基于深度强化学习的自动驾驶车控制算法研究
2020-10-12王丙琛司怀伟谭国真
王丙琛,司怀伟,谭国真
(大连理工大学 计算机科学与技术学院,辽宁 大连 116000)
0 引言
近年来,随着人工智能和无人驾驶技术的快速发展,无人驾驶车辆已经向实用化迈进,在未来将对提高道路安全、促进交通管理和改善城市环保等产生颠覆性影响,成为汽车交通领域的一项革命[1]。据统计,大约有90%的交通事故是由于驾驶员的失误造成的,主要包括注意力不集中,判断失误和情境意识不足等因素[2]。但是,机器并不会出现劳累和注意力不集中等现象。因此,无人驾驶车的出现,将有可能极大程度上降低这部分交通事故的概率[3]。Google、特斯拉、百度、NVIDIA等著名公司在无人驾驶上均投入了大量的人力和物力,并且已经有部分车辆在道路上进行了实测[4]。美国电气和电子工程师协会(IEEE)预测,至2040年自动驾驶车所占比例将达到75%[5]。无人驾驶的决策和控制模块是决定无人驾驶车安全性、稳定性的关键技术[6]。然而,就当前的情况而言,开发出能够完全自主应对各种复杂多变的路况及充满不确定性的交通场景下的无人驾驶车仍然是一项巨大的挑战。
目前,有基于深度学习和基于强化学习的自动驾驶技术。基于深度学习的方法利用人工记录人类驾驶员的行为训练深度网络,利用训练好的深度网络作为“司机”完成自动驾驶。这种方法需要大量的人工标注信息,这是不现实的。而基于强化学习的自动驾驶算法则具有自己探索环境做出正确决策的能力,这符合人们对于自动驾驶汽车的期望。强化学习,其最通用的模型构造方法是构造一个列表存储所有的状态-动作对的评价值。但是,这种方法对于自动驾驶这种状态-动作空间较大的情况不能奏效。因此基于强化学习的自动驾驶算法一直未出现较大规模的应用。
Hinton等[7]在2006年提出的深度置信网络(deep belief networks)开创了深度学习的一个新纪元。2013年,Krizhevsky等[8]在大规模视觉识别挑战赛(imagenet large scale visual recognition competition)使用卷积神经网络取得突出成绩之后,深度学习开始在计算机视觉等许多领域得到广泛应用。2016年,Bojarski等[9]提出使用卷积神经网络进行自动驾驶系统研究的方案。普林斯顿大学于2016年提出了改进的基于深度学习的自动驾驶系统方案[10]。随着深度学习在各大领域的广泛应用,研究人员开始尝试将深度学习和强化学习进行结合形成了较为成熟的深度强化学习框架。其中最具代表性的就是Mnih等[11]提出的DQN(deep q-network)算法。由于DQN这种方法针对的是离散动作空间,所以这种方法并不适用于自动驾驶控制系统的开发。2016年,Google DeepMind又基于演员-评论家模型[12],将DQN算法改进为深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法[13],实现了对于连续动作空间的控制。这种演员-评论家模型,分别使用一个价值网络对当前状况进行评估,一个策略网络做出下一步决策,两者的结合实现了更加符合人类决策过程的智能控制模型。
笔者根据上述研究提出一种结合了深度学习和强化学习的自动驾驶策略学习算法:采用基于DDPG的强化学习算法进行模型的在线训练,使用真实的人类驾驶数据对actor网络进行预训练,同时为了增强模型的泛化能力,在actor网络中加入LSTM预测机制。最后,笔者对原始DDPG算法和新的算法的实验效果进行了比较。
1 基于强化学习的方法
1.1 强化学习
强化学习思想来源于生物学中的动物行为训练,驯兽员通过奖励与惩罚的方式让动物学会一种行为和状态之间的某种联系规则[14]。强化学习框架如图1所示。智能体agent从环境感知初始状态st,采取动作at,此agent会得到来自环境的奖励rt,如此产生一系列的“状态-动作-奖励”,直到结束状态为止。agent的目的就是通过不断地探索环境得到反馈来最大化奖励值总和。下面将对一些比较成熟的强化学习算法进行介绍。

