面向模型并行训练的模型拆分策略自动生成方法*
2020-10-10郭振华赵雅倩
王 丽,郭振华,曹 芳,高 开,赵雅倩,赵 坤
(1.浪潮电子信息产业股份有限公司高效能服务器与存储技术国家重点实验室,山东 济南 250000; 2.广东浪潮大数据研究有限公司,广东 广州 510000)
1 引言
近年来,随着人工智能的兴起,深度神经网络DNN(Deep Neural Network)在图像视频分类、语音识别和语言翻译等领域得到广泛应用。随着训练数据集的增大和网络规模的日趋复杂,深度学习的巨量计算需求催生硬件架构不断创新,当前的混合异构平台拥有大量的计算资源,包括 CPU、GPU、FPGA和AI芯片[1,2]等。现有的AI算法模型训练方案都是基于CPU+GPU架构设计实现的,虽然GPU在AI算法模型训练方面的异构加速性能比较好,但是GPU的高成本、高功耗特性随着大规模训练GPU平台的部署已经成为AI算法模型训练平台的挑战。为了实现高性能和高能效,学术界和工业界都对DNN的硬件加速进行了深入研究,使用混合不同特性的异构加速设备对AI算法模型进行协同训练已经成为一种新的研究思路。
当前最流行的分布式训练方式是数据并行,每个计算设备上都部署了完整的模型副本,设备间使用不同数据集进行参数训练。这种方式需要在单个设备上存储整个DNN模型的权重和特征,并且设备间需要同步和更新权重,系统整体效能受限于设备计算能力均衡性和内存配置。当DNN模型规模较大无法将整个模型部署在单个计算设备上时,研究人员会采用模型并行方式进行训练。模型并行训练涉及在设备之间划分模型,以便每个计算设备仅评估模型参数的一部分并执行更新。已有的研究成果表明,模型并行训练主要针对已设计好的神经网络结构采用手工划分网络并将其映射到不同的计算设备上,手工划分网络由于对任务负载的运行时间估计不够精准,容易导致计算节点上的负载不均衡[3 - 5]。要想实现网络模型的自动划分并且达到负载均衡,还面临着如何构建精准的深度神经网络算子性能模型以及设计任务调度算法的难题。
本文提出一种面向模型并行训练的模型拆分策略自动生成方法。该方法首先基于静态的神经网络模型参数、AI 加速器设备的理论计算能力以及设备间的理论通信带宽等参数,构建性能模型;然后根据任务负载均衡策略中提出的算法对网络算子进行任务调度;最后给出DNN网络算子在多个AI加速设备上的模型拆分策略。本文的实验表明,该方法生成的模型分配策略能够高效利用单个计算平台上的所有计算资源,并保证模型训练任务在各设备之间的负载均衡,与目前使用的人工拆分策略相比,具有更高的时效性,且降低了由于人为因素带来的不确定性。
2 背景介绍
2.1 DNN网络训练
深度神经网络(DNN)的训练是计算密集型的,通常使用随机梯度下降SGD(Stochastic Gradient Descent)进行训练,其训练过程分为前向传播和后向传播2个阶段。训练中,数据集被随机抽样,按批次输入到神经网络中,在前向传播阶段对数据集产生预测结果,并计算损失函数;然后向后传递反向传播误差,以获得梯度值,更新模型的权重参数[6]。一个批次的数据经过一次前向和后向传播过程就完成了一次迭代,一个epoch就是使用训练集中的全部样本训练一次。整个训练过程要执行多个epoch,直到模型收敛[7]。DNN的训练过程非常耗时,需要数天或数周才能完成大规模的训练任务,因此需要对DNN网络进行并行训练以加快训练过程,当前最常用的并行化方法为数据并行和模型并行。
数据并行:在数据并行中,每个计算设备都拥有模型的完整副本,每个设备处理不同的训练数据集,如图1所示。 每个设备都会计算自己的梯度,这些梯度通过求和在参数计算节点聚合,然后将聚合的梯度广播到所有设备,以更新权重。因为需要同步在各个设备处更新的权重,设备间通信开销对数据并行的影响很大。为了降低参数节点的通信压力,研究人员提出了Ring-allreduce架构,各个设备都是计算节点,并且形成一个环,如图2所示,没有中心节点来聚合所有计算节点计算的梯度。在一个迭代过程中,每个计算节点完成自己的最小批次训练,计算出梯度,并将梯度传递给环中的下一个计算节点,同时它也接收来自上一个计算节点的梯度。Ring-allreduce的参数更新模式要求各计算设备具有一致的硬件架构和计算能力,虽然在一定程度降低了通信开销对数据并行的影响,但是其具有单一性,不能综合利用计算平台上各种高效能AI加速设备,为基于混合架构的网络模型数据并行训练带来了局限性。
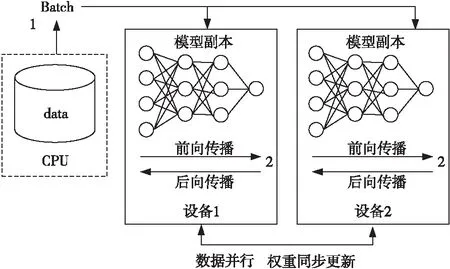
Figure 1 Data parallel training method 图1 数据并行训练方法

