基于条件生成对抗网络的乳腺上皮和间质区域自动分割
2020-10-18张泽林
张泽林,徐 军
(江苏省大数据分析技术重点实验室(南京信息工程大学),南京 210044)
(*通信作者电子邮箱xujung@gmail.com)
0 引言
上皮和间质区域是病理组织图像中的两种基本结构,在乳腺病理图像中,约有80%的肿瘤起源于上皮组织[1],并且上皮-间质转化(Epithelial-Mesenchymal Transition,EMT)过程参与了肿瘤的恶性进展[2],因此上皮和间质区域的自动分割对乳腺癌的诊断和预后具有重要的临床价值。但是,在组织病理图像中上皮和间质组织的自动分割具有以下的挑战:1)上皮和间质两种组织的纹理结构复杂,不同病理图像之间以及不同的病理分级之间两种组织的差异性大,因此很难提取到适应性很强的组织区域识别特征;2)上皮和间质组织区域之间没有明显的边界,甚至两种组织区域交叠在一起,所以模型对两种区域的区分很困难;3)染色剂和扫描仪等一些外部因素造成的病理图像之间的差异也对模型识别两种区域带来了挑战。
传统的分割方法如文献[3]中使用超像素过分割的方法从病理图像中提取小图像块,然后训练支持向量机(Support Vector Machine,SVM)[4],最后以图像块分类的方式分割口腔鳞癌图像中上皮和间质组织;文献[5]中提出了基于贝叶斯表决模型的上皮区域分割方法,该方法使用间质区域细胞的纹理和颜色特征,通过贝叶斯投票的方式去除了间质区域所有的细胞,从而得到了上皮区域的分割结果;文献[6]使用了基于二值图割的方法来分割牙源性囊肿图像中的上皮和间质区域,其中二值图的权重大小取决于图像中上皮和间质区域的颜色直方图概率;文献[7]中首先用80×80 的滑动窗提取了重叠的图像小块,之后提取了图像小块的局部二值模式(Local Binary Pattern,LBP)特征,最后用提取的小块LBP 特征训练SVM分类器来分割上皮和间质区域。
相较于传统的分割模型,深度学习分割模型具有更高的分割准确性和鲁棒性。深度学习分割模型的分割机制一般分为基于滑动块分类预测的分割机制和端到端的分割机制。基于滑动块分类预测的模型在分割大尺寸的病理图像时将会花费大量的时间。如文献[8]首先根据专家标记的上皮和间质区域边界线来重叠地提取两种区域图像块构建训练集,然后训练分类卷积神经网络(Convolutional Neural Network,CNN)Alexnet[9],最后逐块地预测上皮和间质两种区域;文献[10]中提出了一种结合有监督CNN 分类网络和无监督图分割模型的方法来分割上皮和间质区域,该方法通过结合分类识别两种区域和定位两种区域的边缘,从而可以更准确地分割两种区域;文献[11]分别用CNN和LBP、区域感知以及像素强度三种传统特征的提取方式分别提取了上皮和间质区域的2 类特征,然后用SVM 分类器对四种方式提取的特征分类来对上皮和间质区域进行分割,实验结果表明,基于CNN 深度特征的方式可以取得最好的分割性能。
