独立的AHB指令总线和AHB数据总线分别访问Icache和Dcache。
数据和指令的访问可以同时进行。如图7所示,在取指阶段,通过上电引导程序,IFU 通过AHB 总线选择访问Icache 或外部Flash 进行指令的读取。取指完成后,在执行阶段,若是执行load/store 等长指令,则会进入到AGU 中执行,之后LSU 模块通过AHB 总线访问Dcache 模块或外围寄存器进行数据读写。分离的总线使得处理器可以在同一个周期内获得指令字(来自Icache)和操作数(来自Dcache),从而提高了执行速度和数据的吞吐率,减少访存冲突。

图7 读写访问机制
4 仿真与综合
4.1 功能仿真
本文使用硬件描述语言Verilog HDL 将模块功能以代码来实现,形成RTL(寄存器传输级)代码。前仿真使用Synopsys 的VCS 环境进行验证,验证内容包括指令集测试与系统级功能测试。指令集测试方法为汇编级指令自测试程序,该测试程序是由RISC-V 架构开发者为了检测处理器是否符合指令集架构中的定义而编写的测试程序。汇编指令使用宏定义组织成程序点,测试指令集架构中定义的指令。结果表明,RV32IMAC指令集(包括47条基本整数指令、8条整数乘除法指令、11条原子指令以及46条压缩指令)均可测试通过。
系统级功能测试方法为编写C语言基准代码,并使用RISC-V GCC 工具链进行编译。功能测试内容包括AHB 及APB 总线的读写时序仿真、外设功能仿真等。通过对仿真结果的分析,证明该RISC-V 处理器各逻辑功能均可以实现,满足设计要求。
4.2 性能分析
为了对所设计内容的面积和功耗等能效进行评估,对本设计、蜂鸟E203处理器以及Cortex M系列处理器进行了逻辑综合。逻辑综合工具使用Synopsys的Design Compiler,并采用0.11 μmSMIC 工艺技术实现了逻辑综合流程。
