一种高效的压缩Page Walk Cache结构*
2020-10-10贾朝阳张敦博
贾朝阳,张敦博,王 琼,沈 立
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
通用图形处理单元(GPGPU)已被广泛应用于当前的异构高性能计算系统中,加速应用程序中的计算密集型任务。如何减少GPU与CPU之间传递数据的开销,始终是研究者关注的焦点。按照之前的编程模型,GPU与CPU之间显式地交换数据,不仅增加了编程复杂度,还需要程序员合理地安排计算和通信,以尽量隐藏通信延迟。当前主流的解决方案是GPU和CPU采用统一的虚拟地址空间[1],将数据传输工作交给运行时系统自动管理,以降低编程的复杂性[2]。然而,在GPU和CPU构成的异构系统中引入统一虚拟地址空间又会带来新的问题,即可能引入较大的虚实地址转换开销[3 - 5]。由于GPU采用单指令多线程SIMT(Single Instruction Multiple Thread)执行模型,每次访存都会并发大量地址转换请求,导致快表TLB(Translation Lookaside Buffers)命中率比较低。以基准程序2mm为例,32项TLB的命中率是0.81%,64项TLB的命中率是1.54%。对于不规则应用,这一问题将更加严重。过低的TLB命中率势必导致大量页表访问,大大增加虚实地址转换的实际开销。因此,虚实地址转换已经成为GPU一个重要的性能瓶颈[6,7]。虚拟地址按位从高到低依次由L4索引、L3索引、L2索引、L1索引和偏移位组成,对于出现的这些问题,现有解决方案主要有3种:提高TLB命中率、优化IOMMU(Input Output Memory Management Unit) buffer中请求的调度策略,以及提高页表遍历缓存PWC(Page Walk Cache)命中率。
提高TLB命中率是最直接的一种方法[8,9]。Pham等人[10]提出的方案采用多粒度TLB结构,将TLB拆分为粗粒度和细粒度2部分。粗粒度部分覆盖了更多的地址空间,可以有效提高命中率,用来执行虚实地址转换操作;细粒度部分负责CPU和GPU之间的数据传输,由于细粒度页面减少了无用数据的传输,大大提高了总线带宽利用率。不过,这种方案需要对TLB结构进行较大改动,导致硬件成本大幅增加。
优化IOMMU buffer中请求的调度策略是另一种解决思路。GPU中没有命中TLB的请求将被送入主机的IOMMU buffer中排队,等待页表遍历部件PTW(Page Table Walker)空闲,以访问内存中多级页表,完成地址转换。因此,可以通过调度这些请求的响应次序,缩短它们在IOMMU buffer中的平均等待时间,以减少地址转换开销。Shin等人[11]提出了一种buffer中请求重排序机制,优先响应某个warp中的所有请求,这个warp中所有线程的地址转换开销之和最小。当buffer中来自这个warp的所有请求都被响应之后,再去响应来自其余warp的请求。经过排序,开销小的warp中请求的平均等待时间大大缩短,而其余warp请求的平均等待时间几乎不变。虽然这种调度策略可以降低请求的排队延迟,但是不能减少它们的实际访存次数,所以该策略并没有从根本上解决问题。
提高PWC的命中率也可以减少访问页表的次数[12]。PWC中记录了之前被访问过的页表项,如果访问PWC命中,就无需再去访问高级别的页表。当访问高级页表时,多个虚拟地址的高级索引会落在同一个页表项中,这表明这些虚拟地址的高级索引是相同的。当访问低级页表时(如一级页表),多个虚拟地址的低级索引会落在多个不同的低级页表中,上述情况导致PWC中存在很多冗余信息,尤以虚拟地址L4和L3索引的冗余情况最为严重。Intel公司的STC(Split Translation Cache)结构[13],将L4~L2索引分为3个独立存储体,以实现3级索引并行查找,但是依然存在较多的信息冗余。为了消除冗余信息,AMD采用UPTC(Unified Page Table Cache)结构[13],按照虚拟地址的高3级索引将PWC分为3个独立的存储器,并以页表起始地址作为索引进行查找。这样虽然消除了冗余,但不能对3级索引执行并行查找操作,增加了PWC的命中时间。当前主流的PWC结构是TPC(Translation-Path Cache)[13],TPC将L4~L2索引作为一个整体,可以实现PWC的3级索引并行查找。但是,这种结构中存在大量的冗余信息,冗余信息一般占据所有信息的45.8%~66.6%。
本文着重研究如何消除PWC中的冗余信息,使得相同容量的PWC能够保存更多的页表项,从而减少查找页表的实际次数。本文首先分析了典型GPU基准测试集虚拟地址流的特征,发现在这些测试程序的生命周期中,所有虚拟地址的L4索引基本不会改变;L3索引改变很少,不超过4种取值;L2索引的变化相比L4、L3级索引要多很多,而L1索引的变化更多,基本没有局部性可以利用。基于上述观察,本文提出了一种压缩的PWC结构,称为CPWC(Compressed Page Walk Cache)。CPWC采用树形结构,可以消除传统PWC中的全部冗余,同时保持查找开销不变。实验表明,与TPC相比,CPWC可以减少25.4%的访存。
2 CPWC的结构
减少GPU虚实地址转换开销的3个方案中,提高TLB命中率需要修改TLB结构或改变操作系统页表生成策略,改变地址转换流程,改动范围大,开销大;虽然优化IOMMU buffer的调度策略可以有效改善请求在buffer中的平均等待时间,但是却没有从根本上解决地址转换开销过大的问题;提高PWC命中率会引入额外的冗余信息,由于存储空间限制,传统PWC的命中率并不是特别理想。因此,本文从消除PWC中的冗余信息入手,首先分析了GPU执行过程中虚拟地址序列的特征。在此基础上,本文提出CPWC结构来消除冗余信息,提高PWC的命中率,减少TLB失效时访问页表的次数,提高虚实地址转换的效率。
2.1 虚拟地址分析
本文采用GPGPU-Sim[14]模拟器,使用GTX 480 GPU架构进行模拟。模拟器采用默认硬件配置,通过配置选项输出测试程序执行过程中的虚拟地址流,并分析这些地址流的特征[15]。本文从Rodinia 3.1(dwt2d、pathfinder、streamcluster、backprop、hotspot、b+tree)[16]、Polybench GPU-1.0(gramschmidt、2mm、3mm、2DC、3DC、gemm)[17]和ISPASS 2009(AES、BFS、STO、RAY、MUM)基准程序包中随机选择了17个基准程序进行分析。在本文统计的基准程序的整个生命周期中,不同L4、L3和L2级索引出现的频度不同,表1列出了统计结果。

