基于预警文本信息的调度命令智能生成模型
2020-10-11彭其渊胡雨欣鲁工圆
彭其渊,胡雨欣,鲁工圆
(1. 西南交通大学交通运输与物流学院,四川成都610031;2. 西南交通大学综合交通运输智能化国家地方联合工程实验室,四川成都610031;3. 中国中铁二院工程集团有限责任公司,四川成都610031)
调度命令是调度员处理日常行车工作中的有关问题,以及在非正常情况下组织并指挥有关部门和人员办理行车工作的带有约束性的指令。目前,我国列车调度命令主要由调度员人工编写,通过计算机调度命令软件、传真或者电话向相关部门或人员传达。调度命令编写工作占用了调度员大量的时间与精力,特别是在非正常情况下的应急处置过程中,要求调度员在短时间内根据已有信息发布出正确的调度命令。因此,有必要对调度命令的生成进行深入研究,研究智能化调度命令生成方法,从而减轻调度员调度命令拟写工作的负担,改善调度命令发布的效率和规范性,这对于提高铁路运输效率、保证铁路运营安全有着重大意义。
调度命令的发布场景一般可分为日常行车组织和非正常情况下的应急处置两种情况。对于日常行车工作,已有的研究大多集中于规范调度命令管理[1-2],主要针对调度命令在发布、传达、执行中的常见问题[3]提出改进措施[4]。
铁路运输组织是一个动态过程,在日常生产组织中,人员、设备、环境等因素可能突然出现直接危及行车安全或可能危及行车安全的非正常情况,包括设施设备故障、天气变化、群体事件、重大疫情、电力中断等现象。针对这种非正常情况,调度员能够快速掌握事件信息,第一时间介入应急指挥工作,进行相关处置和通报。因此,非正常情况下的应急处置是行车安全的重要组成部分,也是调度员的工作重点。孙鹏举等[5]为有效提升高速铁路列车调度员应急场景处置能力,构建了应急仿真系统。季丕祥[6]对调度人员在面对紧急情况时的应急处置能力进行了分析,同时有针对性地提出解决措施。李磊等[7]将案例推理理论应用到铁路应急决策中,并提出一种实用的行车事故应急决策方法。马齐飞扬等[8]为解决现阶段列车突发事件应急救援方法普适性及动态性差的问题,建立基于改进逼近理想解排序法的处置点应急救援决策方法。
进入新世纪以来,信息技术突飞猛进,智能化技术在自然语言处理[9]、语音识别[10]、图像识别[11]等方面取得突破性进展。在中长期铁路网规划中,将智能化、现代化作为发展任务之一。
针对非正常情况下的应急处置过程,采用深度学习框架,基于预警文本信息,提出一种基于序列‒序列(seq2seq)模型的调度命令智能生成方法,并利用实际预警文本信息和调度命令数据进行实验验证。
1 调度命令智能生成模型总体架构
调度命令智能生成模型针对非正常情况下的应急处置场景。一般来说,当应急处置情况出现时,在铁路局层面上信息的收集和上报都主要集中在调度所,凡与列车运行相关,或是发生在运行列车上的各种信息,现场人员一般都直接向列车调度员反映,可以说列车调度员是整个事件的信息汇聚点。列车调度员通过各方反映的情况编写调度命令,并直接将调度命令发往各受令方。基于以上特点,本模型将相关部门或车站发出的预警文本信息作为模型输入,信息提取与转化后输出对应的调度命令。