和基于滑动块分类预测的分割模型相比,端到端的分割模型在分割效率上更高,但是端到端模型的训练会更加困难。因为一般对于分类器网络,架构都只有一个编码器,而端到端的分割网络则需要多训练一个解码器,解码器的训练要比编码器的训练更加困难。因此基于编码器的结构,文献[12]中提出了全卷积网络(Fully Convolutional Network,FCN)解决了语义分割的问题。FCN 相对于分类器网络的主要变化是在编码器的输出端串联了由一个反卷积构成的解码器,这样就可以实现端到端的分割。基于FCN 的结构,越来越多的端到端模型被提出并成功地运用在医学图像的分割任务中。文献[13]中先将免疫组织化学(ImmunoHistoChemistry,IHC)[14]染色的病理图像和对应的苏木素和伊红(Hematoxylin and Eosin,H&E)染色的病理图像配准,然后在IHC染色的病理图像中用颜色反卷积[15]算法分离通道,并训练一个Unet[16]分割IHC 染色中上皮区域,最后用训练好的分割模型微调训练配准的H&E 染色的病理图像数据集,并在H&E 染色的病理图像中分割上皮和间质区域;文献[17]中基于VGG(Visual Geometry Group)网络[18]、残差网络(Residual Network,Resnet)[19]和预训练的Resnet 三种CNN 的结构设计了三种端到端的分割模型来对乳腺H&E 染色病理图像中的上皮和间质区域进行分割。
本文构建了一种端到端的上皮间质分割条件对抗网络(EPithelium and Stroma segmentation conditional Generative Adversarial Network,EPScGAN)对上皮和间质区域进行自动分割,与一般深度学习分割模型相比,EPScGAN 具有更好的分割性能。
1 EPScGAN模型
一般的深度学习模型都会用一个预定义的损失函数来计算模型输出和标记之间的误差,从而监督模型的训练。对于不同的模型和任务都会有不同的损失函数,因此损失函数的选择会对网络的性能产生较大的影响。对抗生成网络(Generative Adversarial Network,GAN)[20]提供了可训练的损失函数机制。因为GAN 中的生成器可以是一个解码器网络,也可以是一个端到端的分割网络,而判别器的作用是提取生成器生成图像和标记图像的特征,然后在特征水平上判断生成器的生成结果和标记图像之间的差距。GAN 的优化目标函数如式(1):
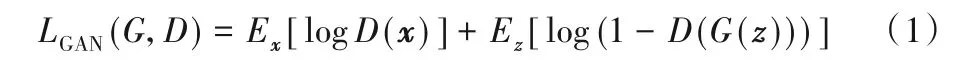
其中:x是生成器的输入;z是生成器的输出;G代表生成器网络;D代表判别器网络。但是生成器的生成输入都是一系列随机的噪声,因此生成结果无法控制。条件对抗生成网络(conditional GAN,cGAN)[21]通过在生成器和判别器的输入中添加生成条件,从而使得生成器的输出变得可控。cGAN的优化目标函数如式(2)所示:

其中:y为添加的约束条件。
Pix2pix 模型[22]首次应用cGAN 机制完美地解决了图像翻译问题。Pix2pix的优化目标函数如式(3):
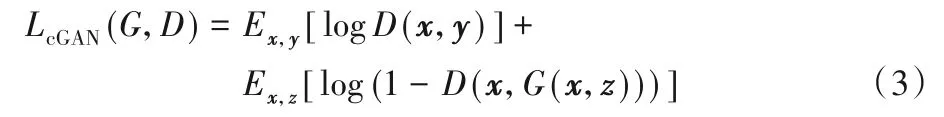
在Pix2pix 中生成器的输入x由随机向量变成了图像,判别器的输入在原来的生成图像z或标记图像y中拼接了原始输入图像x作为条件进行判别。本文基于cGAN 和Pix2pix 的模型结构,构建了上皮和间质组织分割模型EPScGAN,模型结构如图1所示。
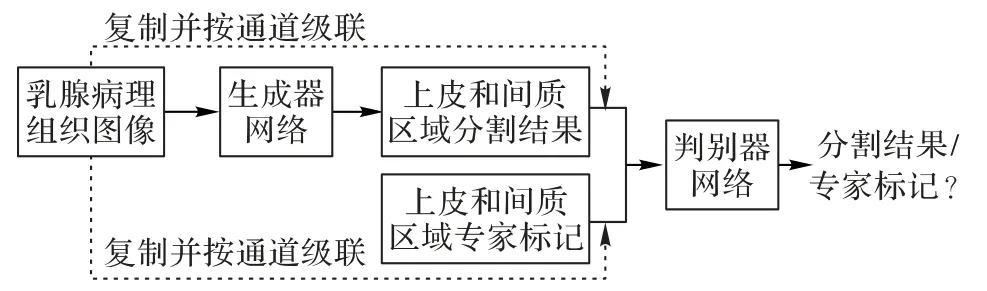
图1 EPScGAN模型结构Fig.1 Structure of EPScGAN model
EPScGAN 包含1 个生成器网络和1 个判别器网络,生成器的主要作用是分割输入的病理图像并输出分割结果,而判别器的主要作用是判别生成器生成的图像和真实的标记图像之间的误差。生成器网络是一个端到端的CNN 分割模型,而判别器网络是一个多层的CNN分类模型。
1.1 生成器结构
在医学图像分割任务中,端到端的分割模型越来越得到了广泛的应用。主要过程是先用编码器下采样提取特征,然后再用解码器上采样解码输出分割结果。目前在医学图像分割中比较流行的几个端到端分割框架有FCN、Unet 等。FCN根据其上采样的步长大小又可以分为:FCN32s、FCN16s 和FCN8s。Unet 的网络结构和FCN 类似,都是在多个尺度下将编码器提取的深度特征和解码器特征进行了融合。但不同之处在于FCN 的解码器只有一个反卷积层,因此是将其他尺度的编码器特征上采样后直接和解码器特征拼接融合,而Unet采用了和编码器相同尺度的对称解码器结构,将编码器不同尺度下的深度特征和相同尺度的解码器特征相融合。一系列的实验结果表明,Unet 的这种短连接对端到端的分割网络非常有效。因为编码器的编码过程会使得一些细节特征被下采样,导致解码器没有足够的信息来恢复细节的结构。而短连接操作可以将原始图像的细节信息尽可能地保留下来,从而使得网络可以更精确地分割一些细小的目标。在一定的情况下,这种结构和Resnet 结构非常相似。和Unet 类似,Segnet[23]也使用了这种短连接操作,与Unet 不同的是Segnet 的解码器使用了上采样串联1×1 的平滑卷积来替代反卷积操作,这样就使得解码器的训练相对更加容易。但是直接采用这种跳跃式的短连接结构存在语义代沟问题。文献[24]中提出的Unet++结构,主要是解决一般Unet 网络的深度和语义代沟问题。因为在Unet 中短连接操作直接把编码器的低维特征拼接到了解码器的高维特征中,而且编码器层数越浅,语义代沟越大。所以为了避免语义代沟的问题,本文使用无短连接的编码解码结构,生成器的网络结构如图2所示。
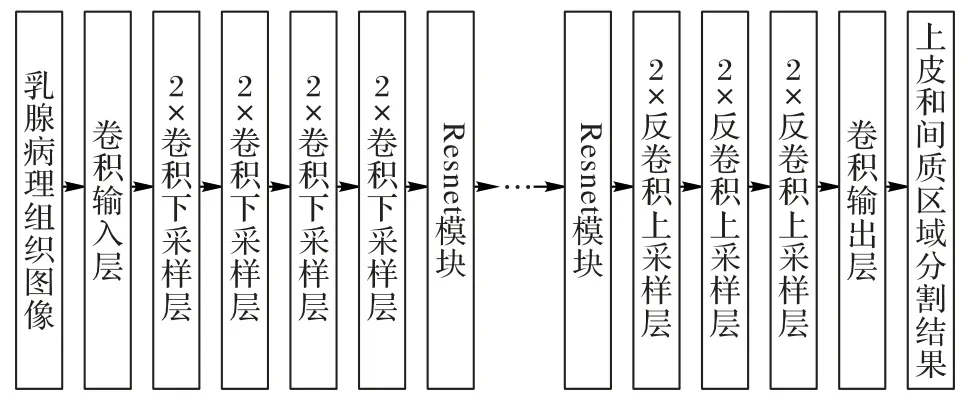
