基于一维卷积神经网络的HTTP慢速DoS攻击检测方法
2020-10-18张美璟许发见
陈 旖,张美璟,许发见
(1.福建警察学院计算机与信息安全管理系,福州 350007;2.福建警察学院网络安全与电子物证研究所,福州 350007)
(*通信作者电子邮箱cy2007126@163.com)
0 引言
针对HTTP 协议的慢速拒绝服务攻击(Slow HTTP Denial of Service,SHDoS)是近年出现的新型攻击手段,原理是攻击者利用HTTP 协议自身的某些缺陷,通过构造畸形报文或低速收发报文,来长期占据服务器连接,达到耗尽服务器连接资源的目的[1-2],最终将导致服务器无法响应正常用户的连接请求,从而实现拒绝服务(Denial of Service,DoS)攻击的效果。
传统的DoS攻击往往需要大量主机和带宽资源来快速地访问服务器,从而耗尽服务器的带宽及运算资源。而新型的SHDoS 攻击仅需要少量的主机,以较低的宽带速率占用服务器的连接资源,即可达到攻击目的。SHDoS 还可以通过分布式方式发起攻击,仅几台主机就能对小型服务器产生显著的攻击效果[3-4]。由于SHDoS 具有实施成本低且效果显著的特点,近年来被频繁用于攻击互联网站点,对网络安全造成了极大的隐患。因此,如何有效地防御SHDoS 攻击是具有实际应用价值的研究课题。
1 相关研究
近年来,随着机器学习技术的发展,越来越多的研究者开始将机器学习方法应用于恶意流量检测问题,其中就包含对DoS流量的检测。
文献[5]中提出一种基于XGBoost(eXtreme Gradient Boosting)算法的检测模型,并在入侵检测数据集KDD-CUP99上进行训练和验证,与决策树、逻辑回归、K最近邻(K-Nearest Neighbor,KNN)等算法相比,具有较高的准确率和召回率。文献[6]中提出一种基于粗糙集属性约简的在线序贯极限学习机(Online Sequential Extreme Learning Machine based on Attributes Reduction,AR-OSELM)方法,该方法先从KDDCUP99 数据集中筛选出无冗余属性的特征集合,再使用AROSELM 算法进行分类,具有较好的泛化能力,误报率较低。文献[7]在完整的网络环境中针对最新的攻击工具及良性访问采集了样本,生成了数据集CICIDS2017,并设计了一种针对数据流的特征分析工具CICFlowMeter。该工具可以从抓包文件中计算出数据流的特征值,其中包含报文发送频率、流传输速率、报文平均长度等数十种量化特征,供分类模型处理。文献[8]在文献[7]的基础上,提出一种基于集成学习的DoS流量检测方法,该方法先对CICFlowMeter 提供的数据流特征进行筛选,再通过随机森林算法构建模型,最后使用CICIDS2017 中的DoS 样本进行训练,取得了较好的效果。文献[9]中提出了一种基于改进遗传算法和模拟退火算法的混合优化框架,用于高效地构建出基于深度神经网络的入侵检测系统。该系统使用CICIDS2017 等数据集进行模拟和验证,具有较高的检测精度和较低的误报率。
上述研究成果各具优势,但也存在一定局限性。主要存在以下问题:1)部分检测方法在SHDoS 攻击频率变化时出现准确率降低的问题。出现该问题有两方面的原因:首先,模型对攻击频率变化的数据流的泛化能力较弱,无法通过对已有样本的学习来对未见过的攻击频率样本进行检测;另外,数据集中SHDoS 数据流的攻击频率是基本固定的,导致训练样本的代表性较弱;2)部分检测方法未清洗无效数据流,导致实际检测中发生误判。由于SHDoS 攻击可使服务器进入拒绝服务的状态,这将导致大量的良性和攻击数据流都处于握手或等待的状态。这些数据流是攻击生效后产生的无效数据流。若未过滤这类样本,将导致模型在实际检测中易对良性主机作出误判;3)部分方法中未对大量高度相似的样本进行去重,导致模型可能出现过拟合。部分方法中使用了数据流的时间及传输速率特征。然而,由于报文的采样时间存在误差,即使完全相同的两个数据流,时间和速率特征也不完全相同。这使得这类方法的训练集和测试集中存在大量高度相似的样本,导致测试集无法准确评估模型的过拟合情况。
