基于生成对抗网络的自动细胞核分割半监督学习方法
2020-10-18刘剑飞
程 凯,王 妍,刘剑飞
(1.安徽大学电气工程与自动化学院,合肥 230061;2.安徽大学计算机科学与技术学院,合肥 230061)
(*通信作者电子邮箱1259827579@qq.com)
0 引言
私人医学[1]的关键是定量评估生物学个体,评估信息通常从显微镜图像分析细胞形态和组织结构中获得。显微镜图像的定量分析涉及细胞密度、形状、大小、质地和其他图像属性的测量。在显微镜图像中对细胞核进行分割是必要且重要的任务。人工测量无法满足高通量处理显微镜图像的临床需求,因为这是一个需要消耗大量时间和精力的过程。另外,人工测量也是不可复现的,这使得难以用于纵向跟踪疾病进展。
自动细胞核分割[2-3]由于可以产生可重复的测量结果而极具应用价值。准确地分割细胞核是计算机辅助图像分析中至关重要的步骤,用于提取丰富的特征进行细胞估计以及诊断和治疗。然而,如图1 所示,对显微镜细胞核的精准分割往往存在较大的困难。一方面,是由于细胞/细胞核区域与背景之间通常存在较小的对比度,这可能是由于图像采集过程中图像噪声和细胞运动性引起的;另一方面,由于细胞图像的差异性,譬如细胞的形状、大小和质地通常会表现出明显的区别。
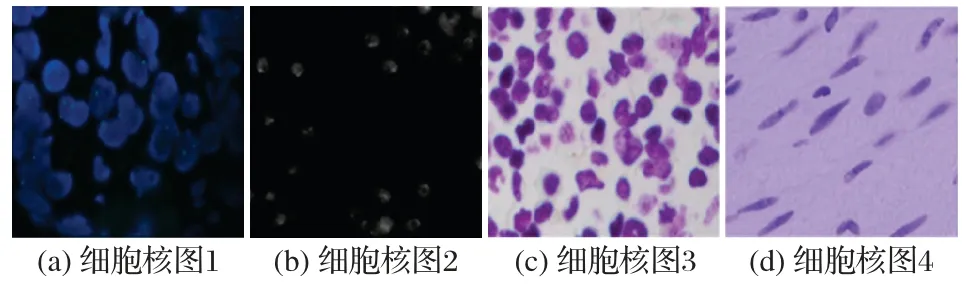
图1 显微镜图像中细胞核的示例Fig.1 Nucleus examples in microscopic images
目前有很多基于显微镜图像特征的方法来实现细胞核自动分割,例如灰度阈值[4]、分水岭[5-6]、活动轮廓[7],以及上述各种方法的组合,这些方法也通常辅以不同的预处理和后处理步骤。尽管在这些方法中精心设计了数学模型以适应图像特征,但由于显微镜图像的复杂性,这些模型往往得不到比较满意的结果。目前,最先进的语义分割方法往往基于卷积神经网络(Convolutional Neural Network,CNN)。例如,Ronneberger 等[8]提出了U-Net 分割网络,以及Kraus 等[9]提出了深度多示例学习来分割显微镜图像,可以直接从显微镜图像建立数学模型。这些基于深度学习的方法通过利用大量标记图像可以实现精确的细胞核分割。然而,标记显微镜图像是一个非常繁琐的过程,为大量显微镜图像制作标签在实际临床操作中通常不具有可行性。
标记显微图像的过程繁琐,促使我们开发一种半监督学习策略,以减少对标记图像数量的依赖性。生成对抗网络(Generative Adversarial Network,GAN)[10]在机器学习领域的成功,提示可以通过生成未标记图像的置信图来增加训练数据。基于这种想法,本文提出了一种新颖的基于半监督学习细胞核分割方法。新颖的卷积神经网络可以从背景中自动提取细胞核区域。与最新的分割网络结构相比,本文设计的网络结构具有较少的参数,并且将特征层次结构的各层组合在一起,从而改善了输出概率图的空间精度。在本文的方法中,通过应用全卷积网络生成判别器网络模型的置信图,并将对抗损失与标准交叉熵损失耦合,用于改善分割网络的性能。结合标记图像、未标记图像与置信图来训练分割网络,最终可以识别提取的细胞区域中的单个核。本文的主要工作如下:
