深度神经网络的仿生矩阵约简与量化方法
2020-10-18朱倩倩
朱倩倩,刘 渊,李 甫
(1.江南大学人工智能与计算机学院,江苏无锡 214122;2.江苏省媒体设计与软件技术重点实验室(江南大学),江苏无锡 214122;3.无锡量子云数字新媒体科技有限公司,江苏无锡 214122)
(*通信作者电子邮箱2848500799@qq.com)
0 引言
在计算机视觉领域中,目标检测[1]依旧是一个活跃的研究方向[2]。随着深度神经网络对存储和计算需求的不断增长,给嵌入式/移动端设备的部署带来了挑战,网络模型压缩和加速的研究成为了深度学习领域的重要研究任务[3]。在过去几十年内,计算机性能得到大幅增长,但随着深度学习的发展、神经网络性能要求的不断提高,伴随着神经网络的参数量越来越大,需要更高的计算力[4],而高存储量和计算力这两个条件大大限制了人工智能(Artificial Intelligence,AI)在终端设备的使用,因为终端设备缺乏足够的存储空间以及较高要求的计算力[5]。但实际上深度神经网络(Deep Neural Network,DNN)中权重参数的重要性和必要性[6]是各异的。神经网络是以生物神经网络为技术原型,以研究智能机理的实现[7]。因此本文从生物神经网络的角度来探索和发现深度神经网络中对目标识别所起到真正作用的参数信息。
文献[8]指出在生物神经学科的研究中发现,人眼处理图像数据时,眼睛所接受的视觉信息传达到大脑时,两者之间所连接的神经元数量其实很少,这些少量连接的神经元对于图像的传输是远远不够的,而我们的大脑就要在这少量神经元的情况下看清世界[8]。卷积神经网络和人眼在处理图像数据时采用的原理有着相似之处,共同之处就在于它们都简化了图像与处理过程之间的神经元的连接。本文受到人眼与大脑之间的少量神经元连接处理图像的启发,研究了一种在神经网络模型中对已有的大量参数进行简化的方法,该方法首先通过聚类算法找出具有主要信息价值的权重参数,然后仿照网络动力学[9]中振荡网络的周期性变化原理对近似的权重矩阵进行重构得到近似模型,在保证模型测试准确度的同时可以有效缩小模型所占存储空间。
已知神经网络目前在嵌入式设备上部署所存在的限制主要有两方面:存储和计算力。围绕这两大问题,已有的压缩方法主要有四种:
1)基于参数剪枝和共享的方法。该方法主要应用在卷积层和全连接层,能减少对网络性能不敏感的冗余参数。
该类方法可再细分为量化[10]和二值化[11]、参数剪枝[12]和共享以及结构化矩阵[13]三种子方法。其中量化和二值化主要通过减少深度网络中表示每位权重所需的比特数来压缩原始网络。对于参数剪枝和共享方法,早期的偏差权重衰减方法就属于该类方法,目前该方法的发展趋势是在预先训练的深度神经网络模型中修剪冗余的、无信息的权重[14],在大多的深度神经网络中虽然存在大量的参数,但有很多的参数并不是重要的,真正起作用的往往只有少数参数。在神经网络结构中,全连接层往往是内存消耗的瓶颈[15],针对这一问题结构化矩阵方法被提出,神经网络的层通过非线性变换使得m-n阶稠密矩阵只需要更少的参数来描述[6],该结构通过快速的矩阵向量乘法和梯度运算,不仅降低内存开销,还大大加快了推理和训练的速度,但在如何找到一个合适的结构矩阵等方面还存在一些困难[16]。
2)基于低秩分解和稀疏的方法。该方法也应用于卷积层和全连接层,是利用矩阵/张量分解来估计信息参数的方法。
在深度神经网络中卷积层占据了大部分的计算量,因此减少卷积层可以有效地提高压缩率和整体的速度,已有的方法是采用低秩近似将稠密矩阵由若干小规模矩阵近似重构[17]。另一种针对全连接层权重的方法是使用矩阵分解来降低权重矩阵参数,如奇异值分解重构权重。当前的低秩近似是针对各层进行的,不能执行全局参数压缩,因为不同的层包含的信息各不相同,且与原模型相比,因式分解需要大量的模型再训练达到收敛,因为涉及分解操作,需要有大计算力的支撑。
3)基于迁移/紧凑卷积滤波器的方法。不同于前两种方法,基于迁移/紧凑卷积滤波器的方法[15]只适用于卷积层使用,用迁移卷积层对CNN 模型压缩受到Cohen 的等变群论的启发,即将输入先进行矩阵变换再送至网络或层得到的结果与先将输入映射到网络再变换映射后得到的表征结果一致。使用紧凑的卷积滤波器可以直接降低计算成本,但此方法对处理广泛/平坦的网络(如VGGNet)比较有效。
4)基于知识蒸馏(Knowledge Distillation,KD)的方法。原有的知识迁移(Knowledge Transfer,KT)[11,17]压缩模型是训练一个带有伪数据标记的强分类器的压缩/集成模型,并复制了原始较大网络的输出结果,但是这仅限于浅层模型。知识蒸馏[18]是采用知识迁移思想将深度较广的网络压缩为较浅的网络,它的压缩模型是模仿复杂模型学习的函数。设计思路是将大模型神经网络(教师网络)学习出来的知识作为先验,再将先验知识迁移到小规模的神经网络中训练更小但性能仍较好的小型神经网络(学生网络)。基于知识蒸馏的方法可以使模型更薄,并显著降低计算成本。本文方法对全连接层比较有效。
本文在以上工作的基础之上,结合当前的研究进展和成果,提出模型参数结合生物神经模型原理进行重构模型的方法,从而对神经网络模型进行压缩。首先通过k-means算法对模型去重后的权重参数作聚类;然后对权重参数的聚类结果进行参数重构,使其适应模型框架;最后对重构模型做压缩,从而实现对模型作整体压缩的目的。
1 模型重构
本文基于Darknet 框架[19-21]对Darknet19、ResNet18、ResNet50 以及YOLOv3 这四种模型进行权重重构。首先提取预先训练的DNN 模型权重参数,然后通过octave 软件进行仿真实验,对权重进行去重,并根据k-means算法进行权重聚类,接着根据每一类的聚类质心将同一类的权重都替换为所属类的质心值,最后在所在簇的质心值基础上添加随机数,达到重构模型的目的。模型重构的方法框架如图1所示。

