一种基于卷积神经网络的入侵检测方法
2020-10-15时东阁章晓庆毛保磊李润知林予松
时东阁 章晓庆 毛保磊 李润知 林予松,2*
1(郑州大学互联网医疗与健康服务河南省协同创新中心 河南 郑州 450052) 2(郑州大学软件学院 河南 郑州 450003)
0 引 言
随着科学技术的发展,互联网走进了千家万户,在给我们生活带来便利的同时,也带来了网络安全问题。工业界和学术界采取各种技术和措施解决网络安全问题,其中入侵检测系统(Intrusion Detection System,IDS)是网络安全体系的重要组成部分,一直以来备受网络安全领域学者的关注。IDS作为防火墙后第二道安全屏障,从网络中收集信息并进行分析,从中发现违反安全策略的网络行为,并和其他设备联动做出响应。虽然当前人们信息安全意识在不断提高,但网络攻击的复杂性以及攻击手段的多样性,使得信息安全事件频繁发生。海量复杂且标签不平衡的入侵数据,给入侵检测带来了重大的挑战。如何有效地从入侵数据中选择特征进行多分类,并提高入侵检测的精度,在网络安全领域具有重要的研究价值和广阔的应用前景。
1 研究现状
目前,将机器学习和深度学习应用于入侵检测领域是个重要的课题。机器学习能对特征进行学习并发现重要特征,利用机器学习的方法可以将入侵检测转化为对网络中正常和异常行为分类的问题。Balabine等[1]提出了SVM算法应用于网络流量异常检测的专利;Pan等[2]和Tahir等[3]将K-means和SVM算法结合用于入侵检测;Ambusaidi等[4]采用网络流量的相关性检测网络的恶意行为;聚类也是常用的入侵检测方法,基于聚类的入侵检测主要包含有常规聚类方法[5]和联合聚类方法[6]。上述方法虽然有较高的检测率,但是由于数据的维度较大,特别在数据处理阶段会依据专家经验进行特征提取,这不仅需要较长的时间来选择合适的特征,还可能破坏数据之间的相关性,从而漏掉一部分有效特征。
近年来,深度学习在语音识别、图像识别和自然语言处理等领域取得了不错的成果[7]。深度学习可以从原始特征提取出抽象的高层特征,不需要依据专家经验进行特征选择,因其强大的学习能力,国内外已有学者尝试将深度学习技术应用于网络安全领域中。文献[8]将J48决策树应用到NSL-KDD[9]数据集上进行入侵检测;文献[10]将数据集的70%作为训练集,剩余部分作为测试集,利用ANN进行入侵预测;文献[11]将随机树应用于入侵检测中并取得了不错的成果。上述方法虽然取得了不错的效果,但是其在模型训练和测试时只使用了官方的训练集,具有一定的局限性。此外,官方测试集中攻击方法比官方训练集的攻击方法多17种,因此本文在模型的训练和测试中分别采用官方训练集和官方测试集,这样有利于提高模型的健壮性。
