基于条件生成对抗网络的图像转化方法研究
2020-10-12冷佳明曾振刘广源郑新阳刘璎慧
冷佳明 曾振 刘广源 郑新阳 刘璎慧


摘要:近年来,利用设备将手绘图像转换为自然图像的方法是当前的图像处理领域主流方向之一。生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。本文提出一种基于生成对抗网络的图像转换方法,它可以改善原本存在的图像转换方法的差异大、模糊不清等缺点,减小手绘图像与自然图像的视觉差异。实验中生成器由U-net构成,判别器为patch-GAN,对网络模型使用L1进行约束。二者交替训练,通过改变学习率、迭代次数等参数来进行对比训练效果。最后得到的网络模型可以对人脸的手绘图进行轮廓和部分细节的还原。
关键词:手绘图像;条件生成对抗网络;人脸
1 引言
近年来,随着越来越多的智能化设备的开发,人类正一步步迈向智能化生活,也期待着存在更加方便快捷的设备或系统可以满足人们的设想。在日常生活中,手绘是一种常见的交流方式,人类自古以来就以绘画的方式描绘生活中的一点一滴。概括地说,手绘可以快速地对某个场景进行较为完整的描述。在当今社会,通过普遍存在的触屏设备,人们能在智能设备上手绘出一幅简单的图片,而设备给出符合程度相对较高的实物图片,这在互联网信息时代是有价值的。
在手绘图像转化为自然图像的过程中,亟需解决的重要问题是消除二者之间的视觉差异。消除此差异有三个思路:第一种是可以使用一些边缘提取算法将自然图像转换为手绘图像; 第二种是可以使用一些图像渲染算法将手绘图像转换为自然图像; 第三种是将二者映射到相同的特征空间,但应用此思路的方法较少。第一种虽有算法工具的优势,但转化过程前后容易存在较大的图片差异,所以本文采用第二种想法——利用近些年取得重大进展的生成对抗网络(generative adversarial networks, GAN)模型实现手绘图像到自然图像的转化。
相比于其它模型,利用GAN模型实现的转化图像更清晰,模糊部分减少。本文由此模型联想到GAN家族中的条件生成对抗网络(conditional generative adversarial networks, CGAN),就像GAN学习数据的生成模型一样,CGAN也学习了条件生成模型,这使得CGAN更适合于图像到图像的转换任务。该模型更加符合本文所要完成的任务,而且它展示了很好的边缘图至自然图像的转换能力。
2 方法
生成式对抗网络(GAN)框架于2014年被Ian J. Goodfellow等人开创性地提出,此框架同时训练用于捕获数据分布的生成模型和用于估计样本来自训练数据而不是生成器的概率的判别模型,整体系统通过反向传播进行训练,而且训练过程或生成模型期间不需要任何马尔科夫链或展开近似推理网络。与以往的模型不同,本文的生成器使用以U-Net为基础的架构,判别器使用卷积的PatchGAN分类器,它只在图像patch的尺度上对结构进行惩罚,曾有论文提出了一个类似PatchGAN的架构并将其用于捕获本地风格数据。本文证明这种方法可以用在更广泛的问题上。
2.1 CGAN原理
传统GAN在图像应用方面只能保证输入x尽可能地靠近真实图片,并不能使输入符合描述条件c的要求。2014年Mirza等人提出了有条件生成对抗网络(CGAN),此模型中判别器的输入x被修改为同时输入c和x,而输出一方面判断x是否为真实图片,另一方面判断x和c是否匹配;它还演示了如何使用该模型来学习一个多模态模型,并提供了一个应用于图像标记的示例。
在生成器模型G和判别器模型D的比较中,CGAN的学习过程相比于GAN的只有随机噪声向量z到输出图像y的G:z→y的匹配关系,增加了被观察图像x的输入,即是G:{x,z}→y的匹配关系。
CGAN的目标函数为
在此式中,生成器G要最小化该目标函数。相反地,判别器D要最大化该目标函数:
.