1)提出了一种轻型神经网络Light-Unet 识别显微图像中的细胞核。该网络的多层上采样网络可以增强细胞核图像分割中特有的边缘信息。实验结果表明,Light-Unet网络比现有的网络(例如U-Net)计算速度更快、参数量更少。
2)设计了一个对抗网络,通过在判别器网络中采用对抗损失来进行对抗学习以提高细胞核分割的准确性,而无需在网络的前向计算中增加额外的运算量。
3)对于未标注的图像,利用判别器网络的半监督学习方案可以很好地帮助分割网络的训练。
1 基于GAN的细胞核分割算法
本章首先提出基于生成对抗网络的细胞核分割算法,然后介绍设计的分割网络结构和全卷积判别器网络结构,并给出分割网络和判别器网络的详细学习方案。
1.1 框架
基于GAN 的细胞核分割算法包括一个判别器网络和一个分割网络。在本文中,判别器网络和分割网络分别用S(·)和D(·)表示,图2 为细胞核分割算法框架。给定一个大小为H×W×3的输入图像,分割网络会输出大小为H×W×C的概率图。本文中,C的值被设置为2,那么,判别器网络的输出概率图的大小则为H×W×2。
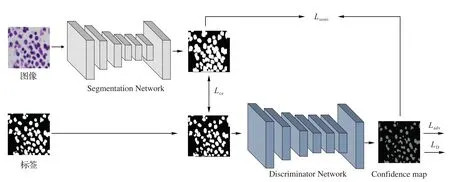
图2 基于生成对抗网络的细胞核分割算法框架Fig.2 Nuclei segmentation algorithm framework based on generative adversarial network
1.1.1 判别器
判别器网络的作用是将生成器生成的概率图和真值标签图区分开来。判别器网络的输入是来自分割网络输出的分割图S(Xn)或来自真值标签,且真值标签需要在训练之前进行一次One-hot 编码;输出的是空间概率图,且图中的每个像素值代表像素来自这些分割图或真值标签的概率。典型的GAN是将固定大小的图像作为输入和输出,反映了图像是真实还是伪造的单一概率值。受全卷积网络的启发,本文使用的判别器网络是一个全卷积网络,能输入任意大小的图像并输出概率图,可以反映空间水平。值得注意的是,判别器网络的参数仅在带标签的图像训练中被更新。
1.1.2 细胞分割网络
对于细胞分割网络,给定一个大小为H×W×3 的输入图像,输出大小为H×W×2 的类别概率图。当训练带标签的图像时,通过使用真值标签优化标准交叉熵损失(Lce)和使用判别器网络优化对抗损失(Ladv)来训练分割网络,此时仅使用标记图像来训练判别器网络。当训练无标签图像时,使用判别器网络和半监督损失训练具有对抗损失的分割图。在训练带标签图像和无标签图像时,分割网络的参数均会被更新。