图2 EPScGAN生成器框架结构Fig.2 Framework of EPScGAN generator
为了尽可能多地保留细节信息,本文的编码器只使用了3 个下采样卷积层,并且为了增加生成器网络的鲁棒性,本文用一系列的Resnet 模块来增加网络的参数容量。Resnet 模块不仅能够保留输入图像或特征的细节信息,而且可以有效地避免加深网络导致的梯度消失问题。Resnet提供了一种非常有效的深度特征融合方式,最大的特点是将输入的特征图和输出的特征图相加得到最终的输出。一个Resnet模块的输入x和输出y之间的关系表达如式(4):

其中:F表示整个Resnet 模块的运算映射;x和Wx代表输入和对应输入的卷积操作;σ表示Resnet 模块中的激活函数。因此在加入了Resnet 连接的反向传播中,如果对式(4)求x的偏导数可以得到如式(5)所示的结果:

所以当网络很深时,dF/dx有可能等于0,此时dy/dx恒等于1,对于整个网络的前向传播仍然有效。
为了方便反向传播求梯度,EPScGAN 生成器中的激活函数均使用线性整流单元(Rectified Linear Unit,ReLU)函数,ReLU函数的计算表达式如式(6):

从式(6)可以看出,ReLU 函数只输出大于0 的特征,因此在反向求梯度的过程中,该激活函数对输入x的偏导数恒等于1,所以使用ReLU激活函数可以加快网络的训练。
并且为了增加网络训练的稳定性,一般深度网络中的卷积操作后会用一个标准化层对卷积的输出进行标准化操作。标准化层的主要作用是将网络的输出一直保持在一个相同的分布区间,同时可以避免梯度消失,正则化网络和提高网络的泛化能力。常用的标准化方式为批量标准化(Batch Normalization,BN)[25],该标准化方式的计算表达式如式(7):

其中:x代表卷积层输出的特征张量B×C×H×W,B代表特征张量中批量样本的数量,C代表特征张量的通道数,H×W代表特征张量中的特征图谱;xi表示特征张量中的每个具体值;μ(x)和σ(x)为输出特征张量的均值和标准差。批量样本的数量会对批量标准化的效果产生重要的影响,但是批量样本的数量会受限于GPU 的显存大小。所以EPScGAN 中的所有标准化方式都采用了组标准化(Group Normalization,GN)[26]来替代BN。GN和BN的主要区别是GN首先将特征张量的通道分为许多组,然后对每一组做归一化,即将特征张量矩阵的维度由[B,C,H,W]改变为[B,C/G,H,W],然后归一化的维度(求均值和方差的维度)为[C/G,H,W],所以GN 的效果不会受到批量样本数量B的影响。生成器各层的详细结构如图3所示。
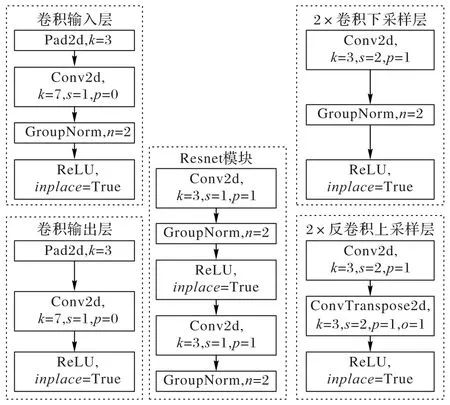
图3 EPScGAN生成器模块结构Fig.3 Module structure of EPScGAN generator
