云计算中一种高效的工作流调度方法
2020-10-15胡红宇
胡红宇 陈 政
1(永州职业技术学院计算机系 湖南 永州 425000) 2(湖南工学院计算机与信息科学学院 湖南 衡阳 421001)
0 引 言
许多科学领域,如生物信息学、物理、天文学等,均有着复杂的任务执行需求[1],通常可建模为工作流模式。这种工作流模式可表达为有向无循环图DAG,图中每个节点代表一个任务,任务间的有向边代表两个节点间的数据传输关系。科学工作流规模大,结构复杂,在处理时需要更强大的计算能力和存储空间。云计算因为可以通过虚拟机技术提供无限制强大资源使其成为执行大规模科学工作流的有效平台[2-3]。云计算中的工作流调度问题即将每个任务节点映射至虚拟机,实现任务执行,该问题本质上是一个NP完全问题。
已有很多类型的算法对任务调度问题进行了研究,包括启发式算法、搜索算法、元启发式算法。而任务调度管理中的任务通常分为独立任务,即包任务(Bag of Tasks,BoT)和依赖任务(工作流)[4-6]。任务至资源间调度可划分为两个阶段:调度阶段和提供阶段。传统的GAIN算法[7]可归类为纯任务调度阶段的算法,而DRIVE算法[8]更侧重于资源提供阶段。云调度系统则同时包含了调度与提供两个阶段。
工作流调度算法通常有两个主要的分类:尽力服务调度算法与服务质量约束调度算法[9]。前者通常会忽略一些重要的参考因素,如代价因素,再以最小化执行跨度Makespan为目标进行任务调度。类似于启发式算法,最小最小算法(MIN-MIN)、最大最小算法(MAX-MIN)及Suffrage[10]算法等均是以最小化makespan作为工作流调度目标的。MIN-MIN首先计算所有任务在所有资源上的最小完成时间,形成矩阵,然后在矩阵中选择完成时间最小的任务优先进行在相应资源上进行调度执行。MAX-MIN类似于MIN-MIN,区别在于优先选择的是完成时间最大的任务进行调度执行。此外,文献[11]提出一种异构最快完成时间调度算法HEFT,通过赋予任务不同优先级,最小化任务调度时间。
为了解决云工作流调度问题,本文提出一种有效的调度算法:首先,将工作流中每个层次的任务划分为包任务BoT从第一个包任务进行迭代调度,BoT中所有任务的估计计算时间值利用最小最大标准化方式进行标准化操作;然后,利用动态阈值将BoT中的所有任务划分为两类批任务B_large和B_small;最后,基于最小完成时间,将批任务中的每个任务调度至相应虚拟机上执行,在执行跨度最小化的同时,还可以确保较高的云资源利用率。
1 云计算中的工作流调度问题
1.1 工作流模型