Figure 2 Hardware architecture of Ring-allreduce 图2 Ring-allreduce硬件架构
模型并行:模型并行[8]在多个设备之间划分模型,其中每个设备负责指定模型层的权重更新,如图3所示。 前向计算的层输出和后向计算的梯度等中间数据在计算设备之间传输,设备之间传递的数据明显少于数据并行方式,因此对于单个计算设备内存无法容纳的大模型来说,模型并行是一个很好的选择。为了使模型并行训练能够充分利用多设备计算平台上的计算资源,需要解决一些挑战,首先,由于模型划分具有依赖性,在模型并行的简单实现中,一次只有一个GPU是活动的,导致计算资源的利用严重不足。为了实现并行,PipeDream[8]通过同时向模型注入多个批次来实现流水线操作,每个GPU可以同时处理不同的批次。Chen等[7]针对PipeDream方法提出权重预测技术SpecTrain,来解决流水线操作引入的权重过时问题。第2个挑战是负载平衡。数据并行在多个GPU之间划分训练数据,因此可以轻松维护负载平衡。至于模型并行,由于不同DNN层的复杂性各不相同,划分算法不仅需要考虑每个设备的计算能力,还要考虑跨设备的通信数据量,并根据以上因素为不同计算设备分配相应的总工作量,因此如何精准高效地将训练任务分配到不同计算设备需要开发人员付出巨大努力。

Figure 3 Model parallel training method 图3 模型并行训练方法
2.2 AI加速器
现有的大部分DNN 网络的训练过程是基于CPU+GPU集群的传统分布式异构计算架构实现的,其存在能耗过高、扩展性较差、计算资源利用不足等问题。 为了实现高性能和高能效,学术界和工业界都对DNN的硬件加速进行了深入研究,使用低能耗高性能的FPGA和专用处理器ASIC芯片等新型AI加速器对传统CPU+GPU的计算架构进行加速,已经成为混合异构分布式计算领域的发展重点[9]。
2016年,谷歌I/O开发者大会上,谷歌正式发布了首代TPU(Tensor Processing Unit)[10],这是一款专门针对TensorFlow开发的芯片,至今已发布到第3代。近期,Google 推出了可在Google 云平台上使用的Cloud TPU,谷歌还有专用于AI边缘计算的ASIC Edge TPU,它以较小的物理和电源占用空间提供了高性能,从而可以在边缘部署高精度AI。2017年8月,微软宣布推出一套基于FPGA的超低延迟云端深度学习系统Brainwave,以具有竞争力的成本以及业界最低的延时进行实时AI计算,Brainwave旨在加速实时AI计算的硬件体系结构。Eyeriss[11,12]是一种具有代表性的设计,它采用空间数据流在处理引擎(PE)之间共享数据。 为了充分利用内存处理的优势,Neurocube[13]使用编程数据包方案,在混合存储的多维数据集(HMC)中部署PE。Flexflow[14]是一种具有拼贴优化的脉动体系结构。 MAESTRO[15]探索了5种用于DNN加速器的细粒度片上数据流。为了充分利用各种AI加速器的硬件资源,研究人员需要尝试基于各种具有不同硬件架构、不同计算能力的AI加速器进行DNN网络模型训练。
3 全自动的模型拆分策略生成方法
DNN网络目前主要采用计算图[16,17]来表示,不同的DNN网络的复杂性各不相同。为了充分利用AI加速器硬件资源,研究人员需要在集合了多种不同算力、不同硬件架构AI加速器的计算平台上进行神经网络模型训练。为了将计算图中的计算任务映射到多个并行计算的AI加速设备上,并且实现训练任务在多种加速器上的负载均衡,本文提出了全自动的模型拆分策略生成方法,该方法主要包括2部分,如图4所示。首先需要对计算图中的DNN网络算子构建性能模型,本文构建等同于DNN计算图的前向网络,用于统计每个算子的参数信息(包括卷积核大小、输入输出图像大小等),从而得到每个算子的理论数据通信量和理论计算量。考虑硬件加速设备对训练过程的影响,根据每个AI加速设备的理论算力,求解性能模型,得出每个算子在并行计算设备上应该分配的理论计算量。然后结合DNN网络算子理论计算量和通信量对训练性能的影响,设计合理有效的负载均衡策略,通过负载均衡策略中任务调度算法得到深度神经网络模型的最终划分策略。最后将划分策略作为构建计算图的参数传入到训练脚本中,根据得到的模型划分策略将计算图中的计算任务映射到不同架构的AI加速设备上。模型拆分策略生成的整个过程集成在DNN网络模型训练脚本中,无需人工干预,即可自动完成从性能模型构建到模型设备映射、启动训练的整个过程。