在训练过程中,在半监督设置下同时使用带标签图像和无标签图像。当训练带标签的图像时,通过使用真值标签优化标准交叉熵损失(Lce)和使用判别器网络优化对抗损失(Ladv)来训练分割网络。对于无标签图像,用判别器网络和半监督损失训练具有对抗性损失的分割网络。通过经过判别器网络的初始分割图S(Xn)获得置信图。置信图像是一个指导者,指导分割网络在概率图S(Xn)中选择置信区域,然后在置信域执行半监督性损失。由于对抗损失仅与判别器网络有关,因此分割网络始终受到对抗损失的监督。
1.2 网络框架
本节提出的分割网络结构受到U-Net的启发,包含6个卷积层,2 个上采样层。在每一层之后还执行批量标准化(batch-normalization)[11]和Xavier 初始化[12]。由于提出的网络参数比U-Net 少得多,因此将其命名为Light-Unet。与U-Net相似,上采样部分具有大量特征通道,这些特征通道允许网络将上下文信息传播到更高分辨率的层。Light-Unet 的网络结构如图3所示,每层的参数列于表1。
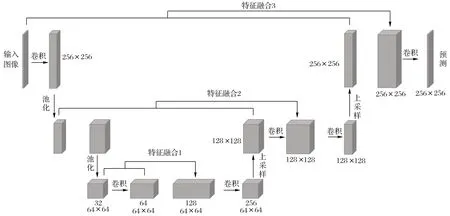
图3 Light-Unet结构Fig.3 Structure of Light-Unet
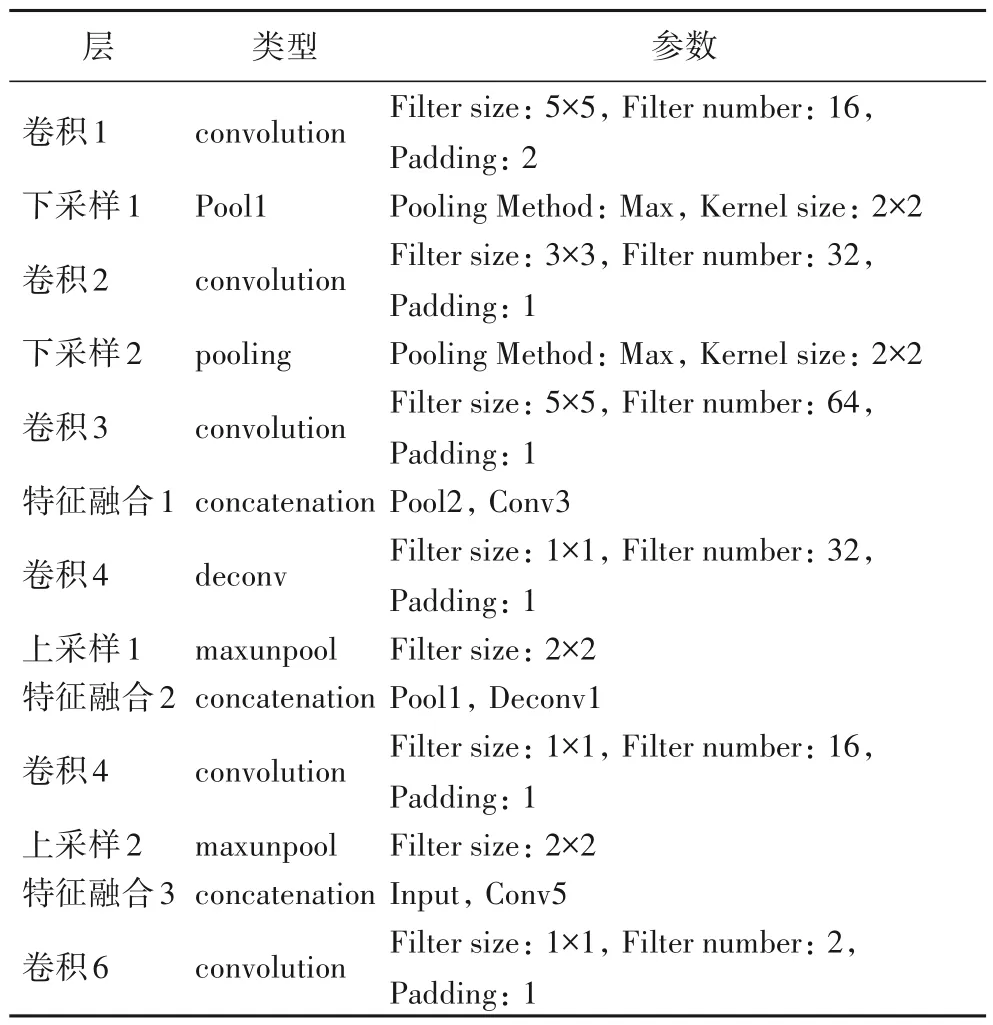
表1 Light-Unet的相关层及其参数Tab.1 Relevant layers and their parameters of Light-Unet
对于判别器网络,遵循Radford等在文献[13]中使用的结构。它包含5个具有尺寸为4×4卷积核的卷积层,步长为2,通道数为{64,128,256,512,1}。此外,在每个卷积层后应用Leaky-ReLU[14]激活函数。
1.3 训练
给定大小为H×W×3 的输入图像Xn,分割网络表示为S(·),S(·)将预测大小为H×W×2的概率图S(Xn)。对于全卷积判别器网络,将其表示为D(·),它输入大小为H×W×2 的概率图并输出大小为H×W×1的置信图。
1.3.1 判别器网络训练
训练判别器网络时,使用与Goodfellow 等[10]相同的方法,利用对抗损失函数,可定义为:

其中:x表示来自未知分布Pdata的原始图像;z是生成网络G(·)的输入噪声;G(z)是生成网络的输出图。判别器D(·)和生成器G(·)在利用此损失函数做最大化和最小化交替游戏。也可以将式(1)转换为另一种形式:
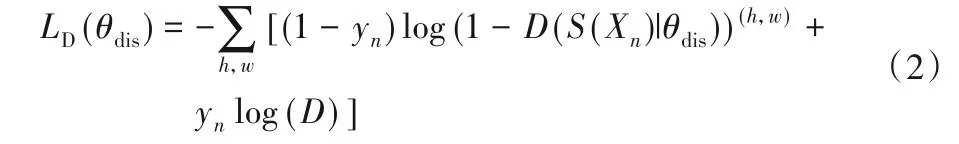
其中:θdis是判别器网络参数;Xn是第n个输入图像。当yn=0时,表示判别器网络的输入是分割网络的预测分割图;当yn=1 时,表示输入图像是从真值标签中采样的。需要注意的是,真值标签图像只是一个通道,需要执行一位有效编码(onehot decode)将真值通道转换为与训练前的概率图S(Xn)相同。
1.3.2 分割网络训练
在此训练阶段,本文提出一种多任务损失来优化分割网络。损失函数可以定义为:
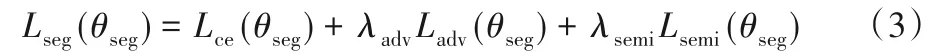
其中:θseg是判别器网络参数;Lseg、Ladv和Lsemi分别代表交叉熵损失、对抗损失和半监督损失。此外还有两个超参数λadv和λsemi,这些参数的作用是平衡多任务训练。
当训练带标签的图像时,使用标准的交叉熵损失对其进行优化。损失定义为:

其中:S(Xn)是第n个输入图像的分割网络的预测结果,标准的交叉熵损失Lce可以使预测的概率图分布更加接近真值标签分布。通过使用对抗损失来进行对抗学习,该损失定义为:
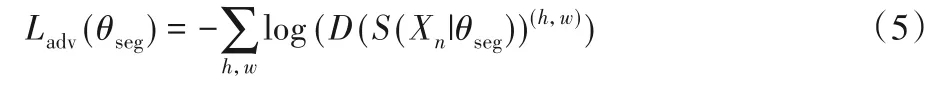
使用对抗性损失Ladv,可以在考虑真值分布的情况下最大限度地提高预测分割图S(Xn)的概率。
当训练无标签图像时,在半监督环境下进行对抗训练。尽管Lce不适用于多任务,但Ladv仍适用,因为它仅依赖于判别器网络。判别器网络可以生成空间概率图,置信图反映的是预测结果接近地面真值图分布的概率。再通过设置阈值Tsemi对置信图进行二值化。最后,真值标签表示为结合了该二值化置信图掩模分割预测=arg max(S(Xn))。半监督损失定义为:
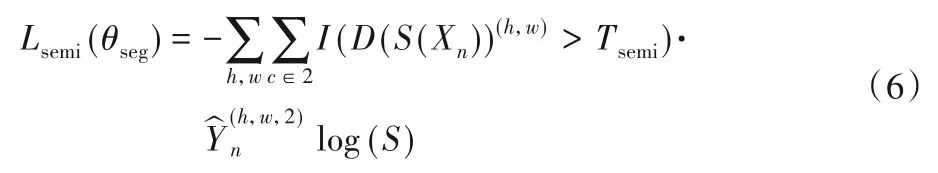
其中:I(·)是激活函数;Tsemi是控制置信区域的阈值。在训练过程中,已经获得了,可以将其视为标准的交叉熵损失。利用半监督损失Lsemi,可以通过使用更多无标签图像来增强分割网络的性能。学习目标是判别器网络中的参数θdis和分割网络中的θseg。判别器网络中的θdis仅传播带标签图像的训练参数,并通过自适应矩估计(Adam)[15]进行更新;参数θseg通过随机梯度下降(Stochastic Gradient Descent,SGD)来更新。
2 实验与结果分析
2.1 实验细节
应用标准随机梯度下降算法(SGD)来优化分割网络参数,其中,动量设置为0.9,批尺寸为10,权重衰减为0.000 4,初始学习率为0.001。训练判别器网络,采用Adam 优化器,学习率为0.000 1,动量设置为0.999。
对于半监督训练阶段,在每次迭代中随机选择标记图像和未标记图像。在开始半监督学习之前,仅在实验中的前600 次迭代中开始使用带标签的图像进行训练。由于该模型将受到初始噪声掩膜和预测结果的影响,且经过600 次迭代,因此分割网络的初始分割图是较精准的。每次迭代过程中,当训练带标签图像时,会同步更新分割网络和判别器网络;当使用无标签图像进行训练时,仅使用半监督学习更新分割网络。
获得分割结果后,可进一步利用OpenCV 库进行分水岭操作,这对于分割粘连细胞核效果显著。
2.2 数据处理
2.2.1 数据集