工作流模型最佳的表达结构是图论中的有向无环图模型。该模型可以明确工作流结构中所有任务间的偏序关系,即前驱与后继关系,以此约束任务间的执行次序,且工作流结构中的入口任务与出口任务在有向无环图中也可明确表示。基于有向无环图,算法设计中对于任务的调度选择也更加有利。一个工作流可表示为一个有向无循环图DAG结构Dg=(T,E),T={T1,T2,…,Tn}表示n个任务节点集合,E表示DAG中的有向边集合。从Tp至Ts间的有向边表示任务Ts无法开始执行,直到Tp完成为止,表示为Tp→Ts。此时,Tp是前驱节点,Ts是后继节点。
在工作流结构中,若节点没有任一前驱节点,则称为入口任务;若节点没有任一后继节点,则称为出口任务。若一个工作流拥有多个入口任务,可以对其添加一个伪入口任务,以权重为0(传输时间)的虚拟边连接至所有入口任务节点上。同时,此伪入口任务的计算时间也为0。类似地,多出口任务时也可作同样的处理。节点间的数据传输时间DT可通过矩阵表示为:
(1)
式中:元素DTi,j表示任务Ti至任务Tj间的数据传输时间,1≤i≤n,1≤j≤n。
1.2 云资源模型
一个云服务提供者CSP可提供具有不同能力的虚拟机VM实例集合用于执行工作流任务。令CS={CS1,CS2,…,CSM}表示可用云服务器集合,部署VM数量为m。需要注意的是,活跃的VM数量在每个云服务器间是变化的,进而导致每个云服务器的部署能力也是变化的。同时,假设若两个VM部署于同一个云服务器上,两者间的数据传输时间可忽略不计。对于该异构虚拟机构成的云资源模型,每一种可用的虚拟机类型均可以作为任务调度的所选目标,并基于虚拟机的处理能力和资源占用状态进行任务调度目标的优化与映射求解。
1.3 估计计算时间
工作流中的一个任务节点在不同的VM上的执行时间是不同的,所有任务在不同VM上的估计计算时间ECT可表示为一个矩阵:
(2)
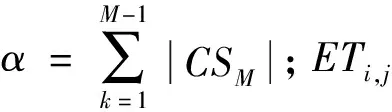
1.4 工作流的执行跨度
工作流执行跨度MS,即工作流中所有任务的整体执行时间,根据有向无环图所表示的工作流结构特征,即执行入口任务开始到出口任务完成的时间段。令MS(CSk)表示所有执行于云服务器CSk上虚拟机的任务的Makespan,1≤k≤M,MS(VMj)表示执行于虚拟机VMj上任务的Makespan,1≤j≤|CSk|(假设VMj部署于云服务器CSk),则云服务器CSk(1≤k≤M)的个体Makespan可计算为:
MS(CSk)=max(MS(VMj)) 1≤j≤|CSk|
(3)
因此,对于给定工作流执行的所有云服务器的整体Makesapn可计算为:
MS=max(MS(CSk)) 1≤k≤M
(4)
工作流的执行跨度需要基于工作流本身的结构特征、云资源的异构处理能力以及各任务在资源上的估计计算时间的综合考虑进行计算。在设计工作流调度算法过程中,也需要根据以上因素,设置优化目标,求解任务与虚拟机间的最佳映射关系,从而得到工作流的调度解。
1.5 平均云资源利用率
任一VM在其部署的云服务器上的时间占用率即为VM利用率,该利用率可表示为VM的Makespan与部署的云服务器CSk的整体Makespan间的比例,公式如下:
(5)
式中:U(VMj)为VMj的利用率。因此,云服务器的利用率可定义为同一云服务器上所部署的所有VM的平均利用率,即:
(6)
式中:U(CSk)表示云服务器CSk的利用率。类似地,所有云服务器的平均利用率为:
(7)
云计算中的工作流调度最优化问题,即将工作流的每个任务调度至部署于M个云服务器上的m个虚拟机上,同时实现执行跨度Makespan的最小化和平均云服务利用率的最大化。
1.6 相关参数描述
为了便于算法描述,定义工作流调度的相关参数与说明如表1所示。

表1 参数说明
1)估计计算时间ETi,j:表示的是任务Ti在VMj上的估计计算时间,由式(2)定义。
2)最早开始时间ESTi,j:表示任务Ti在VMj上执行的最早开始时间,可表示为:
(8)
式中:pi表示任务Ti的前驱节点;pred(i)表示前驱任务集合;ACTpi表示任务Tpi的实际完成时间;DTpi,j表示任务Tj与前驱任务Tpi间的数据传输时间。
对于所有的入口任务,ESTi,j=0,即ESTentry,j=0。同时,若任务Ti与其前驱任务Tpi调度至同一虚拟机或云服务器上,则其数据传输时间为0。
3)最早完成时间EFTi,j:任务Ti在VMj上的最早完成时间为最早开始时间与估计计算时间之和,即:
EFTi,j=ESTi,j+ETi,j
(9)
4)实际完成时间ACTi,j:表示任务Ti在VMj上的绝对完成时间。
5)标准化估算完成时间N_ECTi,j:
(10)
初始状态下,在工作流层次1中,标准化ECTi,j通过式(10)计算。然后,N_ECTi,j会随着N_Temp_ECTi,j进行更新,由于任一单个任务Ti被调度至任一可用VMj,则先前的ECTi,j需要更新为Temp_ECTi,j。
6)动态标准化阈值Thrsh(dTi):任务Ti的Thrsh(dTi)表示任务Ti在m个VM上的最大计算时间与该任务与其所有前驱任务{Tp}的最大数据传输时间DTpi,i的比率。若任务不存在任一前驱任务,则数据传输时间为0。Thrsh(dTi)定义为:
1≤i≤n,1≤j≤m,1≤pi≤|Tp|
(11)
Thrsh(dTi)与Temp_ECTi,j是相互独立的,仅在工作流Dg的每个层次中基于初始的ECTi,j进行计算。
7)平均通信/计算比率CCR:表示DAG中的平均数据传输时间(通信代价)与平均计算代价间的比率,为工作流调度问题的固有属性。基于CCR值,DAG可被划分为计算密集型或数据密集型工作流。
2 算法设计
2.1 算法原理