图1为调度命令智能生成模型总体架构,主要分为神经网络模块和调度命令修正模块两个部分。将预警文本信息处理后的词序列作为神经网络的输入,该神经网络是一个seq2seq模型,神经网络输出初始调度命令。由于生成的初始调度命令与标准调度命令的部分内容存在一些误差,因此利用调度命令修正模块对初始调度命令内容进行修正、替换,得到最终调度命令,从而提高调度命令生成质量。
2 调度命令智能生成模型
2.1 基于长短时记忆网络的seq2seq模型
seq2seq模型是一种编码器‒解码器结构的网络,该模型最早于2014年被Google Brain团队和Yoshua Bengio团队提出[12-13],是一个广泛应用于机器学习的深度学习模型框架,目前在聊天机器人、机器翻译、自动文摘等领域中应用广泛。
编码器和解码器的组合具有多样性,使用长短时记忆(LSTM)网络进行编码器和解码器的构建。LSTM网络是循环神经网络(RNN)的改进模型,能够在一定程度上避免梯度消失问题。LSTM网络神经元内部结构如图2所示。
令t时刻输入为xt,一个LSTM网络单元通过
学习可得到t时刻隐节点状态ht。LSTM网络内部计算式如下所示:
式(2)~(6)中:ft、it、ot分别表示LSTM网络中的遗忘门、输入门和输出门;σ为激活函数;W、U为权重;b为偏置项;ct为t时刻记忆细胞存储信息;ct-1为(t-1)时刻存储信息;⊙表示矩阵点乘。
seq2seq模型基本思想是利用神经网络模型将一个可变长度的输入序列转变成一个固定长度的向量,再利用神经网络模型将该向量转变成一个可变长度的目标输出序列。seq2seq结构如图3所示。
2.1.1 编码部分
在编码过程中,对预处理阶段得到的调度命令词序列(x1,x2,…,xt)从前向后编码,根据LSTM网络计算规则,可得到当前隐节点状态
式中:xt表示当前时刻的输入。
在输入遇到结束标识符时表示最后一次编码完成,此时整个文本通过编码器转化为隐节点状态。每一次隐节点状态都依赖于上一次隐节点状态,经过多次循环迭代后,最后一次隐节点状态包含了整个文本的语义特征。定义语义向量c为编码过程中最后一个隐节点状态。
2.1.2 解码部分
解码过程可以看作是编码过程的逆过程。当前隐节点状态由前一时刻隐节点状态st-1、前一时刻输出yt-1和语义向量c得到,即当前时刻隐节点状态
通过隐节点状态st和前一时刻的输出来预测当前时刻的输出yt,语义向量c作为输入的一部分同时参与运算。每个单元的概率可表示为
式中:g(·)表示非线性多层神经网络。选取其中概率最大的值作为t时刻的输出yt。
从整体来看,基于LSTM网络的seq2seq模型将预警文本信息及其对应调度命令看作词序列,编码端将输入的预警文本信息编码为固定维数的向量,解码端负责从该向量中解码出对应的语言表达。
编码器‒解码器框架在自然语言处理中可读取任意的文本序列,并将其转化为另一种文本序列,这也是调度命令智能生成模型的基础。研究发现,seq2seq模型在将输入文本信息压缩为一个语义向量时可能产生信息丢失的问题[14],并且在对文本进行输出时缺乏提取关键信息、排除无用信息的能力,这就会使输出的初始调度命令部分信息的生成出现错误。
2.2 调度命令修正
调度命令是行车有关部门具体办理行车工作的依据,其内容的正确性关乎铁路运营安全,因此有必要针对初始调度命令生成错误的部分进行修正。通过构建调度命令修正模块对神经网络生成有误的信息加以修正、替换,以保证调度命令智能生成的正确性。
2.2.1 调度命令修正策略