实验数据来自公开的竞赛数据集(2018 Data Science Bowl competition)。该数据集包含大量关于细胞核分割的图像。图像是在多种条件下采集的,并且包含的细胞种类、放大率和成像方式(明光与荧光)方面有所不同。如图4 所示,此数据集包含3种不同类型的图像。此数据集中,训练集有670张图像,测试集有65 张图像。由于图像的大小不同,因此需要进行预处理,实验中将所有图像裁剪尺寸为256 × 256。另外,在这个公开数据集中某些细胞核图像有一些错标注。从图5 可以看到某些细胞核图像存在错误标注的情况,比如第一列和第二列图像展示图像中有明显的核,但是人工分割可能会忽略了它。尽管在测试阶段本文提出的网络的预测分割图可以轻易地发现它,但是人类专家很容易忽略它。图5 中第三列的细胞图像中某些细胞核是独立的,而人工却将其标注为聚合在一起的细胞核。由于此公开数据集存在这些问题,最后在原有的测试数据集中选择了40 张没有明显此类问题的图像作为测试图像。
2.2.2 数据扩充
小数据集或复杂的神经网络结构可能会导致严重的过拟合,因此本文采用两种数据扩充方式对数据进行扩充:一种是方式是通过水平旋转;另一种方式是随机裁剪。裁剪时首先将细胞核图像缩放尺寸为331× 331,然后随机裁剪成尺寸为256 × 256的图像。数据增强操作使得提出的方法更加健壮。
2.3 评价指标
为了评估检测性能,采用F1来度量,定义为:

其中:P=代表精准度;R=代表召回率。具体地,TP指“真正”,即模型判断为真的正确率(True Positive);FP为“假正”,即误报率(False Positive);FN为“假负”,即漏报率(False Negative)。
使用分割准确率度量(SEGmentation accuracy measurement,SEG)来评估分割掩模的准确性,基于Jaccard相似性。其中Jaccard 相似度的计算公式为J(G,S)=,SEG可表示为:

其中:i是第i个输入核测试图像;j是测试图像中的第j个核。SEG是所有GT 核的Jaccard 相似性指数的平均值,范围在0~1。SEG值越大,分割的输出图像与标签图像之间的相似性就越高,表明单个核与原始人工标注越相似。

图4 数据集中的三种细胞核图像示例Fig.4 Three kinds of nuclei images in dataset

图5 数据集中具有弱标注和错误标注的细胞核图像示例Fig.5 Examples of nucleus images with weak labels and wrong labels in dataset
2.4 实验结果对比
本节展示基于GAN 的细胞核分割半监督学习方法的实验结果,并将其与深度学习分割方法进行比较,如表2 所示。其中:由Ronneberger 等[8]提出了U-Net 网络能够很好地识别细胞核,是现存的最先进的分割方法之一;Deeplab-v2 网络由Chen 等[16]提出,本文将其用作分割网络,以在显微镜图像中识别细胞核。从表2 可知,本文提出的模型比DeepLab-v2 有更好的分割结果,且与U-Net 相比具有更少的参数量,Light-Unet 与U-Net 的参数量和推断速度的对比如表3 所示。实验时,Light-Unet中的参数设置为:Ladv=0.002,Lsemi=0.1,Tsemi=0.2。