本文设计的工作流调度算法(简称NMMWS)的主要思想如下:首先,将工作流中每个层次的任务划分为包任务BoT,从第一个包任务进行迭代调度,BoT中所有任务的ECT值利用最小最大标准化方式进行标准化操作。然后,利用动态阈值将BoT中的所有任务划分为两类批任务B_large和B_small。最后,基于最小完成时间,将批任务中的每个任务调度至相应虚拟机上执行。这种动态的阈值计算机制可以对任务进行有效的批集合划分,使得不同的批任务可以基于最小完成时间标准选择最佳的目标虚拟机进行调度,进而实现任务执行时间和资源利用率的同步优化。
算法在工作流Dg的每个层次li上分两个阶段进行。第一个阶段中,算法对每个层次上的每个任务Ti的ECTi,j进行标准化操作,然后利用式(11)计算每个任务的阈值。对{N_ECTi,j}中的最大标准化值和阈值Thrsh(dTi)进行比较,以便将每个层次中的任务划分为大批任务B_large和小批任务B_small。以上的计算过程从工作流的入口任务至出口任务自顶向下的方式进行计算。第二个阶段中,算法通过从ECTi,j中选择最小的执行时间将任务调度至相应虚拟机上。任务分配后,将ECTi,j更新为Temp_ECTi,j。该过程迭代执行至所有任务完成调度,同时要计算任务的EST和EFT。算法过程如算法1至算法4所示。
算法1NMMWS算法
输入:包括n个任务节点的工作流Dg(T,E)。
输出:Dg(T,E)在部署于M个云服务器上的m个VM上的映射。
1. 读取估计计算时间矩阵ECT和数据传输时间矩阵DT
2. while任务池中有未调度的任务
3. for each levelliofDg
//在工作流Dg的每个层次上迭代
4. call Generate-Ready-Tasks-List(n,ECTi,j)
//调用算法2生成就绪任务列表
5. call Comp_EFT(ECTi,j,ofQRli,DTi,j)
//调用算法3计算任务的估算完成时间
6. call Norm_Partition(ECTi,j,N_ECTi,j,Thrsh(dTi))
//调用算法4分割任务,生成任务的B_large和B_small集合
7. if B_large is not empty then
8. find min(EFTi,j)
//寻找EFT中的最小值
9.taskVMmap(Ti)=VMj
//按EFT最小值作出相应调度
10.ACTi,j=EFTi,j
//更新任务实际完成时间
11.ESTi,j=1
//设置最早开始时间
12. removeTifrom B_large
//从B_large移除任务
13. else
//在B_small集中搜索
14. find min(EFTi,j)
//寻找EFT中的最小值
15.taskVMmap(Ti)=VMj
//按EFT最小值作出相应调度
16.ACTi,j=EFTi,j
//更新任务实际完成时间
17.ESTi,j=1
//设置最早开始时间
18. end if
19. end for
20.end while
算法2Generate-Ready-Tasks-List(n,ECTi,j)