本文提出了一种基于卷积神经网络的入侵检测模型(CNN-Focal)。该模型将卷积神经网络(Convolutional Neural Network,CNN)中的门限卷积[12]和Softmax[13]应用于入侵检测领域中进行多分类,针对不平衡数据集[14]采用Focal Loss[15]损失函数进行优化,有效提升了入侵检测精度。
2 CNN-Focal入侵检测模型
2.1 卷积神经网络基本原理
在深度学习领域中,卷积神经网络(Convolutional Neural Network,CNN)是一种高效的神经网络模型,已成为众多领域的研究热点。卷积神经网络的基本结构由输入层、卷积层、池化层、全连接层和输出层组成,如图1所示。在一个模型中卷积层、池化层和全连接层可以有一个或者多个,其中卷积层和池化层二者一般交替出现,即卷积层连接池化层,或池化层后连接卷积层,以此类推。全连接层一般紧随在池化层后面。
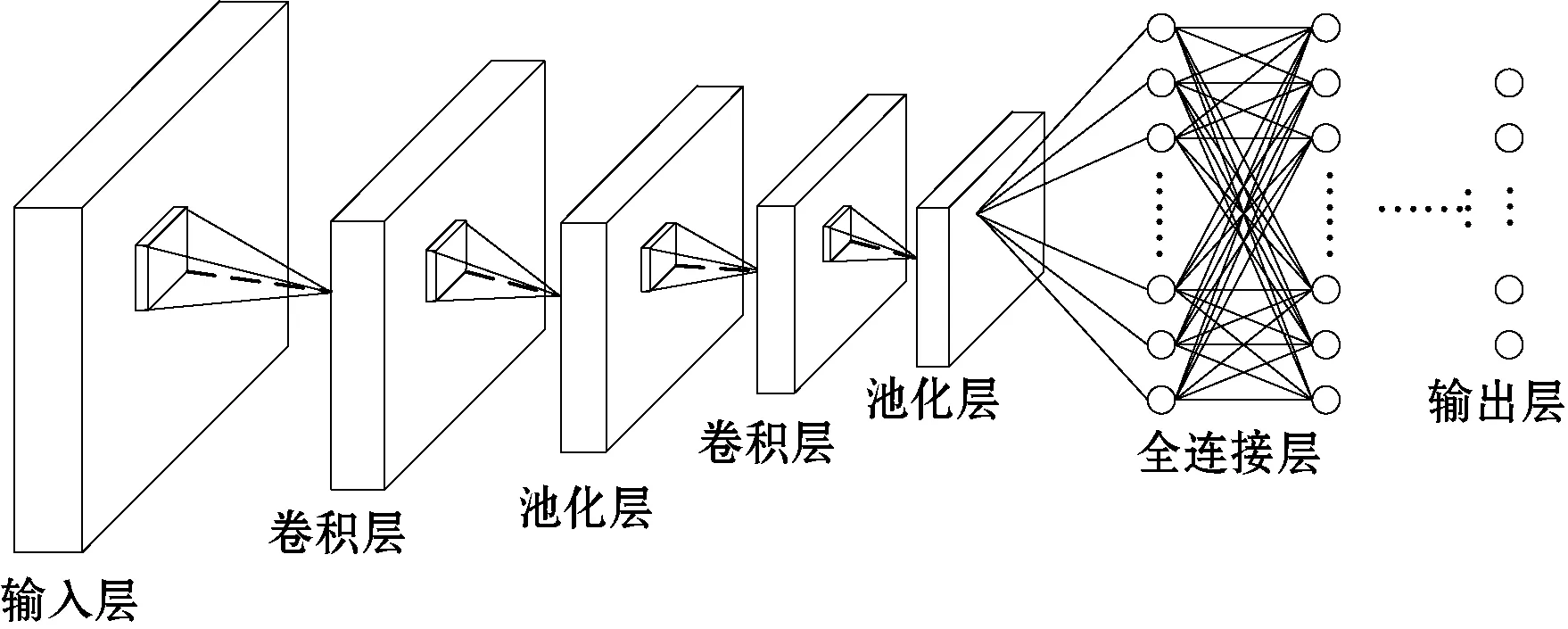
图1 卷积神经网络基本结构
全连接层中每个神经元与前一层所有神经元进行全连接,位于CNN结构的末端。通常在全连接层之后是输出层,即分类层。输出层对卷积神经网络提取到的特征进行分类,分类的输出即为结果。
Softmax回归是Logistic回归模型的推广,主要用于多分类。当进行2分类的时候,Softmax回归会退化为Logistic回归。在多分类问题中,类标签y取两个以上的值,即类标签y有k(k为大于2的整数)个不同的值。给定的数据集{(x1,y1),(x2,y2),…,(xn,yn)},yi表示第i类标签,i∈{1,2,…,k}。对于给定的x,Softmax回归估计出x在k类标签中每一类的概率。
损失函数(Loss function)是用来评估模型的预测值f(x)和真实值Y的差别程度,通常表示形式为L(Y,f(x))。损失函数反映了模型的鲁棒性,即损失函数值越小,模型的鲁棒性越好。
2.2 网络结构
入侵检测问题是一个分类问题,可以通过有监督学习训练出分类模型,然后使用训练的模型对未知数据进行预测。在使用卷积神经网络时,输入层输入数据通常是二维的,入侵记录是一维数据,因此在卷积操作选择方面,本文采取一维卷积方法对入侵记录数据进行卷积操作。根据NSL-KDD标签不平衡和模型实际分类性能等情况,本文设计了CNN-Focal模型,其结构如图2所示。CNN-Focal模型共有10层,1个输入层、3个卷积层、3个Dropout层、1个Max-pooling层、1个全连接层和1个Softmax层。
