基于混合聚类分析的区域短期用电量预测方法研究
2020-10-13宋倩芸
宋倩芸


摘 要: 提出了一种基于功能聚类、极限学习机和混合模型的区域短期用电量预测方法。该方法使用功能聚类算法对用电量曲线进行分组,随后针对聚类分组使用极限学习机模型进行用电量预测,最后使用线性回归方法对独立的分组模型极限进行混合实现对区域客户的短期整体用电量预测。此外该方法还使用温度分区策略提高聚类分组的合理性。实验表明该方法能够提高最终用电量预测的准确性。
关键词: 用电量预测; 功能聚类; 极限学习机; 混合模型
中图分类号: TP391,TM714 文献标志码: A
Abstract: This paper proposes a regional short-term electricity consumption prediction method based on functional clustering, extreme learning machines and hybrid models. This method uses a functional clustering algorithm to group power consumption curves, then uses a limit learning machine model to predict power consumption for clustering grouping, and finally uses a linear regression method to mix independent grouping model limits to achieve short-term regional customer overall electricity consumption forecast. In addition, the method uses the temperature partitioning strategy to improve the rationality of clustering and grouping. Experiments show that this method can improve the accuracy of the final electricity consumption prediction.
Key words: electricity consumption prediction; functional clustering; extreme learning machine; hybrid model
0 引言
随着电力市场的开放,用电量预测对于降低电力交易成本都具有重要意义[1-2]。但是由于多种随机因素的干扰导致短期用电量预测的难度很大,因此本文提出一种基于功能聚类[3]的混合预测模型。首先,使用功能聚类算法根据用电量曲线的相位和幅度将用电客户划分为不同分组,接下来,根据不同气候对单一区域进行划分,进而细分第一步聚类的分组。随后通过对这些更加细分的分组来研究温度对用电量预测的影响。之后在细分的分组中分别训练复杂程度不同的极限学习机(ELM)[4-5],并生成特定的ELM模型。最后通过集成这些单独预测模型的混合模型实现更为准确的最终的用电量预测。其中功能聚类算法重点是通过功能线性回归模型预测用电量。ELM是一种用于前馈神经网络的学习算法,该算法可以随机选择隐藏层节点的输入权重和偏差,实现在达到最小训练误差的同时大幅减少训练时间[6]。本文首先阐述所提出预测方法,并简要说明了用于实现该方法的功能聚类、ELM模型和模型混合方法。随后通过实验演示了该方法的预测过程,并对实验结果进行了介绍和讨论。
1 预测方法
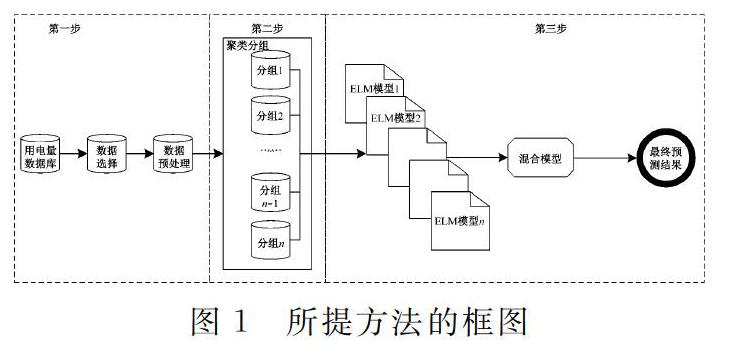
本文所提出的用电量预测方法通过汇总用电量曲线来实现对具有不同经济活动客户的用电量进行预测。用电量曲线的聚合对象必须是对具有相同用电模式的客户才能实现较好的预测准确度。由于本文的目标是实现对区域汇总用电量的预测,因此通过将针对聚类分组客户的单个预测模型进行混合,并使用不同的样本进行训练,实现预测误差的相互补偿,减少汇总的预测方差和偏差,提高混合模型的准确性。所提出预测方法如图1所示。
由图1可知,该预测方法侧重于在一个由三个步骤组成的统一框架内处理区域短期用电量预测。第一步,对所收集的客户日用电量数据进行数据清洗、數据约简、数据归一化等数据预处理操作。第二步,对用电量曲线图进行相位和幅值聚类分析,并对依据天气因素对聚类分组客户进行细化,最后根据区域划分及其环境温度建立了独立的分组预测模型。第三步,通过混合模型来实现对整个区域的更高精度预测。