例如文献[5-6]使用KDD-CUP99 数据集及文献[7]采集的CICIDS2017 数据集都存在样本在攻击频率方面代表性较弱的问题;文献[8-9]中都未对无效数据流进行清洗,且都未对高度相似的样本去重;在实验中发现,文献[8]模型对未见过的攻击频率样本的检测能力较弱。
在上述研究与分析的基础上,本文提出一种基于一维卷积神经网络(Convolutional Neural Network,CNN)[10-11]的SHDoS 攻击流量检测方法,以解决当前研究中存在的问题。该方法在多种合理的攻击频率下对三种类型的攻击流量进行采样,并从样本中清洗掉无效的数据流;之后,设计了一种数据流转换算法,可将样本转换为一维序列,并进行去重处理;最后,使用一维CNN 构建检测模型,并使用序列样本进行训练。
首先,本文方法借助CNN 算法中卷积计算的特性,使模型能够对训练集中未出现过的攻击频率的样本具有较好的检测能力;并且通过对采样环节的设计,保证了数据样本在不同攻击频率上具有代表性,从而解决了问题1)中攻击频率变化导致的准确率降低的问题。此外,本文方法通过对数据流的处理流程设计,能够有效地清洗无效数据流,并剔除大量高度相似的样本,避免了问题2)和问题3)导致的样本误判和模型过拟合的问题。在独立验证集上的实验结果表明,本文方法可解决攻击频率变化导致的检测准确率降低的问题。
2 方法和模型
2.1 系统建模
2.1.1 应用场景
本文方法典型的应用场景如图1 所示,HTTP 服务器一般部署在内网中,通过出口网关和互联网连接。网关配置镜像端口与防火墙连接,将出入内网的双向报文镜像同步给防火墙。防火墙以旁路部署模式工作。SHDoS防御组件作为防火墙中的功能组件,实时监听HTTP 数据,当发现SHDoS 攻击时,将设置网关转发规则并发送传输控制协议(Transmission Control Protocol,TCP)的RST(ReSeT)报文,来主动屏蔽恶意主机连接,避免攻击占用服务器的连接资源。
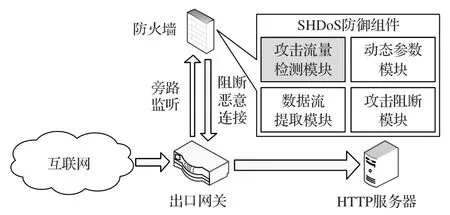
图1 典型应用场景Fig.1 Typical application scenario
如图1 所示,SHDoS 防御组件可分为四个子模块。其中,数据流提取模块用于从镜像的IP 报文中提取TCP 数据流;攻击流量检测模块基于本文方法设计的模型构建,用于对数据流进行SHDoS 攻击检测;攻击阻断模块用于对检出的攻击流和恶意主机进行屏蔽;动态参数模块根据连接负载情况,动态调节检测及滤波参数。
2.1.2 模型训练与应用的过程
本文方法可分为模型训练和模型应用两部分,过程如图2所示。
在本文模型训练的过程中,首先需要搭建网络测试环境,对攻击报文进行采样,再从采样报文中提取出完整的数据流并清洗掉无效数据;之后,使用本文方法设计的转换算法,将数据流转换为一维序列数据,并进行去重;最后,在一维CNN算法构建的模型上,使用序列数据进行训练和验证,最终生成针对SHDoS数据流的检测模型。
在模型应用的过程中,SHDoS 防御组件通过旁路监听获取原始报文,再从报文中动态提取数据流,并转换为一维序列后加入缓冲队列。攻击检测模型从缓冲队列中周期性读取序列并进行攻击检测,进而检测出攻击数据流和恶意主机。
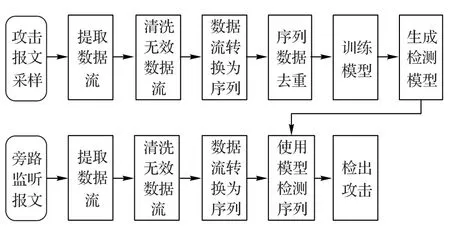
图2 模型训练与应用的过程Fig.2 Model training and application process
2.2 数据处理方法设计
2.2.1 样本标签类别设计
