基于卷积神经网络的道路图像语义分割∗
2020-10-09赵昆淇
张 蓉 赵昆淇 顾 凯
(江苏科技大学电子信息学院 镇江 212000)
1 引言
图像语义分割是在图像分割的基础上对分割出来的物体进行语义标注。图像语义分割是图像理解和图像识别的基石性技术,对后续图像处理的结果有很大的影响。因此,基于卷积神经网络的道路图像语义分割对于可以有效地分割道路图片,并准确地标记分割物体的类别具有重要意义。
图像语义分割主要是通过提取图片的低级特征进行分割,分割出来的结果并没有进行语义标注,只是简单的图像分割。常用的方法如Jianbo shi 提出的“Normalized cut”图划分方法,虽然能够考虑全局信息来进行图划分,但分割的结果并不准确且不能对复杂图像进行分割。此外,微软研究院提出了一种人机交互的技术——“Grab Cut”方法,人工干预图片进行处理能得到较好的期望结果,但只能做二类语义分割。
现阶段,计算机也从人工智能时代步入了深度学习时代,因此图像语义分割也进入了全新的发展阶段。Long 等在2014 年提出了全卷积神经网络(FCN),它对深度学习在图像语义分割上有开创性的意义,沿用了AlexNet卷积网络的结构,在全连接层的地方扩大了卷积阶段和全连接层的plane size,该结构可以将图像分割成任意大小的图像,提高了处理速度,但是不能够对类别图像进行精确的调整。因此,Cambridge 在FCN 的基础上提出了Seg-Net网络,该网络采用编码——解码的网络结构,将最大池化指数转移到了编码器中,保留了池化层中的位置信息,改善了分割分辨率,提高了速度。
然而,在图像的采集与传输过程中会存在各种噪声,图像中的噪声属于无效信息,因此输入的图像也会对分割的结果产生影响。本文在使用Seg-Net 网络结构模型的基础上,采用了一种基于差异系数的稀疏度自适应图像去噪算法,弥补图像在传输和获取过程中存在的噪声问题。该算法在对图片进行去除噪声的同时尽可能地完整保留图像的有用信息,然后再利用卷积神经网络模型对图像进行语义分割,最终得到较好的分割结果。
2 卷积神经网络模型
2.1 SegNet网络模型
本文采用SegNet网络结构模型,SegNet网络结构如图1所示。其中Input为输入的原始图片,Output 为分割出的输出结果,图片中用不同的颜色代表不同的物体,同一种物体用固定的颜色表示。使用SegNet 网络进行图像语义分割的重点是它不仅可以指明图片中某个物体的属性,而且还会标注它所在的位置。SegNet 网络结构是一个对称的网络结构,以中间的池化(pooling)层和上采样(upsampling)层作为分割线。左边通过卷积的方法提取高维特征,并在提取特征的同时通过池化(pooling)使图片变小,右边是采用反卷积(在这里反卷积与卷积没有区别)与上采样(upsampling)的方法,通过反卷积使得图像分类后的特征得以重现,上采样(upsampling)使图片变大,最后将输出的值通过分类器(Softmax)进行分类,得到最终的图像分割结果。
SegNet 网络由两个对应的网络组成即一个编码(encoder)网络和一个对应的解码(decoder)网络,在俩个网络的最后在连接一个像素级的分类层,其中解码网络与VGG16 的13 层卷积层相同。解码网络的主要作用是将通过编码网络得到的低分辨率的编码特征图映射到全分辨率的编码特征图中,提高特征图的分辨率,并且使用最大池化的池化索引方法进行非线性上采样。之后将经过上采样得到的稀疏的特征图与可训练的解码滤波器相卷积,这样就能够得到致密的特征图。使用池化层索引进行上采样的优势:1)提升边缘刻画度;2)减少训练的参数;3)可以将这样的上采样模式运用到任何编码-解码网络中。
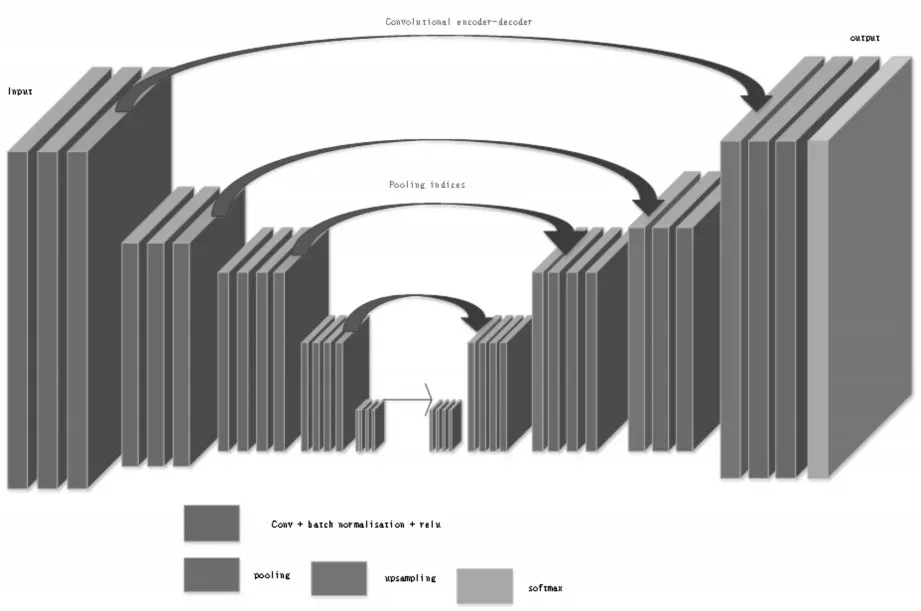
图1 SegNet网络结构图
SegNet 网络结构中卷积层与普通的卷积层不同,区别在于SegNet中的卷积层都会在后面加上一个批标准化(bn)层,作用主要是加快学习速度,批标准化(bn)层后面为ReLU 激活层,用于激活函数之前。批标准化(bn)层的作用过程可以归为
1)训练时
(1)向前传播,批标准化(bn)层对卷积后得到的特征值(权值)进行标准化处理,与此同时保持输出不变,即批标准化(bn)层仅仅是保存输入权值的均值与方差,当输出的权值回到卷积层时依旧是当初卷积后的权值,不对它进行任何改变。
(2)向后传播,结合网络结构中每一个卷积层与ReLU层对批标准化(bn)层中所保存的均值与方差进行求导得到梯度值从而可以计算出当前的学习速率。
2)测试时
每个批标准化(bn)层都需要对训练集中的所有数据进行总体均值与方差的求取。假设要将一个预测试图像经过卷积层再输入批标准化(bn)层时,首先需要对输入权值的均值与方差进行统计,然后再根据训练集中的无偏差估计准确计算出批标准化(bn)层的输出。需要注意是测试时,批标准化(bn)层已经改变了卷积的权值,因此激活层Re-LU的输入值也相应的被改变。
在SegNet 的编码(Encoder)过程中,卷积是为了提取特征。在SegNet 网络中使用到的是same 卷积,即卷积后不改变图片的大小;相应地,在解码(Decoder)过程中,同样使用same卷积,不过其中卷积的作用与编码网络中不同是为经过上采样(upsampling)处理的图像丰富其丢失的信息,即对在池化(Pooling)过程中丢失的信息可以通过不断学习在解码(Decoder)中得到。
2.2 去噪算法
本文采用一种基于差异系数的稀疏度自适应SK-SVD图像去噪算法(Sparsity Adaptive SK-SVD),该算法在稀疏训练阶段自适应计算稀疏度K,并将此K 值反馈到SK-SDV 去噪过程中。此外,还引入“差异系数”修正在选择原子列的过程中造成的假相似性。SK-SDV 去噪模型依据灰度方差值将样本块分为两部分分别进行去噪。
该算法将相似度均值作为阈值,并设置最小残差自适应的生成稀疏度K,同时引入“差异因子”作为计算相似度时的系数,用来修正假相似现象[14]。该去噪算法具有良好的自适应性,在给图像去噪的同时也能够很好地恢复图像的一些细节信息,能够很好地去除图像中的无用信息,保留有用信。因此,能够有效地提高图像的分割结果。图像去噪之后对比图如图2所示。