Figure 4 Schematic diagram of the fully automatic model splitting strategy generation method图4 全自动的模型拆分策略生成方法模块示意图
本文使用粗体大写字母表示向量,表1对本节所用到的符号进行了说明。

Table 1 Commonly used notations表1 常用符号说明
3.1 DNN网络算子性能模型构建
随着AI加速器的快速发展,研究人员需要尝试基于各种AI加速器进行神经网络训练,因此会出现一个模型在训练时同时用到单机服务器上多种AI加速器设备的情况。当前网络模型并行化主要针对已设计好的神经网络结构采用手工划分网络并将其映射到不同的计算设备上,而对于集成了多种AI加速设备的单机计算平台,手工划分网络不具有兼容多种设备的通用性,还会由于对训练任务在不同AI设备上运行时间的估计不够精准,容易导致计算节点上的负载不均衡。针对以上问题,本文构建了DNN网络算子的性能模型。计算量和通信量大小是影响DNN网络训练性能的主要因素,本文构建的性能模型主要负责在构建前向网络的过程中收集网络算子的参数信息,统计网络算子的理论计算量、通信量以及总的算子数量。然后根据提供的单机服务器上现有的AI设备类型、设备理论算力等信息,给出在仅考虑计算量对性能影响的情况下,为了保证负载均衡,每个设备上应该分配的理论计算量。
假设,当前服务器上的AI加速设备数量为M,设备列表为D={d1,d2,…,dM},每个设备的理论算力列表为C={c1,c2,…,cM}。该DNN计算图中的算子数为N,性能模型前期统计出来的,每个算子的理论计算量列表为F={f1,f2,…,fN},则整个计算图总的理论计算量为:
(1)
flopsdi={Flopstotal/θ}*(ci/c1)
(2)
因此,最后性能模型输出AI设备的理论计算量列表FLOPSdevice={flopsd1,flopsd2,…,flopsdM}。
3.2 任务负载均衡

