基于生成对抗网络的系统日志级异常检测算法
2020-10-18白宇轩殷俊杰
夏 彬,白宇轩,殷俊杰
(1.南京邮电大学计算机学院、软件学院、网络空间安全学院,南京 210023;2.江苏省大数据安全与智能处理重点实验室(南京邮电大学),南京 210023;3.中兴通讯股份有限公司,南京 210012)
(*通信作者电子邮箱junjieyin112358@163.com)
0 引言
互联网行业中大规模信息管理系统的兴起使得系统管理员在面对系统故障等问题时面临巨大的压力。越是规模庞大的系统就越是拥有复杂的结构,而面对复杂的系统想要查看日志并定位异常事件是一件极其困难的任务。因此越来越多的大规模信息管理系统寄希望于人工智能,而自动化智能运维就是解决这一问题的有效途径之一。
目前人工智能的应用在各行各业中兴起,但是仍然只有少量的研究被应用于智能运维中。基于系统日志的异常检测算法研究也十分有限。由于大规模系统的复杂性使得系统日志的并发性与依赖也变得十分难以估计,因此传统的异常检测算法致力于将大规模系统日志在离线状态下,通过对一段时间内事件的发生频率和关系离线地判断系统的异常。将这种离线状态下对一段时间内的异常日志分析称之为会话级的异常检测。这种异常检测虽然拥有更多的上下文信息用于判断异常,然而在实际应用过程中,系统崩溃和宕机是一瞬间的事情。因此,需要根据大规模系统按照时序产生的日志信息进行分析。即将传统的会话级异常检测算法转换为日志级的序列化异常检测算法,使得每当有新的日志到达时,可以根据前序的日志信息快速给出当前日志为正常或是异常的判断,有效在系统故障发生前侦测到异常并防止其发生。
为了解决大规模系统在线日志级异常检测任务,本文提出了一种基于生成对抗网络的系统日志级异常检测算法。该算法采用了生成对抗网络结构的模型,该模型包括一个生成模型与一个判别模型,其中生成模型用于拟合真实样本的分布,生成的样本可以使判别模型无法分辨该样本来源于真实样本还是生成的样本。这种对抗学习的模式可以使得该模型尽可能拟合正常与异常事件分布,可以有效解决异常事件样本稀疏的问题。此外,在生成和判别模型中,采用了基于循环神经网络(Recurrent Neural Network,RNN)结构的长短时记忆(Long Short-Term Memory,LSTM)网络与门控循环单元(Gated Recurrent Unit,GRU)网络用于拟合序列化的事件模式,是一种有效处理流日志数据的方式。基于序列化的事件模式可以有效随着流日志的抵达实时对下一时刻抵达事件是否异常进行判断。此外,在提出的生成与判别模型中应用了注意力机制,使得模型基于当前事件模式下预测后续事件发生分布时拥有更好的效果。
1 相关工作
1.1 系统日志
本文旨在提出一种面向系统日志的异常检测算法,然而系统日志的复杂性为这一任务带来了巨大的挑战。因此,为了能够在异常日志检测任务中充分利用系统日志所带来的信息,需要首先来了解一下什么是系统日志。系统日志是由监控系统基于程序代码预设条件下自动产生的富含大量描述系统(如分布式系统、操作系统)状态信息的事件集合。系统日志拥有以下特点:1)结构极其复杂,几乎没有两条系统日志是一致的;2)系统日志的高并发性使得很难判断哪一条日志代表的事件是因,哪一条日志代表的事件是果;3)系统日志所表述事件之间的关系也十分复杂,比如事件之间的依赖关系等[1]。
