基于句子关联图的汉越双语多文档新闻观点句识别
2020-10-18黄于欣余正涛
王 剑,唐 珊,黄于欣,余正涛*
(1.昆明理工大学信息工程与自动化学院,昆明 650500;2.云南省人工智能重点实验室(昆明理工大学),昆明 650500)
(*通信作者电子邮箱ztyu@hotmail.com)
0 引言
汉越双语观点句识别旨在从描述同一事件的多篇汉越双语新闻文档中识别出能够传递作者情感、表征作者观点的句子,对开展跨语言事件分析和舆情分析等有着重要的支撑作用。
传统的观点句识别任务包括单语言观点句识别和跨语言观点句识别。单语言观点句识别主要利用单语信息,基于情感词典或机器学习算法实现观点句识别。前者主要依据情感词典来判断句子是否包含情感特征。如文献[1]通过建立观点词集,通过计算句子中观点词的强度来实现观点句识别。基于机器学习方法则将观点句识别视为传统的分类任务,通过选择合适的主客观分类特征和机器学习分类算法实现观点句分类;文献[2]利用主观词和客观词作为分类特征训练朴素贝叶斯分类器来实现观点句识别;文献[3]中提出了通过隐马尔可夫模型抽取情感特征,对句子进行序列标注,通过赋予句子不同的权重来实现观点句的识别。相比单语观点句识别任务,跨语言观点句识别相关研究较少。目前常用的主要有基于双语词典、基于平行语料和基于机器翻译和基于双语词嵌入模型的方法。基于双语词典方法的是将句子看成要素的集合,通过预先构造的双语对齐词典来实现跨语言句子要素对齐,然后基于双语对齐要素实现观点句识别。基于平行语料的方法则利用平行语料间的对齐关系进行映射,得到目标语言信息。文献[4]利用词对齐的双语平行语料进行跨语言观点挖掘,提出了一种基于依存关系的细粒度观点挖掘算法;文献[5]中提出了一种利用源语言主客观分类器及平行语料来对目标语言进行观点句分类。然而这类方法要求在做观点句识别时,必须有高质量的平行语料。基于机器翻译的思想是利用机器翻译将源语言翻译为目标语言,将跨语言问题转换为单语言观点句识别。文献[6]中提出了源语言翻译到目标语言和目标语言翻译到源语言两种跨语言方式,然后在单语上进行观点句分类。这类方法过于依赖于机器翻译的性能,而越南语属于低资源语言,机器翻译性能不佳。因此基于机器翻译的跨语言观点句识别方法在汉-越等低资源语言上不适用。近年来,利用双语词嵌入来实现跨语言文本的语义空间对齐,解决不同语言之间差异性成为了重要的研究方向[7-9]。如文献[7]中提出了一种基于注意力机制(Attention Mechanism)的跨语言表征方法,并结合长短期记忆网络(Long Short Term Memory Network,LSTM)实现跨语言情感分类;文献[10]中提出一种基于双语词嵌入,融合主题特征、位置特征和情感特征的跨语言观点句识别方法。综上所述可以看出,通用的观点句识别任务,不管是单语言还是跨语言,都将其作为一个基于句子内部情感特征的分类任务,而很少考虑不同句子间的关联关系对观点句识别的影响。
针对汉越双语多文档新闻观点句识别任务,仅通过判断句子内部的情感特征难以达到很好的效果。在描述同一事件的多语言文档中,句子之间存在复杂的关联关系,这些关联关系对观点句识别有着重要的支撑作用[11-12]。基于此本文定义了两类关联关系,即事件要素关联和情感要素关联。如表1所示,汉越双语话题“一带一路”中的两个句子均包含事件要素“阮春福”“中国北京”,这种关联称为事件要素关联。此外,这两个句子均出现了情感词“重要”,这种关联称为情感要素关联。本文认为具有较强关联关系的句子是不同来源媒体所共同关注的焦点,更容易成为观点句。因此提出通过构造句子之间的关联关系图来表征多语言、多文档句子之间的关联特性,并结合深度学习框架,融合句子编码特征和关联特征实现跨语言观点句分类。

