基于多姿态特征融合生成对抗网络的人脸校正方法
2020-10-18林乐平李三凤欧阳宁
林乐平,李三凤,欧阳宁*
(1.认知无线电与信息处理省部共建教育部重点实验室(桂林电子科技大学),广西桂林 541004;2.桂林电子科技大学信息与通信学院,广西桂林 541004)
(*通信作者电子邮箱ouyangning@guet.edu.cn)
0 引言
近年来,视频监控已经成为保障城市安全的主要技术手段。在同一个监控环境中,不同的监拍设备有可能拍摄到同一个人不同姿态的脸部图像。为了充分利用多幅人脸图像进行识别、分类等应用,本文研究从多幅不同姿态的侧脸图像中恢复出正脸的问题。
人脸姿态校正的目的是从不同姿态的侧脸图像中恢复出一幅逼真且保持身份的正脸图像。针对从具有姿态变化的侧脸图像中恢复出正脸的问题,传统的人脸姿态校正方法[1-2]是通过2D/3D局部纹理变形[3]或者建模旋转[4]来生成正脸图像,但合成结果往往不具有真实感。近年来,深度学习强大的学习能力使网络模型能够直接学习端到端的非线性映射,而将侧脸图像转换成正脸的姿态校正问题恰可以视为侧脸到正脸的非线性映射。因此,基于深度学习的单幅人脸姿态校正技术[5-6]近年来取得了重大进展。Yin 等[7]提出了一种针对大姿态人脸校正的FF-GAN(Face Frontalization Generative Adversarial Network)方法,该方法将3D 形变模型[8]结合到网络中以提供形状和外观先验;Zhang 等[9]提出基于流型的人脸姿态校正 A3F-CNN (Appearance Flow-based Face Frontalization Convolutional Neural Network)方法,该方法通过学习非正脸和正脸之间的密集对应关系,移动非正脸像素来重建正脸,能较好地恢复真实正脸。Huang 等[10]提出双通路对抗网络(Two-Pathway GAN,TP-GAN),利用两个深度卷积网络分别学习侧脸图像的全局结构和局部纹理细节。该方法通过融合两条通路的全局信息与局部特征来进行正脸视图的合成,能够更好地保留轮廓信息。
在基于深度网络的人脸姿态校正中,往往只根据人脸图像的深层特征来重建正脸,而忽视了较多的浅层特征,没有充分利用不同卷积层之间的特征依赖关系。考虑到同一个人不同姿态的侧脸图像之间具有相关性与信息互补性,如果充分融合多幅侧脸之间的相关信息与互补信息,将有利于提升网络的人脸姿态校正性能。
本文利用深度网络进行从多幅侧脸图像中恢复出正脸图像的方法研究,提出了一种基于多姿态特征融合的生成对抗网 络(Multi-pose Feature Fusion Generative Adversarial Network,MFFGAN)的人脸校正方法,该方法通过充分融合多幅侧脸图像间的相关信息与互补特征来恢复正脸图像。同时,该方法与对抗网络[11]相结合,通过生成器与判别器的相互博弈,使姿态恢复过程受到更好的约束,能提高合成正脸图像的质量。Shi 等[12]提出的卷积长短期记忆(Convolutional Long Short-Term Memory,ConvLSTM)网络对解决长期依赖问题具有显著效果,已在自然语言处理[13]、时间序列预报[14]等领域得到了有效验证,ConvLSTM 的研究为融合多姿态特征来进行人脸校正奠定了基础。