表1 列出了不同软件系统产生的一些系统日志案例(注:https://github.com/logpai/loghub 提供了完整的系统日志数据集)。从表1 中可以看出,基本上每一条日志都有时间戳信息表示事件发生的时刻和详细的内容阐述了当前系统某一组件的状态。然而,这些日志中,只有部分日志包含了可以描述日志类型的标识信息(如ALERT、INFO 和ERROR)。此外,实际上相同软件系统类型下的系统日志的结构仍然有着天壤之别。因此,只有当日志可以被正确地解析,才能有效地利用日志中丰富的信息用于系统健康状态诊断并避免系统宕机等严重性问题。

表1 不同软件系统中的系统日志示例Tab.1 Examples of system logs in different kinds of systems
日志解析方法主要分为正则表达式匹配和事件模式挖掘两大类。虽然正则表达式匹配的方法对日志的解析非常准确,但是书写相应系统的日志正则表达式需要大量的人力。因此,如果对日志解析过程中产生的错误是零容忍的话,那么正则表达式匹配则是首选。事件模式挖掘方法则是通过模板匹配的方法,将日志中不变的部分提取出来,并将该不变的部分作为事件的签名加以识别。Du等[2]提出了一种在线流日志解析方法,该方法使用了基于最长公共子序列的方法挖掘和解析在线流日志数据并动态维护了一个日志模式集用于后期事件依赖的分析。针对在线流日志解析问题,He 等[3]也提出了一种在线日志解析方法,该方法使用了一棵固定深度解析树对日志解析规则进行编码,用于提升流日志解析时的效率问题。Guo 等[4]提出了一种事件签名生成方法用于挖掘系统日志记录中不变的部分,并将这种不变的模型定义为签名用于区分不同的事件。当前最主要的日志解析方面的研究都集中在流日志与无监督解析方法上。换句话说,现在提出的方法主要都是用于解决新到来日志中那些从未出现的未知的事件。目前提出事件模式挖掘的算法主要问题在于少量的解析错误会直接影响到系统诊断的准确性。本文主要致力于异常检测的研究,所以使用了正则表达式匹配的方法用于降低错误日志解析对异常检测判断带来的误差。
1.2 异常检测
从表1 中可以看出,在一些系统日志中(如Hadoop 与BGL)存在一些很明确的标志(如INFO、FATAL)告知系统管理员当前日志所描述的事件是正常事件还是异常事件。然而像Thunderbird 和Andriod 的系统生成的日志只有非结构化的文字,并没有类似的标志标明当前事件的性质。此外,监控系统产生的日志都是基于系统设计时专家对已知问题定制的代码段而产生的。换句话说,这样以预设代码段所产生的日志是无法有效地呈现当前系统中未知的异常情况的。因此希望利用尽可能多的历史日志数据,通过异常检测算法将那些系统管理员人工无法发现的未知问题的原因探索清楚,并建立模型有效地预测未知异常事件的发生。
一般来说,异常检测算法可以简单分为监督模型与无监督模型[5-6]。例如,Chen等[7]和Liang等[8]就把异常检测视为传统的机器学习任务,分别应用决策树模型与支持向量机模型对大规模系统中的异常样本进行分类和判断。Bodik 等[9]则提出了一种有效的特征提取方法并用“指纹(fingerprint)”去描述当前数据中心的状态信息,并通过在线比对当前数据中心“指纹”与已诊断的历史“指纹”来判断当前数据中心是否处于异常状态。