图1 强化学习框架Figure 1 Reinforcement learning framework
1.2 DQN算法
DQN算法于2013年由Mnih等[11]提出,并于2015年进行了改进。DQN算法是传统强化学习的一个延伸,它将智能体agent和环境的交互与马尔可夫决策过程(MDP)形式化。马尔可夫决策过程就是智能体在初始状态s0下,从动作空间A中挑选一个动作a0执行,执行后,智能体按照一定概率转移到下一个状态s1,然后再执行下一个动作,重复上述过程。尤其是在步骤t时,agent通过执行动作at,从状态st转移到新的状态st+1,并且会得到环境反馈的奖励值rt。在DQN之前,强化学习中的一个重要分支为Q学习算法。Q学习通过构造一个表来存储状态-动作对。Q学习的目的是根据Bellman方程将Q值函数最大化,其形式为:
(1)
式中:γ是折扣因子。在DQN之前,当采用非线性结构(例如神经网络)来逼近Q学习的值函数时,不能保证探索的收敛性。DQN引入了经验回放和目标网络来解决这个问题[11]。首先,状态-动作对转移序列{st,at,rt,st+1}保存在经验缓冲区中,然后训练一个深度神经网络,采用从经验缓冲区中随机抽取的转移序列来逼近Q函数,这种技术在很大程度上打破了连续转移的相关性,使得学习过程更加稳定。Q网络更新时,Q值的目标为:
(2)

(3)
DQN算法只考虑离散动作域,这种方法对于自动驾驶这种连续动作空间来说将不再适用。下面将介绍一种适用于连续动作空间的算法。
1.3 DDPG算法
DDPG算法基于确定性策略梯度DPG算法[15],同时采用了演员-评论家模型[12],而且保留了DQN的经验回放和目标网络技术[11]。
actor-critic算法[12]将策略梯度算法和值函数结合在一起。策略函数称为actor。值函数称为critic。基本上,演员actor会做出一个动作,评论家critic会评价这个动作。然后根据这些评价,演员将调整自己的动作,为了下次做得更好。
DDPG算法分别参数化评论家函数Q(s,a)和演员函数μ(s|θμ)。评论家函数的定义类似于Q-learning中的值函数,并通过最小化来更新。如公式(4)和(5)所示:
(4)
Q(st,at|θQ)。
(5)
演员函数将当前状态映射到当前最佳动作,并通过以下方式更新,如式(6)所示:
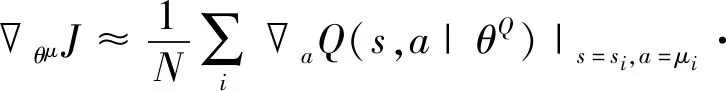
(6)