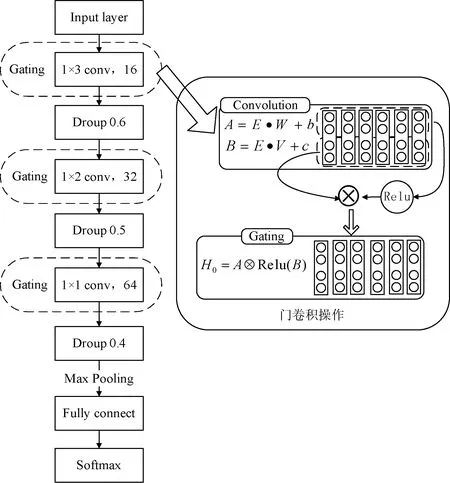
图2 CNN-Focal模型结构
该模型具体描述如下:
1)输入层:第一层为输入层。入侵记录是一维数据,经过数据标准化、one hot预处理后,单条入侵记录数据由1×41转换为1×122。
2)卷积层:第2、4、6层都是卷积层。在卷积层使用了门限卷积的概念,门限卷积中分为两部分:一部分是卷积的激活值,即B;另一部分是直接线性得到卷积,即A。A、B两部分相乘得到相应的卷积值。已有不少文献证明较小的卷积核能得到更好的局部特征和分类性能[16],因此在卷积核大小的设计方面,CNN-Focal采用了小卷积核策略,卷积核大小分别为1×3、1×2和1×1,卷积核的个数分别为16、32、64。除此之外小卷积核可以对学习到的特征进行聚类,在一定程度上缓解卷积冗余对模型性能的影响。
3)Dropout层:卷积神经网络模型在训练过程中容易出现过拟合现象,过拟合对模型实际性能影响很大。为了缓解此问题,CNN-Focal模型中第3、5和7层都采用了Dropout。Dropout值的大小分别设置为0.6、0.5和0.4,这是根据CNN-Focal模型实际分类效果进行设置的。
4)Max-Pooling层:池化层能减小计算量,CNN-Focal模型第8层为Max-Pooling层,stride为2,即参数数量减少为原来的一半。
5)全连接层:CNN-Focal中全连接层神经元的个数为200。
6)Softmax层:在深度学习中,Softmax回归通常作为标准的分类器用于多分类或二分类问题。CNN-Focal采用Softmax回归作为多分类器。
2.3 优化策略
在模型训练中一般会遇到收敛速度慢、数据不平衡、耗费资源大等问题,因此需要引入相应的优化策略减少这些问题带来的负面影响。为了提高CNN-Focal模型的性能,本文采用以下三种优化策略。
1)批标准化(Batch Normalization)。在深度学习中,深度网络参数训练时内部存在协方差偏移(Internal Covariate Shift)现象。根据链式规则,随着层数的增加,偏移现象会被逐渐放大,这将影响网络参数学习。因为神经网络的本质是表示学习(Representation Learning),如果数据分布发生改变,神经网络不得不学习新的分布。批标准化对每一层都进行标准化处理,使输入样本之间不相关。通过标准化每一层的输入,使每一层的输入服从相同分布,因此克服内部协方差偏移的影响。批标准化可以看做对输入样本的一种约束,最大作用是加速收敛和提高模型分类性能。