输入层的作用是用大卷积核的卷积操作将输入图像快速转化为稀疏多通道的特征映射,而输出层的作用是将特征反稀疏化,从而快速得到分割结果。EPScGAN 生成器的输出层末尾使用了双曲正切(hyperbolic Tangent,Tanh)激活函数对卷积输出进行激活。因为和生成器的深层卷积输出特征相比,输出层的卷积输出特征图中目标和背景的特征差异已经足够明显,并且Tanh激活函数是0均值输出,可以增大分割结果中背景和目标的差异性,使分割结果更加明显。
卷积下采样层的作用为下采样并融合特征,同时提升输出通道,增强特征的可表达性。EPScGAN 生成器的编码器使用了3 个相同结构的卷积下采样层,每个下采样层中的卷积都使用了3×3 的小卷积核,2×2 的卷积步长提取特征,并且对卷积运算前的输入特征进行了大小为1 的零扩充操作,从而保证了每个下采样层的下采样倍数都为2。反卷积上采样层的作用为上采样并解码深度特征,同时减少输出通道,融合解码后的特征来得到分割结果。类似于EPScGAN 生成器的编码器,EPScGAN 生成器的解码器使用了3 个相同结构的反卷积上采样层,每个上采样层中的反卷积都使用了3×3 的小卷积,2×2 的卷积步长提取特征,并且对反卷积运算输入特征和输出特征都进行了大小为1 的零扩充操作,从而保证了每个上采样层的上采样倍数都为2。
Resnet模块的作用为融合深度特征,增加网络容量,提升网络的鲁棒性,同时可以避免梯度消失。在EPScGAN 的生成器中用6 个相同结构的Resnet 模块串联融合特征,并且连接编码器和解码器。每个Resnet 模块的每个卷积中都使用了3×3 的小卷积核,同时为了保证输入和输出特征图的大小相等,每个卷积步长的步长都为1×1,并且对卷积输出的特征进行了大小为1的零扩充操作。
1.2 判别器结构
判别器的主要作用是判别生成器的生成图像和真实的标记图像。在GAN 中:生成器的优化目标是最小化生成损失,使得判别器很难判别生成图像和真实图像的差异,而判别器的优化目标是最小化判别损失,要尽可能地找出生成图像和真实图像的差异;在GAN 的训练过程中,判别器会逐渐地提升判别能力,生成器也会提升生成能力,并且指导生成器训练的反向传播误差损失来源于判别器。因此判别器相当于一个可训练的损失函数,它可以从深层的数据分布上计算生成器生成的结果和真实数据之间的差异,所以它可以很好地监督生成器的训练。判别器网络是一个编码器结构,因此判别器比生成器更容易训练。所以为了避免判别器判别能力过强而导致生成器训练崩溃的问题,同时为了防止判别器过拟合,EPScGAN 的判别器由2 个下采样层和3 个卷积过渡层构成。EPScGAN的判别器结构如图4所示。

图4 EPScGAN判别器结构Fig.4 Structure of EPScGAN discriminator