图2 部分去噪结果对比
3 道路图像语义分割流程
3.1 数据集标定
在训练网络模型过程中,重要的是制作自己的标签数据集。首先要选择好训练集,注意,训练集需要与预分割图片一个类型。本文用到的制作标签集工具是labelme,需要手动划分物体并进行语义标注,对图像中的各种预分割物体进行逐项素的语义标注,同时达到对图像的像素级的分割。制作的部分标签图如图3所示。

图3 部分标签图
3.2 分割流程
要有效地对图像进行语义分割重点要解决两个部分。首先要训练网络模型,在训练网络模型之前,应该先确定预分割图像的类型,然后选择大量与预分割图像类型一致的图片作为数据集,并制作相应的标签图,这样就能够进行网络模型的训练。第二是对输入图像进行预处理,本文主要是对图像进行去噪处理,采用基于差异系数的稀疏度自适应图像去噪算法有效去除图像中的噪声,减少图像损失,最后将处理过后的图像输入到训练好的网络模型中,得到输出的分割结果。整体的分割流程图如图4所示。
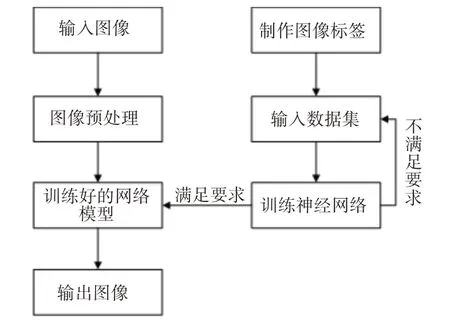
图4 整体分割流程图
4 实验结果及分析
为了对本文提出的方法进行验证,在CamVid数据集上进行测试,有12 个类别,分别为天空、建筑物、电杆、路标、道路、人行道、树木、道路符号、栅栏、自行车、汽车、行人。将这些数据分为三部分:训练集、验证集和测试集。训练集有367 张图片,测试集有233 张图片,验证集有101 张图片。首先基于训练集训练模型,然后用验证集的验证模型,最后用测试集进行测试。
4.1 实验设置
本实验系统采用ubuntu系统,SegNet网络实现工具为TensorFlow。模型的训练和测试基于以下配置环境:Tensorflow+Ubuntu16.04+Cuda8.0。+Cudnn5.0。在上述环境设置下对网络模型中的参数进行不断的调整,并一直训练网络模型直到达到预期效果。经过训练之后,网络模型的参数设置如表1所示。