为了验证半监督方案,实验随机选择了训练集总数的1/32、1/16、1/8 张带标签图像,其余训练数据均无标签来训练网络。通过使用对抗损失Ladv,该模型的F1 得分比基准模型高约1.4%~1.9%,表明了提出的对抗损失方案可以促进分割网络从真值标签分布中学习结构信息。当同时使用对抗损失Ladv和半监督损失Lsemi时,该模型可以比基准模型再提高约2.8~3.2个百分点的F1得分。

表2 与其他深度学习分割方法的比较Tab.2 Comparison with other deep learning segmentation methods

表3 Light-Unet与U-Net的比较Tab.3 Comparison between Light-Unet and U-Net
当使用DeepLab-v2 网络并选择训练集带标签数据的1/8训练网络时,可以获得78.1%的最佳SEG得分。然而,分割结果需要结合SEG和F1 得分来作出准确的决定。尽管该方案获得了最高的SEG得分,但F1 得分仅为65.6%,表明图像中的许多细胞核无法被完全识别出来。这主要有两方面原因:首先,由于细胞图像中的上下文特征比现实世界中的图像更加简单和稳定,因此像Deeplab-v2 这样的更深层网络会带来更多参数,并且会在像细胞分割这样的小数据集中引起过拟合问题。其次,Light-Unet 采用经典的编码器-解码器体系结构,其中低级和高级特征的融合可以实现更精细的对象边界恢复。
此外,还可以从表2中得知最高的F1得分仅为76.1%,意味着有大约1/4的细胞核没有被清楚地识别出来。事实上,这是由于本文使用的数据集中一张图像可能包含300 多个细胞核,在这种情况下,即使人类专家也无法清楚地识别全部或者大多数细胞核。不同于现存的大多数细胞核分割的数据集中每张图像仅包含有约30 个细胞核,本文使用的测试集中每张测试图像的细胞核数量从十几个到几百个不等。当在每张图像中包含少量的细胞核的数据集中测试时,本文方法测得的F1得分可以达到86.0%。
2.5 超参数分析
分割任务采用多任务学习策略来学习两个超参数λadv和λsemi,并使用Tsemi来控制半监督学习中的敏感度。本节通过设置不同的超参数来分析分割结果,如表4所示。
实验首先评估λadv的影响,注意到在没有λadv损失的情况下,该模型获得75.5%的F1 得分和78.1%的SEG得分。当λadv被设置等于0.002,该模型的F1 得分将提高1.2 个百分点,SEG得分将提高0.2 个百分点。而当λadv=0.005时,模型性能的F1得分将下降约1.5%,表明对抗损失太大。