SHDoS攻击通过长期占用服务器的可用连接资源来达到攻击目的,主要包含以下三种攻击方式:1)慢速头部(Slow Header),通过循环发送请求头而不发送结束空行来占用连接;2)慢速发送(Slow Post),通过极低的速率上传数据来占用连接;3)慢速读取(Slow Read),通过设置极小的滑动窗口来限制数据下载速度,从而占用连接。
这三种攻击方式的原理不同,报文结构存在显著的差异,对应的阻断措施也不尽相同。因此,本文方法根据攻击方式的不同,将攻击样本使用三类标签进行标记。
2.2.2 数据流提取与清洗
在采样结束后,还需要从抓包文件中提取出独立的数据流。本文方法使用Python 语言和Scapy 库实现了数据流提取模块。该模块根据TCP协议的三次握手、连接释放、端口分配及系统端口重用等规则,将每个独立的数据流从抓包文件中提取出来,形成以“IP-端口号-时间戳”为唯一标识的数据流样本文件。
在提取数据流完成后,还需要对无效的数据流进行清洗。在SHDoS 攻击过程中,由于HTTP 服务器可能因攻击而进入拒绝服务的状态,导致大量的数据流处于握手或等待的状态,之后又因超时被断开。这类数据流是攻击成功后产生的副产品,一般长度较短,无法反映出正常攻击数据流的特征,需要被过滤掉。
本文方法在清洗数据流时,将从数据流抓包文件中读取IP 报文并进行分析,只有同时满足以下三个条件的数据流才被认为是有效的:1)IP报文中包含合法的TCP三次握手过程;2)至少存在一个由客户端发出的HTTP 请求报文;3)在服务器收到请求报文后,至少发出一个确认请求报文已收到的带有ACK(ACKnowledgment)标志的TCP 报文。该清洗策略有效的原因是,SHDoS 是通过长期占用服务器TCP 连接来达成攻击目的,因此必然存在与服务器握手和双向交互的过程。而无效数据流处于握手或等待响应报文的状态,不能满足上述条件,因此可以根据上述规则来清洗无效数据流。
2.2.3 数据流转换为序列
清洗后得到的有效数据流样本保存在PCAP 格式的抓包文件中,还需要进一步转换为模型能够处理的一维序列数据。本文方法根据攻击报文的特征分析及实验验证的结果,选取了报文方向、负载类型、TCP 报文标志位、报文时间间隔等参数,将PCAP格式的数据流转换为一维序列。
开始转换时,待输出的序列为空,算法将依次读取数据流的每一个TCP 报文:1)算法首先过滤掉握手、挥手等无关报文,并选取数据流中前t秒的报文进行下一步处理;2)算法处理负载非空的报文,根据报文的收发方向、负载内容为HTTP头部或数据,生成负载报文元素加入到序列中;3)算法检查ACK 报文的标志位,根据其滑动窗口是否耗尽来生成控制报文元素加入序列;4)算法将在报文元素间插入时间间隔元素,时间间隔元素的数量为报文元素以秒为单位取整的时间差;5)将序列长度处理为固定值h,对超出的部分截断,对不足的部分补空值。
由于入侵防御系统中,往往存在针对恶意攻击的检测时间指标要求。因此,不同于其他方法使用完整数据流分析,本文方法仅截取数据流固定的前t秒来生成样本序列。另外,由于检测模型的限制,生成的样本序列的长度需为定值h,若h过大则将大大增加模型训练和检测的开销,若h过小则会损失过多的样本特征。在观察样本结构且权衡限制因素的基础上,本文方法选取t为240 s,选取h为300。采样数据流的前240 s样本中仅有9.6%的序列长度超过300。
图3 举例展示了若干个数据流样本经过算法处理后生成的序列结构。对其中的负载报文而言,R和S指报文的收发方向为接收或发送,H 和D 指负载内容为HTTP 头部或数据;对控制报文而言,A 指普通响应报文,Z 指通告滑动窗口耗尽的响应报文;另外,P 指1 s 的时间间隔,N 指序列尾部填充空值。

图3 数据流样本序列示例Fig.3 Examples of data stream sample sequences