1 基于多姿态特征融合的生成对抗网络
本文提出的网络模型如图1 所示,由生成器与判别器组成。其中,生成器部分由多姿态特征提取、多姿态特征融合、正脸合成三个模块组成。输入的待融合N幅图像记为{Ii},i∈{1,2,…,N}为输入的待融合图像的序号。
第一个模块是多姿态特征提取。该模块由四个卷积层组成,每层卷积核大小均为3×3,因为该尺寸的卷积核涉及的参数较少。多姿态侧脸图像输入后,使用多个卷积层来依次提取各幅人脸特征。第i幅侧脸图像Ii经过第j个卷积层进行提取的特征表示为fj(Ii)∈RH×L×D,其中,j∈{1,2,3,4}是多姿态特征提取模块的卷积层数,H×L×D为特征的尺寸及维度。
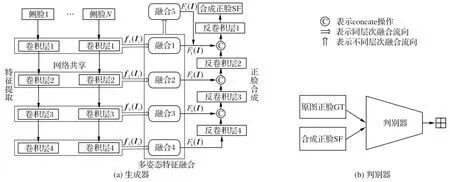
图1 基于多姿态特征融合的生成对抗网络结构Fig.1 Structure of generative adversarial network based on multi-pose feature fusion
第二个模块是多姿态特征融合。为了充分融合多幅侧脸图像的特征,该模块采用多支路方式对提取到的多姿态侧脸特征进行融合。每个支路均由多个ConvLSTM 单元组成。分别对应多姿态特征提取模块不同卷积层的同层次融合支路负责对相应卷积层提取到的多姿态特征进行融合,以探索多姿态特征之间的相关信息与互补信息。对多个融合特征进行探索的不同层次融合支路旨在探索多个融合特征之间的依赖关系,来融合不同卷积层的浅层特征与深层特征,以获取全局信息。
第三个模块是正脸合成。该模块首先对多幅侧脸图像的深层融合特征进行上采样操作,再将其他融合特征逐层添加到姿态恢复的过程中,以逐层补充人脸信息。通过逐层加入包含多姿态侧脸的相关特征以及全局特征,为正脸合成过程提供丰富的人脸信息,使网络能够从多幅不同姿态的侧脸图像中恢复出轮廓清晰的正脸图像。
由于基于博弈思想的生成对抗网络可以不断地推动生成器的输出去匹配真实正脸的目标分布,从而鼓励合成的图像驻留在正脸的流形中。因此,为了在训练过程中结合正面人脸分布的先验知识,本文遵循Shrivastava 等[15]提出的SimGAN对抗网络模型,引入一个由五个卷积层与两个最大池化层组成的判别器去区分真实的正面人脸图像与合成的正面人脸图像,如图1(b)所示。其中,前三个卷积核的大小为3×3,后两个卷积核大小为1×1,在第二个卷积层与最后一个卷积层之后均使用了最大池化操作。该判别器输出的不是一个标量概率值,而是2×2的概率图,其中每个概率值对应人脸特定的区域,而不是整张人脸,以此来关注人脸图像的多个区域。通过生成器与判别器的交替训练及相互制约,使得生成器合成的正脸图像逐渐向正脸原图靠近。多姿态侧脸具有丰富的相关信息与互补特征,有效地学习多姿态侧脸之间的依赖关系对正脸图像的合成至关重要。因此,本文设计的多姿态特征融合模块旨在从多个相互关联的图像中学习到丰富的人脸特征。
2 多姿态特征融合模块设计