Table 1 Statistical results of virtual address characteristics表1 虚拟地址特征统计结果
根据表1中虚拟地址特征的统计结果,本文将这些基准程序分为3类:
第Ⅰ类:原始PWC即可获得很好的命中率。由于这些基准程序中虚拟地址的高3级索引局部性很强,PWC在有限条目的情况下即可获得接近100%的命中率。这类程序一般是规则的GPU应用。
第Ⅱ类:需要大幅增加PWC容量才能获得理想的命中率。这类基准程序的虚拟地址特征也很明确,L4、L3级索引的局部性仍然很好,但是L2级索引的局部性很差,不同L2级索引的数目超过150个。由于L2级索引的局部性较差,需要很大容量(分布情况最差的程序STO至少需要300项的PWC,需占空间66 000 bit)的PWC才能获得接近100%的命中率。要在此类基准程序中获得良好的PWC命中率势必导致硬件开销大大增加。
第Ⅲ类:这类基准程序的L4、L3级索引局部性和前面2类一样,但是L2级索引的局部性介于第Ⅰ类和第Ⅱ类之间。这类基准程序的PWC命中率随PWC容量的增加表现出明显的提升,因此只需要增加少量PWC存储开销即可获得接近100%的命中率。
综上所述,这3类基准程序的虚拟地址中L4和L3级索引的局部性都很好,不同的局部性体现在L2级索引上。本文通过本次实验得出2个结论:
(1) 传统PWC中高度冗余的信息是由L4和L3级索引导致的。3类基准程序的虚拟地址中高2级索引的变化很少,每次存储L2级索引时都重复存储L4和L3级索引,导致信息冗余。
(2) 传统PWC的命中率由L2级索引的局部性决定。如果虚地址中L2级索引的局部性差(例如表1中的STO基准程序,不同的L2级索引数目达到了409个),为了达到理想命中率,需要增加很多PWC存储开销。
本文通过消除PWC中相同的L4和L3级索引来消除冗余信息,并采用映射方式保持现有的3级索引并行查找过程不变。这样既消除了PWC中的冗余,又可以保证PWC查找开销不变,还可以将之前存储冗余信息的空间用来缓存新PWC条目,从而在存储开销相同的条件下增加PWC命中率,减少地址转换开销。
2.2 CPWC结构
根据2.1节的统计结果,本文采用树形结构存储PWC中的条目,以消除冗余信息。由于TPC结构实现了3级索引并行查找,采用树形结构的一个挑战是如何维持3级索引的并行查找过程。为此,本文将PWC按照3级索引分成3个独立的存储体:L4 PWC、L3 PWC和L2 PWC,每部分分别缓存虚拟地址的L4、L3和L2级索引及其对应的页表起始地址PBA(Page Base Address)。
本节以1个拥有2项L4索引、4项L3索引、32项L2索引和1个多路选择器的CPWC为例进行介绍,其中L2 PWC分为4个PWC块,每个块包含8个条目,其具体结构如图1所示。L4 PWC中每个条目缓存虚地址的L4索引(L4 Tag)和对应的L3级页表起始地址(L3 PBA)。L3 PWC每个条目缓存虚地址的L3索引和L2级页表起始地址,X位的Mask部分是1个位向量,用来指示当前L3条目对应哪些L2 PWC 块。L2 PWC由多个PWC 块和1个多路选择器构成,每个PWC块中的条目缓存虚地址的L2索引和L1级页表起始地址,多路选择器使用L3条目中的Mask向量从所有L2 PWC块的匹配结果中筛选正确结果。本文在L4 PWC和L3 PWC中采用直接映射方式,L2 PWC的每个PWC块内采用全相联映射。