(7)
(8)
2 DDPGwE算法
基于深度学习的自动驾驶方法需要大量人工标注的数据,模型泛化能力不足。而基于强化学习的算法初始阶段学习速度缓慢,学习效率低。除此之外,希望智能体能够在驾驶过程中从专业司机的演示中学习一些驾驶风格,但是强化学习算法只能根据给定的奖励函数来进行优化,这很难描述专业司机的偏好,很难学习到类似人类的驾驶技巧。基于以上存在的问题,笔者在DDPG算法的基础上,提出融合了专家经验的DDPGwE(determi-nistic policy gradient with expert)算法。DDPGwE增加了采用由专业司机驾驶数据组成的专家经验对演员网络进行预训练的模块。同时,为了让智能体学习到类似人类在驾驶环境中对未来状况预判的能力,笔者在演员网络中加入LSTM预测模块,用来增强智能体在驾驶环境中对未来状况的预判能力,以便更好地做出决策,避免一些危险状况的发生。
2.1 DDPGwE整体框架
DDPGwE算法的整体框架如图2所示。本文方法仍然采用原始DDPG算法的整体框架。但是,在原始网络中进行改进。本方法加入了采用基于专业司机的驾驶经验数据组成Expert模块来对演员网络进行预训练。因为人类在学习新知识的过程中,在初始阶段会有“老师”进行指导和传授经验,在后面的学习过程当中自己将会不断地探索,这一过程正是强化学习的过程。所以,在强化学习阶段之前使用专业司机经验对网络进行预训练,这一过程更加接近人类的学习过程。同时专家经验参与到强化学习过程当中,使用一个策略在演员和专家之间选择最佳动作。同时为了让智能体更好地做出决策,该算法在演员网络中加入LSTM预测模块,让智能体学习对未来状况进行预判。因为这也符合人类的驾驶习惯,有了对未来状况的预判,将很大程度地提高驾驶安全性。
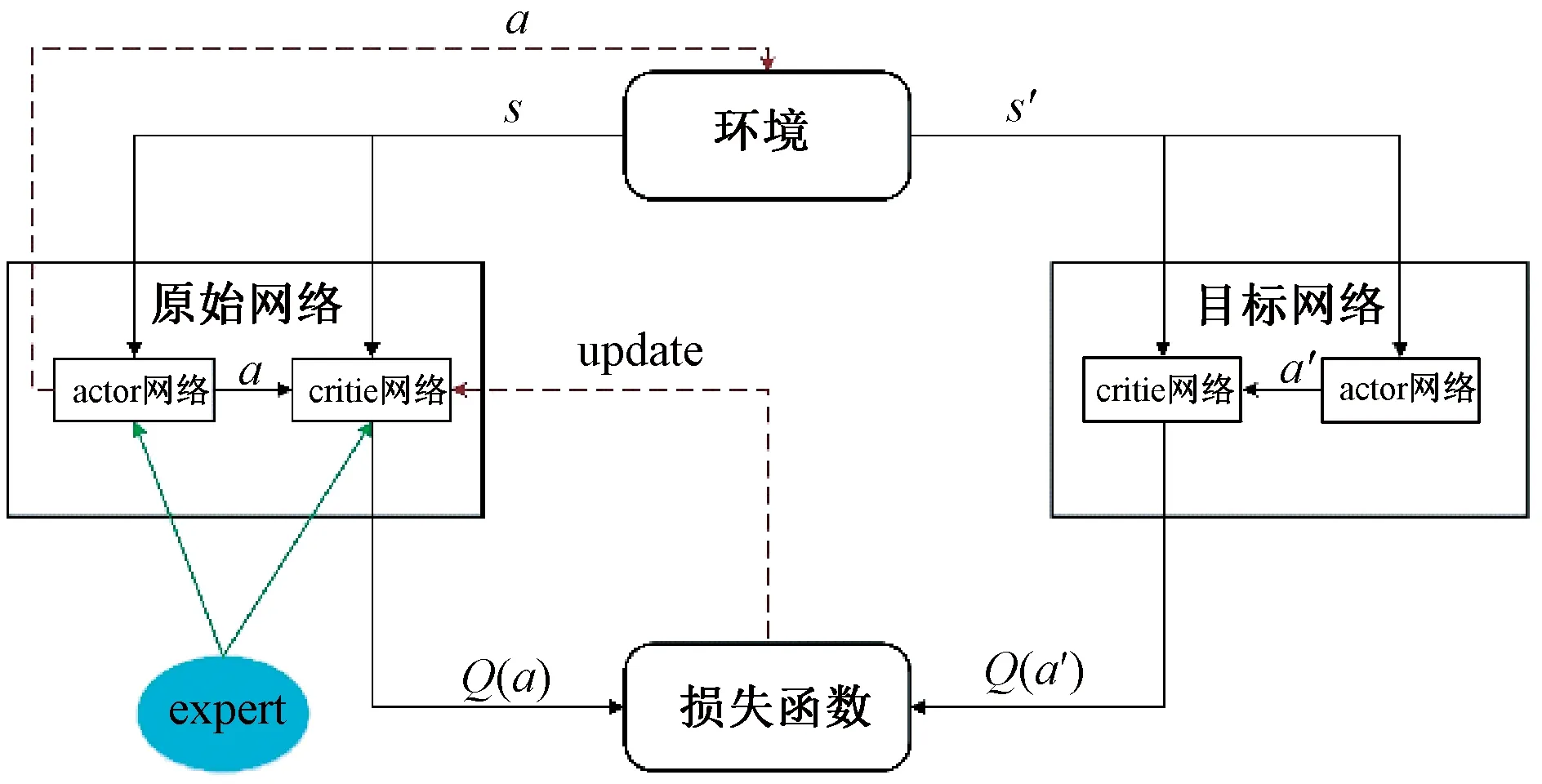
图2 DDPGwE框架Figure 2 DDPGwE framework
2.2 LSTM算法
长短期记忆网络(long short term memory network,LSTM)算法[16]是一种改进的循环神经网络算法,它使用一种被称为LSTM的记忆单元来判别哪些信息应该被保留,控制信息从前一时刻到下一时刻进行传输,是目前应用最为广泛的具有记忆功能的网络,其数学模型如式(9)~(13)所示:
it=tanh(Wxixt+Whiht-1+Wcict-1+bi);
(9)
ft=tanh(Wxfxt+Whfht-1+Wcfct-1+bf);
(10)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc);
(11)
ot=tanh(Wxoxt+Whoht-1+Wcoct+bo);
(12)
ht=ottanh(ct),
(13)
式中:W是LSTM 细胞单元的参数矩阵;b是LSTM细胞单元的偏置;tanh是激活函数,可以增强神经网络的非线性。
2.3 预训练演员网络
根据深度学习当中的预训练思想,对演员网络进行改进,如图3所示。通过人工采集的专业司机的驾驶数据组成的专家经验来对演员网络进行预训练,训练过程将状态-动作对作为神经网络的输入。同时专家经验也参与到动作的决策过程中,该方法确保了专家经验在初始阶段参与度高,而在接下来的强化学习阶段的参与度较低。最后,演员网络将掌握专家的驾驶经验,并且学习到专家经验之外的动作。同时为了让智能体学习类似人类真实驾驶行为中对未来状况预判的能力,在演员网络中加入LSTM预测模块,从而加强模型对未来状况的预判能力,从而更好地做出决策,避免危险状况的发生,使得算法具有更好的泛化能力和预测能力。