为了充分探索多姿态特征之间的上下文关系,本文使用ConvLSTM 作为多姿态特征融合支路的重要组件。ConvLSTM是由特征存储状态ct和三个门控单元(遗忘门ft、输入门it、输出门ot)组成,通过门控单元实现对输入特征的剔除与增加来融合多姿态特征。
在多姿态人脸校正的过程中,获取全局信息与融合多幅侧脸相关特征对恢复出轮廓清晰的正脸图像至关重要。因此,多姿态特征融合模块采用同层次融合与不同层次融合的方式,以获取多姿态侧脸图像相关特征与全局信息。其中,同层次融合有四个支路,不同层次融合只有一个支路,且每个支路均由多个ConvLSTM 单元组成。
2.1 同层次融合
同层次融合的四个支路,分别对应多姿态特征提取模块中的不同卷积层,如图1(a)所示。每个支路将对应卷积层提取到的多姿态特征进行融合,以探索多幅侧脸之间的相关信息,增强网络的人脸校正性能。
在每个同层次融合支路,将多姿态特征提取模块提取到的多姿态特征,依次输入到不同时刻的ConvLSTM 单元。在每个ConvLSTM 内,输入特征fj(Ii)首先经过遗忘门,遗忘门根据当前的输入特征来决定从前一个特征存储状态ct-1中丢弃什么信息。然后输入门被激活,将输入特征累加到当前特征存储状态ct。ConvLSTM 最终状态ht的输出由输出门ot控制,公式如下所示:
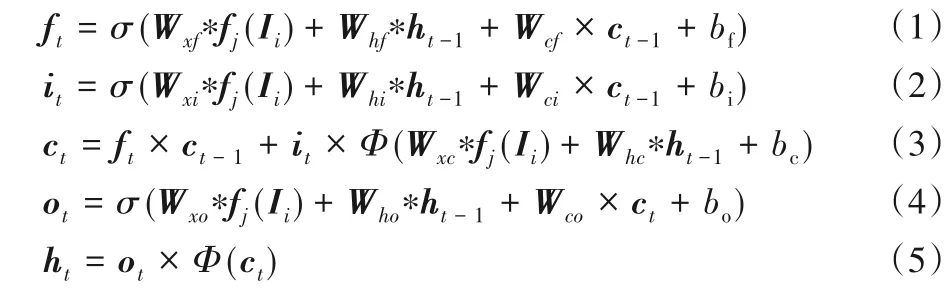
其中:σ与Φ分别表示sigmoid函数与tanh函数;W表示相应的权重矩阵;bf、bi、bc、bo表示偏置项;“*”表示卷积操作。
ConvLSTM 网络具有时间记忆性,即当前时刻的输出与前一时刻的输出有关,而本文多幅侧脸图像的输入顺序是随机的,当前时刻的特征状态不仅与前一时刻有关,还需要考虑未来时刻的特征信息,即特征融合模块的输出要联系上下文特征进行判断,因此本文特征融合支路的输出由前向与后向两个ConvLSTM 的最终输出状态共同决定,使融合特征得到更好的表达。公式如下所示:
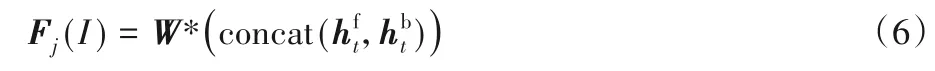
由式(1)~(6)可知,多幅侧脸图像的特征通过ConvLSTM的特征累加器ct传递,然后根据正反两个方向的输出状态与来获取多姿态特征的相关信息,因此,融合特征Fj(I)包含了丰富的多姿态侧脸信息。通过对特征提取模块每个卷积层进行同层次特征依赖关系的探索,使得融合后的特征能够充分地表达身份信息。
2.2 不同层次融合
不同层次融合只有一个支路,该支路是对多个同层次融合支路输出的融合特征进行探索。通过探索不同卷积层之间的特征依赖关系,进而从相互关联的浅层特征与深层特征中获取全局信息。
不同层次融合是对多个同层次融合支路输出的融合特征进行再次融合,以探索全局信息。但是,在将这些融合特征输入到不同层次特征融合支路之前,需要先将其上采样到统一维度,再依次输入到不同时刻的ConvLSTM 单元,执行与同层次融合相同的操作。该支路ConvLSTM 单元个数与同层次融合支路不同,同层次融合支路的ConvLSTM 个数由输入的多姿态侧脸幅数决定。而不同层次融合支路是对同层次融合特征的再次探索,因此,该支路的ConvLSTM 单元个数只与同层次融合支路的个数有关,如图2 所示。将经过上采样的四个融合特征输入到该支路不同时刻的ConvLSTM 单元,进行前向与后向的融合,来获取全局信息。