Figure 1 Structure of CPWC图1 CPWC的结构
2.3 CPWC地址映射方式与查找方式
CPWC各部分的项数决定了它们的映射方式,在本文中,CPWC各部分的映射方式如表2所示。CPWC的映射方式也决定了它的查找方式。如图1中的CPWC结构,由于L4 PWC中只有2项,所以采用直接映射并以L4索引的最低位作为L4标识。同理,L3 PWC只有4项,采用直接映射并将L4索引的最低位与L3索引的最低位拼接起来,形成2位的L3标识。L2 PWC 分为4块,每块的内部采用全相联映射,整个L2 PWC使用4路选择器选择最终结果。下面介绍CPWC如何实现并行查找:当一个虚拟地址查找CPWC时,将虚拟地址分成L4索引、L3索引和L2索引3部分。

Table 2 CPWC configuration parameters 表2 CPWC配置参数
第1步,分别在L4、L3、L2 PWC中查找,请注意这3个查找是并行的:使用L4标识查找L4 PWC,同时使用L3标识查找L3 PWC,同时并行查找L2 PWC中所有PWC块,将L2 PWC块的命中结果输入多路选择器,作为备选输出。
第2步,将L3中命中条目的Mask字段输入多路选择器作为选择依据(Mask哪一位为1则输出对应的PBA),选择多个L2 PWC块查找结果中正确的结果,完成PWC查找过程。
保存L4、L3和L2的3个PWC有不同的命中结果处理策略。若L4 PWC失效,则整个CPWC失效,需要访问4次页表;若L4 PWC命中且L3 PWC失效,则L2 PWC也失效,得到了L3级页表起始地址,从L3级页表开始访问3次页表;若L4 PWC和L3 PWC命中且所有L2 PWC块都未命中,多路选择器没有输出,则L2 PWC失效。得到了L2级页表起始地址,从L2级页表开始访问2次页表;L4、L3 PWC均命中且多路选择器有输出结果,此时L2 PWC命中,得到了L1级页表起始地址,只需要访问1次页表。
2.4 CPWC的访问过程
本节以3个虚拟地址0x7F72B010F1F0、0x7F72BC30F1F0和0x7FF2FC30F1F0为例,描述CPWC的访问过程。假设它们先后到达CPWC,3个虚拟地址的L4级、L3级和L2级索引如表3所示。