图3 加入预训练的actor网络Figure 3 Adding pre-trained actor network
2.4 算法流程
DDPGwE算法的参数更新过程和DDPG算法的过程相似。使用状态-动作对作为专家经验对初始演员网络进行预训练。在强化学习阶段,在同样的输入状态下,希望演员网络生成的动作跟专家经验相似。同时,也希望agent所产生的这一动作在与环境交互的过程当中能够得到更高的奖励值。算法流程如下。
1:随机初始化原始演员网络θμ、原始评论家网络θQ。
2:随机初始化目标演员网络θμ′、目标评论家网络θQ′。
3:初始化经验回放池D。
4:首先采用专业司机数据预训练原始演员网络并保存权重。
5:forepisode=1,Mdo
6:加载预训练权重。
7:获得初始状态s1。
8:forstep=1,Tdo
9: 利用策略在专家经验和演员网络产生的动作中选择一个执行动作。
10: 将执行完动作之后得到的序列数据(st,at,rt,st+1)存储到D中。
11: 利用固定的比例从D中采样一批训练数据。
12: 利用式(4)和式(5)更新评论家网络。
13: 利用式(6)更新演员网络。
14: 利用式(7)和式(8)更新目标网络。
15: end for
16: end for
3 实验环境及设置
Torcs是一款开放式的、跨平台的赛车模拟器[17]。它通过模拟真实车辆的发动机、离合器、变速箱等车辆物理模型来实现车辆与环境的交互,其高度的模块化和可移植性使其成为人工智能研究领域众多研究工作者的理想选择。本文方法也是采用了基于Torcs平台的仿真环境来验证算法的可行性。Torcs有多个可用的地图,笔者采用如图4所示的地图进行算法的测试。

图4 模拟赛道Figure 4 Simulated racetrack
采用一个包含29个传感器值的向量(速度、角度、测距仪等)作为状态输入,3个连续值(转向、加速和制动)作为动作输出。对于转向,范围为[-1,1],其中-1表示最大右转,1代表最大左转。对于加速度,它在[0,1],其中0表示加速度为0,1表示加速度最大。对于制动,在[0,1],其中0表示无制动,1表示全制动。
在本文中,采用一种相对简单的方式来定义奖励函数,如式(14)所示:
R=vxcosθ-vxsinθ-vx|trackPos|。
(14)
为了防止agent经常偏离轨道中心,也将trackPos作为奖励函数计算的一部分,trackPos表示车辆中心线与轨道边缘的距离。希望最大化agent纵向速度vxcosθ,最小化agent横向速度vxsinθ。
4 结果与讨论
笔者分别记录了两种方法在训练过程中所获得的平均奖励值的统计分布。如图5所示,图5中黑色虚线是原始DDPG算法在训练过程中所得到的奖励值的分布,黑色实线是改进的DDPGwE算法在训练过程中的平均奖励值的分布。从图中可以看出,随着训练的不断进行,智能体所得到的奖励值在不断地增加,说明了智能体很好地学习了驾驶技能。

图5 平均奖励值Figure 5 Average reward
表1记录了原始DDPG算法和改进的算法的训练过程所消耗的时间和碰撞次数,以及达到收敛的迭代次数。根据仿真时间记录并且结合图5,原始DDPG算法需要240 min的学习才能在Torcs中完整跑完一圈。而本文的算法仅用30 min即可在Torcs中完整跑完一圈。在相同的迭代次数下,原始DDPG算法的学习过程不稳定,而且学习速度较慢,并且收敛到相对稳定的值所需要的时间较长。而改进过的算法则表现较好,根据图5和表1可以看出,DDPGwE算法的学习速度较快,可以很快地收敛到一个较稳定的奖励值。并且,学习的过程非常稳定,所需要的时间也大大缩短。

表1 训练信息Table 1 Training information
5 结论
提出了一个基于深度强化学习的自动驾驶策略学习算法(DDPGwE)。基于DDPG算法,首先使用专业司机驾驶数据对网络进行预训练,同时在强化学习过程中,专业司机经验也将参与到决策过程中。并且在actor网络中加入了LSTM模块来增强网络的稳定性和泛化能力。实验结果显示,笔者所提出的算法与原始DDPG算法相比,能够加快智能体的学习速度,并且能够快速地收敛到一个稳定的奖励值。同时,算法的泛化能力也得到了提高,具有很好的实际应用价值。