仇媛等[10]提出了一种基于LSTM 网络和滑动窗口的流数据异常检测方法,通过有效划分数据起到分段学习异常短期依赖的关联性。这些监督模型最大的限制就在于其效果受到标定数据的质量影响,然而在实际应用场景中,异常事件是极其稀疏的,这就给监督模型的训练带来了更大的挑战。此外,监督学习是基于已知异常事件的标定数据进行训练并预测的,然而实际场景中,对于未知异常的检测对系统诊断具有更加深远的意义。因此无监督模型在这个领域中的应用更加流行且有效。Breunig 等[11]提出了一种局部异常因子用于独立地表示系统中某一组件的状态情况而不受到相关组件的影响。Xu 等[12]则提出了一种基于主成分分析(Principal Component Analysis,PCA)的特征提取算法用于准确描述大规模系统的复杂状态信息,并设计了一种可交互的决策树视图用以表征复杂的系统状态,为系统管理员提供准确定位异常的手段。Lin 等[13]则提出了一种基于知识图谱的聚类算法LogCluster 用于总结历史数据中的序列化日志信息用作判断异常事件的基准。类似于Lin 等[13]的研究,李海林等[14]提出了一种基于频繁模式发现的事件序列异常检测算法,采用了最长公共子序列的方法挖掘新时间序列数据与历史数据的相似度。这些无监督学习方法虽然训练的过程中不需要明确的标签数据,但是准确的标签数据可以进一步提升这些方法的性能,因此数据驱动对于异常检测仍然具有非常深远的意义。本文提出的日志级异常检测算法属于监督学习方法,因此非常依赖于样本的标定情况;相较于半监督或者无监督学习方法,对于数据质量的要求比较高,因此想要训练出有效的模型需要数据驱动。
1.3 异常粒度
针对异常检测粒度的研究主要可以分为会话级的异常检测和日志级的异常检测。例如在Hadoop 分布式文件系统日志数据集中,专家对异常的时序日志段进行了正常或者异常的标注,但是实际上由于哪一条具体的事件的出现导致了这一异常不得而知[1]。称这种类型的异常为会话级异常,即无法定位到具体的一条日志。然而在实际的应用场景中,需要尽可能迅速地侦测到那些会导致系统崩溃宕机的异常事件,而不是等到当整个时间段过去之后,回顾这一时间段内的日志再进行判断。因此,研究者们提出了一些日志级异常检测方法用以检测流日志数据,从而在第一时间预测异常事件的发生。如果说会话级异常检测是一种非常有效的离线异常分析方法,那么日志级异常检测就是一种非常实用的在线流日志异常分析策略。
加利埃尼下令巴黎的3000辆出租车全部征用。到晚间10时,将军院子门前广场上已经聚集了数十辆出租车。第一批车队在夜幕下开往巴黎西北小镇特朗布雷。次日清晨,又一批出租车会聚将军院启程,浩浩荡荡离城奔向东边另一处军队集结地。
针对会话级异常检测方法,Liu等[15]提出了一种基于孤立随机森林算法iForest,这种方法采用下采样的方式将异常事件显式地从所有的事件中隔离并提取识别,并为大数据场景下的异常检测提供了线性时间复杂度的运算效率以及相对较低的内存需求。此外,Lou 等[16]则通过将结构化后的日志进行归类,并通过对一段时间内各类日志的计数分布来判断会话级异常事件。然而相对于会话级异常事件检测,日志级异常检测方法往往更加关注流日志数据以及较小窗口下的日志信息。Du等[17]结合LSTM 与在线学习的机制提出了一套异常检测的一体化框架,解决了未来未知异常事件难预测对系统运维诊断所带来的影响。