1. while there is unscheduled task in workflowDgdo
2. B_large of tasks is empty
//B_large为空
3. for each taskTido
//在每个任务上迭代
4. ifECTi,jthen
//若存在估计计算时间值
5. addTitoQRli
//将任务添加至就绪队列
6. end if
7. end for
8. end while
算法3COMP_EFT(ECTi,jofQRli,DTi,j)
1. for each taskTiin ready task listQRlido
2. ifTihas no parent taskTpthen
//若任务不存在前驱任务
3.ECTi,j=Availj+ETi,j
//计算任务估计计算时间
4. else
5. for eachVMjandTpin parent task ofTido
6. iftaskVMmap(Tp)is not equalVMjthen
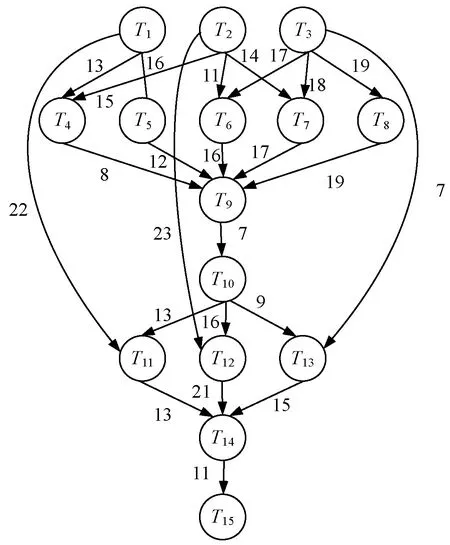
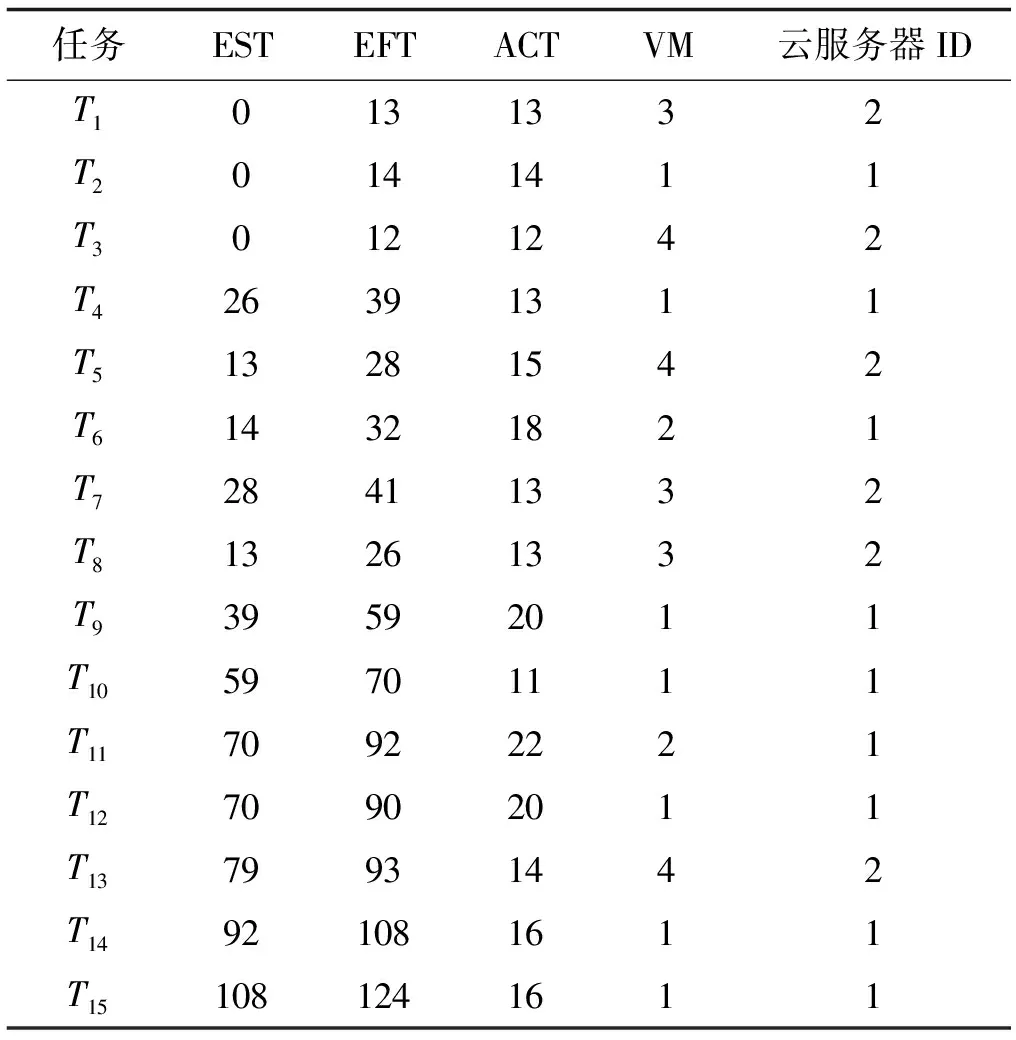
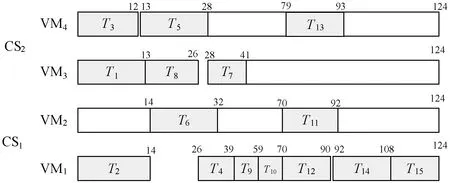
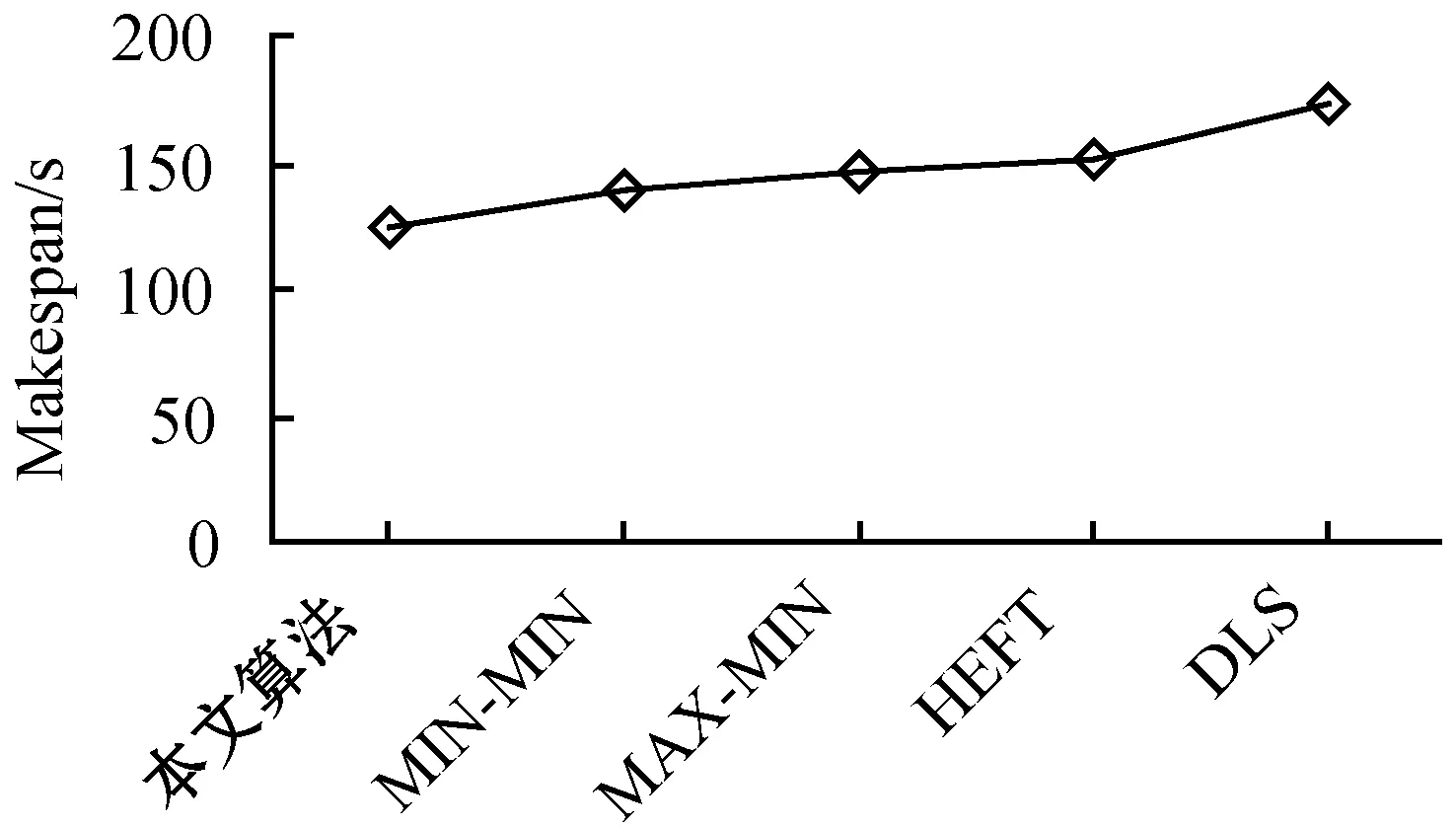
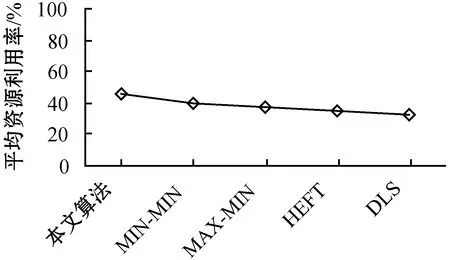
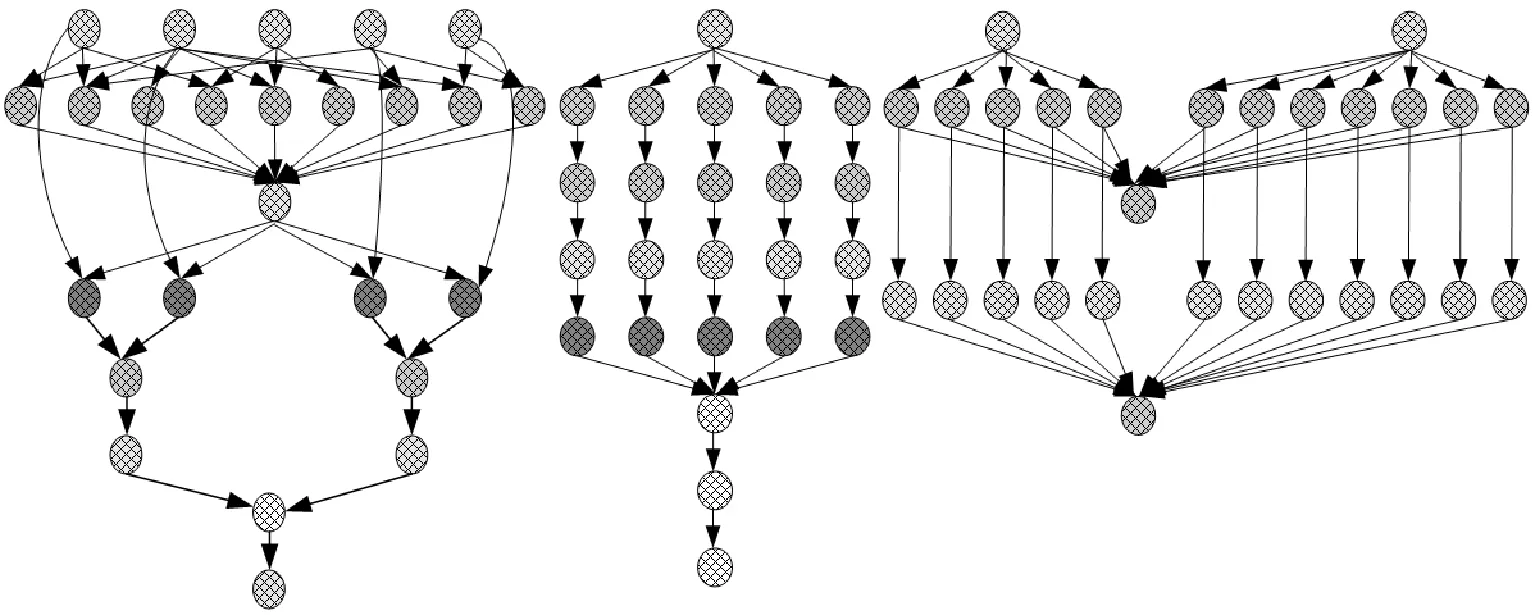
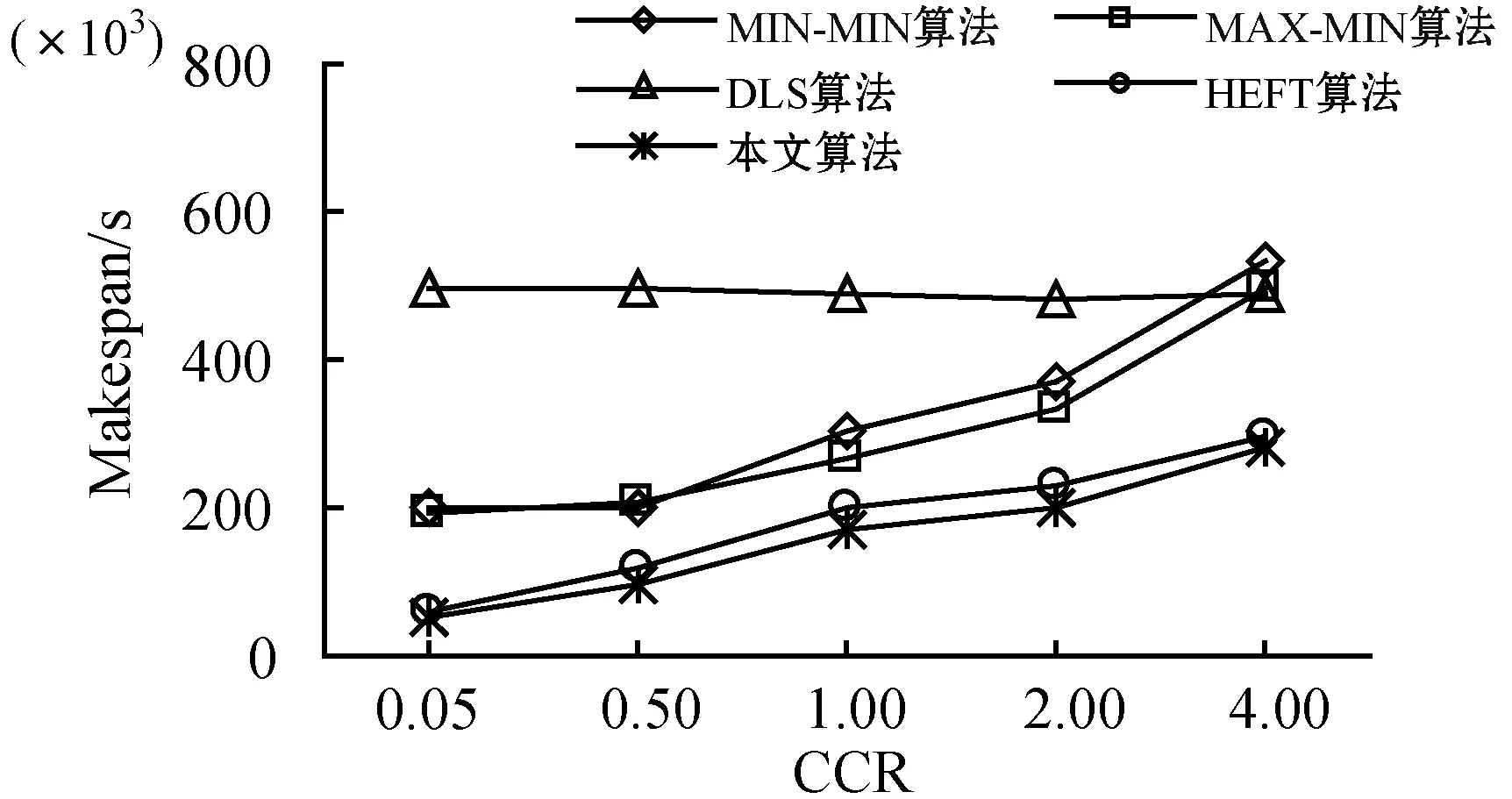
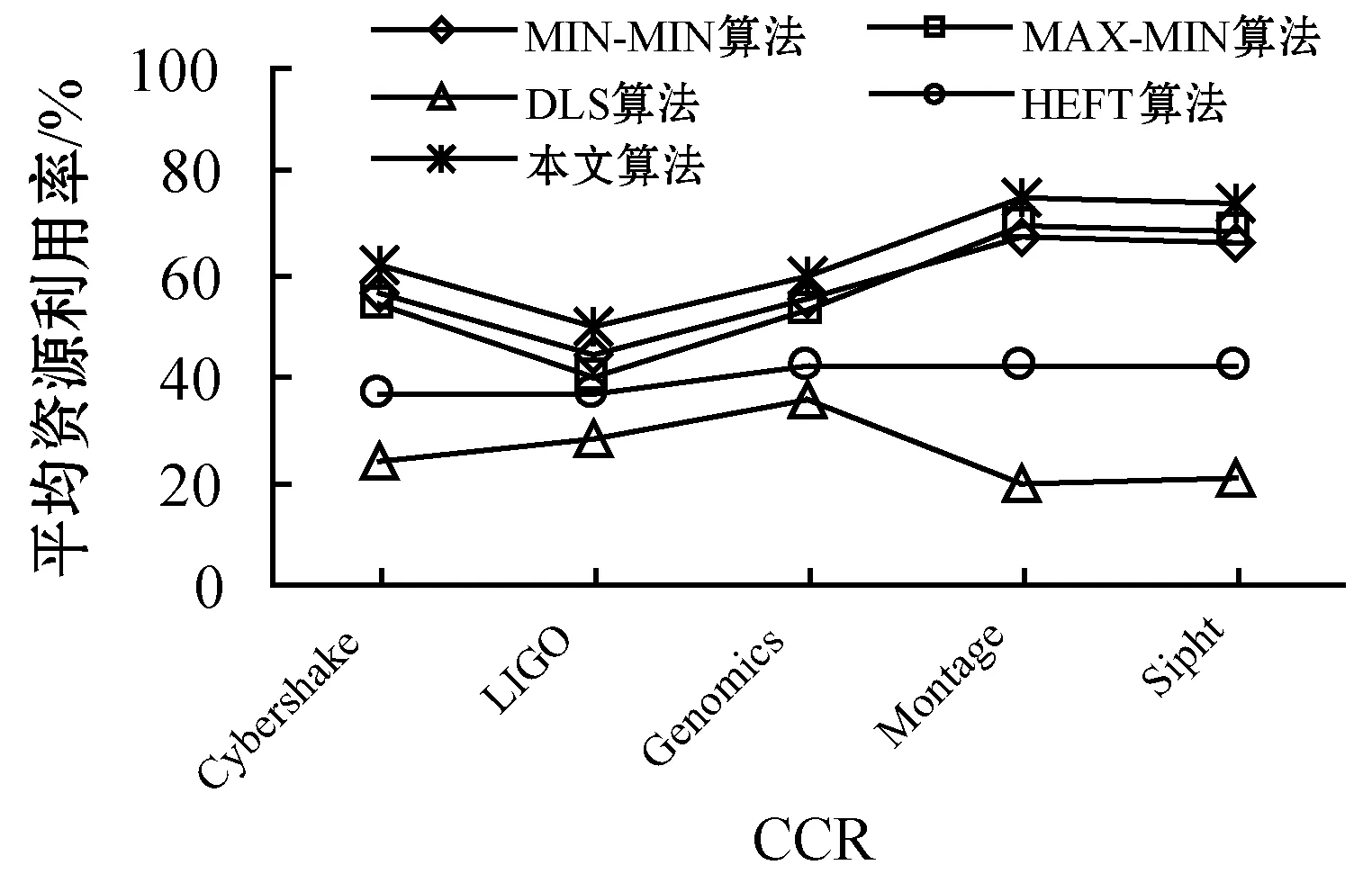
7. ifECTi,j 8.ECTi,j=max{Availj,max{ACTpi+DTpi,i}} //更新任务的估计计算时间 9. end if 10. else 11. ifECTi,j //估计计算时间小于虚拟机可用时间与前驱任务的 //实际完成时间较大值 12.ECTi,j=max(Avail,ACTpi) //更新估计计算时间 13. end if 14. end if 15. end for 16. end if 17.end for 算法4Norm_Partition(ECTi,j,N_ECTi,j,Thrsh(dTi)) 1. for each taskTiin ready task listQRliandVMjdo 2. find min(ECTi,j) //寻找ECT中的最小值 3. find max(ECTi,j) //寻找ECT中的最大值 4. find the normalizedECTi,jasN_ECTi,j 5. find