图1 模型重构框架Fig.1 Framework of model reconstruction
1.1 参数聚类
1.1.1 权重参数提取
DNN 中的参数有很多,对于每一层只需要提取对应的权重参数并写入文件,对网络模型中各层参数进行重构。如图2 显示的是Darknet19 模型中权重参数的分布直方图,可以明显看出模型中的权重参数大部分分布在0 附近,权重数值较大的只占少数,整体分布呈现正态分布。
1.1.2 权重聚类
在预先训练的模型中提取权重参数后,对提取的权重参数进行去重,并记录原模型权重参数中重复参数的位置,对重复的权值设置一个标量值mask 进行位置标记;再对去重后的权重作k-means聚类来识别已训练的模型中的近似权重,以使得所有在同一簇中的权重可以共享相同的权值。近似权重可以实现跨层共享。将原始权重W分为k个簇,从而最小化类内平方误差和(within-cluster Sum of Squares Error,SSE):

其中:μ(j)表示属于第j簇的参数质心值;x(i)是属于当前聚类中的各个权值。

图2 权重参数分布直方图Fig.2 Histogram of weight parameter distribution
1.2 参数重构
在达尔文理论中提到,进化是一种机体经过自然选择强化后所产生的微小改变的结果,在自然选择的过程中,具有优势特性的有机体则更有希望生存并繁衍,也自然而然会淘汰那些相对劣势的有机体。纵观生物发展起源,当前所有的生物其实都是由早期极少数或者某种微生物发展而来,在生物的发展过程中也并非一成不变,总会依据不同的生存条件产生新的物种。遗传算法表示进化初始阶段通过随机的形式实现,以增加物种多样性。生物多样性的存在与稳定发展对所有生物包括人类的生存都具有重要意义,这是维持生态系统平衡发展的一个重要的因素。综上所述可知,物种的发展起源于某种微生物,经过不受控制的、随机的发展过程,从而衍生出整个生态系统,在发展的过程中遵循“物竞天择,适者生存”的进化原理。
生物学的发展原理为现有的神经网络模型提供了相关的理论基础。基于生物学原理中“物竞天择”“渐进进化”的基本原理,本文针对具有一定准确率预测的现有模型,即具有一定的生存能力,根据生物进化的理念,对现有模型的参数进行挑选,通过聚类挑选出最具有代表性的、有价值的参数,再利用随机数对这些重要的参数进行优化。
经过聚类后的权重信息,对于属于同一簇中的参数共享权重,在每一位共享权重的基础上再添加微扰值δ,可表示为:

其中:rand()表示为均匀分布产生的随机数;var代表各类中权值方差之和的平均值。基于选出的核心参数结合随机数生成更具多样性的参数值,在多样性的前提下才更有机会获得更优的参数,以实现对现有模型进行参数优化。依据遗传算法对每一代种群基于适应度随机选择不同个体产生新种群的过程,在参数优化的过程中,最终只保留优于1 的阳性结果,以此增强参数的优化效果。如式(2)所示,当微扰δ只使用均匀分布产生的随机数时容易使权值掉入局部最优,对于权值收敛也会花费更多的时间。为解决这一问题,在均匀分布的随机数基础上添加方差均值,好处在于使权值参数在幅度上有所变化,在权值参数浮动比较大的地方δ值较大,以此增加权值跳出局部最优的可能,对于权值浮动较小的地方,则加速收敛。此外,式(2)中的rand随机数随着聚类平均值的变化而变化,因此其方向的变化幅度也随着优化局部数值而变化,一定程度上避免了掉进局部最优。权重重构所采用的公式可表示为:

其中:W(i)表示属于第i类中重构后得到的权重;W(k)代表对应类中的质心值。设模型的权重为W(i),k-means 聚类后的权重质心为W(k),在此基础上增加微扰δ,得到重构权值信息。对于同一模型,每次重构的结果并不唯一,且或许并非每次重构模型的测试准确度总是绝对的。从生物神经学的角度讲,这更符合人的行为学,也模拟了人脑的思维方式,如同对于同一问题不同人脑的思维反应必然存在快慢之分,给出的答案也存在差异,这也正符合了类脑研究的理论,该理论认为通过认知、经验得知问题的结论,结果未必一定正确,但更符合正常人的思维判断。本文遵循的类脑思想,不同于主张以统计和先验知识为前提的贝叶斯方法,贝叶斯方法每次总是致力于寻找最正确的判断,但发现新概率的难度很大。以生物神经网络为原型的神经网络在进行权重取值时可以仿照生物神经网络中的取值原理,在文献[7]中提出基于生物神经网络中神经元之间进行信息传递时突触权值的计算方法,公式如下:

式(4)中的突触权值处于网络振荡的模型中,神经元的活动呈现周期性和振荡性模式,网络振荡通常产生于细胞的兴奋性和抑制性种群的动态相互作用中,抑制作用产生的影响要更为重要。式(4)中的参数ω决定移动的突起的传播速度,相当于网络中单个神经元的振荡频率。
本文研究对神经网络模型进行重构。通过k-means 聚类将近似大小的权重值归为一类,属于同一类中的权值替换为当前类中的质心数值,并添加一个微扰值δ,通过质心值与微扰值的相加重构模型,使用公式如(3)所示。参数重构的过程如图3所示。
1.3 重构模型稳定性分析
重构模型的稳定性验证可以通过实验的累计误差error验证,即每一次实验的误差之和再取平均,得到模型的累计误差,累计误差值收敛于某一具体值即可判断当前模型的稳定性。累计误差的公式可表示为:

其中:n表示实验次数;errori表示每次实验计算得到的误差值;error为n次实验的误差和均值。
2 实验与结果分析
本文所使用的实验设备是基于ubuntu16.04操作系统,采用Intel Xeon CPU E5-1603 v3@ 2.80 GHz×4 处理器,8 GB 内存,500 GB 硬盘,在octave 环境下进行仿真实验,在Visual Studio Code 环境下使用Darknet 框架实现模型准确度和稳定性验证。
本文分别对Darknet19、ResNet18、ResNet50 以及YOLOv3这四种模型进行参数重构实验:前三种模型在ImageNet 数据集上对得到的重构模型进行图像分类准确度验证,YOLOv3重构模型在COCO 数据集上进行目标检测准确度验证。重构后模型的网络存储节省了1/4~1/3的存储空间,而几乎不损失准确度。
2.1 模型压缩结果与分析
对四种模型重构后的准确度测试及稳定性进行验证,各模型分别进行17 次测试实验,结果如图4~5 所示(Baseline 和Reconstruct2 后的数字分别表示原模型的模型参数量和模型重构后的参数量)。

图3 权重共享(上)和加随机数微调的权重(下)Fig.3 Weight sharing(top)and fine-tuning weights with random numbers(bottom)
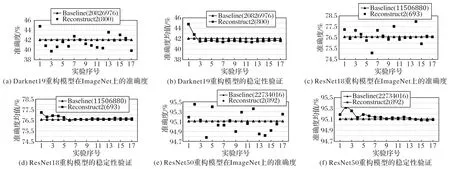
图4 重构模型在ImageNet数据集上的准确度及稳定性验证Fig.4 Validation of accuracy and stability of reconstructed model on ImageNet dataset
根据实验结果得知,四种重构模型经过几次实验后准确度都向基线模型的准确度收敛,逐渐趋于稳定,并且模型重构误差不超1%。大数定律表明,在重复实验过程中,随着实验次数的增加,事件发生的频率会趋于一个稳定值,这反映了一些随机事件的均值在发展过程中具有长期稳定性。本文算法通过对现有模型参数添加随机数进行重构,从实验结果可以看出,对现有模型重构后随着模型重构实验次数的增加,重构模型的准确度趋向于一个稳定值,这正符合大数定律的规律。图4(b)、(d)、(f)以及图5(b)的实验结果也表明了在重构模型多次实验后,重构的累计误差是收敛的,验证了重构模型的稳定性,验证了本文方法的有效性。
2.2 重构前后模型的准确度和压缩比对比
表1 是Darknet19、ResNet18、ResNet50 以及YOLOv3 这四种模型与其对应重构模型前后准确度以及所占存储空间大小的对比,其中各重构模型的压缩比均取自其17 次实验的压缩比均值。从表1 可以看出,四种重构后的模型的存储空间为原模型存储空间的1/4~1/3,同时还提升了1%~3%的准确度,在模型参数重构的同时,大大降低了模型参数的复杂度,模型参数中自由度的降低为之后更大程度地简化网络带来了可能。
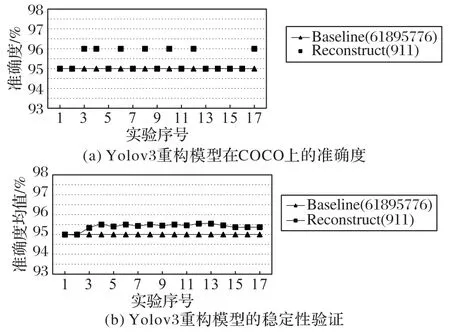
图5 重构模型在COCO数据集上的准确度及稳定性验证Fig.5 Validation of accuracy and stability of reconstructed model on COCO dataset

表1 四种模型重构前后的准确率和存储代价对比Tab.1 Comparison of accuracy and storage cost of four models before and after reconstruction
3 结语
针对深度神经网络模型占据存储空间大、参数冗余的问题,本文模仿生物神经的网络结构,从模型的权重参数角度,基于“进化”+“随机”+“选择”的原理对现有模型参数进行优化,通过对神经网络中的权重参数添加随机微扰进行模型重构,降低模型占据终端设备的存储空间。实验结果表明,这种重构方法可以有效地减少参数存储空间,并保证模型准确度的稳定性;实验结果也验证本文方法在理论上的合理性以及在模型压缩的有效性。在今后的工作中,为实现压缩模型在已有设备上的加速效果,需要进一步对重构模型中的参数做合并,从而生成一个更小、更快的模型,进一步提高重构模型的性能。