图2 不同层次融合支路Fig.2 Fusion branches of different levels
同层次融合旨在融合多幅侧脸图像间的相关特征与互补特征,而不同层次融合的目的是通过探索不同卷积层融合特征之间的特征依赖关系,来获取包含多姿态侧脸特征的全局信息,构建出一幅粗略的正脸结构,为重建高质量正脸提供丰富的人脸信息。通过多支路特征融合,能够减少信息的丢失,多姿态特征能够充分结合,使得融合特征能够较好地表达,促进网络合成轮廓清晰的正脸图像。
3 人脸识别开源项目face recognition
该项目是基于C++开源库dlib 中能够提供人脸关键点检测和人脸编码的深度学习模型,来进行打包创建的人脸识别项目模板。它适用于多种条件下的人脸识别,且操作简单,兼容多种电脑系统。使用包含13 000 多幅人脸图像的数据集(Labeled Faces in the Wild)进行测试,可以达到99.38%的准确率。该人脸识别开源项目的识别过程包括人脸检测、人脸关键点检测、人脸特征提取等步骤,最后通过分类器将人脸图像与数据库进行匹配。
具体来说,首先使用人脸检测器对输入图像(静止图像)进行人脸检测。为了检测图像中的人脸,该项目将人脸图像转化为灰度图像输入,因为不需要颜色数据来查找人脸。在一张图像中检测到人脸后不能直接进行识别,因为不同姿态的人脸在计算机看来是不属于同一人的。为了解决这个问题,该项目使用一个人脸对齐方法来估计人脸关键点位置,基本思想是训练一个深度学习方法以在人脸图像上找到68 个关键点,该方法不管人脸姿态如何变化,都可以经过仿射变换将眼睛和鼻子放在中心位置。然后,使用一个训练好的深度卷积神经网络来对仿射变换后的人脸图像进行特征提取,并得到128 维的人脸特征向量。识别人脸是整个过程中最简单的方法,该开源项目通过训练一个分类器,来将待识别的人脸图像分类到图像数据库中与之距离最接近的人,从而获取识别结果。
4 实验与结果分析
4.1 实验数据及网络参数
本文实验使用Multi-PIE(Multi-Pose,multi-Illumination,multi-Expression)数据集来进行网络的训练与测试。该数据集共收录了337 个人在四个不同时间段的人脸图像,并且每个时间段内的每个人有15种姿态,每一个姿态下又包含20种不同的光照。本文实验选取Multi-PIE 数据集中第一个时间段内人脸图像的子集,该子集包含337 个人的脸部图片,其中每个人都包含-90°~+90°范围内的13 种姿态,相邻两个姿态之间间隔15°,并且13种姿态包含了7种不同的光照。将该子集的前200人作为训练集,后137个人作为测试集。训练集与测试集的输入侧脸IP、正脸原图IF和恢复的正脸ISF都是大小为128×128×3的彩色图片。
实验中,本文方法MFFGAN 中生成器的结构参数如表1所示,训练时采用Adam(β1=0.9,β2=0.999)算法优化网络参数,学习速率为0.000 2,网络模型在显卡型号为P4000,显存为8 GB 的PC 上使用Tensorflow 深度学习框架进行训练与测试。