综合结果表明,在不包含存储单元的情况下,本文所设计处理器面积比蜂鸟E203 处理器面积减小6%。在包含存储单元面积的情况下,面积比蜂鸟E203 处理器面积减小了89%,主要原因在于本文采用了面积更小的一级缓存结构:蜂鸟E203 使用64 KB 的指令紧耦合存储器和64 KB的数据紧耦合存储器,本设计采用4 KB大小的Icache和Dcache。
如图8 所示为两种处理器在包含存储时各模块面积占比,图(a)蜂鸟E203 处理器中DTCM(数据紧耦合存储器)和ITCM(指令紧耦合存储器)所占比例分别为46.005%。图(b)本设计中Icache 和Dcache 分别占整体面积的26.732%,由图可看出本设计明显降低了存储单元的占比。在嵌入式系统中,存储器关系着整个处理器的性能,缓存单元的设计节约了整体面积,对处理器硬件成本的降低起到了重要作用。
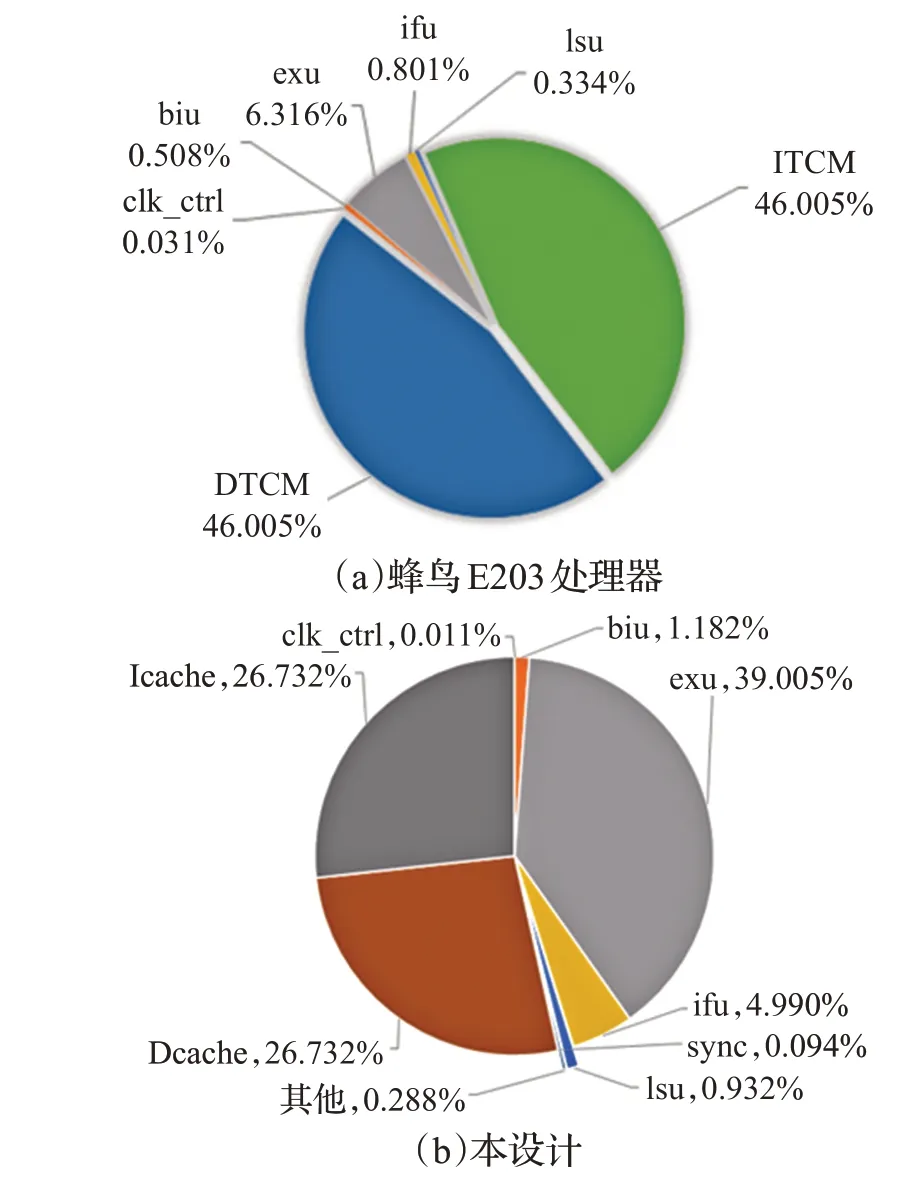
图8 RISC-V处理器核各模块面积占比
如表2 所示,作为通用型MCU,本设计与ARM cortex M 系列处理器在功耗、逻辑门数、跑分等性能方面进行了对比。并对本文所设计处理器与Cortex-M0和 Cortex-M3 处理器以相同的 0.11 μmSMIC 工艺技术,1.08 V电压以及50 MHz的时钟下进行综合。因综合需要设定约束条件和特定的综合库,不同的库中门电路基本标准单元(standard cell)的面积,时序参数是不一样的。Cortex-M0+处理器是在不同的环境下进行综合,因此在功耗、面积上是会有所差异。

表2 本设计与Cortex M系列处理器性能对比
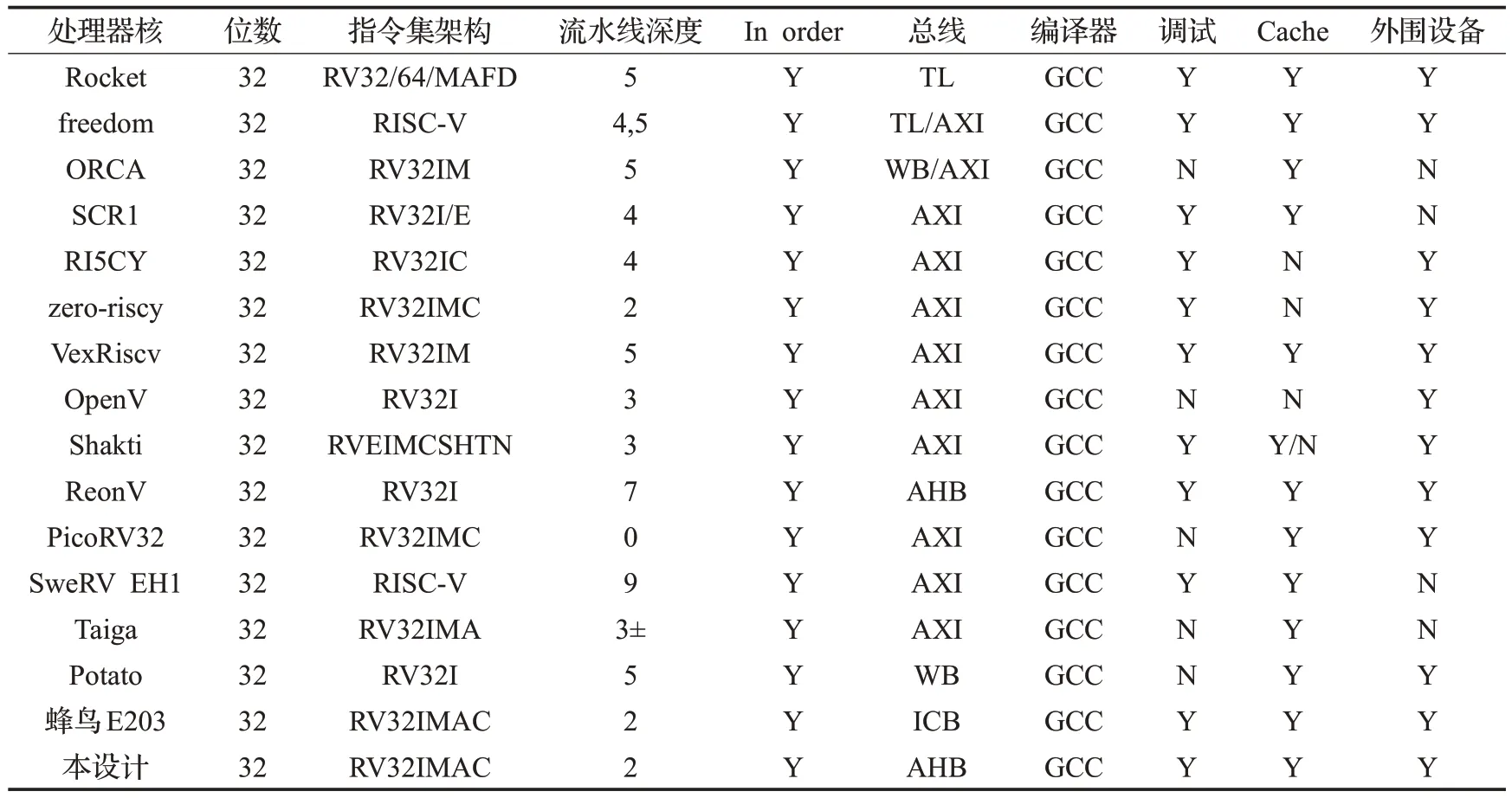
表3 当前开源RISC-V处理器与本设计关键技术对比