2)损失函数优化。本文采用的入侵检测数据集的标签分布是不平衡的,数据集标签统计如图3所示。Focal Loss函数适用于不平衡数据集,因此本文采用Focal Loss作为模型的损失函数。与其他损失函数相比,Focal Loss损失函数修正了正负样本、难分和易分样本对损失的贡献量。
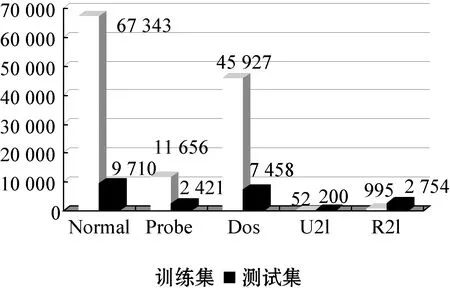
图3 数据集标签统计
3)Adam优化算法。Adam算法[17]可以替代传统随机梯度下降过程的优化算法,能基于训练数据迭代地更新网络模型的权重。Adam算法具有减少深度学习的时间以及占用计算机的资源等优势,因此被广泛应用于深度学习领域。CNN-Focal模型采用Adam算法提高模型的性能。
3 实 验
3.1 实验目的
针对本文数据集不平衡问题,本文将Focal Loss损失函数应用到模型中。为了验证Focal Loss的有效性,本文将Focal Loss和深度学习中常用的交叉熵损失函数进行实验对比,即将CNN-Focal模型的损失函数换成交叉熵损失函数,更改损失函数后的模型记为CNN-Cross。除此之外,为了验证CNN-Focal模型具有更好的分类效果,本文将CNN-Focal与SVM、RandomForest、DecisionTree、GaussianNB四种方法进行了对比实验。
3.2 实验方法
在入侵检测领域,NSL-KDD数据集被广泛应用,本文将经过数据预处理的NSL-KDD数据集用于CNN-Focal以及对比模型的训练和测试。另外本文选取了精度、准确率、召回率、F1评分等指标对模型进行评估。
1)数据集介绍。在入侵检测的研究中,KDD CUP 99数据集是使用最为广泛的数据集。KDD CUP 99数据集中训练集有约500万条记录,测试集有约30万条记录,该数据集的数据量对实验硬件环境要求较高。另外,各种统计分析显示KDD CUP 99数据集中存在大量冗余的记录[18],这将使模型出现过拟合现象,且在训练过程中需要更多的计算机资源,模型收敛缓慢。
NSL-KDD数据集解决了KDD CUP 99数据集中存在的问题,目前有许多研究成果都是基于NSL-KDD数据集的。NSL-KDD数据集中包含41列特征和1列标签。标签列分为5大类:Normal,Probe,Dos,U2L和R2L。