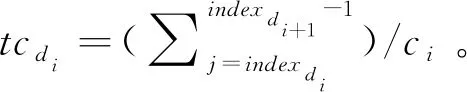
tdi=tcdi+tsdi=
(3)
对于每一种分配策略,本文利用式(3)计算设备的执行时间,为了保证所有设备在训练任务上的负载均衡,又兼顾整体训练性能,本文设计了简单高效的拆分策略对比算法,用于衡量对比选取较优的拆分结果,其实现如算法1所示。
算法1拆分策略对比算法split_compare()
输入:2种拆分结果:SPLIT_RES1和SPLIT_RES2,及其设备执行时间列表T1和T2;设置阈值:τ。
计算T1的均值avg1和标准差ε1;T2的均值avg2和标准差ε2;
if(|ε1-ε2|<τ)
ifavg1≤avg2,则选取T1,返回T1和SPLIT_RES1;
ifavg1>avg2,则选取T2,返回T2和SPLIT_RES2;
else:
if(ε1<ε2-τ),则选取T1,返回T1和SPLIT_RES1;
if(ε2<ε1-τ),则选取T2,返回T2和SPLIT_RES2;
负载均衡策略实现主要分为2个阶段。第1阶段根据理论计算量列表,采用基于理论算力的拆分算法2对计算图的算子进行初步拆分,输出一个基于算力的拆分结果。第2阶段针对阶段1的拆分结果采用基于最大值的微调算法(算法3)对拆分结果进行微调,最后给出最终的拆分结果。
算法2基于理论算力的拆分算法split_computingbased()
输入:每个设备的理论计算量列表FLOPSdevice。
输出:拆分列表SPLIT_RES。
初始化:SPLIT_RES中indexd1=0;
fordiinD:
layer_start=indexdi;
初始化当前设备的实际计算量real_flopsdi=0;
forjinrange(layer_star,N)
real_flopsdi=real_flopsdi+fj;
real_flops_nextdi=real_flopsdi+fj+1;
如果real_flopsdi
indexdi+1=j+1;
j=N;//退出内部循环。
得出一种拆分方案,将临界层算子划入下一个计算设备:SPLIT_RES1;
fordiinD:
layer_start=indexdi;
初始化当前设备的实际计算量real_flopsdi=0;
forjinrange(layer_star,N)
real_flopsdi=real_flopsdi+fj;
real_flops_nextdi=real_flopsdi+fj+1;
如果real_flopsdi
indexdi+1=j+2;
j=N;//退出内部循环。
得出一种拆分方案,将临界层算子j+1划入当前计算设备:SPLIT_RES2;
利用式(3)计算上述2种分配策略下的设备的执行时间T1和T2;
调用拆分对比算法1:
SPLIT_RES,T=split_compare(SPLIT_RES1,SPLIT_RES2,T1,T2);
ReturnSPLIT_RES,T。
根据DNN网络算子的理论计算量统计分析,相邻DNN网络算子的计算量可能会相差较大,因此在基于算力的拆分算法2中,(1)依次对网络层算子的理论计算量进行累加求和,当累加到某一层使得当前计算设备总的计算量大于其应分配的理论计算量时,停止累加,并将该临界层算子划分到下一个计算设备,满足当前设备的实际总的计算量小于其应该分配的理论计算量;(2)依次对网络层算子的理论计算量进行累加求和,当累加到某一层使得当前计算设备总的计算量大于其应分配的理论计算量时,停止累加,并将该临界层算子划分到当前计算设备,该临界层的下一层网络算子划分到下一个计算设备,满足当前设备的实际总的计算量大于其应该分配的理论计算量。然后通过对比算法1选取较优的方案作为返回值。
在DNN网络模型并行训练时,影响性能的通信时间主要为跨设备的数据传输时间,网络算子的通信时间由其通信量和PCIE带宽决定,每个设备考虑通信时间后对算法2的分配结果影响不是很大,因此本文采用基于最大值的微调算法3,对算法2的分配结果进行微调。微调算法3每次查找设备实际执行时间列表中运行时间最长的设备,然后调整该设备的起始计算位置以减少其计算的算子数。为了增加微调算法的稳定性,微调算法采用下调2次起始位置的方法,并通过对比算法选出最优的分配方案,直到分配方案不再发生变化。
算法3基于最大值的微调算法finetuning_maximum()
输入:SPLIT_RES_before,T_before=split_computingbased()。
输出:拆分列表SPLIT_RES。
设置最大迭代次数:MAX_STEP;
foriin (0,MAX_STEP):
max(T_before),记录最大值的设备max_index;
SPLIT_RES1:将最大值设备的起始位置下移一个算子;
SPLIT_RES2:将最大值设备的起始位置下移2个算子;
SPLIT_RES_now,T_now=split_compare(SPLIT_RES1,SPLIT_RES_before,T_before);
SPLIT_RESSPLIT_RES,T=split_compare(SPLIT_RES_now,SPLIT_RES2,T_now,T2);
SPLIT_RES_before,T_before=SPLIT_RES,T;
ifSPLIT_RES_before,T_before连续不再变化,退出循环;
ReturnSPLIT_RES,T。
3.3 模型拆分策略算法优化
DNN网络模型在训练时同时用到单机服务器上多种AI加速器设备,不同AI设备之间需要进行数据传输,其传输方式不尽相同,如图5所示。