2.2.4 样本序列去重
将数据流样本转换为序列之后,还需要对各类别中相同的样本序列进行去重。原始的数据流样本中存在大量高度相似的数据流。这类数据流一般由相同的工具生成,报文结构相似,仅在抓包时间上存在微小的差异。传统基于流速率特征的检测方法难以直接根据速率来对这类相似的数据流进行去重。本文方法在数据流序列化的过程中将时间值处理为以秒为单位的时间片间隔,可直接通过对序列去重,来实现对相似数据流的剔除,避免大量相似数据流样本对模型的泛化能力产生的影响。
2.2.5 数据流转换序列的一般性处理方法
在本文模型训练阶段,对数据流转换序列的过程主要有以下步骤:1)采集攻击样本;2)提取数据流;3)清洗无效数据流;4)转换为一维序列;5)样本序列去重;6)生成训练数据集。在本文模型应用阶段,本文方法对数据流的一般性处理过程和训练阶段相比,在以下步骤中存在差异:步骤1)中,应用阶段直接从网卡中实时抓取报文;步骤5)中,应用阶段无需对样本去重;步骤6)中,应用阶段将直接使用模型检测生成的样本。
2.3 一维卷积神经网络模型
2.3.1 检测算法的分析与设计
本文方法将样本数据流处理为序列后,还需要构建模型来学习攻击数据流的序列特征。目前可对一维序列数据进行分类的常见模型有一维CNN、循环神经网络(Recurrent Neural Network,RNN)[12]、长短期记忆(Long Short-Term Memory,LSTM)网络[13]、双向长短期记忆(Bidirectional LSTM,Bi-LSTM)网络[14]等。
在传统的密集连接型神经网络中,网络节点在输入和输出之间不保存任何状态,这导致该结构在处理自然语言等一维序列时效果不佳。而RNN 则通过在节点中引入内部循环的方式,使得模型对序列元素的前后顺序状态信息具有一定的记忆能力,增强了模型对序列处理的能力。LSTM网络则在RNN 的基础上增加了将状态信息跨越多个元素的方法,解决了RNN 中梯度消失的问题。Bi-LSTM 网络在LSTM 网络的基础上,通过从正序和逆序两个方向对序列进行学习,进一步提高了模型的性能。
不同于RNN这类网络,一维CNN是通过序列的局部模式特征来识别序列。它通过一维卷积核来提取序列的局部片段,进而从片段中学习序列的局部模式[15]。一维CNN 模型从一个片段学习到的局部模式还可以在其他位置的片段中再被使用,这使得模型在处理序列时具有平移不变性,即局部模式在序列整体中的位置发生平移时,并不影响模型的处理结果。
在SHDoS 检测问题中,恶意数据流的攻击频率的可选值众多,但采样工作仅能覆盖部分典型的攻击频率。这就要求模型能够从少数几种攻击频率的样本中学习到攻击序列的特征,从而对其他攻击频率的样本也具备检测能力。对于RNN这类网络而言,模型的记忆能力仅能记住训练样本中出现过的几种攻击频率的特征,而无法拓展到对其他攻击频率样本的检测。然而,对于一维CNN 而言,未知攻击频率的样本序列可以看作是训练集中典型频率样本序列的拓展和平移,这是因为这两类样本虽然攻击频率不同但局部模式依然是相似的。由于一维CNN 具有的平移不变性,使得模型对未知攻击频率的SHDoS 样本依然具有较好的检测能力。因此,本文方法选取一维CNN算法来构建检测模型。
2.3.2 一维CNN模型结构
本文方法使用一维CNN 算法来构造检测模型,结构如图4所示。
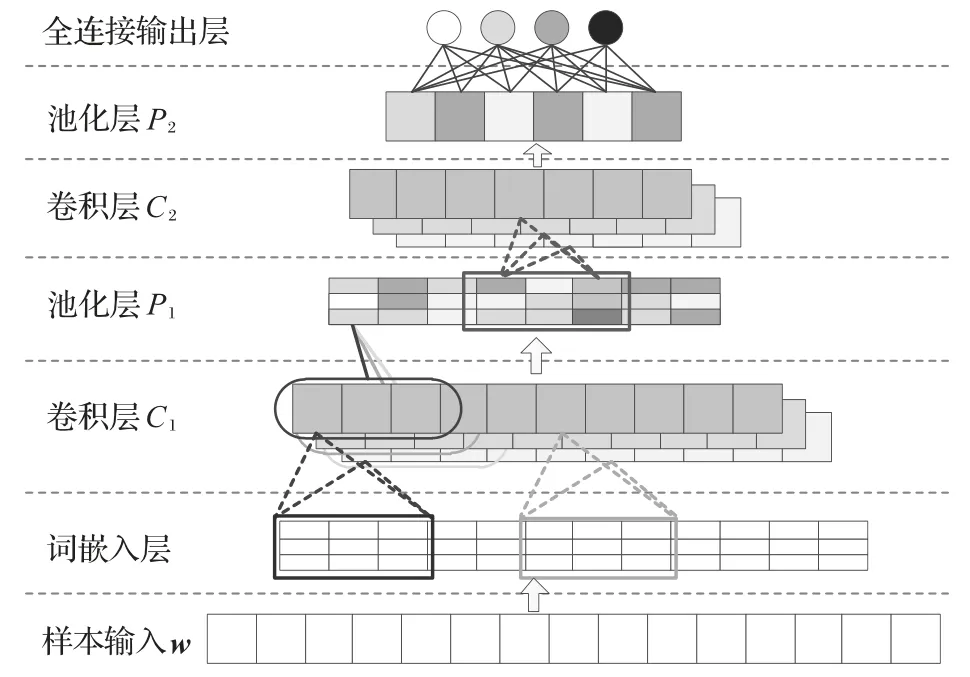
图4 检测模型结构Fig.4 Detection model structure
本文模型包含一个词嵌入层、卷积层C1和C2、池化层P1和P2以及一个全连接输出层。其中,本文模型要求输入数据是一维序列w,w即是数据流生成的序列样本,序列中包含可反映通信过程的报文元素。