Table 3 L4,L3,and L2 indexes of virtual addresses表3 虚拟地址的L4级、L3级和L2级索引

Figure 2 CPWC structure after three virtual addresses are written图2 3个虚地址写入后的CPWC结构
第1条虚拟地址到来时CPWC为空,需要查询4次页表获得物理地址信息完成地址转换,然后将虚拟地址的高3级索引和对应的页表起始地址分别存储在L4 PWC、L3 PWC的第1个条目和L2 PWC第1个块的第1项,并将L3中对应项的Mask字段置为0b1000。第2条虚拟地址到来时,并行查找L4、L3和L2 PWC。发现L4 PWC、L3 PWC都命中第1项。因为所有L2 PWC块都未命中,所以将Mask信息输入多路选择器后发现没有输出,此时CPWC中L3 PWC命中,PTW执行2次访存,并将完成访存后的L2索引和L1级页表起始地址存储在L2 PWC第1个块的第2项。第3条虚拟地址到来时,发现L4~L2 PWC都未命中,完成地址转换后将虚拟地址的L4索引填入L4 PWC的第2项,并根据L3标识(值为0b11)将L3索引填入L3 PWC的第4项。L2索引填入L2 PWC第2个块的第1项,将L3中对应的Mask字段的值置为0b0100。这3个请求都响应后的CPWC如图2所示。
2.5 CPWC优势分析
与传统PWC相比,CPWC减少了缓存L4与L3级索引的空间。根据2.1节中虚拟地址各级索引分布特征的统计结果,由于L4与L3索引极强的局部性(在整个程序运行过程中,只会出现1~4个不同值),因此传统PWC中存在大量的冗余信息。CPWC采用分离式的PWC结构,将用于缓存重复L4与L3索引的空间改为缓存L1级页表起始地址的空间,这样相当于增加了PWC的整体容量。也就是说,采取CPWC的树形结构可以在相同空间开销的情况下,缓存更多的L2级页表项,从而提高PWC的命中率,减少地址转换开销。
3 性能测试与分析
本文使用GPGPU-Sim模拟器,采用GTX 480 GPU架构配置,模拟基准程序执行过程获取虚拟地址流。随后设计实现GPU-CPU地址转换模拟器对所提出的压缩PWC进行性能测试与分析。GPGPU-Sim的具体配置如表4所示。
基准程序采用第2节中分析虚拟地址特征时使用的测试集,各个基准程序的详细信息请参见第2节。为了体现CPWC相比之前结构的提升,本文进行以下3个方面的测试与分析:(1)信息冗余度与空间开销分析;(2)CPWC命中率分析;(3)地址转换开销分析。
3.1 信息冗余度与空间开销
表5和表6都展示了PWC与CPWC的容量和所能缓存的页表项数之间的关系。不同的是,表5展示了随项数的增加PWC和CPWC容量的变化;表6展示了随容量的增加PWC与CPWC能缓存的项数的变化。

Table 4 GPU configuration parameters for the experiment表4 实验用GPU配置参数

Table 5 Space occupied (bits) by PWC and CPWC with the change of entry numbers表5 PWC与CPWC的占用空间随项数的变化

Table 6 Entry number of PWC and CPWC with the change of space occupation (bits)表6 PWC与CPWC的项数随占用空间的变化
PWC中的每一项可以分成3个索引以及对应的页表起始地址,因此PWC的每一项所需要的空间开销为:1位有效位(1 bit)、3个索引(3*9 bit)、3个页表起始地址(3*64 bit),共220 bit。CPWC中每一项包含:1位标识位(1 bit)、索引(9 bit)和页表项(64 bit),其中L3 PWC每一项还需增加N位的Mask字段。基于虚拟地址各级索引的分布情况,N项的CPWC需要1个2项的L4 CPWC(2*74 bit)、1个4项的L3 CPWC(4*(74+N) bit)和1个N项的L2 CPWC(N*74 bit)。1个N项的PWC所需的空间开销为:N*220 bit,而1个N项的CPWC所需的空间为:(6+N)*74+4*Nbit。通过这2个表可以看出,CPWC通过调整结构消除了冗余信息,两者在相同项数下,随着容纳项数的增加,PWC所占用的空间接近CPWC的3倍;在相同容量的情况下,随着容量的增加,CPWC所能缓存的项数也接近PWC的3倍。
表7展示了相同容量下PWC与CPWC中冗余信息所占的比例。1个虚拟地址可以被分为1~4级的索引和偏移量。在地址转换时PTW会按照各级索引去遍历页表,由于L4、L3级索引的强局部性,导致地址转换请求多次访问同一个高级页,而传统的PWC将高3级索引作为一个整体进行处理。按照2.1节中的分析,L4与L3级索引局部性非常高,导致PWC中接近2/3的信息都是冗余的。随着PWC的容量不断增大,PWC中冗余信息所占的比例也在不断增大,并且不断逼近于66.6%,这相当于浪费了将近2/3的空间缓存重复信息。无论CPWC的容量多大,CPWC中都没有冗余信息。CPWC在相同容量的情况下可以缓存更多不同的页表项,进而提升命中率。