NSL-KDD数据集中训练集共有125 973条(约18.2 MB),测试集共有22 543条(约3.2 MB)。这个数据集的数量级对实验硬件环境的要求不高,可以在普通机器上进行实验。另外,训练集和测试集中包含的攻击方法不同,所以使用该数据集训练出的模型对于新型的攻击具有较好的检测效果。
2)数据预处理。机器学习中一般使用标称型和数值型两种数据类型,NSL-KDD数据集中41列特征属性值既有标称型又有数值型。该数据集中protcol_type、service、flag和label 4列属性值类型为标称型,剩余各列为数值型。
数据的标准化(Normalization)是把数据按比例缩放到一个特定区间,使之从一个大区间落入一个小区间。标准化后的数据具有缩短模型的收敛时间、提高模型精度等优势。本文对数值型特征进行标准化操作,使之缩放到[0,1]之间。具体如下:
(1)
式中:x、xmin、xmax分别表示原始样本数据值、样本数据的最大值、样本数据的最小值。
one-hot编码,又称独热编码,它不仅能处理非连续型数值的特征,也会让特征之间的距离更加合理。本文中使用sklearn包中的OneHotEncoder对protcol_type、service、flag和label 4列标称型数据进行one-hot编码。
3)评价指标。对模型进行评估,不仅需要有效可行的实验方案,还需要有衡量模型泛化能力的评价指标,这就是性能度量。在不平衡分类任务中,最常用的性能度量有精度(Accuracy)、准确率(Precision)、召回率(Recall)以及F1评分四种。本文以这四种指标来评估模型。
3.3 环境构建
本文实验环境采用了Ubuntu 16.04 64位操作系统、Intel Core i7处理器、64 GB内存。实验平台采用了TensorFlow 1.9.0、Sklearn 0.20.1等框架,在程序实现中使用了Python 3.5.2进行编程。
3.4 结果分析
本文所有实验均使用NSL-KDD数据集。CNN-Cross和CNN-Focal两组对比实验的结果如表1-表3所示。SVM、RandomForest、DecisionTree、GaussianNB四组实验与CNN-Focal的实验结果的对比结果如表4-表6所示。
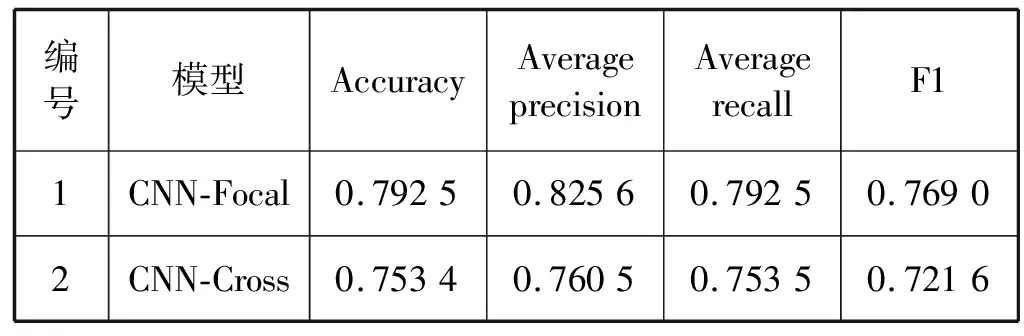
表1 两种损失函数总体指标对比
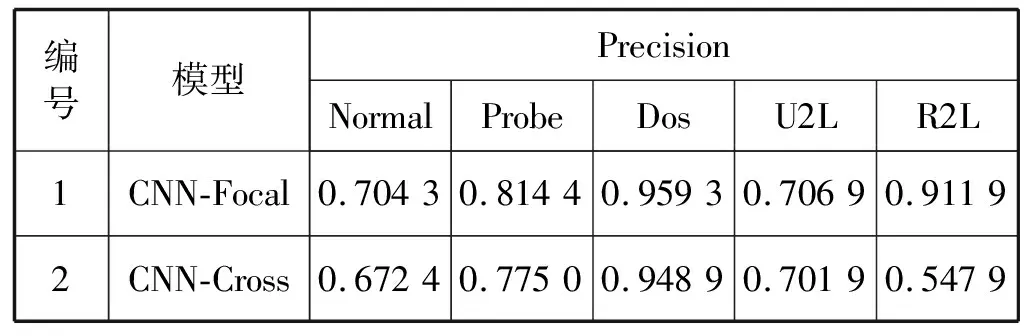
表2 两种损失函数准确率对比
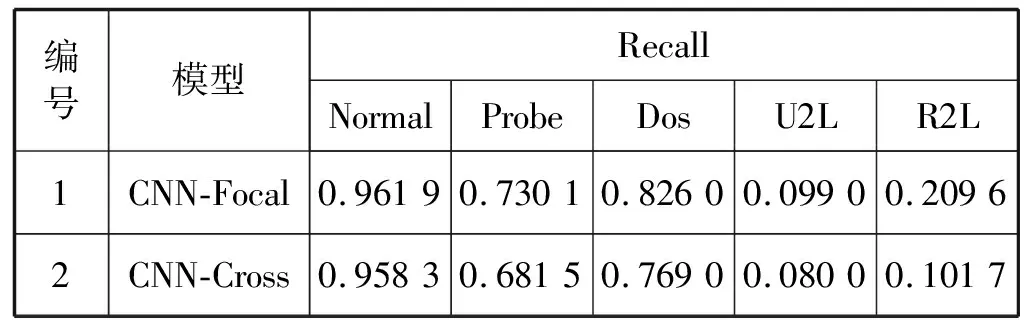
表3 两种损失函数召回率对比
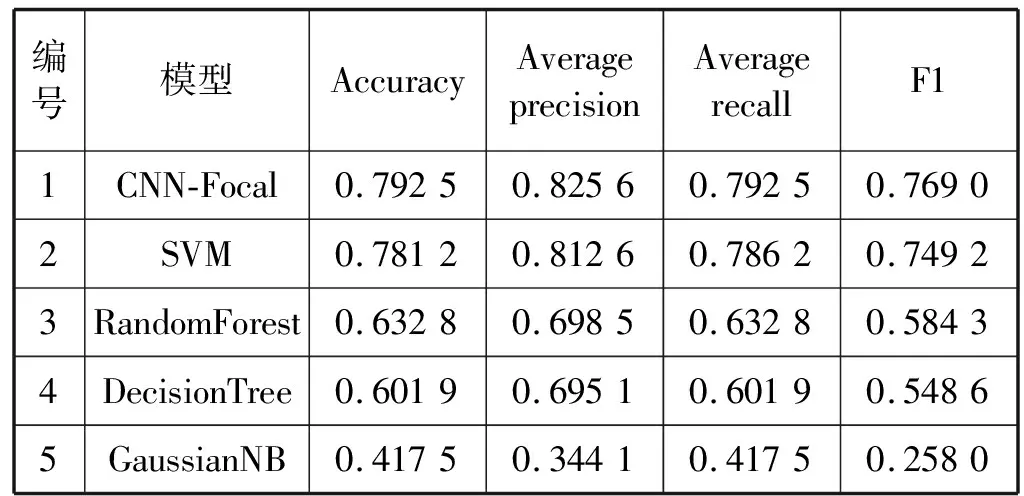