LSTM 最大的好处就在于可以对序列化抵达的日志数据进行拟合,并迅速给出下一时刻异常事件的判断。在线学习机制则可以在产生误判未知异常事件时快速重训练LSTM 以保证异常检测的效果。而为了解决异常事件与正常事件样本数量的不平衡问题,Xia等[18]提出了一种基于生成对抗网络的异常检测模型LogGAN(Log Generative Adversarial Network)用以生成更多的异常事件样本;此外,不像传统异常检测任务用以判断下一个事件是否引起异常,LogGAN 是通过生成器判别当前事件模式下的后续异常和正常事件分布。系统管理员可以通过该分布作为字典来判断未来时刻异常事件发生的情况与概率。本文算法是一种日志级异常检测算法,相较于会话级的异常检测算法,本文方法在实际的应用场景中具有更快速的反馈,且针对故障溯源时的问题定位也拥有极强的解释性。
2 基于生成对抗网络的异常检测算法
图1 是本文提出的基于生成对抗网络的日志级异常检测算法框架,主要包含日志解析模块与日志级异常检测模块两大部分。整体的数据流可以简单描述为以下几个部分:1)从监控系统读取原始系统日志信息;2)将原始系统日志通过日志解析模块中的日志模板解析,转换成结构化的日志;3)通过结构化日志的时间戳与日志签名将提取的日志转换成序列化事件,并用滑动窗口按照时序进行截取构建训练真实样本;4)通过日志级异常检测模块中的生成模型生成假样本,将其与真样本一同交由判别模型进行分类,并根据判别损失分别对判别模型与生成模型交替更新;5)向收敛的生成模型提供解析好的流日志数据,生成模型则返回当前事件模式下的后续异常事件分布情况。本章将重点阐述框架中的日志解析模块与日志级异常检测模块的工作原理。
2.1 日志解析模块
日志解析模板的主要作用在于将原始系统日志数据处理成通用的机器学习模型的输入形式,以方便本文涉及的日志级异常检测模块对输入数据的形式与格式要求。正如在相关工作中提到的,日志解析主要分为正则表达式匹配与事件模式挖掘两种。本文使用了正则表达式匹配的形式解析以保证日志可以被正确地解读,使下文的异常检测任务不受到数据标注的精确性的影响。正如图1 中所示的,一般一条日志包含以下信息:时间戳、日志签名和日志参数。时间戳作为日志产生的时间点的记录,对事件之间的因果关系的判断具有十分重要的意义,也是在日志解析模块中对事件进行事件序列排序的重要依据。日志签名表示的是当前日志与其他所有相似日志(如长度相同)比对时日志表示中不变的那部分[4]。通过日志签名,可以将具有相同日志签名的日志归为同一类事件,并对其进行编号处理E={e1,e2,…,em},其中ei表示事件集合中第i个事件(如图1)。日志参数则是除去日志签名之后剩下的部分,这部分往往区分了相同日志签名的日志之间的差异性,具有十分丰富的信息。需要特别说明的是,在有些监控系统(如Hadoop)的日志中包含类似INFO、ERROR 等日志类型的标识信息用以描述该日志属于一条正常的信息还是一条异常的报警。

图1 本文方法框架Fig.1 Framework of proposed method
本文提出的异常检测不仅是针对系统标注的异常警报,甚至在没有系统标注的异常警报时,也能检测出系统管理员无法标注的系统状态异常事件。为了充分利用日志中的信息,Du 等在DeepLog 的研究中针对每一种日志签名单独构建了用于拟合日志参数的模型,用以从更多维度有效判断当前日志的异常性[17]。由于日志参数过于复杂,且不具有通用性,因此,本文主要将目光放在时间戳与日志签名上,即时序事件模式对后续异常事件的判断和预测。