在CGAN中加入损失函数会使网络更加有效。例如加入L1范数损失函数后:
VL1 (G)=Ex,y~p(x,y),z~p(z)
[‖y-G(x,z) ┤‖1]
目标函数变为
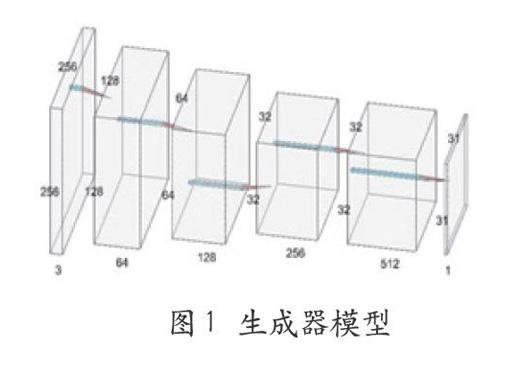
2.2 生成器
两种图像之间的转换问题的特点是将高分辨率输入网格映射到高分辨率输出网格。对于本文研究的问题,在表层外观方面输入和输出是不同的,但都具有相同的底层渲染架构。因此输入中的架构大致与输出中的架构对齐。在本文所涉及到的领域中,很多以前的模型都是用了编码器-解码器网络。在这样的网络中,输入经过一系列层,逐步向下采样,直到达到瓶颈层后进行反转。此网络要求所有的信息流通过瓶颈层在内的所有层。而对于图像翻译问题,输入和输出之间有大量的底层信息共享,所以可以选择直接通过网络传输这些信息。
本文使用一种绕过此类信息瓶颈层的方法——U-Net跳过连接,即在第i层和第n-i层之间跳过连接(n是层次总数),每次跳转连接将第i层所有通道与第n-i层的通道连接起来。
2.3 判别器-PatchGAN原理
很多模型的判别器都是在网络的最后使用一个全连接层将判别的结果以一个结点的形式输出,即将输入映射为一个实数。PatchGAN不然,该模型的判别器完全由全卷积层组成,会将输入映射为N×N的矩阵,矩阵中的每个元素值表示是真实樣本的概率,然后对所有元素取平均值,得到的结果即为最终判别器的输出。在此过程中,形成的矩阵就是由卷积层输出的特征图,以此特征图为起点可以找寻原图像中的某个位置,进而获得此位置对最终输出结果的作用。
在图像风格迁移方面,PatchGAN有着很好的效果。为了使生成图像具有更高的清晰度和更微小的细节,本文也将采用此模型。
本文将采用生成器和判别器如图1、图2所示。
3 实验分析与结果
3.1 实验平台
本文实验平台为Tensor-Flow,实验均在windows 10 64位操作系统,Intel i7处理器,内存8GB上进行,其中所用到的GPU为NVIDIA GeFore GTX 1060。
3.2 实验数据与处理
本文训练所用到的人脸图像数据集是CelebA-HQ,它是由香港中文大学开放提供,广泛用于人脸相关的计算机视觉训练任务的人脸属性数据集CelebA的升级版,总共30k张图片,每一张的分辨率都是1024*1024。由于机器性能有限,我们截取了其中500张作为训练集,100张为测试集。部分人脸图像如图3所示:
接下来利用PIL(Python Image Library)库对人脸图像进行处理:对于输入的图片利用像素间的梯度值以及虚拟深度值进行重构,为了得到形如手绘式的人脸图像,需要调节图片灰度以模拟人类视觉的明暗程度;然后通过构造光源效果加强所得图片效果,即设置光源的方位角度和俯视角度;最后梯度归一化将梯度与光源相互作用,得到新的图片灰度,过程中注意灰度值的取值范围。提取出的手绘图像效果如图4。
3.3模型训练
训练过程中,我们使用Mini batch SGD和Adam优化器在生成器和判别器间交替执行梯度下降,实验中我们对三组参数进行了测试,每隔100step保存可视化结果,同时保存训练日志(loss值),参数如表1:
将人脸原像、处理后的手绘图像和训练中的还原效果图片进行拼接,从而有更好的对效果,如图5。
3.4实验结果
为了评估训练模型对人脸的还原效果,本文使用训练好的模型对训练集中的100张人脸图像进行测试,自动还原效果如图6所示。从损失值(如图7)上来看,对判别器来说,生成器在测试集上的输出有非常好的效果,但是如果使用L1损失进行计算,则生成器的输出效果不是很好。本文认为L1损失太大的原因是背景饰品和肤色的原因。从生成器生成的图像来看,虽然生成的图像在细节方面不是很好,但是生成的图像与原图像大体上是接近的,因此可以认为生成器与判别器均有不错的训练效果。而且由于实验机器受限,本文只选取了500张作为训练集,存在样本不足的问题,如果用整个数据集训练的话效果会好很多。
4 结语
本文提出了一种基于条件生成对抗网络的图像转化方法,构建了能还原人像的条件生成对抗网络模型,通过改进CGAN的损失函数保证了输入和输出图像的相似度,其中生成器采用了U模型,判别器采用patchGAN结构。在训练过程中交替训练生成器和判别器,并使用了minibatch SGD 和Adam优化器,最终得到的网络可以对人脸的手绘图进行轮廓和部分细节的还原。后续我们希望能对如何提高生成的人像图的清晰度做进一步的研究,进一步实现更高精度的还原效果。
参考文献
[1]Isola P, Zhu J Y, Zhou T H, et al. Image-to-image translation with conditionaladversarial networks[C] //Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition.Los Alamitos:IEEEComputer Society Press, 2017: 1125-1134.
[2]Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative Adversarial Nets[C]. International Conference on Neural Infor-mation Processing Systems. MIT Press, 2014.
[3]C. Li and M.Wand. Precomputed real-time texture synthesis with markovian g-enerative adversarial networks. ECCV,2016.
[4]M. Mirza and S. Osindero. Condition-al generative adversarial nets. arXiv pre-print arXiv:1411.1784, 2014.
[5]Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders:feature learning by inpainting[C] //Proceedings of the IEEE conference on Computer Vision and P-attern Recognition. Los Alamitos: IEEE C-omputer Society Press, 2016: 2536-2544.
[6]CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intellige--nce, 1986,PAMI-8(6): 679-698.
[7]MARTIN D R, FOWLKES C C, MALIK J. Learning to detect natural image boun-daries using local brightness, color, andtexture cues[J]. IEEE Transactions on Patt-ern Analysis and Machine Intelligence, 2004, 26(5):530-549.
[8]劉玉杰,窦长红,赵其鲁.基于条件生成对抗网络的手绘图像检索[J].计算机辅助设计与图形学学报,2017,29(17):2336-2341.
作者简介
姓名:冷佳明,性别:男,民族:汉,出生年月:1999年11月,籍贯:吉林省四平市公主岭市,单位:吉林大学计算机科学与技术学院,专业:计算机科学与技术,单位所在省市:吉林省长春市,邮编 130012。曾振,吉林大学计算机科学与技术学院,130012,刘广源,吉林大学计算机科学与技术学院,130012。