由于神经网络模型只能处理数值张量,因此样本输入模型时,需要先使用词嵌入层对w进行向量化。本文模型的词嵌入层用于将序列中的每个元素转换成长度固定的词向量。词嵌入层相当于是一个字典,它可在训练中动态地学习元素的权重值,从而将一个离散元素映射为一组连续值组成的词向量。w经过词嵌入层的转换,可生成一个由词向量组成的矩阵d∈Rhg,其中h为样本序列的长度,g为词向量的维度。
一维卷积层可以对序列中的局部特征进行学习。如图4所示,卷积层工作时,将使用卷积窗口以固定的步长遍历序列,窗口内的元素将与多个卷积核进行点积运算。每个卷积核与整个序列完成运算后,将生成一个新序列,其值反映出输入数据在该卷积核下表现出的特征。数学模型可描述为:

其中:Wc∈Rgp是卷积层C1中n个长度为p的卷积核中的第c个卷积核;di:i+p∈Rpg表示从d的第i行到第(i+p)行之前的每一行数据所组成的子矩阵;b∈R 表示偏置值;f为激活函数;sci是卷积核Wc和第i个子矩阵进行点积的结果。记d中子矩阵的个数为e。将n个卷积核和e个子矩阵运算后,可得到由sci组成的矩阵s∈Ren。
池化层可用于对数据进行下采样,它使用一个长度为q的窗口扫描数据,用窗口内元素的最大值或平均值来代替整个窗口的数据,从而缩短数据的长度。这使得位于下层的卷积层能够从更宽的跨度上观察数据的特征。池化层P1使用最大值池化算法,数学模型可描述为:

其中:sjq:(j+1)q∈Rqn表示从s的第jq行到第(j+1)q行之前的每一行数据所组成的子矩阵,max 函数用于计算子矩阵中每一列的最大值,uj是由子矩阵每一列的最大值所组成的向量。记s中子矩阵的个数为l。将所有子矩阵进行最大池化运算后,可得到由uj组成的矩阵r∈Rln。
卷积层C2重复了卷积层C1的操作。它以矩阵r为输入数据,目的是从更高的跨度上学习序列的特征。使用n个长度为p的卷积核对矩阵r进行卷积运算之后,得到矩阵a。池化层P2和P1的运算过程相似,使用全局最大池化算法,以矩阵每一列的最大值来代表整个列,即在式(2)的基础上,设置窗口长度q的值等于矩阵的行数。矩阵a经过全局最大池化操作后生成全连接层可处理的一维向量z∈Rn,包含了原始输入数据的高阶特征。
全连接输出层用于学习向量z和k种报文类别之间的映射关系。数学模型如式(3)所示,其中v∈Rnk为权重矩阵;B∈Rk为偏置向量,f为激活函数。运算将输出向量y∈Rk,表示原始输入样本归为某种数据流类别的概率。

本文模型使用交叉熵损失作为损失函数,使用均方根传递(Root Mean Square prop,RMSprop)算法作为优化器。本文模型开始训练前,神经网络各层节点的权重值都是随机的。本文模型训练时,使用反向传播算法和小批量梯度下降算法来逐步更新网络的权重值,经过多轮的训练与测试后,选取最优的权重值作为模型的网络参数输出。
2.4 方法的有效性与优势分析
本文方法在设计中有效地解决了当前研究中存在的三个问题:1)本文方法使用一维CNN 算法构建的模型,能够有效地学习到样本序列的局部特征,对局部特征发生平移的样本也具有较好的检测能力。因此,相较于RNN 等网络模型,本文模型在对未知攻击频率样本的检测方面更具优势,可解决攻击频率变化导致的准确率降低的问题。2)本文方法根据协议规则分析,通过报文特征来有效地清洗掉无效数据流。相较于聚类、离群点等异常值检测手段,该方法在计算速度和准确性方面存在明显优势,可避免无效数据流导致的误判问题。3)本文方法在数据流序列化的过程中,通过对时间值的单位量化处理,可将高度相似的数据流处理为完全相同的序列,进而有效地剔除重复数据。相较于选取数据流的多种特征进行相似性判断的方法,该方法的运算量更小且具有较好的去重效果,可避免大量高度相似的样本导致的过拟合问题。
3 实验与结果分析
3.1 实验数据采样与处理
3.1.1 实验环境搭建与采样