表1 汉越双语新闻文档示例Tab.1 Example of Chinese-Vietnamese bilingual news document
1 基于句子关联特征的观点句识别模型
本文提出了一种基于双向长短期记忆(Bi-directional Long Short Term Memory,Bi-LSTM)网络[13]和句子关联特征的汉越双语新闻观点识别模型。首先构建汉越双语句子关联图,生成句子关联特征;然后基于双语词嵌入和Bi-LSTM 获得汉越双语同一语义空间下的表征;最后联合句子的编码特征和关联特征构造观点句分类器。总体结构如图1 所示,模型共分为四个部分:句子关联图构建、双语词嵌入层、编码层和观点句分类层。图1中:wi,k表示第i个句子的第k个词;hi是句子编码表示;ea表示相同语言顶点之间的边;eb表示不同语言顶点之间的边;v1、v2、v3、v4代表汉语句子;va、vb、vc、vd代表越南语句子;Avg 表示对句子编码特征和句子关联特征加权平均来获得最终的观点分类特征。
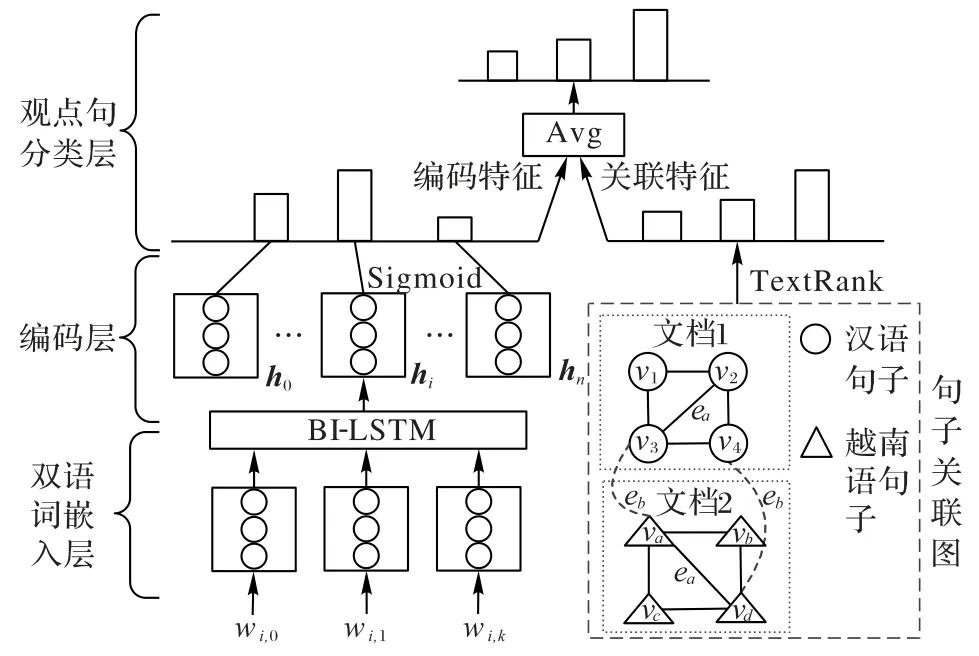
图1 基于句子关联特征的汉越双语新闻观点识别模型Fig.1 Chinese-Vietnamese bilingual news opinion sentence recognition model based on sentence association features
1.1 汉越双语多文档新闻句子关联图构建
汉越双语多文档句子关联图能够体现不同语言、不同文档的句子间关联关系,对于开展多文档观点句识别有着一定的支撑作用。首先定义了事件要素关联和情感要素关联两种关联关系;然后构造以汉越双语句子为顶点,以关联关系为边的句子关联图;最后基于句子关联图,通过TextRank 算法[14]计算句子的关联特征。
1.1.1 事件要素关联
事件要素包含事件发生的时间、地点、人物和组织机构等信息。利用不同新闻句中事件要素的共现次数来表示不同句子间事件要素的关联强度。具体来说,首先抽取汉越双语新闻句子中的命名实体作为事件要素,得到的汉语事件要素的集合记为和相应的越南语事件要素集合记为。对于汉越双语句子sk,将其表征为相应要素集合,即:sk={a1,a2,…,ak},其中事件要素ak为汉语或越南语对应的事件要素。为了计算不同语言句子的要素关联强度,首先利用汉越双语词典对抽取的要素进行对齐,得到对齐的汉越双语事件要素集合Acv=。最后通过计算不同句子的事件要素共现次数来确定其关联强度,共现次数可以通过判断两个句子是否包含相同的要素,即任意语言的两个句子si、sj的要素集合是否存在交集。特别说明,不同语言句子的要素关联强度需要利用对齐的汉越双语事件要素集合中的实体共现来实现。具体计算如式(1)所示:

其中:C(si∩sj)表示新闻句si和sj的共现要素数;C(si)表示句子si的要素个数。
1.1.2 情感要素关联
情感要素关联是指汉越双语新闻句子中包含的情感词的关联关系,通过计算不同句子间情感词的相似性来衡量其关联关系。为了实现情感要素关联,首先抽取不同语言新闻句中所包含的情感词,其中,汉语新闻句情感词抽取利用知网情感词典和台湾大学情感词典[15],提取出每个句子中的情感词集。针对越南语情感词典资源缺乏的问题,采用汉越双语词典翻译汉语情感词典,来构建越南语情感词典。抽取后得到每个越南语句子中包含的情感词集合。通过计算任意两个句子si和sj所包含情感词的相似性作为句子的情感关联强度。其中情感词相似性通过汉越双语词向量的余弦相似度得到,如式(2)所示:
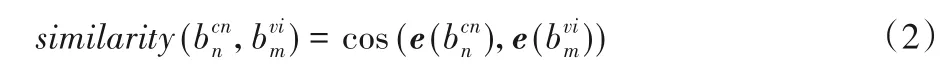
最终两个句子的情感关联强度通过计算两个句子的所有情感词相似度的最大值得到。如式(3)所示:
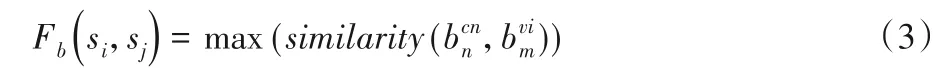
1.1.3 汉越双语多文档句子关联图的构建
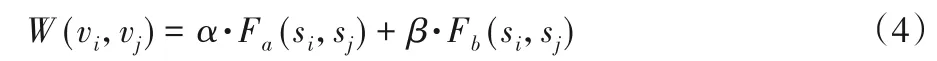
其中:Fa(si,sj)为句子的要素关联强度;Fb(si,sj)为句子的情感关联强度。特别说明,为了降低模型的复杂性,设置边的权重阈值ε,如果W(vi,vj) >ε则保留这条边,反之则删除这条边。
最后在已构建的图G上,利用TextRank 算法计算得到汉越双语的句子关联特征,如式(5)所示:
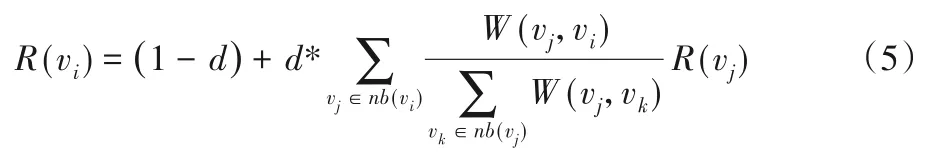
其中:R(vi)是句子vi的句子关联特征;W(vj,vi)为顶点vi和vj的边的权重;nb(vi)为与vi有关联关系的邻居节点;d=0.85,为阻尼系数。
1.2 双语词嵌入层
双语词嵌入的目的是为了把不同语言的词语映射在同一语义空间内,以实数向量的形式来表示词语,同时保证语义相近的词语在向量空间上也足够接近,是一种解决跨语言问题的通用框架。首先利用双语词向量模型将汉语、越南语两种不同的语言映射到同一个语义空间下。对于给定的句子si={wi,1,wi,2,…,wi,k},其中wi,k表示第i个句子的第k个词,利用式(6)计算得到其双语词嵌入表征:

1.3 语义编码层
编码器的目标是把输入的文本映射为向量表示,获取其深层的语义特征。使用双向长短期记忆(Bi-directional Long Short Term Memory,Bi-LSTM)网络作为编码器,编码器在接收到每个双语词向量后,顺序更新其隐藏状态,输出句子向量。具体来讲,通过Bi-LSTM 编码器对双语词嵌入进行编码,如式(7)所示:

其中:ei,k为在第i个句子中第k个词的双语词向量表示;hi,k为隐层向量。编码状态中,前向LSTM 顺序读入句子中包含的每个词产生前向隐式状态序列,其中表示第i个句子中第k个词,后向LSTM 逆序读入句子中包含的每个词产生后向隐式状态序列,采用编码器最后时刻的前向和后向对应的隐层状态拼接,构成句子的编码表示,如式(8)所示:

1.4 观点句分类器
在获得句子的语义编码之后,需要对其进行降维来获得其语义特征,如式(9)所示:

其中:Ws和bs为训练参数;sigmoid函数为激活函数。
最后联合句子关联特征和句子语义特征获得最终的观点分类特征,如式(10)所示:

采用二分类的交叉熵损失函数对模型进行优化。

其中:yi是第i个样本的标签;是模型预测样本是正样本的概率。
2 实验与结果分析
2.1 数据集构造
由于目前还没有公开的汉越双语新闻语料,因此利用爬虫工具从中文新闻网站和越南新闻网站收集新闻文档。选择三个中越共同关心事件的双语新闻文档作为数据集,共计200 篇文档,2 832 个句子,详细信息如表2 所示。对每个话题下的新闻文档按照90%、5%、5%随机划分训练集、验证集和测试集。

表2 汉越双语新闻文档数据集Tab.2 Dataset of Chinese-Vietnamese bilingual news documents
2.2 评价指标
采用准确率P、召回率R、F1值作为评价指标。计算公式如下所示:

其中:a表示模型将观点句预测正确的个数;b表示模型将非观点句预测为观点句的个数;c表示模型将观点句预测为非观点句的个数。
2.3 实验参数设置
采用的2 层的Bi-LSTM 网络获取汉越双语的语义特征,其中双语词嵌入维度为300 维。Bi-LSTM 隐状态设置为512维。为避免模型过拟合,dropout 设置为0.3。模型训练批次大小设置为64,训练200轮次。采用Adam 优化器对模型进行优化,学习率为1E -3,同时在模型训练过程中加入梯度裁剪,最大梯度裁剪为5。
2.4 实验结果及分析
为了验证本文方法的有效性,第一组实验在7 个基准模型上进行实验,结果如表3 所示。其中:卷积神经网络(Convolutional Neural Network,CNN)设置卷积层和全连接层皆为一层,卷积滤波器的大小设置为2、3、4;单向长短期记忆网络(Long Short Term Memory Network,LSTM)参数设置与Bi-LSTM 相同,具体如2.3 节所示。仅使用关联特征则利用TextRank算法得到的关联特征值对句子进行排序得到相应的观点句。