在获得序列化的事件模式S={e(1),e(2),…,e(q)}后,使用滑动窗口将事件序列进行划分成一个个独立的事件模式样本S={s1,s2,…,sn},其中sj={e(j-z),e(j-z+1),…,e(j)}表示在滑动窗口尺寸为z时第j个事件模式。如图1所示,以3尺寸的滑动窗口为例,第一个样本中,11、2、20 号事件是事件模式,而13号事件为异常事件,即在11、2、20 号事件顺序的发生情况下,再发生13 号事件则可以认定是异常事件发生。将滑动窗口按照步长为1进行滑动,就得到了第二行的样本,但此时在2、20、13 号事件顺序发生的情况下,14 号事件的发生则认为是正常事件。这些序列则是形式化表示的事件模式,而这些经过滑动窗口划分的数据就构成了后续日志级异常检测模块的训练数据。
2.2 日志级异常检测模块
日志级异常检测模块是本文提出的异常检测方法框架中最重要的一个部分。该部分主要由一个基于注意力机制的GRU 网络和LSTM 的生成模型与一个拥有相似结构的判别模型组成(如图2 所示)。这里的判别模型与生成模型就构成了最传统的生成对抗网络结构[19]。在这个生成对抗网络结构中,生成模型用于产生与实际样本十分相似的假样本(即不是真实存在的样本),然后通过生成的假样本试图使判别模型产生误判。判别模型则用于判断一个样本到底是来自真实的数据集,还是来源于生成模型生成的假样本。生成模型与判别模型通过不断相互博弈互相提升,直到两者达到一个稳定平衡的状态时,就可以将生成模型用于产生与真实数据十分相似的样本了。本文旨在通过收敛的生成模型生成在特定事件模式下后续事件的正常与异常分布情况。
嵌入层主要由事件嵌入表示模块、GRU 和LSTM 组件构成。假设给定一个事件模式sj,由于经过日志解析模块后,每一个事件都拥有了相应的编号,即sj中的每一个事件均属于E。这里使用了自然语言处理中十分常用的Word2Vec 方法[20],将每一个事件用一个连续的一维向量进行表示。通过以事件序列形式表示的事件模式经过事件嵌入表示转换后按照顺序分别输入到LSTM 与GRU 中。经过LSTM 和GRU 序列化的事件模式输入后会分别得到一个一维连续向量hLSTM和hGRU,作为嵌入层的输出传输给注意力机制层。
注意力机制层主要的目的在于应用注意力机制替代传统的深层全连接神经网络,可以通过简单的浅层结构获得有价值的隐层特征表示。本文采用了LSTM 和GRU 两个网络对序列化的事件模式进行拟合,其中LSTM 的输出hLSTM作为传输到全连接层的特征而GRU 的输出hGRU则作为注意力机制的权重作用于hLSTM对其进行各个维度上的微调,两者通过式(1)级联:
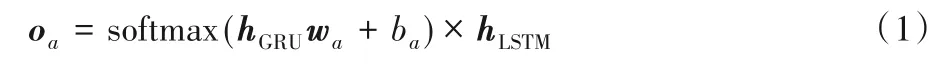
其中:oa为注意力机制层的输出;wa和ba分别为权重和偏置项。
全连接层则负责将注意力机制层的输出(即隐层特征)转换为有意义的模型输出。在本文中,全连接层的输出为m维的一维连续向量oG,含义为事件集合E中每一个事件作为正常后续事件发生在当前事件模式下的概率分布,公式为:
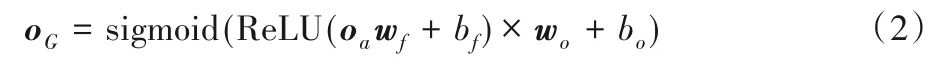