theThrsh(dTi) //寻找阈值 6. if max(N_ECTi,j)≥Thrsh(dTi)then //判定阈值与标准值的关系 7. add taskTito batch B_large //若任务的标准ECT值大于等于阈值,则被添加至B_large 8. else 9. taskTigo to batch B_small //否则添加至B_small 10. end if 11.end for 1)NMMWS算法(算法1)的时间复杂度为O(n3ml)。 证明:令n为DAG中e条连接边时的任务总量,l为工作流DAG的层次,M个云服务器上部署的虚拟机数量为m。步骤2和步骤3时间复杂度分别为O(n+e)和O(l)。步骤4在最差情况下需要执行O(n2)次,以生成n个任务的就绪任务队列。步骤5需要执行O(nm),以计算DAG中每个层次li中的每个任务的估计计算时间。步骤6执行O(n+e)次,步骤3至步骤19迭代n2m次,步骤2至步骤20的while循环迭代执行n次。因此,算法的总体时间复杂度为O(n3ml)。 2)Generate-Ready-Tasks-List(n,ECTi,j)算法(算法2)的时间复杂度为O(n2)。 证明:现有n个任务节点被调度至m个虚拟机上,算法步骤1至步骤8的while循环最差情况下会执行n次,步骤3至步骤7的内层循环会迭代n次,因此算法的时间复杂度为O(n2)。 3)COMP_EFT(ECTi,j,DTi,j)算法(算法3)的时间复杂度为O(nm)。 证明:对于个n个DAG的分隔任务,步骤1至步骤17的for循环会迭代n次,步骤5至步骤15的内层循环会迭代m次,m为部署于M个云服务器上的可用虚拟机数量,因此算法时间复杂度为O(nm)。 4)Norm_Partition(ECTi,j,N_ECTi,j,Thrsh(dTi))算法(算法4)的时间复杂度为O(n2m)。 证明:令n为DAG中总的任务数量,m为部署在M个云服务器上的所有活跃虚拟机数量。算法步骤1至步骤11的for循环会迭代nm次,步骤2至步骤13执行nm次,步骤4和步骤5均执行n次。因此,算法的时间复杂度为O(n2m)。 通过图1的Montage科学工作流示例说明算法的详细执行思路。Montage工作流多应用于天文学领域,基于输入图像产生天气的定制输出模式,对CPU处理能力要求较低,完全串行任务较少。该示例中的工作流包括15个任务T={T1,T2,…,T15},7个层次,24条有向边,由并行任务和管道任务混合组成。图中有向边上的权值即为任务间的数据传输时间,即矩阵DT。表2为每个任务在部署于2个云服务器上的4台虚拟机上的估计计算时间。 图1 Montage工作流 表2 估计计算时间 图1中工作流的层次1的就绪队列QRl1拥有三个任务节点T1、T2和T3,这三个任务均有可能调度至可用的4个VM上。