EPScGAN 判别器的输入为原始病理图像级联生成图像或真实标记图像构成的图像对,原始病理图像的作用是判别输入条件。在深度图像分类网络中,编码器的输出特征会被扁平化为特征向量,然后连接全连接层输出分类结果,因此分类网络的输入图像尺寸是固定的。但在分割模型训练的过程中,反向传播计算会消耗很大的GPU 内存,所以输入图像的尺寸一般都比较小,但是在测试过程中可以用更大尺寸的图像进行测试,所以分割网络的输入图像尺寸大小可以不固定。端到端的分割模型可以适应不同尺度的输入,但是GAN 中的判别器结构为一个二分类网络,所以为了能够分割多尺寸的图像,同时也为了稳定生成器的训练,EPScGAN 的判别器采用了Pix2pix中的patch-GAN技术。该技术是去掉了判别器中的特征扁平化操作和全连接层,直接让判别器输出一个单通道的特征图,然后用生成数据的判别特征和真实数据的判别特征进行特征匹配[27],这样就可以通过判别器输出特征的传递来更好地训练生成器,增强生成器的生成能力。常用的特征匹配损失函数为正则化损失函数l1 函数和l2 函数[28]。相对于l2损失函数,l1损失函数由于内置特征选择,所以有很多不确定解,因此鲁棒性更高。因此,EPScGAN 的判别器中使用了l1损失函数对两种判别特征进行特征匹配。
EPScGAN 判别器中使用了2 个相同结构的卷积下采样层,每个下采样层中的卷积都使用了4×4 的小卷积核,2×2 的卷积步长提取特征,并且对卷积运算前的输入特征进行了大小为2 的零扩充操作,从而有效地融合并下采样特征,同时稀疏化输出特征,并且避免了过多的下采样操作造成的细节特征丢失和过拟合问题。同时EPScGAN 判别器还使用了3 个相同结构的卷积过渡层,每个过渡层中的卷积都使用了4×4的小卷积,用1×1的卷积步长提取特征,并且对卷积运算前的输入特征进行了大小为2 的零扩充操作。因此过渡层不改变特征的尺寸大小,并且可以有效地融合特征,并通过零填充操作有效地稀疏化特征。EPScGAN 判别器的特征输出层为1个卷积层,该卷积层的卷积核大小为3×3,卷积步长为1×1,卷积输入零扩充的尺寸大小为1,这样就保证了不会对输出特征层进行下采样,同时输出的系数特征可以用l2 损失函数更好地进行特征匹配。
EPScGAN 的判别器中所使用的激活函数均为LeakyReLU。当输入的特征值小于零时,ReLU 函数的输出始终为零,所以其一阶导数也始终为零,这样就会导致神经元参数不再更新,出现“死神经元”现象。和ReLU 函数不同,当输入特征张量中的值小于零时,LeakyReLU 会有一个泄露值输出,因此使用LeakyReLU 函数可以避免判别器中出现“死神经元”现象。LeakyReLU函数的表达式如式(8)所示。

EPScGAN 判别器中所有的LeakyReLU 激活函数泄露值ε均设置为0.2。
1.3 损失函数
EPScGAN 使用了和Pix2pix相同的损失函数。式(3)计算的是cGAN 损失,主要的优化目标是生成器和判别器,为了增强生成器的生成能力以及稳定生成器的训练,损失函数部分还包括特征匹配l1 损失。l1 特征匹配的损失函数如式(9)所示:
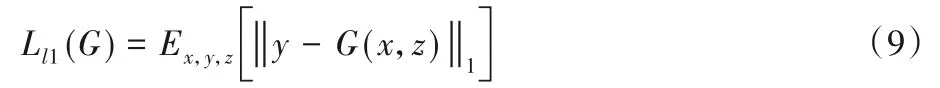
所以EPScGAN 的最终优化目标损失函数的表达式如式(10)所示:
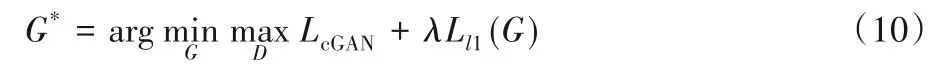
其中:λ为l1 损失的惩罚系数,通过多次实验发现,最终确定λ=10时训练最稳定。
2 实验与结果分析
2.1 实验数据
本文的实验数据集是由文献[29]中荷兰癌症研究所(Netherlands Cancer Institute,NKI)和温哥华综合医院(Vancouver General Hospital,VGH)两个单位提供的总共576张像素尺寸为1 128×720 的H&E 染色乳腺癌病理图像构成。其中NKI 提供了248 张,VGH 提供了328 张,每张图像都有病理专家手动标记的乳腺组织上皮和间质区域。本文在原始576 张1 128×720 大小的图像中随机裁剪出了1 286 张像素尺寸为512×512的图像作为最终的实验数据集。
2.2 实验结果
本文将1 286 张512×512 尺寸大小的H&E 染色病理图像按照7∶3 的比例随机地划分为训练集(900 张)和测试集(386张)对EPScGAN 模型和目前流行的医学图像分割网络进行训练和测试。本文使用的实验平台为Ubuntu 16.04 操作系统,Nvidia GTX 1080Ti 的GPU。网络固定的超参数为:优化器选用自适应的Adam[30],初始化学习率为0.000 2,训练的总迭代次数为200,深度学习框架采用Pytorch1.0。不同模型在测试集上的分割结果对比如图5所示。
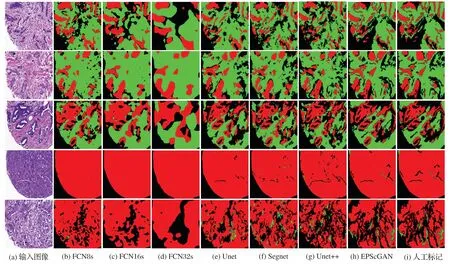
图5 不同模型的分割结果对比Fig.5 Segmentation results comparison of different models
从图5 所示的分割结果对比图中可以发现:FCN 的解码器比较弱而且和编码器不对称,所以很难准确地分割出上皮和间质组织区域;而其他4 种模型结构都采用了对称的编码解码结构,因此整体分割的效果比较好。本文对比了4 种对称结构的分割结果细节,如图6 所示,从分割结果的细节展示中可以发现:Segnet 和Unet++会把淋巴细胞区域误分割为间质组织区域(圆圈内所示),Unet、Segnet 和Unet++都容易把一些细小的间质区域漏掉(三角形所指和方框内所示)。
3 结果评估分析
3.1 多类像素准确率评估
为了定量的说明模型对不同区域的分割性能,使用了像素准确率(Pixel Accuracy,PA)[31]对背景,上皮组织和间质组织区域进行了评估,计算表达式如式(11):

其中:TP表示分割网络正确分为正样例的像素点数量(True Positive);TN表示分割网络正确分为负样本的像素点数量(True Negative);FP表示分割网络错误分为正样例的像素点数量(False Positive);FN表示分割网络错误分为负样本的像素点数量(False Negative)。像素准确率是评估语义分割结果的常用指标,反映了分割正确的像素点数量占所有分割像素的比例。对于每一类区域的类像素准确率(Class Pixel Accuracy,CPA)的计算公式如式(12)所示,最终的评估结果如表1所示。