对各类初始调度命令的生成结果进行分析,将难以正确生成的信息归纳为里程、线路走向、速度值、车次号和车站地点等五种类型。针对这五类信息,分别提出五种相应策略进行修正。
(1)策略1:里程信息修正
预警文本信息或调度命令对事件发生地点的位置描述方式之一是里程表示,如K1200+830,里程表示使地点描述更加精确、规范。
里程信息修正思路为:对预警文本信息中的里程信息进行抽取,结合《高速铁路列车调度员应急处置指导书》中调度命令里程规则对里程信息处理后,得到正确的里程信息;对初始调度命令中的里程信息进行抽取;将正确的里程信息与初始调度命令中的里程信息进行替换,修正完毕。对于这种具有一般格式的信息,使用正则表达式进行信息抽取[15]。通过正则表达式可以快速地对字符串进行信息抽取操作,并且抽取结果不是一个可能值,而是准确值。
(2)策略2:线路走向信息修正
同里程信息修正相似,线路走向信息修正思路为:对预警文本信息中的线路走向信息进行抽取,得到正确的线路走向信息;对初始调度命令中的线路走向信息进行抽取;将正确的线路走向信息与初始调度命令中的线路走向信息进行替换,修正完毕。
正则表达式如下所示:上行线|下行线|上、下行线|上下行线。
(3)策略3:车次号信息修正
车次号信息修正思路与线路走向信息修正类似,正则表达式如下所示:[0-9]{0,2}[a-zA-Z]{0,2}[0-9]*次。
(4)策略4:速度值信息修正
限速调度命令是运用最为普遍的调度命令类型之一,应急处置事件类型和严重程度直接影响限速调度命令的限速大小。针对限速调度命令的限速值,根据《高速铁路列车调度员应急处置指导书》等规章的指导,对两类事件下的限速条件和限速值进行了规则总结:风速限速报警事件与雨量限速报警事件。部分规则如表1所示。

表1 速度值修正规则Tab.1 Speed value correction rule
限速值信息修正思路为:对预警文本信息中的风速或雨量信息进行抽取,结合《高速铁路列车调度员应急处置指导书》中限速规则将其进行处理后,得到正确的限速值信息;对初始调度命令中的限速值信息进行抽取;将正确的限速值信息与初始调度命令中的限速值信息进行替换,修正完毕。
风速正则表达式如下所示:[d+.d]*m/s。
雨量正则表达式如下所示:[0-9]{1,10}mm|[0-9]{1,10}.[0-9]{1,10}mm。
限速值正则表达式如下所示:d+km/h。
(5)策略5:车站信息修正
除里程表示之外,预警文本信息或调度命令一般直接给出事件发生的车站或者区段,如:“3月2日16时01分,贵广线佛山西站SG信号机故障灭灯。”中写明事件发生地点为佛山西站。
车站信息修正思路为:对预警文本信息中的所有车站信息进行抽取,得到正确的车站信息;对初始调度命令中的车站信息进行抽取;将正确的车站信息与初始调度命令中的车站信息进行替换,修正完毕。
然而,直接用车站或地点名描述事件位置时表达方法众多。例如,表达长沙南站至贵阳北站时,可能的表达方式有“长沙南至贵阳北”、“长沙南―贵阳北”、“长沙南站至贵阳北站”等,使用正则表达式进行地点抽取可能会产生疏漏。针对该情况,需要运用更加智能化的信息识别提取方法。
命名实体识别是用来识别并分类文本中所出现的指定名词的一类自然语言处理任务,随着深度学习的兴起,基于神经网络的命名实体识别方法由于其自动提取特征等优势逐渐获得大量应用。使用基于双向长短时记忆(BiLSTM)网络‒条件随机场(CRF)的方法进行命名实体识别。