在压缩指令方面,ARM使用的Thumb指令集,只有最基本指令的简化版本,可以将某些代码压缩20%~30%左右,但是从标准模式到Thumb模式的切换需要增加代码和时间消耗,代码的运行速度降低约15%[20]。ARM 使用的Thumb-2 指令集虽无须状态切换,但是与标准的ARM 代码相比,需要更多的Thumb-2 指令实现相同的功能,额外的指令会使处理速度降低大约15%~20%。在RISC-V 中大约50%~60%的指令可以用RVC指令代替,代码的大小可以减少约20%~30%,只需要在编译阶段完成,无须状态的切换和额外代码开销[21],因此RISC-V压缩指令执行效率更高。
在面积和功耗等方面,Cortex-M3 处理器包含更多的指令和功能,相对于本设计处理器也具有更大的面积和功耗;本设计包含了乘除法单元,所以在逻辑门数上略高于Cortex-M0 和Cortex-M0+处理器。在功耗和性能上本设计处理器都与Cortex-M0处理器相当。
通过指令、面积和功耗等方面的分析,本文所设计处理器可替代Cortex-M0 处理器用于小面积低功耗等嵌入式领域。
目前开源RISC-V 处理器已发展出众多版本。表3总结了国内外RISC-V开源处理器在架构、流水线、总线等方面的一些技术特点。
5 总结
本文针对嵌入式系统小面积低功耗的设计要求,设计了32位RISC-V微处理器。可支持RISC-V基本整数指令集以及MAC 三个扩展指令集。流水线深度为2级,采用哈佛体系结构,通过独立的AHB总线并行访问指令和数据。验证结果表明该微处理器可实现对外部设备的控制和数据的高速处理。作为通用型MCU,本设计性能测试结果优于Cortex-M0处理器,在同等条件下综合,面积和功耗与Cortex-M0 处理器相当,可替代Cortex-M0用于嵌入式应用中。目前该处理器已应用到基于RISC-V 与Cortex-M0 的双核异构系统中,进行更深入的嵌入式开发研究。