在样本采集环境中,存在一台运行Ubuntu Server 系统的服务器作为靶机,一台运行Kali 系统的通用计算机作为攻击机。其中,靶机运行Apache 作为HTTP 服务器,使用DWVA(Damn Vulnerable Web App)作为被攻击页面,使用TCPDump工具生成抓包文件;攻击机上选取SlowHTTPTest 等工具进行攻击。
进行采样时,在攻击模式上,测试环境中分别使用了慢速头部、慢速发送、慢速读取三种不同的攻击模式;在攻击报文的发送周期上,由于过长的通信周期将导致服务器主动关闭超时连接,故在60 s 的范围内分别使用了6 种不同时间值作为报文发送或读取的周期进行采样;在报文负载上,使用随机值作为攻击报文的负载长度。对每种攻击模式和攻击周期值的组合采样1 h。另外,使用CICIDS2017 中的正常HTTP 数据流作为良性样本数据。本文方法在不同的攻击模式和频率下进行采样,可保证样本在不同攻击频率上具有代表性。
3.1.2 样本处理与统计
采集的样本还需要进行一系列的处理,其中包含:数据流提取、清洗无效数据流、转换为一维序列、样本序列去重,进而生成数据集。其中,样本数量的统计情况如表1所示。

表1 数据集样本类别统计情况Tab.1 Statistics of dataset sample categories
从表1 可以看出,从原始样本中提取的数据流中包含大量的无效数据流,平均占比达到55.2%。而有效数据流中也包含大量高度相似的数据流,平均重复占比约为83.5%。从样本统计情况中可以看出,本文方法可有效地清洗无效数据流并对高度相似样本进行去重,从而避免了无效和重复数据导致的样本误判和模型过拟合的问题。
3.2 实验评价指标
实验使用准确率acc(accuracy)和精确率pre(precision)作为模型的评估指标。各类模型对x标签类别的分类准确率和精确率的计算公式为:
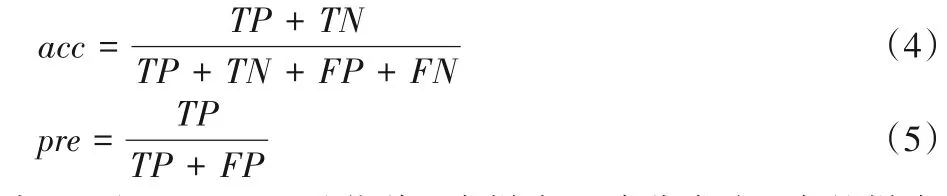
其中:TP(True Positive)指将x类样本正确分类为x类的样本数量;TN(True Negative)指将非x类样本正确分类为非x类的样本数量;FN(False Negative)指将x类样本漏判,误分类为非x类的样本数量;FP(False Positive)指将非x类样本误判,误分类为x类别的样本数量。实验中,使用宏平均(macro-average)的方法来评估多分类器的性能,即迭代地将各类样本视为x类,逐个类别计算准确率或精确率后,取均值作为该分类器的性能。
准确率是模型分类正确的样本数在总样本数中的占比,可反映出模型对各类数据流总体的检测能力;精确率是在所有被检测为x类的样本中,实际确实为x类样本的占比,可反映出模型对样本的误判情况。在本场景中,较高的精确率意味着较少出现良性数据流被误判为攻击的情况,可减少误报对网络正常功能的影响。因此,精确率在本场景中也具有一定的参考价值。另外,实验还使用误报率和漏报率来评估模型对样本误判的情况,其中误报率(False Positive Rate,FPR)和漏报率(False Negative Rate,FNR)的计算公式如式(6)~(7)所示:

3.3 模型参数设置
3.3.1 参数设定
通过多轮的参数设计和对比实验,本文方法设计的模型结构如表2 所示。其中,本文模型的输入为数据流生成的一维序列,长度为300;输出是样本属于某种数据流的概率,存在4种类型。

表2 一维CNN模型参数设定Tab.2 Setting of one-dimensional CNN model parameters
3.3.2 模型结构设计
在一维CNN 模型结构中,卷积与池化层的组数、卷积核的长度及卷积核的个数,都对模型的检测能力有着较大的影响。为了提高本文模型的性能,设计了三组实验来选取最佳的模型结构。实验使用本文采样并转换后生成的一维序列样本数据集,其中包含2 073 个慢速头部样本、3 176 个慢速发送样本、2 473个慢速读取样本及14 341个良性样本,共4种标签类型。攻击样本按3 种攻击类型和6 种攻击频率分成18 组,良性样本单列一组,从每组随机抽取90%的样本合并成训练集,其余部分作为测试集。