表3 不同模型观点句识别结果Tab.3 Results of opinion sentence recognition of different models
从表3 可以看出,三种模型在都不使用关联特征时,Bi-LSTM 模型取得了最佳的性能,这也说明Bi-LSTM 在文本数据上强大的建模能力。但是同时可以看出,在不使用关联特征时,性能最佳的Bi-LSTM 模型也仅能获得63.8%的准确率,比仅利用关联特征的准确率低了7.4%。这也说明了在多文档观点句识别过程中,模型仅依赖深度学习模型的输出无法得到很好的语义表征。本文认为造成这种现象有两个原因:一个是因为数据集规模较小,模型训练不充分;另一个原因是汉越双语词向量质量不高,在词嵌入阶段存在误差。另外还能看出,仅使用关联特征相比三种深度学习模型在准确率、召回率和F1值均能够获得较好的性能,这也说明了本文提出的句子关联特征建模方法是有效的,并且在深度学习模型中融入句子关联特征是有效的。最后可以看出,联合建模深度学习模型和句子关联特征,模型性能有一个较大幅度的提升。相比Bi-LSTM 模型,加入句子关联特征,模型准确率提升了15.1%,相比仅使用关联特征,模型准确率提升了7.7%。这些都充分说明了本文提出的结合语义特征和关联特征能够有效提升汉越双语多文档观点句识别任务的性能。
第二组实验是为了验证式(4)中参数α和β对模型性能的影响,这两个参数分别表示事件要素和情感要素在计算关联特征时的比例对关联特征有着重要的影响。实验结果如表4所示。
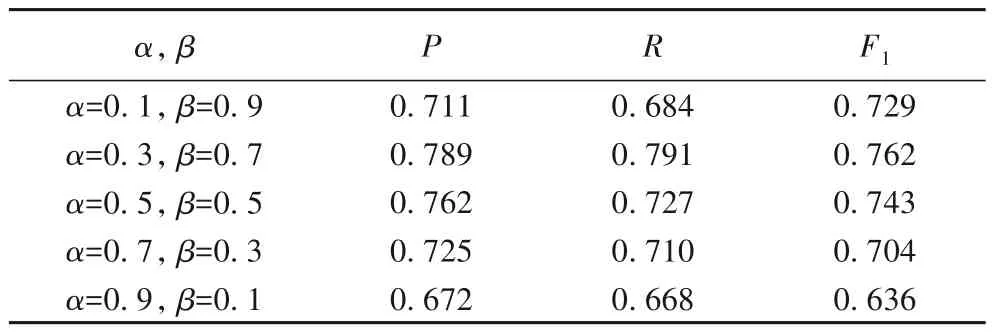
表4 超参数α和β对模型性能的影响Tab.4 Effect of hyper-parameter α and β on model performance
从表4 可看出,模型在α=0.3,β=0.7 时取得了最佳性能,这也表明情感要素在计算关联特征时更重要。本文认为这也说明了观点句识别中情感词仍然是一个重要的影响因素。当α=0.9,β=0.1 时模型性能最差,这也反映了仅使用事件要素来表征关联特征并不能很好地反映不同句子之间的情感关联关系。
设计第三组实验来验证超参数ε对模型性能的影响,其大小决定了多文档关联图的稀疏程度:ε值越大,则关联图越稀疏;反之则越稠密。实验结果如表5所示。
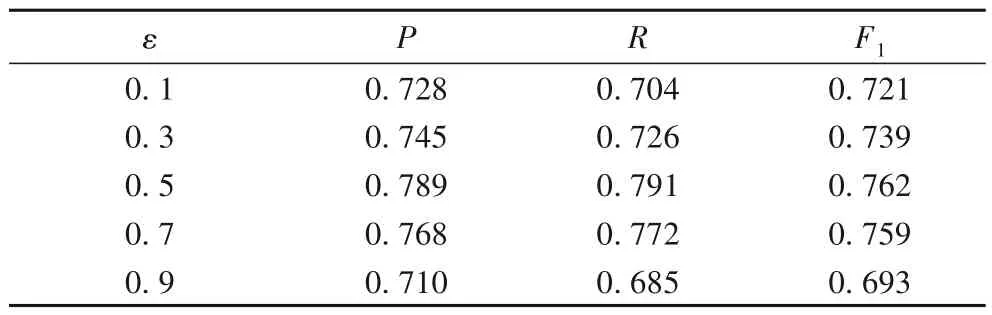
表5 超参数ε对模型性能的影响Tab.5 Effect of hyper-parameter ε on model performance
从表5可以看出,超参数ε=0.5时模型性能最佳。同样可以看出ε过小或者过大,模型性能均有显著的下降。特别是ε=0.9 时,相比ε=0.5,模型F1值下降了6.9%,这也说明ε=0.9 时,图模型过于稀疏,很多句子间的有用的关联关系被丢弃,从而导致句子关联特征产生较大偏差。
3 结语
针对汉越双语多文档观点句任务,提出一种在深度学习框架下,在模型分类层融入句子关联特征的观点句识别方法。实验结果表明,融入句子关联特征能够显著提升汉越双语观点句识别模型的性能。在下一步研究中,拟开展利用深度神经网络联合训练句子关联特征和句子语义特征,探索利用图卷积神经网络等方式利用句子关联图来提升观点句识别模型性能。