构建的命名实体识别模型如图4所示。模型的第一层为输入层,随机初始化嵌入矩阵后,将输入字符表示从独热矢量映射为低维字向量(x1,m,x2,m,…,xk,m);模型的第二层为双向长短时记忆网络层,将上一阶段得到的向量序列作为双向长短时记忆网络的输入,利用上下文信息有效地提取特征;模型的第三层为条件随机场层,对句子进行序列标注,根据上文信息进行标签预测。最终,输出该神经网络预测出的“BIO”标注。
为了得到更好的识别效果,根据”BIO”标注方法对5 000余条调度命令和安监报信息进行标注,作为命名实体识别模型的训练和测试语料。“BIO”标注是指对序列中每个元素赋予标注“B‒X”、”I‒X”或者“O”中的一种。本模型中三种标注类型如下所示:“B‒LOC”、“I‒LOC”和“O”。其中,“B‒LOC”表示该字符属于车站名称的起始字,“I‒LOC”表示该字符属于车站名称的中间字,“O”表示该字符不属于车站名称。
2.2.2 调度命令修正模块构建
XMTD-8222电热恒温鼓风干燥箱,上海精宏实验设备有限公司;MJX-160B-Z霉菌培养箱,上海博迅实业有限公司医疗设备厂;SW-CJ-20双人单面净化工作台,苏州净化设备有限公司;LDZX-30KBS立式压力蒸汽灭菌器,上海申安医疗器械厂;HJ-2A数显恒温磁力加热搅拌器,金坛市城东新瑞仪器厂;FA2004N电子天平,上海菁海仪器有限公司;H1850R离心机,湖南湘仪实验仪器开发有限公司;PHS-3CpH计,上海智光仪器仪表有限公司;紫外可见分光光度计,上海仪电分析仪器有限公司;恒温水浴锅,北京科伟永兴仪器有限公司。
对涉及不同应急处置事件的预警文本信息,神经网络可对其进行统一处理和训练,从而生成初始调度命令。由于调度命令种类多样,不同类型的调度命令拥有不同的内容、结构与特征,因此难以对所有初始调度命令使用同样的方法进行修正。在调度命令修正阶段,对不同类型应急处置事件分别构建不同的调度命令修正模块。为简化模块构建复杂度,各事件调度命令修正模块由第2.2.1节所提出五种调度命令修正策略组合构成。修正策略的调用提高了模块的自由度,并在很大程度上减少了不同类型模块构建的工作量。
以“接触网跳闸重合不成功”事件为例,介绍修正模块构建流程。事件预警文本信息如下所示:“4月5日11时30分,供电调度通知鲘门至惠东站间上、下行线接触网跳闸自动重合不成功(故标下行线1 504 km816 m)”,对应的调度命令为:“G6328次列车运行至鲘门站至惠东站间上下行线1 502 km816 m 至1 506 km816 m处限速40 km·h-1”。
对上述信息进行分析,该类调度命令为列车限速调度命令,由于限速值可通过神经网络训练得到,因此需要修正的部分为:车站信息,如“鲘门”、“惠东”;线路走向信息,如“上、下行线”;里程信息,根据《高速铁路列车调度员应急处置指导书》规定,限速位置按照故障点前后各2 km确定。综上,“接触网跳闸重合不成功”事件修正模块以策略1、策略2和策略5组合而成。
通过以上方法对各类应急处置事件构建对应的调度命令修正模块,当神经网络输出初始调度命令后,即可通过关键词匹配到相应的修正模块,调用其中的修正策略对初始调度命令进行修正处理,得到最终调度命令。
2.3 评价指标