其次,表4 还展示了使用数据总量的1/16 时,Tsemi=0.002且λadv值在不同情况下进行的比较,以及λadv=0.002的情况下改变Tsemi值的比较。当将Tsemi分别设置为{0.05,0.1,0.2}时,可知在仅有λadv损失的情况下,基准模型能获得70.2%的F1得分和76.1%的SEG得分。一般而言,当Tsemi=0.1 时模型具有最佳的性能,与没有Tsemi损失时相比,F1得分提高了1.8个百分点。
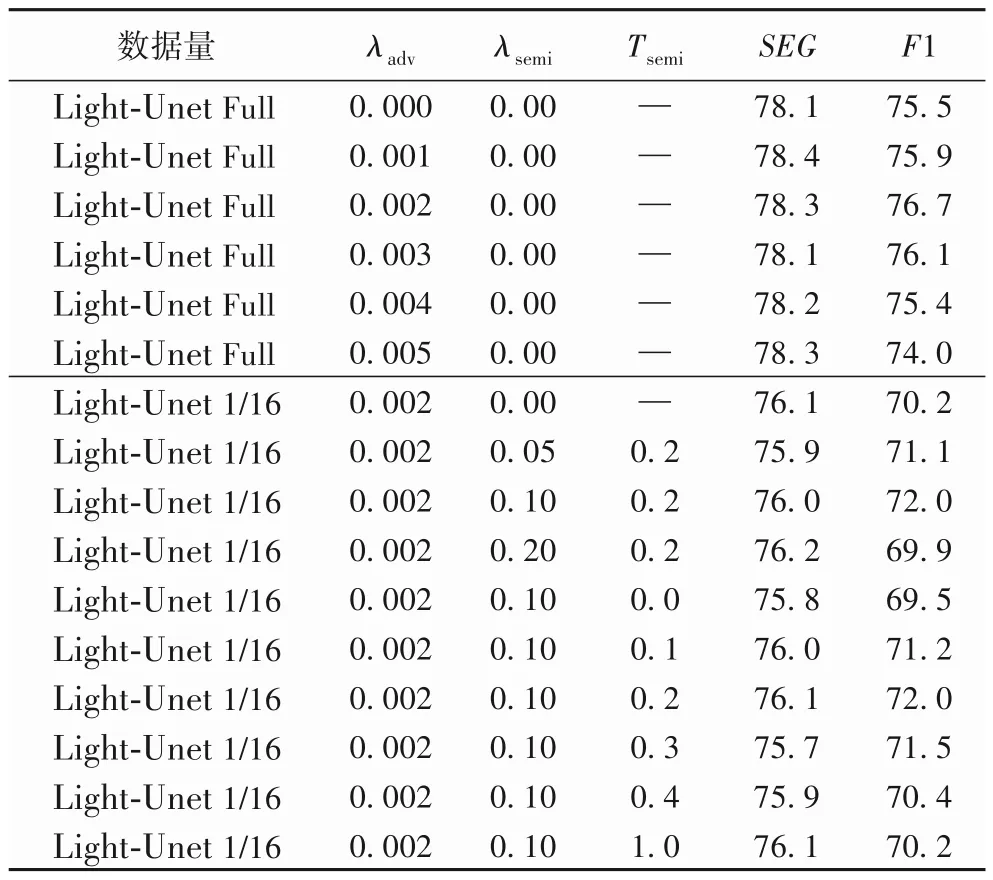
表4 超参数分析Tab.4 Hyperparameter analysis
最后,设置不同的Tsemi值进行实验来对比分割结果。具体地,先设置λadv=0.002,λsemi=0.1,再将Tsemi分别设置为{0.1,0.2,0.3,0.4,1}。对于未标记的图像,Tsemi越高,代表着只选择结构相似度更接近与真值标签分布的真值标签图。如表4 所示,Tsemi被设置为0 时F1 得分下降到69.5%,Tsemi被设置为1 时F1 得分为70%,这两种极端情况下均未取得很好的结果。当Tsemi的值被设置为0.2 时,该算法的效果最佳,此时F1 得分达到了72.0%,SEG得分达到75.9%。在此比较过程中,训练没有对抗损失λadv和半监督损失Tsemi的Light-Unet 作为实验的基准模型。细胞核分割结果如图6 所示,第一行显示了细胞核之间分离良好,可以将这种输入图像成为“易分割”图像;第三行存在许多簇细胞核,可以将称为“难分割”图像。对于“难分割”图像,可以发现即使是人工标注也难很好地分割出簇状核,然而本文方法却可以有效地分割出这些簇状核。图6 也展示了对分割结果进一步进行分水岭操作的结果。
3 结语
本文提出了一种新颖的半监督学习方法用于显微镜图像的自动细胞核分割。受生成对抗网络的启发,方法设计为由分割网络和判别器网络组成。分割网络通过一小部分标记的显微镜图像对模型进行初始化。通过使用来自判别器网络的置信图将无标签图像作为训练数据,可以不断改善分割效果,与此同时,分割网络的损失函数也随着对抗损失而更新。实验结果表明本文方法在小的显微镜图像数据集上实现了高分割精度,且与基于大量标记图像的现有方法具有可比性。
本文提出的基于半监督学习的细胞核分割方法在实际临床应用中具有巨大潜力。目前大多数细胞核分割方法都需要大量标记图像来监督神经网络学习,而本文方法仅需要少量具有代表性的带标记图像,这对于专家建立训练数据来说是可接受的;而且此方法不限于特定的细胞核类型,它可以用作于不同类型的显微图像上的通用分割框架。
将来,我们还需要确定标记图像的最小数量,以实现临床上更高的分割精度。本文提出的半监督学习方法可以使用少量标记图像来实现高分割精度,说明了这个方法作为高通量显微镜图像分析临床工具的巨大潜力。

图6 使用1/16训练数据进行细胞核分割的结果Fig.6 Results of nuclei segmentation using 1/16 training data