Figure 5 Data transfer between AI accelerators图5 AI加速器间数据传输
GPU-GPU 之间可以通过PCIE接口之间通信传输,GPU-FPGA之间需要借助中间CPU设备完成数据传输,其相当于进行了2次数据传输,传输数据量增大为原来的2倍。为了兼容不同设备间的数据传输,本文在计算数据通信时间时引入设备的数据传输参数列表γ,对前期的通信时间进行优化。设定设备传输参数列表为γ={γ1,γ2,…,γM},其中,γi为设备di的数据传输参数,优化设备的通信时间:tsdi=γi*(sindexdi/B),而且设备传输参数列表γ={γ1,γ2,…,γm}也可以根据实际数据传输量进行调整,以更接近实际传输时间。以图5b所示为例,在GPU+FPGA的硬件架构中,GPU与FPGA之间的数据传输参数为2.0,因此其传输列表为γ={1.0,2.0}。
4 实验
面向模型并行训练的模型拆分策略自动生成方法主要为DNN网络在集合了多种不同算力、不同硬件架构AI加速器的计算平台上进行模型并行训练提供模型拆分策略。针对以上应用场景,本文基于TensorFlow2.0深度学习框架,选取ResNet网络进行模型并行训练,来验证全自动的模型拆分策略生成方法的性能,实验中生成的模型拆分策略基于集成了多个AI加速设备的单机服务器实现。
4.1 实验环境搭建
TensorFlow2.0开源框架原生支持CPU和GPU设备,本文选用可编程逻辑器件FPGA作为其他架构的加速设备模拟AI芯片。为了能够实现DNN网络模型在除GPU外的其他设备上的模型并行训练,首先需要对TensorFlow源码注册FPGA设备,添加其对FPGA的设备支持;然后利用FPGA加速器支持的高级编程语言OpenCL对DNN网络中常用算子卷积、最大池化、全连接和矩阵乘法等的前向传播和后向传播过程进行并行优化实现,并在TensorFlow源码中注册为FPGA设备,使得FPGA能够支持DNN网络常用算子的前向和反向传播计算。实验环境如下所示:CPU:2路Intel(R)Xeon(R) CPU E5-2690 v3 @ 2.60 GHz(每个CPU包含12个物理core,24个thread cores);FPGA:Inspur F10S板卡x1;GPU:NVIDIA Tesla V100 x1;RAM:629 GB;OS:CentOS Linux release 7.6.1810 (Core);Kernel version:3.10.0-514.el7.x86_64;输入图像:ImageNet2012。
4.2 实验结果分析
本节首先测试了在拥有GPU+GPU+FPGA 3种AI加速器的计算平台上,对于不同模型大小的ResNet网络,使用该自动生成方法自动生成模型拆分策略所需时间与研发人员通过手工划分网络模型生成模型拆分策略的方式所需时间进行对比,实验结果如表2所示。

Table 2 Comparison of time between automatic generation method and manual division method表2 自动生成方法与手工拆分方法耗时对比
通过实验结果可知,与人工拆分相比,自动生成模型拆分策略的方法能够大幅提升生成模型拆分策略的时效性,在节省研发人员人工成本的同时,降低了人为因素带来的拆分误差。且随着网络模型规模增大以及计算平台上AI加速器数量和种类的增加,手动拆分网络模型时研发人员需要考虑和尝试的选择性越多,拆分策略生成就会更慢,自动生成方法带来的快速、准确性的优势更加显著。
然后,本节基于ResNet-101网络模型,利用自动生成方法分别生成了使用GPU+FPGA 2个加速设备和GPU+GPU+FPGA 3个加速设备进行模型并行训练时的模型拆分策略,并根据生成的拆分策略进行理论的设备执行总时间计算,最后与手动拆分时的理论分配时间进行对比,其性能结果分别如图6和图7所示。