采用记忆导向型摘要评价(ROUGE)方法来评价最终调度命令智能生成质量。ROUGE 方法是Lin等[16]于2003年提出的一种评价自动文摘和机器翻译质量的指标,中心思想是将自动生成的文摘与专家制定的标准文摘进行比较,通过统计两者之间的基本单元数目进行评分。将模型输出的调度命令与标准调度命令进行比较,统计生成调度命令与标准调度命令的基本单元数目,使用ROUGE 准则中的ROUGE‒1、ROUGE‒2和ROUGE‒L来评价调度命令生成质量,最终得出的数值越高表示生成的调度命令与标准调度命令相似度越高。
ROUGE准则定义如下所示:
式中:Cn,m为生成的调度命令与标准调度命令共有的n元词数目;Cn为标准调度命令中n元词数目,取n=1,2。
式中:l(Y,Y标)为自动生成调度命令与标准调度命令连续最长共有序列的长度;l(Y标)为标准调度命令长度。
3 实验过程及结果分析
3.1 实验过程
探究基于seq2seq模型的调度命令智能生成方法的应用效果,并对调度命令修正模块的修正情况进行验证,实验过程如图5所示。首先,将训练数据预处理之后用于神经网络训练,通过参数调试得到最优神经网络模型;其次,将测试数据中的预警文本信息作为模型的输入投入训练好的神经网络模型中,生成初始调度命令;再利用调度命令修正模块进行内容修正,得到最终生成的调度命令;最后,使用ROUGE评价方法对生成的调度命令进行评价。
3.2 数据集
根据广州铁路集团安监报数据和调度命令数据,建立了预警文本信息‒调度命令数据集,共计16 735条。数据集中预警文本信息和发布的调度命令一一对应,共计13种类型。表2列出了13种类型应急处置、对应的调度命令以及各类型事件所对应的调度命令修正策略。为了更好地对实验结果进行测试,在数据集中抽出1 300条数据构建验证集,验证集中包含13种类型预警文本信息‒调度命令数据,每种类型数据100条,共计1 300条。将剩余数据的90%作为训练集,其余10%的数据作为测试集(包含13种类型应急处置事件,每个应急处置事件数据量一致)。为了保证调度命令的规范性,依据《铁路运输调度规则(2017版)》中调度命令模板对调度命令数据进行规范化处理。
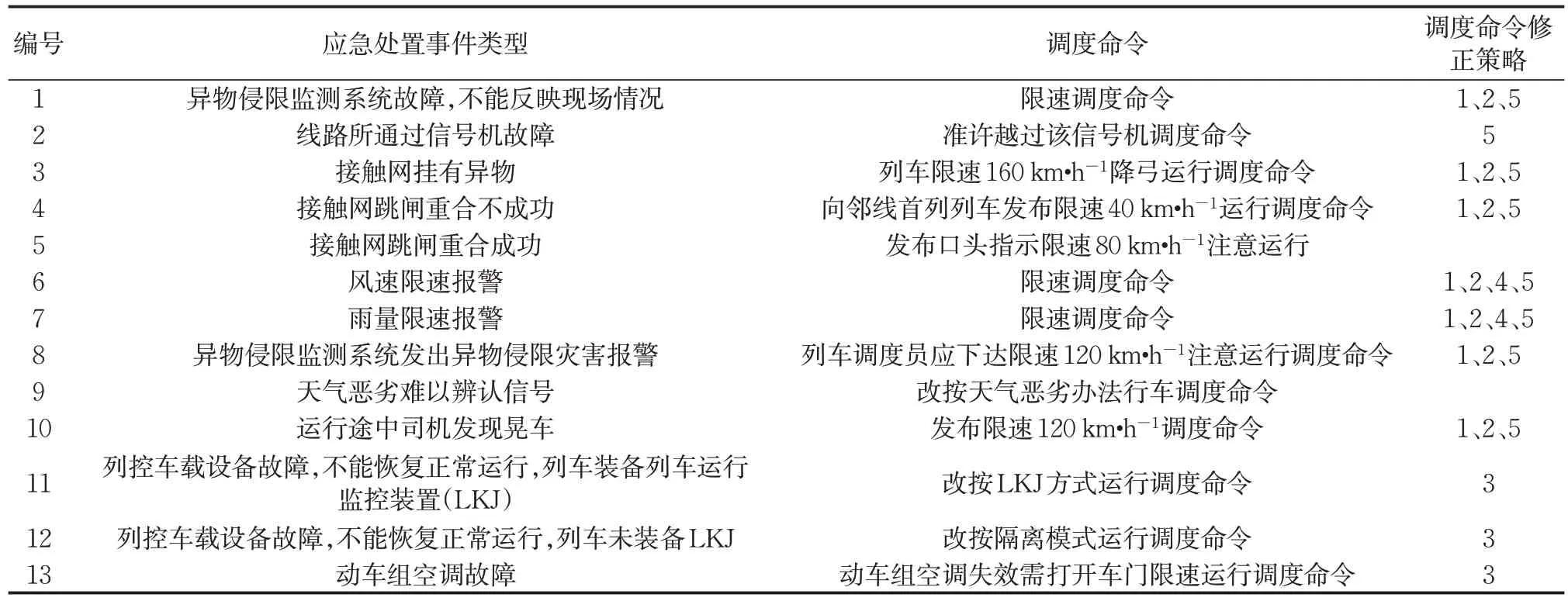
表2 调度命令数据集类型及修正策略Tab.2 Dispatching command dataset types and correction strategies
值得注意的是,对于同一类型应急处置事件,不同情况下的处置办法不同。例如,针对接触网跳闸事件,接触网自动重合不成功时,需发布调度命令限速;接触网自动重合成功时,只需发布口头指示限速80 km·h-1注意运行。从两者之间区别度非常小的文本信息中能够获取的有效特征是有限的,这也是调度命令生成的难点之一。
3.3 数据预处理
为了便于模型能够对预警文本信息进行识别,并获取更多的有效特征,在将数据输入模型之前首先需要进行预处理,主要有以下三个步骤:
第一步,中文分词。使用Python库中的jieba库进行分词处理,为了更好地识别未登录词,构建了车站名称词典。词典中包含了所研究的广铁集团管辖范围内的354个车站和地理位置词汇,提高分词精度。
第二步,去噪处理。主要剔除无用的停用词或标点符号,由于需要生成完整的调度命令信息,因此仅对预警文本信息进行去停用词及标点符号处理。