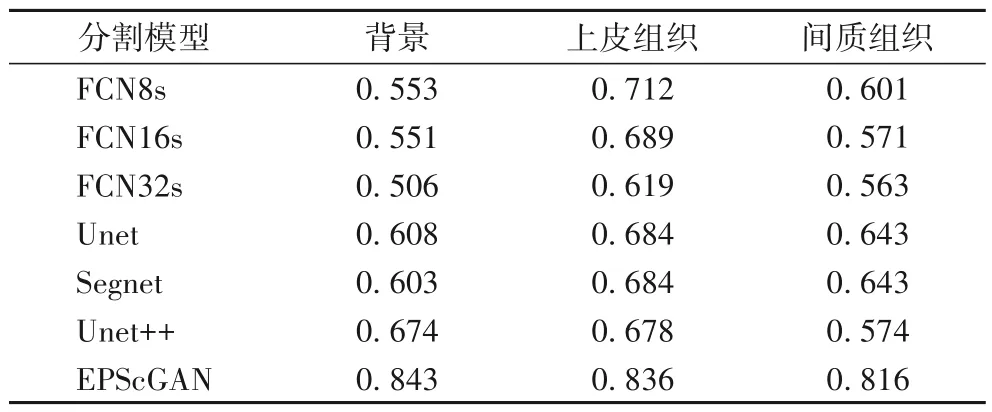
表1 不同模型的CPA评估结果Tab.1 CPA evaluation results of different models
从评估结果中可以看出,FCN 对上皮组织区域的分割准确率要高于对间质组织区域的分割准确率,同时对背景区域的分割准确率要远低于上皮区域。主要是因为FCN 的网络结构中解码器较弱,因此无法对一些细小的敏感区域进行精准分割。而Unet 对背景区域和间质区域的分割准确率较低,因为语义代沟的问题,所以无法很好地区分上皮和间质区域,Segnet和Unet++则对三类的分割都比较均衡。对比其他端到端的深度学习分割模型,EPScGAN 可以在保证三类分割比较均衡的前提下,每一类的分割像素准确率都达到最高。
3.2 平均交并比评估
平均交并比(mean Intersection over Union,mIoU)在深度学习图像分割领域中是一个衡量图像分割精度的重要指标。交并比(Intersection over Union,IoU)的计算公式如式(13)所示:

所以IoU 计算了分割结果和真实标记交集和并集的比例。先求出分割结果在每一类上的IoU 值,然后计算平均值就可以得到mIoU 值。不同模型在测试集上的mIoU 对比结果如表2所示。

表2 不同模型的mIoU评估结果 单位:%Tab.2 mIoU evaluation results of different models unit:%
从表2可以看出,本文提出的EPScGAN 模型在H&E 染色的上皮和间质组织区域病理图像分割任务中比其他的流行医学图像分割模型具有更高的分割精度。
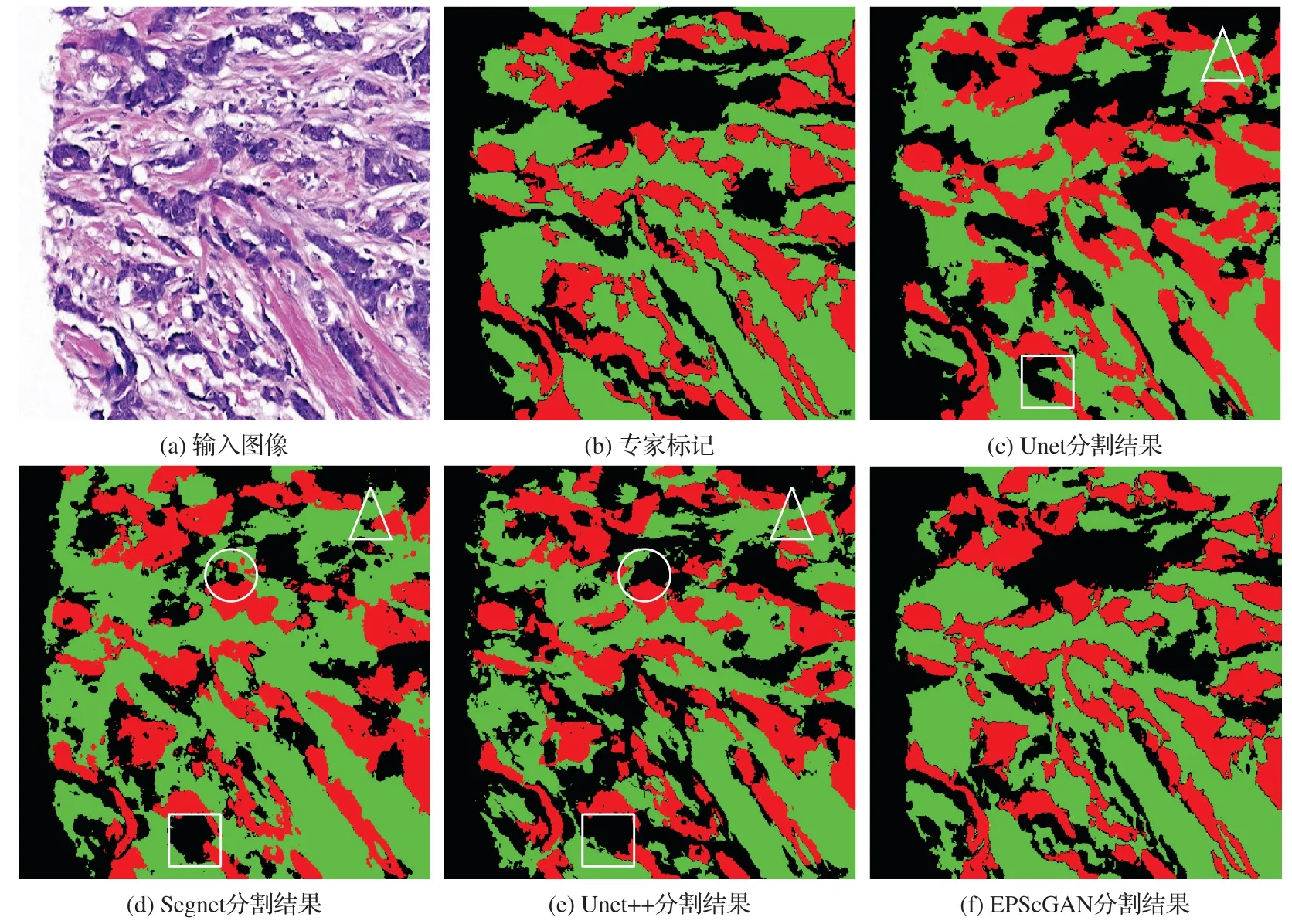
图6 对称结构分割模型的分割结果细节展示Fig.6 Detailed display of segmentation results of symmetric structure segmentation models
4 结语
为了有效地分割出H&E 染色病理组织图像中的上皮和间质区域,本文提出了基于cGAN 的分割模型EPScGAN。该模型中使用了Resnet 模块增加网络容量来提升网络的鲁棒性,同时使用了cGAN 中的判别机制来为生成器的训练提供了可训练的损失函数,使得网络得到了充分的训练。对比实验结果表明,与一般的深度分割模型相对比,EPScGAN 模型能够更加有效地提取上皮和间质组织区域的语义特征,并且对两种区域的多样性识别具有更高的鲁棒性。目前我们只使用了乳腺组织病理图像中的上皮和间质区域区域数据集进行了实验,因此下一步工作是把EPScGAN 模型用到其他的医学图像分割任务中,并和一般的深度分割模型作比较。