Figure 6 Training performance comparison of AI devices under different splitting strategies图6 不同拆分策略下AI设备的训练性能对比

Figure 7 Load balancing performance comparison of AI devices under different split strategies图7 不同拆分策略下AI设备的负载均衡性能对比
由于GPU与FPGA需要通过CPU进行数据传输,因此本实验设定GPU+FPGA时设备传输参数列表为:γ={1.0,2.0},GPU+GPU+FPGA时γ={1.0,1.0,2.0},采用某种拆分策略时,设备执行时间的标准差衡量训练任务在AI设备间的负载均衡性。实验结果表明,采用自动生成的模型拆分策略,AI设备在训练时总的执行时间与结合理论数据进行手动划分的拆分策略结果基本一致,但是设备任务的负载均衡性优于手动生成的拆分策略,这说明本文自动生成的拆分策略能够高效利用单个计算平台上的不同计算资源,且能保证模型训练任务在各设备之间的负载均衡。
负载均衡策略实现的算法1设定了方差阈值参数τ,阈值参数τ的不同将较大程度影响到最终分配结果,因此本节对比了不同阈值参数对拆分策略结果的影响,其实验结果分别如图8和图9所示。
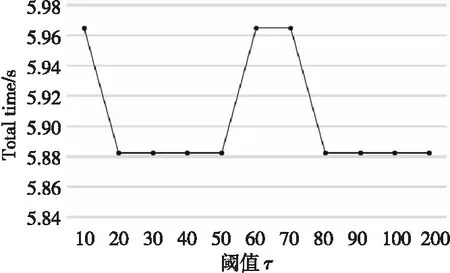
Figure 8 Effect of different threshold parameters τ on the training performance of AI devices in the results of the split strategy图8 不同阈值参数τ对拆分策略结果中 AI设备训练性能的影响

Figure 9 Effect of different threshold parameters τ on the load balancing performance of AI devices in the results of the split strategy图9 不同阈值参数τ对拆分策略结果中 AI设备负载均衡性能的影响
实验结果表明,在拆分对比算法1中设计合理的阈值参数τ,将直接影响拆分结果。理论上τ的值越小越能保证设备间的任务负载均衡,在τ为60,70等较大值时也到达了负载均衡的局部最优解,但其对应训练的整体性能较差。训练过程中在保证负载均衡时,也要兼顾整体的训练性能,因此在ResNet-101的训练中,本节选择τ=20,其负载均衡性能接近于最优解,也保证了网络的整体训练性能。
利用自动生成的模型策略完成ResNet-101网络在GPU+FPGA 2个加速设备上的映射后,模型训练的实际性能,如图10所示。实验结果显示,实际训练性能远低于自动生成策略时的理论分析性能,这是因为在实验中,本文采用FPGA模拟AI芯片,只限于功能验证实现,FPGA加速器上实际运行的卷积、全连接等算子由OpenCL高级编程语言实现,但并未进行核心代码的充分并行优化,使得FPGA上运行的算子的实际计算性能远低于其理论计算性能。将FPGA换为AI芯片后,由于AI芯片具有针对算子设计的特定结构,其在实际计算能力以及通信带宽上将优于FPGA的性能。该实验结果也表明本文提出的模型自动拆分策略具有较高的通用性和灵活性,能够应用到包含不同架构和不同计算能力的AI加速设备上。

Figure 10 Comparison of theoretical analysis and actual training performance图10 理论分析与实际训练性能对比
5 结束语
本文基于DNN网络的理论计算量、通信量以及AI加速器的理论算力等提出了一个面向模型并行训练的模型拆分策略自动生成方法,该方法主要包括网络算子性能模型构建和训练任务负载均衡2部分。网络算子性能模型构建负责收集网络算子的参数信息,统计网络算子的理论计算量、通信量以及总的算子数量,并根据AI加速器的理论算力给出每个设备应该分配的理论计算量;训练任务负载均衡部分通过对比算法和微调算法对网络算子进行任务调度,以保证训练任务在多个AI加速器上的负载均衡。该自动生成方法能够高效利用单个计算平台上的所有计算资源,并保证模型训练任务在各设备之间的负载均衡,与目前使用人工拆分策略相比节省了研发人员的人工成本,具有更高的时效性,降低了由于人为因素带来的不确定性。