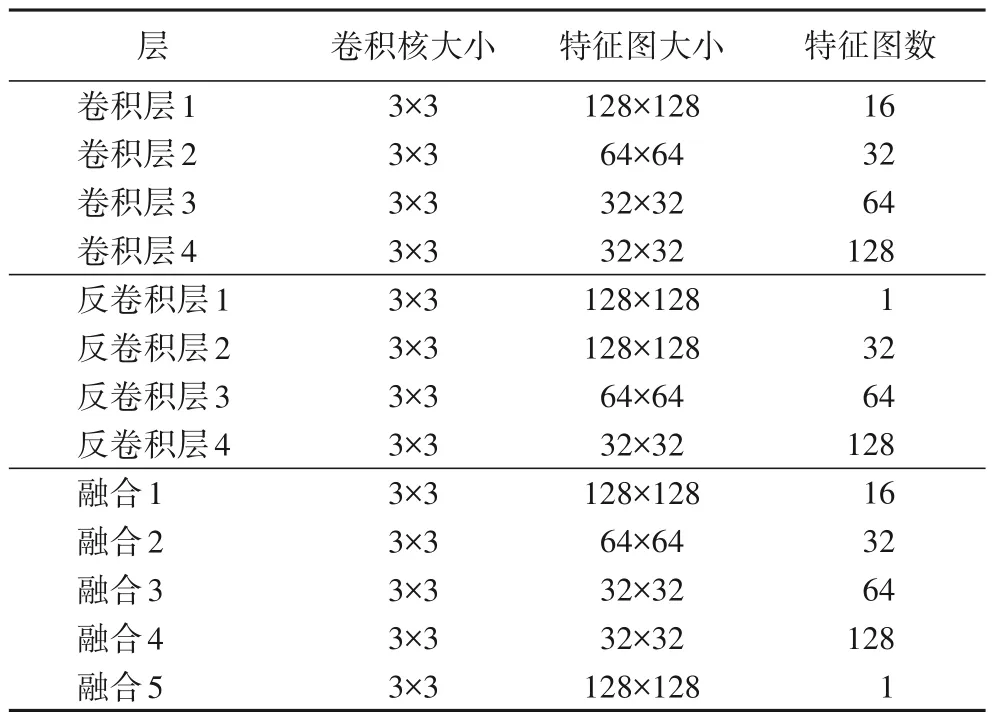
表1 MFFGAN生成器结构参数设置Tab.1 Structure parameter setting of MFFGAN generator
4.2 实验结果分析
为了验证本文方法的有效性,将多个侧脸特征直接级联融合的网络(Concat-Net)作为基准与本文MFFGAN 方法作比较;同时为了检验对抗机制对实验结果的影响,做了一组本文方法不使用对抗机制训练即去除判别器仅使用生成器进行网络训练的实验(MFF-Net)。该部分的对比实验是为了分别验证本文方法中融合模块与对抗机制训练的有效性,故依次删掉融合模块与判别器来进行实验。实验从如图3(a)所示的12种不同姿态的侧脸图像中完全随机不放回抽取n幅侧脸图像作为网络输入,其中n∈{2,3,4,6},则每个n值情况下进行校正后的正脸图像幅数分别为{6,4,3,2}。在输入相同的情况下,恢复出相应的正脸视图效果如图3所示。

图3 不同融合方式的校正效果Fig.3 Reconstruction results of different fusion methods
从图3 可以看出,当输入多张不同姿态侧脸图像时,本文所提出的融合方式在不加对抗训练(MFF-Net)与加了对抗训练(MFFGAN)的两种情况下,都比级联融合方式(Concat-Net)合成的正脸轮廓清晰。尤其是在对抗机制的辅助下,MFFGAN 合成的正脸图像能够保留更多的身份信息,使恢复出的正脸图像更接近原图。另外,随着输入侧脸图像张数的增加,本文方法校正的正脸效果也逐渐提升。尤其是在输入4张侧脸和6张侧脸的情况下,MFFGAN 合成的正脸五官轮廓已经基本贴近原图。这说明在使用对抗机制训练的情况下,通过融合同层次特征及不同层次特征,使得融合特征能够更好地探索多幅侧脸图像之间的相关信息,可以增强特征的表达能力,也说明了本文提出的基于多姿态特征融合网络的人脸校正方法有较好的姿态恢复能力。
表2 是在输入一致的情况下,Concat-Net、MFF-Net、MFFGAN 三种方法合成正脸的识别率比较,本文采用face recognition开源人脸识别库对合成的正脸图像提取人脸特征,再用最近邻分类器进行识别。从表2 可明显看出本文方法MFFGAN在多种输入情况下的识别率均远远高于级联融合方式Concat-Net 的识别率,且加入对抗机制训练网络之后能更好地调整参数,合成的正脸图像的识别率更高,进一步验证了本文方法的有效性。
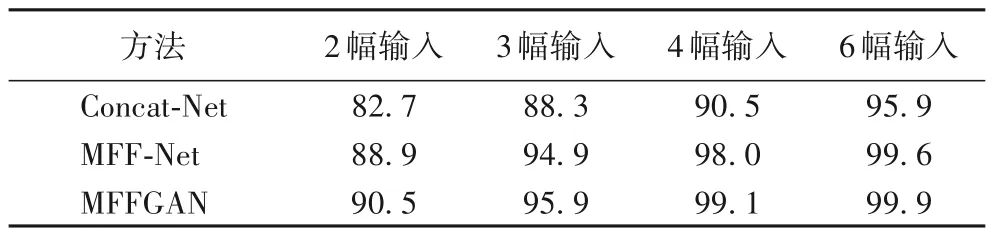
表2 不同融合方式的识别率 单位:%Tab.2 Recognition rate of different fusion methods unit:%
为了体现本文方法在输入不同侧脸图像的情况下,生成的正面人脸图像的差异,实验从-90°~+90°的侧脸图像中选取多组特定姿态的侧脸进行对比实验,如图4所示。图4中每个子图的第一行与第二行正面人脸分别是在特定姿态组合的情况下从多幅侧脸图像中恢复出来的,每幅正脸图像上方的数字是其对应输入侧脸图像的姿态。