因此,对于层次1,T1、T2和T3的Temp_ECT为: 根据式(10),标准化Temp_ECT计算为: 任务T1、T2和T3不存在前驱任务,因此不存在来自于前驱的数据传输。若DTpi,i=0,则式(11)中的阈值Thrsh(dTi)也为0。因此,此时将阈值可固定设置为0.99。现在比较Thrsh(dTi)与N_Temp_ECT的最大元素间的关系。N_Temp_ECT矩阵中,在层次1中任务T1的最大元素N_Temp_ECTi,j=1.0,而Thrsh(dTi)固定为0.99,故Thrsh(dTi) 对应的标准化Temp_ECT为: 在更新的N_Temp_ECT矩阵中,任务T3的最大N_Temp_ECTi,j也为1,与固定Thrsh(dTi)为0.99比较,Thrsh(dTi) 对应的标准化Temp_ECT为: 此时,Thrsh(dTi) 在DAG的层次2中,拥有5个任务T4、T5、T6、T7和T8在就绪队列QRli中。由于层次1中的任务T1、T2和T3已经调度至VM3、VM1和VM4上,因此,VM1、VM2、VM3和VM4的可用时间Availj分别为14、0、13和12。而T4为T1和T2的前驱任务,带有数据传输时间DTi,j为13和15。根据算法4中步骤5至步骤11,任务T4、T5、T6、T7和T8在4个虚拟机VM1、VM2、VM3和VM4上的Temp_ECT可更新为: 然后,标准化Temp_ECT被依次计算,并根据Thrsh(dTi),任务被置入B_small或B_large中。最终得到的调度结果如表3所示。 表3 工作流各任务的调度结果 Montage工作流DAG调度的甘特图如图2所示,其中还包括了算法MIN-MIN、MAX-MIN和HEFT得到的结果。可以看出,本文算法在工作流执行跨度和平均云资源利用率方面均优于另外3种算法。各算法的工作流执行Makespan和平均资源利用率分别如图3和图4所示。MIN-MIN算法的主要调度思想是以最快的时间进行任务分配与处理,以时间为单一权重设计的任务调度算法,将任务分配至处理时间最小的资源上,保证任务完成的时间最短。这种算法虽然保证了处理时间最短,但会导致处理能力强的资源一直处于工作状态,而处理能力相对一般的资源则资源率不足。MAX-MIN算法与MIN-MIN算法非常类似,同样是计算每一个任务在任一可用资源上的最早完成时间,不同的是MAX-MIN算法优先调度大任务,任务到资源间的映射是选择最早完成时间最大的任务映射到所对应的资源上。HEFT算法是一种基于异构最快完成时间的工作流调度算法。首先通过升秩值或降秩值的计算赋予任务不同的优先级,按照优先级递减的次序形成任务的调度队列,然后以最小任务调度时间为标准依次将任务调度至资源上,是一种最为经典的单一优化目标工作流调度算法。由此可见,已有的方法更加注重的是调度效率的优化,更加适用于传统的计算环境。