第一组实验用于选取卷积与池化层的组数,实验分别将组数设置为1~3 组后训练本文模型,通过比较各组模型的性能来选取最佳的组数配置,结果如表3 所示。其中,组数为2的模型在准确率和精确率上都要高于其他两组模型,故本文方法使用两组卷积与池化层来构建模型。
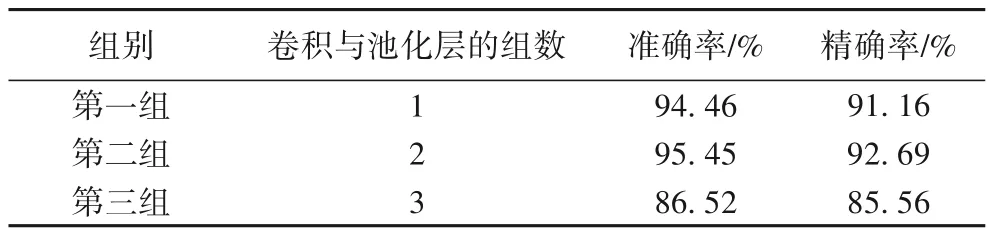
表3 不同卷积与池化层层数下本文模型的准确率和精确率对比Tab.3 Accuracy and precision comparison of proposed model with different convolution and pooling layers
第二组实验用于选取一维卷积核的长度。分析序列样本的生成规则可知,一次报文交互往往包含一对载荷、响应报文,进而生成5~6个序列元素。根据卷积计算的特性,预计卷积核的长度与一次报文交互生成的元素长度相近时,模型能更好地学习到报文序列的特征。因此,实验分别将卷积核长度设置为1~10 后训练本文模型,结果如图5 所示。从图5 中可以看出,当卷积核长度为6 或8 时,模型的准确率和精确率指标都处于较高的水平。考虑到较短的卷积核长度能降低模型的训练开销,故本文方法使用长度为6 的卷积核构建模型。
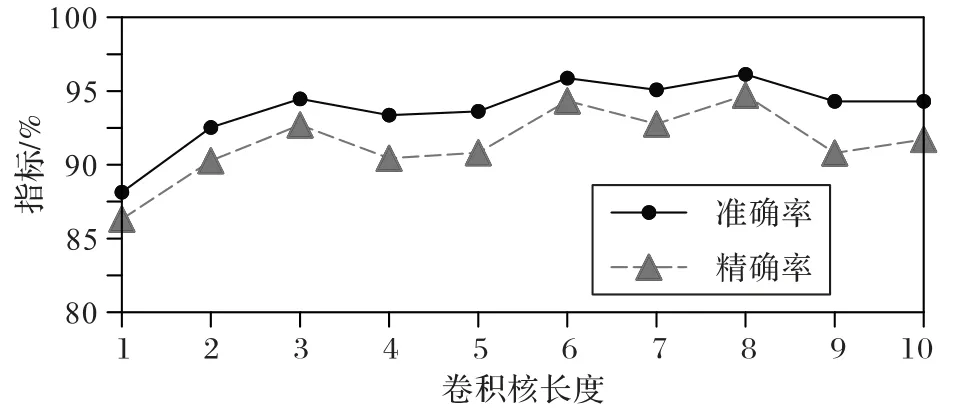
图5 不同卷积核长度下本文模型的准确率和精确率对比Fig.5 Accuracy and precision comparison of proposed model with different convolution kernel lengths
第三组实验用于选取一维卷积核的数量。一般来说,卷积核的数量越多则模型的学习能力越强,但数量过多时易导致过拟合,且增加了模型的训练开销。因此,实验分别将卷积核的数量设置为2~60 内的偶数来训练模型,性能变化的拟合曲线如图6 所示。从曲线的变化趋势可以看出,在横轴值为34 的点之前,模型的性能基本随着卷积核数量的增加而上升;在该点之后,模型的性能基本不再明显上升;在该点上,模型的准确率和精确率都达到了较高的水平,故本文方法将卷积核数量设置为34来构建模型。
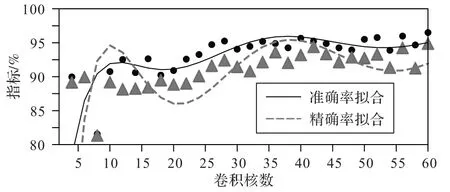
图6 不同卷积核数量下本文模型的准确率和精确率对比Fig.6 Accuracy and precision comparison of proposed model with different numbers of convolution kernels
3.4 多种模型的性能比较分析
为检验本文模型的检测性能,设计了实验将其与RNN、LSTM、Bi-LSTM等几种常见的序列分类模型进行对比。
实验使用本文采样并转换后生成的一维序列样本数据集。使用10折交叉验证法生成10组训练和测试集,即将数据集分为10 组,每次取9 组作为训练集,取1 组作为测试集,共对模型测试10 次。测试时,每次训练最大迭代次数为20 轮,训练批量大小为128。从20轮迭代中选取结果最优的模型数据作为本次测试的性能数据。当10组测试都完成后,以10组测试数据的均值来评估模型的性能。实验结果如表4所示。
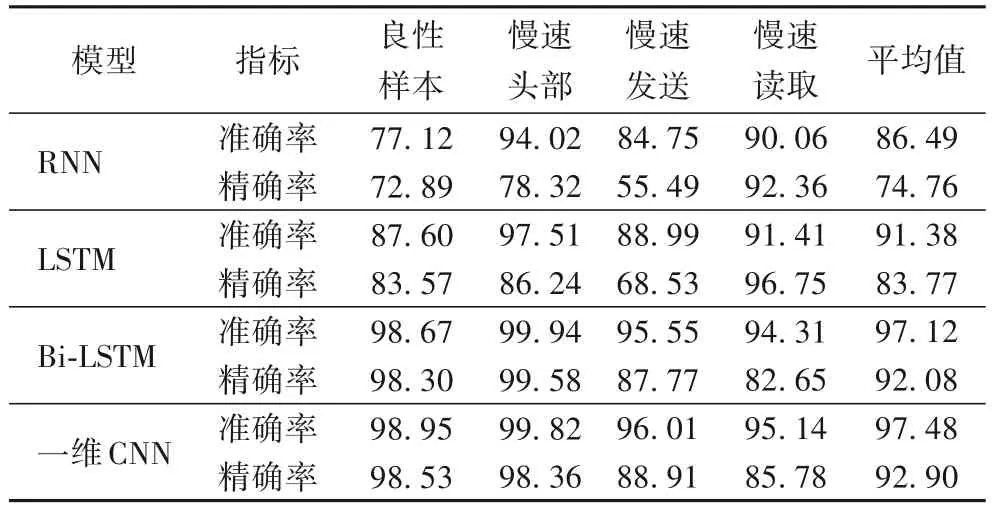
表4 不同模型对各类样本的检测准确率和精确率对比 单位:%Tab.4 Detection accuracy and precision comparison of different models for various samples unit:%