图4(a)可以看出,组合2 中由两幅最小姿态(±15°)侧脸合成的正脸图像在眼镜部位,比组合1 中15°侧脸与90°侧脸结合恢复出的正脸要更清晰。但随着人脸偏转角度的增大,从对称的两幅侧脸图像中恢复的正脸图像逐渐偏离正脸原图。如图4(a)组合2 所示,当人脸姿态大于60°时,合成的正脸图像会丢失较多人脸特征,尤其是在90°的情况下,合成的正脸图像在五官轮廓上与正脸原图相差较大。而组合1 中由大姿态侧脸与小姿态侧脸两两结合生成的正脸图像整体真实度较高,不会出现严重失真现象。在图4(c)组合1 中的后两幅图像可以看到,在同样包含90°与60°的情况下,加入30°侧脸与加入75°侧脸对合成正脸的影响较大。由于输入的侧脸图像越多,相互之间的互补信息就越多,所以从4 幅和6 幅侧脸图像中恢复的正脸图像之间相差不大,如图4(d)与图4(b)所示。表3 是在图4 所述侧脸图像组合的情况下,使用Multi-PIE测试集做的人脸识别结果。

图4 不同组合侧脸校正结果Fig.4 Reconstruction results of different profile face combinations
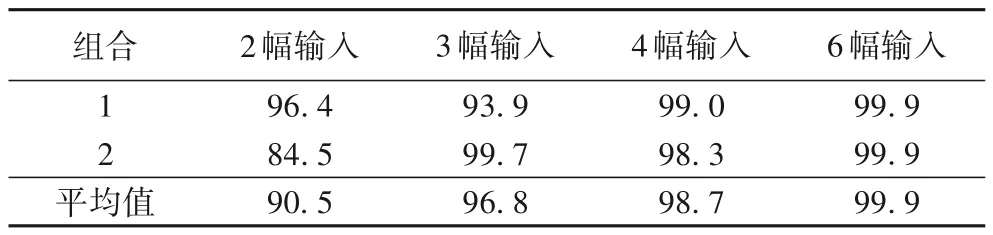
表3 不同组合侧脸校正的识别率比较 单位:%Tab.3 Comparison of reconstruction recognition rates of different profile face combinations unit:%
由表3 可知,在输入侧脸图像幅数相同的情况下,不同姿态组合产生的结果差异较大,尤其是在两幅侧脸输入的情况下差异最明显。这是因为大姿态与小姿态相互配合的情况下,小姿态具备的丰富特征能够大大提升大姿态的正脸重建效果;而相互对称的两幅侧脸随着人脸姿态的增大,遮挡造成丢失的人脸信息也是双倍的,较多的信息丢失不利于正脸的重建。随着输入侧脸幅数的增多,多幅侧脸之间的互补信息越丰富,合成正脸图像的质量就会越高,因此不同姿态组合产生的差距就会逐渐缩小。由于姿态变化对人脸识别的结果影响较大,所以特定姿态组合1与组合2的识别率并没有随着输入侧脸图像幅数的增加而提高。但是,两种组合识别率的平均值是随着输入侧脸图像幅数的增加而提高,这说明多幅人脸姿态校正能够提升人脸识别性能。
图5 是采用本文方法MFFGAN 校正后的正脸效果图,输入是从测试数据集中随机选取具有不同姿态且不同光照的多幅侧脸图像。观察图5 可知,由两张不同姿态侧脸图像恢复出的正脸图像已经较为准确,但由图5(a)可以看出,部分正脸图像在眼睛、头发等细节方面还有所模糊,与正脸原图有一些差距。但是,当输入3幅及3幅以上不同姿态不同光照的侧脸图像时,重建出的正脸图像已经基本接近于原图,视觉效果也更好。尤其是在输入6 幅侧脸图像的情况下,轮廓细节已经与原图相对一致,整体轮廓也更为清晰。这说明本文根据不同姿态侧脸图像间的相关性与信息互补性来恢复正脸,输入的侧脸图像张数越多,互补信息就越丰富,恢复出的正脸图像也就越准确。

图5 MFFGAN方法校正结果Fig.5 Reconstruction results of MFFGAN method