1.1 功能聚类
大多数聚类算法的对象都是静态数据,即特征值不随时间变化或变化很小的数据[7]。因此,传统的聚类方法,如划分、分层或基于模型的方法,不适用于以曲线形式出现、指定为功能数据或纵向数据的分组数据。当应用于功能数据时,传统的聚类方法因为忽略功能数据的相位变化可能导致信息丢失。为了处理这类数据,一些研究提出了一些函数聚类算法。其中一些算法是对传统聚类算法的改进,以处理时间序列数据;另一些算法对时间序列数据进行转换,使传统的聚类算法可以直接应用与动态数据[8-9]。前一种方法通常直接对原始时间序列数据进行处理,因此称为基于原始数据的方法,主要的修改是将静态数据的距离或相似性度量替换为适合时间序列的度量[10]。后一种方法首先将原始时间序列数据转换为低维特征向量或多个模型参数,然后对提取的特征向量或模型参数应用传统的聚类算法,称为基于特征的方法[11]。
本文提出一种专门用于分析纵向变化数据的K均值算法(Kml算法)[12]。Kml算法提供了几种不同的技术来处理曲线轨迹中的缺失值,运行的距离是专门为纵向数据设计的,比如弗雷切特距离或动态时间扭曲,或任何用户定义的距离。由于K-means是一种局部择优算法,为了避免收敛到局部解,Kml改变了迭代的起始条件,并对集群数量进行优选。与现有算法相比,Kml另外一个优点之是通过图形界面帮助选择最优的聚类分组数量。
在实验1#、2#、3#中,引入温度变量的36个模型的实验3#获得了更好的预测结果,因为占总用电量的69.5%的客户在某种程度上是受到温度条件影响。另一个原因与实验3#使用了较多的单个预测模型,这也有利于模型混合。
最后将对模型的预测结果做简单的可视化处理,即绘制真实值和预测值曲线,以发现预测结果不佳的区域。可视化处理结果如图5所示。
如果仅在汇总统计数据(如R2)上对模型进行度量,就会导致可视化图形的定性信息丢失。为此,计算了2019年(测试数据集)所有周的周平均R2。图5比较了7天的实际用电量曲线和模型的预测曲线。如图所示,使用线性回归混合模型所得出的预测曲线与实际用电量曲线非常相似。
4 总结
本文提出了一种基于功能聚类、极限学习机和混合模型的区域短期用电量预测方法。 实验表明,KmL函数聚类算法表现良好,已根据其形状、相位和幅度正确对用电量曲线进行了聚类分组。对比测试证明了基于线性回归的混合模型优于基于求和的混合模型,可以有效地提高最终预测结果的准确度。
参考文献
[1] 张文涛,马永光,董子健.基于优化核极限学习机的短期电力负荷预测[J].计算机仿真,2019,36(10):125-128.
[2] 李永通,陶顺,赵蕾,等.基于短时间尺度相关性聚类的负荷预测[J].电测与仪表,2019,56(16):32-38.
[3] 史佳琪,张建华.基于多模型融合Stacking集成学习方式的负荷预测方法[J].中国电机工程学报,2019,39(14):4032-4042.
[4] 谢伟,赵琦,郭乃网,等.改进的并行模糊核聚类算法在电力负荷预测的应用[J].电测与仪表,2019,56(11):49-54.
[5] 李杰,靳孟宇,马士豪.基于粒子群算法的极限学习机短期电力负荷预测[J].制造业自动化,2019,41(1):154-157.
[6] 刘南艳,贺敏,赵建文.基于大数据平台的电力负荷预测[J].现代电子技术,2018,41(20):153-156.
[7] 王琳璘,谢忠局,陈永权,等.机器学习聚类组合算法及其应用[J].山东农业大学学报(自然科学版),2018,49(3):463-466.
[8] 王知芳,杨秀,潘爱强,等.基于改进集成聚类和BP神经网络的电压偏差预测[J].电工电能新技术,2018,37(5):73-80.
[9] 朱祥和.考虑气象因素的短期负荷预测模型研究[J].数学的实践与认识,2018,48(3):131-143.
[10] 黄青平,李玉娇,刘松,等.基于模糊聚类与随机森林的短期负荷预测[J].电测与仪表,2017,54(23):41-46.
[11] 刘蓉晖,赵才涛.基于数据挖掘技术的气温敏感负荷短期预测研究[J].电网与清洁能源,2017,33(11):32-38.
[12] 苏舟,李灿,姚李孝,等.电力负荷数据预处理研究及应用[J].电网与清洁能源,2017,33(5):40-43.
[13] 李黎,杨升峰,邱金鹏,等.电力系统供电短期负荷预测方法仿真研究[J].计算機仿真,2017,34(1):104-108.
[14] 雷景生,郝珈玮,朱国康.基于“分层-汇集”模型的短期电力负荷预测[J].电力建设,2017,38(1):68-75.
(收稿日期: 2020.01.03)