而本文算法在优化调度效率与提高资源利用率、均衡不同处理能力的虚拟机资源上均可体现出较好的优势,更加适用于云计算中的工作流调度环境。 (a)本文算法 图3 工作流的执行Makespan 图4 算法平均资源利用率 为了评估算法性能,设计仿真实验对算法进行测试。利用CloudSim作为仿真工具[12],现有CloudSim工具包仅允许调度独立任务,不适用于多个相互关联的依赖任务组成的工作流调度问题。因此,本文对CloudSim的内核架构进行扩展。使用5种不同科学领域中的合成工作流结构作为数据源,包括:天文学中的Montage工作流、生物学中的Genomics工作流、地震学中的CyberShake工作流、引力物理学中的LIGO工作流和生物信息学中的SIPHT工作流。图5给出5种科学工作流的结构模型。5种工作流结构在其结构特征和任务并行程度等方面均体现出不同特征,在此环境下的测试有利于观察算法在不同结构组成的工作流中性能的适应性和稳定性。在不违背不同工作流的核心结构的前提下,设置工作流中的任务的通信/计算率分别为{0.05,0.5,1,2,4}进行测试,任务规模为1 000,云服务器数量为4,部署的虚拟机数量为30。 (a)Montage (b)Genomics (c)CyberShake 图6为在不同类型的工作流不同CCR取值环境下得到的算法的执行Makespan结果。可以看出,本文算法提供了最小的执行跨度,执行效率更高。即使改变工作流任务中的通信密集型和计算密集型任务的配比,依然不会对结果产生反转式的影响,仅仅会在不同算法间增加或降低执行跨度,但对其他算法同样会产生影响,验证了本文算法的适应性和鲁棒性。图7为各算法的平均资源利用率结果,可以看出,本文算法也体现出了优势。主要原因在于,本文算法不仅根据任务在工作流结构的位置以及对资源执行的需求进行了分类,而且可以更加精确地选择最优的虚拟机执行任务;不仅可以提高执行效率,还可以保证云服务器资源得到更大化的利用。本文算法均得到最高的平均资源利用率,说明本文算法面临不同的任务类型和任务组成结构时也具有很好的适应性。 (a)CyberShake工作流 图7 平均资源利用率 为了解决云计算科学工作流调度优化问题,本文提出基于执行跨度和资源利用率为优化目标的工作流调度算法。算法在工作流结构的层次基础上,将任务节点与云服务器的虚拟机间的映射关系求解划分为两个阶段。第一阶段算法对每个层次上的每个任务的估计计算时间以最小最大标准化方式进行操作,并计算任务阈值,将得到的最大标准化值和阈值进行比较,以便将每个层次中的任务划分为大批任务和小批任务;第二个阶段算法通过从估计计算时间矩阵中选择最小执行时间将任务调度至相应虚拟机上,并更新相应执行时间矩阵。实验结果表明,算法不仅可以最小化执行跨度,还可确保更高的云资源利用率。2.2 时间复杂度分析
3 算例说明

4 仿真实验
4.1 环境搭建
4.2 仿真结果
5 结 语