其中:wf、wo、bf和bo分别为全连接层中的权重与偏置项。系统管理员就可以通过设定阈值的ofc作为字典判断在当前流事件模式下,后续的事件是否是一个异常事件。
作为与生成模型博弈的判别模型,结构与生成模型基本相似,只不过在原来的基础结构上添加了图2 中最右侧虚线框中的全连接层。该全连接层的输出oD表示判别模型的输入样本是当前事件模式下的真实事件分布还是生成模型生成的假事件分布。计算方式为:
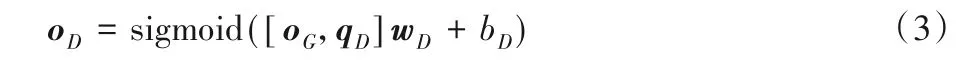
其中:qD表示当前输入判别模型进行判断的一维连续事件分布向量;wD和bD分别为判别模型中全连接层的权重与偏置项。然而生成对抗网络(Generative Adversarial Network,GAN)最大的特点在于如何使生成模型与判别模型在相互博弈中成长,即生成模型生成的事件分布越来越趋向于真实,而判别模型更能够区分真实事件分布与生成模型生成的假的事件分布,直到两者达到一个平衡后即收敛。这里,生成模型G与判别模型D的损失函数分别为:
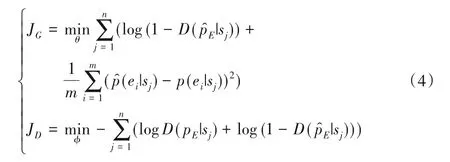
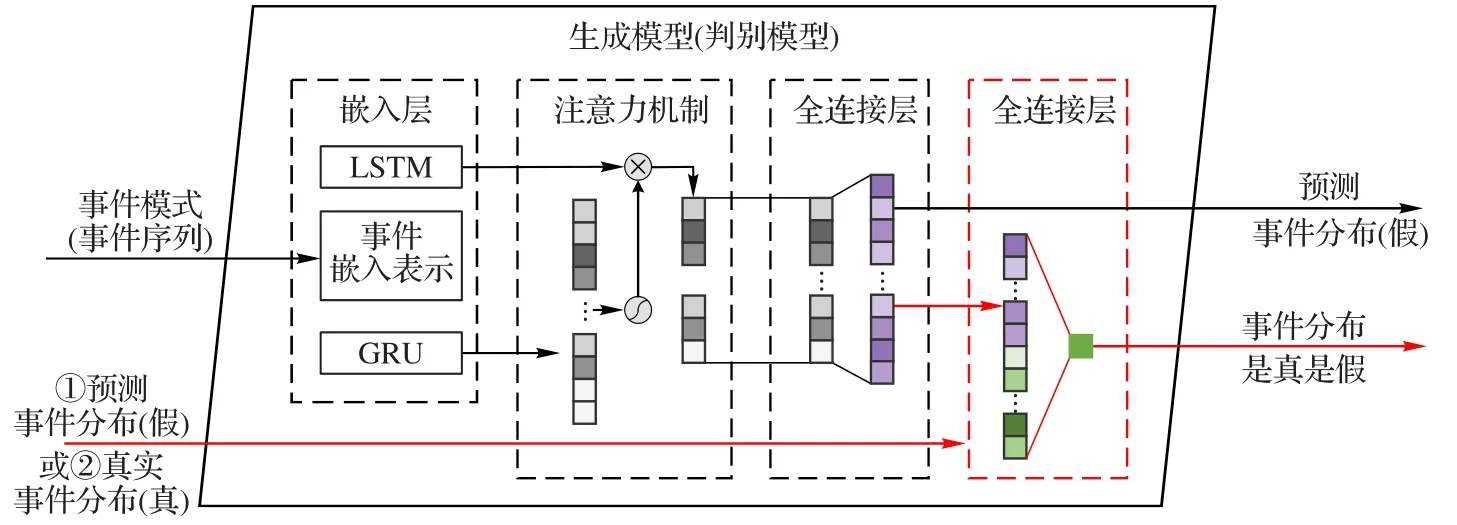
图2 生成模型与判别模型结构Fig.2 Structure of generative model and discriminative model
3 算法评估与实验分析
3.1 实验设计
为了验证本文方法的有效性,在公开的数据集BGL(https://github.com/logpai/loghub)上与其他日志级异常检测算法进行了比较。为了保证实验的可重复性,这里将简单地描述方法中使用的一些参数。本文将BGL 的日志按照时序的方法进行排列,并用其前30%的数据作为训练数据,后70%的数据作为测试数据来验证本文方法与基线方法的性能。其中,事件模式的滑动窗口z为3,即通过历史最新的三个事件信息来判断下一时刻事件的正常与异常分布情况;由于生成模型G输出的一维连续向量是由m个取值范围为[0,1]的数字,为了区分正常与异常事件,这里取阈值0.1,即概率大于等于0.1的事件被认定为正常后续事件,而概率小于0.1的事件被认定为异常后续事件,这里阈值的选择主要根据实验在当前数据集上的表现进行选择,根据不同的数据集,该阈值的表现均不相同;嵌入层中事件的嵌入表示维度为200。在实验中,某一个特定事件模式的后续事件是极其有限的,没有出现过的不能认为就是异常事件。为了保证模型不受到这些未见样本的影响,因此在生成模型输出事件分布时,用一个m维且每一维取值范围为(0,1)的过滤器将未见事件的损失过滤,防止模型产生过拟合。
3.2 实验与结果分析
本文方法与传统方法的区别在于注意力机制的部分。在该问题中,传统方法可以将LSTM 等基于循环神经网络模型的每一步输出取出来作为计算注意力权重的参数使用;而在本文方法中,使用了不同模型相互之间提供注意力权重的方式提供特征提取任务。表2 展示了本文方法中4 种不同注意力机制组合与不适用注意力机制的模型性能对比情况。从总体上来看,在只使用LSTM 对日志序列进行拟合的情况下,模型的总体性能要比使用了注意力机制的模型相对弱一些,这就说明加入注意力机制可以有效地提升对异常事件的检测效果。重要的是,很直观地可以看到将LSTM 作为隐层特征而GRU 的输出作为注意力权重参数时,模型的性能最优。