表1 SegNet网络参数
4.2 评价指标
通常基于区域的评价标准是IU,通过检查Sseg和Sgt的重叠率得到其中Sseg和Sgt分别表示分割结果和真值。为了定量评价图像语义分割结果的精度,采用四种评价指标:像素精度(pixel accuracy),平均类精度(mean accuracy),平 均IU(mean IU)和 带 权IU(frequency weighted IU)。其中平均IU是最常用的评价方法。
各种评价方法的表达式如下式所示:

式中:nij表示预测第i 类属于第j 类的像素数,ncl表示不同的类别,是第i 类的总像素数。
4.3 结果分析
分别将未经过预处理的图片与经过预处理的图片输入到训练好的网络模型中,对输出的分割结果图进行比较,结果对比图如图5所示。

图5 分割对比图
仅仅从输出图片的结果难以分辨出结果的好坏,所以需要根据评价IU 的评价标准进行直接的比较,这样可以清晰直观地看出分割的差距。表2是对分割结果的评估。
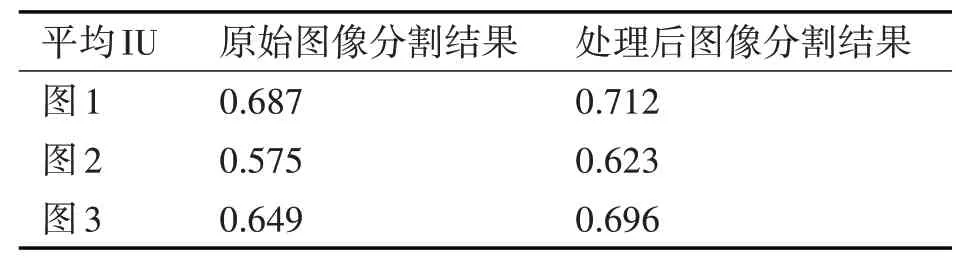
表2 分割结果评价
除了SegNet 网络可以用于道路驾驶场景的分割之外,还有FCN,Deeplab-CRF 等用于图像语义分割的模型。利用不同的网络结构模型,分别对同一组处理过的图片进行图像语义分割,对不同的网络模型的分割效果进行评估。表3 是FCN,Deeplab-CRF 等各语义分割模型在PASCAL VOC-2011 test set数据集上的结果。
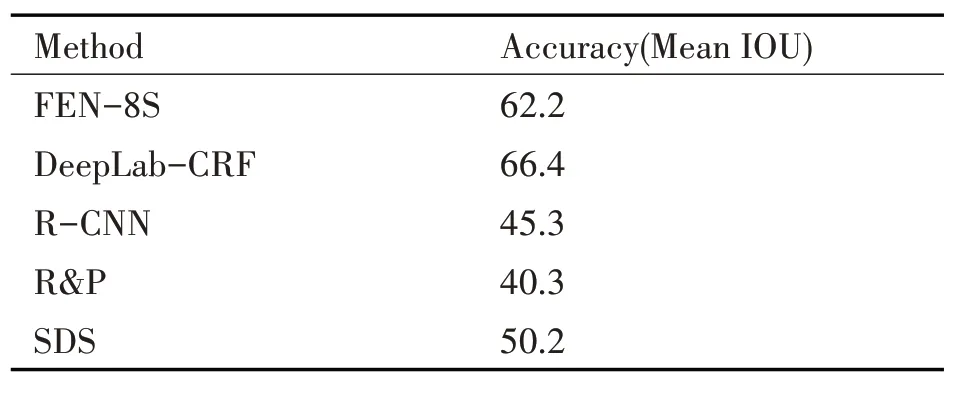
表3 网络模型结果对比
5 结语
卷积神经网络在图像语义分割领域有很好的应用,本文在SegNet网络的基础上对输入的图像进行预处理,采用了一种基于差异系数的稀疏度自适应图像去噪算法,在去除噪声的同时极大地保留有效信息。本文提出的方法既不增加网络模型的复杂程度,又能够简单高效地提高图像的分割效果。