本文提出的多角度人脸姿态校正网络是目前为止第一个使用多侧脸进行人脸姿态校正的方法,不同于以往基于单幅图像的人脸姿态校正方法有特定姿态的识别率比较。由于本文输入的多幅侧脸图像是从15°~90°的12 种姿态中随机不放回抽取直至抽取结束,故包含了所有姿态,而其他方法是针对特定姿态的侧脸图像进行校正,将所有姿态的识别率进行平均值处理之后,平均值也包含了所有姿态,因此本文这部分是与当前人脸姿态校正方法识别率的平均值进行比较。本文方法MFFGAN 与当前TP-GAN[10]、LB-GAN(Load Balanced GANs for multi-view face image synthesis)[16]、A3F-CNN[9]三种人脸姿态校正方法相比较,识别率如表4~5所示。
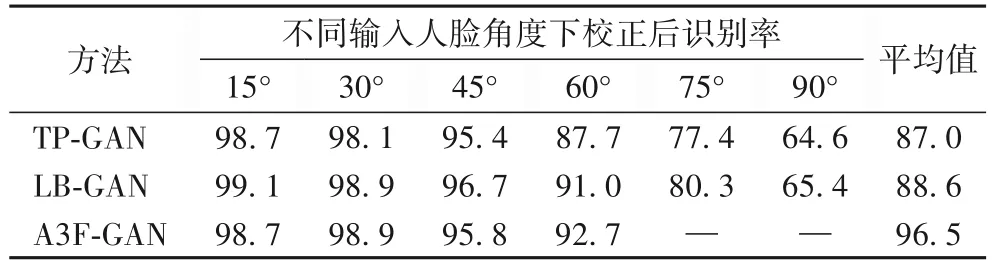
表4 不同方法的识别率和平均值对比 单位:%Tab.4 Comparison of recognition rates and average value of different methods unit:%
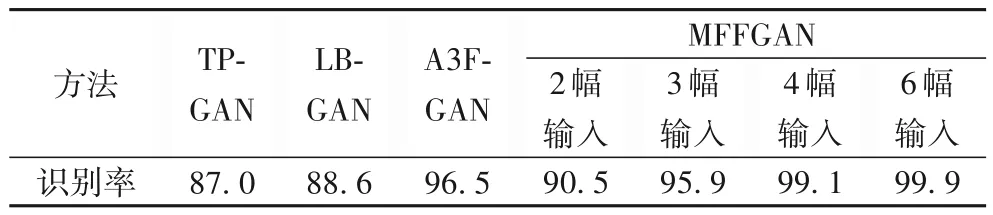
表5 MFFGAN与其他方法的识别率对比 单位:%Tab.5 Comparison of recognition rates result of MFFGAN and other methods unit:%
结合表4~5 可知:TP-GAN 与LB-GAN 没有很好地解决大姿态侧脸的问题,而A3F-GAN 没有做人脸姿态大于60°的实验,这是因为该方法是基于“搬运像素”而非“合成像素”的思想来进行姿态校正,但大姿态侧脸图像由于遮挡造成信息丢失,不利于“搬运”,说明大姿态角度侧脸仍然是人脸识别的一个重要挑战;而相比以上方法,本文研究方案不再将大姿态侧脸看作独立的问题,而是仿照人类视觉机制来充分利用多幅侧脸之间的相关信息来进行人脸姿态校正。实验结果显示:在输入2 幅不同姿态侧脸图像时的识别率比当前基于深度学习的单幅图像方法的识别率有了较大提升;当输入侧脸图像幅数为3 或者更多时,本文的人脸识别准确率相比其他方法的优势更加明显;尤其是输入图像幅数为6 的情况下,识别率已接近于100%,这是因为6 幅侧脸图像本身几乎已经包含了恢复正脸视图所需要的全部信息,所以当输入不同侧脸图像张数越来越多时,输入中所包含的人脸身份特征信息就越丰富全面,姿态校正效果就会越好,人脸识别率也就越高。
5 结语
本文提出的基于多姿态特征融合生成对抗网络的人脸校正方法融合了多幅侧脸之间的相关特征与互补特征,通过进行同层次特征及不同层次特征之间依赖关系的探索,联合多幅侧脸之间的相关信息来增强网络的重建性能。该方法首先依次提取多幅侧脸图像的人脸特征;再利用多姿态特征融合网络来融合多侧脸特征;然后在正脸合成的过程中逐层加入融合特征,为姿态恢复过程提供丰富的人脸信息,使网络合成视觉良好的正脸图像。实验结果表明,与目前基于深度学习的人脸姿态校正方法相比,本文方法充分利用了多张侧脸图像之间的依赖关系,使恢复出的正脸图像具有更清晰的五官轮廓,在图像视觉效果和识别性能上都有所提高。