此外将GRU 作为隐层特征而LSTM 作为注意力权重时,虽然准确率并不是最好的,但是相对的召回率有接近于1 的效果。这对于已出现的异常事件预测错误的低容忍相较于前一种有更好的效果。此外,使用GRU 和LSTM 为各自的输出提供注意力权重参数的结果,相较于混合式而言,表现并不是非常理想。但是从整体的结果上可以看出,LSTM提取特征的能力要比GRU 更胜一筹。而由于GRU 与LSTM 的结构不同,所以在作为注意力权重参数时可以进一步提升LSTM 的特征提取能力。

表2 生成(判别)模型中不同LSTM与GRU组合对模型性能的影响Tab.2 Impact of different combinations of LSTM and GRU on generative(discriminative)model performance
在明确了LSTM 作为特征提取模型和GRU 作为注意力权重参数拥有更好的效果以后,将本文方法与相关工作中提到的两个日志级异常检测算法DeepLog和LogGAN 进行了比较。由于会话级的日志异常检测算法应用的场景并不相同,因此这里只对用于时序日志级异常检测的算法进行了比较。表3展示了本文方法与基线方法在BGL 数据集上对异常检测任务的性能表现。结论上来说,本文方法在日志级异常检测方面拥有更好的性能。值得注意的是,DeepLog 方法为了保证每一个出现过的异常都被检测出来(即召回率为1),会将大部分的正常事件也判别为异常事件。从F1-score 可以看出这种正常与异常事件判别的非平衡型在DeepLog 中是非常明显的。相比较而言,LogGAN与本文方法在这方面虽然有一些缓和,但是对于已出现的异常事件会有部分检测遗漏。所以针对不同的场景,可以适当调整阈值,以保证对异常事件零容忍的情况下可以确保本文方法对异常事件检测的性能。
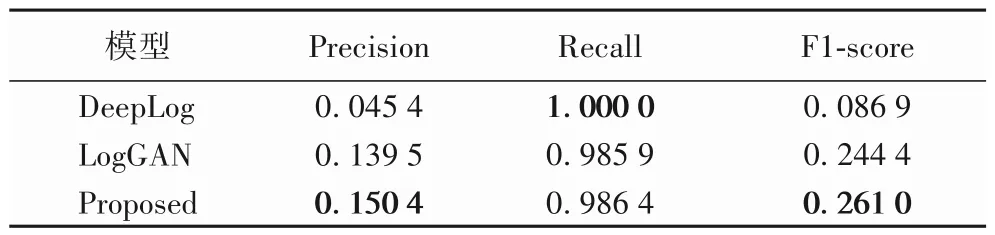
表3 不同方法在BGL数据集上的性能比较Tab.3 Comparison of different methods on BGL dataset
4 结语
针对目前智能运维的自动化异常检测需求,本文提出了一种基于生成对抗网络的日志级异常检测算法用于检测流日志中存在的异常事件行为。通过BGL 数据集上与其他有效的日志级异常检测算法进行比较,可以看出,不仅生成对抗网络的设置在一定程度上可以缓解异常事件与正常事件极端不平衡性的问题,而且注意力机制在一定程度上使得模型可以更好地拟合真实数据,使模型的性能得到进一步的提升。
针对日志级异常事件检测任务,未来我们打算进一步解决以下尚未解决的问题。首先是异常检测的准确率,目前异常检测的准确率的提升完全依赖于将大部分的正常事件错分成异常事件,这样从另外一个角度也加大了系统管理员对异常的审核难度。所以如何进一步提升异常事件与正常事件检测的平衡性,是一个重要的问题。然后,针对LSTM 这类基于序列化输入的模型,在运行效率上是无法做到并行的。换句话说,当流日志的量十分巨大的情况下,LSTM 可能很难快速消化流日志并判断未来的异常事件。因此如何解决模型对时序数据的并发处理是对在线异常检测非常重要的一个挑战。最后,异常检测的目的最终还是要将问题定位于故障排除,所以仅仅是检测出异常是远远不够的,如何定位系统问题并产生合适的工单供专业团队予以解决才是异常事件检测的最终目的。