表4 总体指标对比
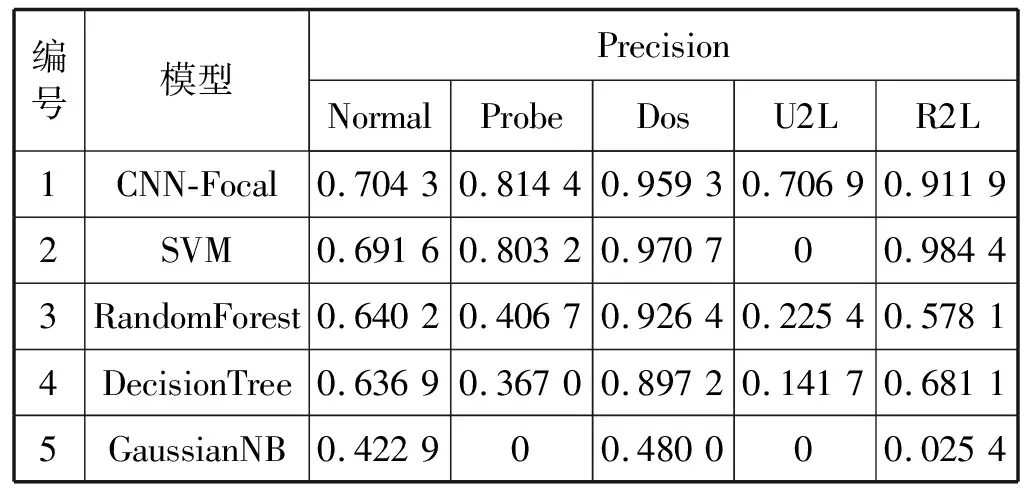
表5 准确率对比

表6 召回率对比
表1为CNN-Focal和CNN-Cross在精度、平均准确率、平均召回率和F1评分上的对比结果。可以看出,CNN-Focal取得了79.25%的精度、82.56%的平均准确率、79.25%的平均召回率和76.90%的F1评分,均高于CNN-Cross。
由表2可知,CNN-Focal在Normal、Probe、U2L、R2L等五种类型上分别取得了70.43%、81.44%、95.93%、70.69%和91.19%的准确率,均高于CNN-Cross。
由表3可知,CNN-Focal在Normal、Probe、U2L、R2L等五种类型上分别取得了96.19%、73.01%、82.60%、9.90%和20.96%的召回率,均高于CNN-Cross。
综合对比表1-表3实验结果,Focal Loss 损失函数在本文数据集上的分类效果优于交叉熵损失函数。
表4列出了CNN-Focal模型和其他四种模型在精度、平均准确率、召回率和F1评分上的结果对比。可以看出,CNN-Focal模型取得了79.25%的精度、82.56%的平均准确率、79.25%的平均召回率、76.90%的F1评分,均高于其他四种模型。
由表5可知CNN-Focal模型在Normal、Probe和U2L三种类型的准确率上均高于其他四种模型。CNN-Focal模型在Dos、R2L两种分类上准确率略低于SVM模型,而高于其他三种方法。但是SVM在U2L类别上的准确率为0,即SVM没有检测出U2L类型的攻击,而文中设计的CNN-Focal模型达到了0.706 94的准确率。总体来说,CNN-Focal模型在准确率上优于其他四种模型。
由表6可知,CNN-Focal模型在召回率上均高于其他四种模型,尤其在U2L攻击类型的检测效果上比其他四种更有效。
综合表4-表6实验结果,本文提出的CNN-Focal模型具有更好的分类效果,与其他方法相比,本文模型在取得较高的准确率的同时,也提高了不同攻击类型的检测准确率。
4 结 语
针对传统入侵检测系统在网络流量较大及复杂入侵环境下检测能力弱且精度低的问题,本文提出了CNN-Focal模型。实验结果表明,与SVM、RandomForest、DecisionTree和GaussianNB等方法相比,本文模型具有较高分类精度和F1评分。在未来工作中,将进一步优化模型结构,减少训练时间,提高分类效果,同时还将探索二维卷积模型在入侵检测中的应用。