Table 7 Comparison of PWC and CPWC redundancy at the same capacity 表7 相同容量下PWC与CPWC冗余度对比
3.2 CPWC的命中率
图3展示了各个测试程序在相同存储开销情况下的L2索引命中率,存储开销都为5 280 bit(PWC 24项、CPWC 62项)。根据2.1节中的分析,所有程序都只出现1~3个不同的L4、L3级索引,因此L4与L3级索引的命中率都接近于100%(除了强制失效)。故本节只对L2级索引的命中率进行测试与分析。从图3中可以看出,所有程序都可以从CPWC结构中获益。其中pathfinder、3DC、2DC、hotspot、backprop、b+tree、gemm、3mm、2mm、BFS可以从CPWC中获得2倍乃至3倍的L2索引命中率提升,这是因为相同容量下CPWC所能覆盖的地址范围已经接近程序的地址分布范围,而PWC只能覆盖小部分。STO、AES、RAY、dwt2d、streamcluster、MUM的L2索引命中率提升没有上一组程序明显。从2.1节中可以发现,这些程序的地址覆盖范围相较于上一组程序来说更广泛,当前CPWC所能覆盖的地址范围仍然不能很好地满足程序的需求,因此命中率提升有限。对于gramschmidt程序来说,原本的PWC几乎覆盖了程序中所有的地址分布范围,L2级索引命中率已经接近100%,因此CPWC对此程序的提升并不明显。综上所述,在空间开销为5 280 bit的情况下,PWC的L2索引平均命中率为46.5%,CPWC的L2索引平均命中率为86.5%,平均提升了40%的PWC命中率。
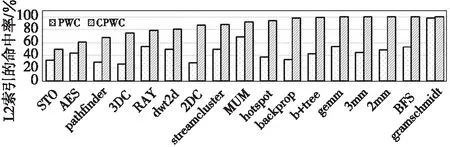
Figure 3 Hit ratio of the L2 indexes图3 L2索引的命中率
3.3 地址转换开销
表8对比了PWC与CPWC中各个测试程序地址转换所需的访问页表(访存)次数。表8中所有的访存都是由TLB失效后的地址转换请求引起的,对于不同程序CPWC所能带来的性能提升也不同。根据第2节中的分类依据,本文将gramschmidt作为第I类,将STO、AES、RAY、dwt2d、MUM作为第II类,将pathfinder、3DC、2DC、hotspot、backprop、b+tree、gemm、3mm、2mm、BFS、streamcluster作为第III类。其中第I类测试程序只减少了2.18%的访存,这是由于程序本身的L2级索引命中率就很好,地址转换性能已经接近理想性能,因此很难再获提升。第II类程序平均减少了15.11%的访存,由于这些测试程序虚拟地址分布范围已经超过了当前PWC和CPWC所能覆盖的页表范围,PWC容量失效影响了性能的提升,因此CPWC所能带来的性能提升并不明显。第III类程序平均减少了32.2%的访存,由于这些测试程序的虚拟地址分布范围超过了PWC覆盖的范围,而没有超过CPWC覆盖的地址范围,性能提升接近于L2级索引命中率的提升,不会受到容量失效的影响。

Table 8 Comparison between CPWC and PWC with the same capacity表8 同容量CPWC与PWC的对比
针对CPWC结构命中时间问题,本文做了以下实验:采用SMIC 16 nm标准CMOS工艺,在Cadence软件中完成了64项直接映射PWC和64项CPWC的设计,并测试了两者的命中时间。实验结果表明,直接映射PWC和CPWC的命中时间分别为147 ps和154 ps。因此,全相联的L2 PWC块对地址转换性能几乎没有影响。
综上所述,相比于PWC,CPWC能减少25.4%的访存。
4 结束语
GPU的多线程执行模型会同时发出多个虚实地址转换请求,使得TLB的未命中率逐渐增加,虚实地址转换的开销也随之增加。因此,用于减少TLB失效后访存次数的PWC将发挥越来越重要的作用。传统的PWC有一些不足,如容量有限和信息冗余,使它无法有效地减少实际页表访问次数。本文提出了一种新的PWC结构,称为CPWC。CPWC以树形结构组织页表条目,完全消除了冗余的L4级和L3级索引,同时保持了3级索引并行查找。实验结果表明,CPWC增加了PWC可缓存的页表项数,平均减少了25.4%的页表访问次数,有效地减少了虚实地址转换开销。