第三步,中文转换。在利用神经网络模型进行调度命令生成任务之前,首先需要将预警文本信息和调度命令的自然语言化的字词转化为计算机可以理解的数学语言。按出现频率从高到低的顺序分别为每一个分词词语赋予一个数字,数字从1开始依次增加,并按<“词语”:数字>的形式存储在字典中,如<“车站”:128>。除了现有词语之外,额外加入以下四种字符:
3.4 实验结果
3.4.1 神经网络学习率和迭代次数参数对比实验
为了确定seq2seq模型的最优参数,针对学习率、迭代次数设置不同的对比实验。实验中seq2seq模型编码器和解码器均采用两层LSTM网络,隐层节点数为64,批量大小为64,随机失活设为0.5,采用Adam算法优化损失函数。
通过seq2seq模型输出的调度命令称为初始调度命令,将初始调度命令与标准调度命令进行比对,初始调度命令与标准调度命令完全匹配视为生成正确,有任何一处无法匹配则视为生成有误。值得注意的是,由于后续还会由调度命令修正模块对前一阶段生成的初始调度命令内容进行修正,因此对于初始调度命令中与标准调度命令不相同,但可由调度命令修正模块进行修正的部分,不将其看作生成有误。
在相同的训练集下,设定学习率r为0.100、0.010、0.001,迭 代 次 数 为100~700。 图6 为 对seq2seq模型在以上参数下进行训练,并在验证集上实验的结果。由图6可见,在三种学习率下,随着迭代次数的增加,模型正确率都呈现出先增高后降低的趋势。当学习率0.001,迭代次数400时,实验效果最佳。对此时各类型应急处置事件的初始调度命令生成正确率利用验证集进行测试,如图7所示。
由图7可知,应急处置事件类型编号2“线路所通过信号机故障”在所有事件类型中正确率最低。该类调度命令由于文本长度较短、特征过少,导致在机器学习时难以捕获命令特征,未能达到较好的智能生成效果。其余事件的调度命令生成正确率大部分在90%以上,生成正确率较高。
3.4.2 实验结果
基于第3.4.1节确定的各项参数对训练集进行训练,在测试集上进行最终实验结果展示。使用ROUGE评价指标分别对seq2seq模型和调度命令修正阶段生成的调度命令进行评价,结果取所有输出结果的平均值,实验结果如表3所示。

表3 ROUGE评价结果Tab.3 ROUGE evaluation results
实验结果表明,最终生成的调度命令与标准调度命令的匹配度较高,并且调度命令修正模块有效提升了模型生成质量。其中,Rouge‒1结果提升19.0%,Rouge‒2结果提升18.5%,Rouge‒L结果提升37.9%。
表4为利用修正模块修正前后的调度命令生成结果示例,其中包含13种类型的应急处置事件。从最终生成效果可见,提出的调度命令智能生成模型能够有效地基于预警文本信息生成对应调度命令,生成的调度命令具有连贯性和可读性,并且调度命令修正模块能够对初始调度命令进行合理修正,提高了调度命令内容的正确率。
5 结论
(1)seq2seq模型能够有效地基于预警文本信息生成调度命令,正确率超过90%。
(2)引入调度命令修正模块可以有效提升调度命令生成正确率,相较于没有使用修正模块时,Rouge‒1结果提升19.0%,Rouge‒2结果提升18.5%,Rouge‒L结果提升37.9%。
(3)不同结构、特征的预警文本信息对于最终生成的调度命令正确率有一定影响,“线路所通过信号机故障”事件错误率最高。