结合表4 的数据可以看出,本文模型在检测准确率和精确率上都略高于Bi-LSTM 模型,且明显优于RNN 和LSTM 模型。该结果说明,在SHDoS 攻击检测的场景中,本文模型对攻击生成的序列样本具有较好的检测能力,相较于其他方法更具优势。
3.5 对其他频率样本的检测性能分析
为解决攻击频率变化导致模型检测性能降低的问题,本文模型在对少数几种攻击频率样本进行学习后,应能够对其他未知攻击频率的样本也具有较好的检测能力。为评估本文模型对未知攻击频率样本的泛化能力,本组实验采集了独立的验证集,并对本文模型、LSTM及Bi-LSTM模型进行了测试。
在生成验证集时,实验分别采集了攻击周期为1~60 s 的60组攻击数据流,每组数据流包含3种攻击模式,每种攻击模式采样5 min。为了和实际检验过程保持一致,验证集的数据流在生成序列样本时不进行去重处理。实验将采集的良性样本分别与60 组攻击样本组合成60 组验证集,每组都包含4 种标签类型。平均每组验证集包含有1 481个攻击样本,并加入了同等数量的良性样本。
实验分别将60 组包含不同攻击频率样本的验证集输入各模型,并统计其检测性能的变化情况。结果如图7 所示,其中横轴上的每个点对应一组验证集,图中的折线反映了各模型在不同验证集上的检测准确率和精确率的变化情况。从图7 中可以直观地看出,相较于其他模型,本文模型性能变化的折线更加平稳,在不同组别的验证集上基本都保持了相近的准确率和精确率。
表5 统计了各模型在所有验证集上取得的准确率和精确率的方差、标准差及平均值。从表5 的标准差和方差值也可以看出,在攻击频率变化时,本文模型性能的变化是最小的,平均准确率和精确率分别达到了96.76%和94.13%。
实验使用独立验证集来评估本文模型在样本误报和漏报方面的性能,误报率和漏报率分别为2.24%和8.49%,都处于较低的水平。此外,由于SHDoS 攻击主机需要同时维持多条连接才能达成攻击目的,因此防御系统还可以通过统计被检出的攻击数据流在固定时间段内是否超过阈值的策略,进一步降低系统对攻击主机的误判率和漏报率。
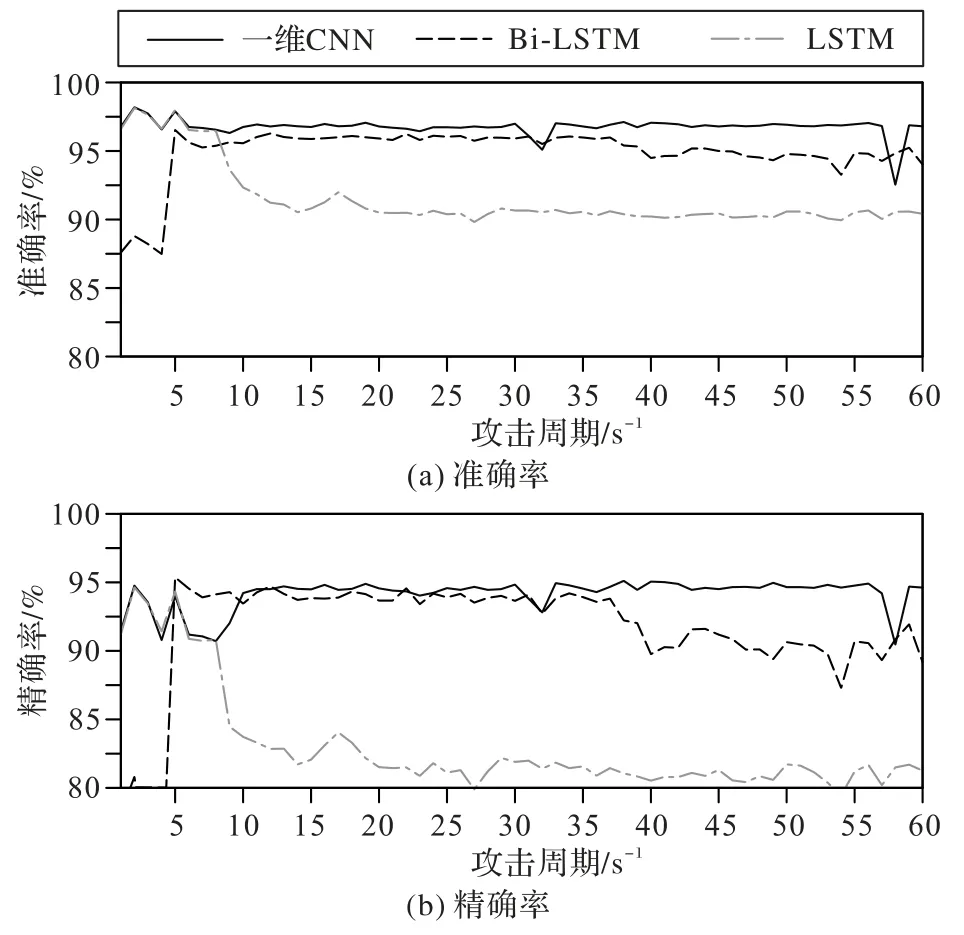
图7 在验证集上各模型的准确率和精确率对比Fig.7 Accuracy and precision comparison of different models on validation sets
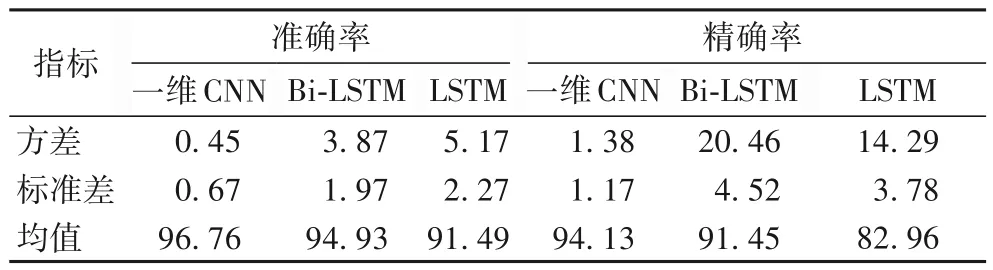
表5 不同模型在所有验证集上的准确率和精确率的方差、标准差及均值 单位:%Tab.5 Variance,standard deviation and mean of accuracy and precision of different models on all validation sets unit:%
实验结果表明,本文模型能够对其他未知攻击频率的样本具有较好的检测能力,能够解决攻击频率变化导致模型检测性能降低的问题。
4 结语
本文针对SHDoS 攻击流量检测在攻击频率变化时出现准确率降低的问题,提出了一种基于一维CNN 的SHDoS 攻击流量检测方法。通过对SHDoS 攻击原理和报文的分析,本文方法在多种攻击频率下对三种模式的攻击流量进行采样,保证了数据样本在攻击频率上具有代表性。之后,本文方法还对样本进行清洗,避免访问失败的无效数据流混入样本,导致模型学习到错误的特征。另外,本文方法通过数据流的序列化算法和序列去重操作,有效地将高度相似数据流进行去重,避免训练集和测试集中出现基本相同的样本,导致模型出现过拟合的现象。最后,本文方法使用一维CNN 构建的分类器有效地学习到攻击流量的序列特征,并对验证集中未见过的攻击频率样本具有较好检测能力,取得了较高的检测准确率和精确率。通过以上设计,本文方法能够解决攻击报文收发频率变化导致的检测准确率降低的问题,可满足对不同攻击频率的SHDoS流量进行检测的需求。
