基于卷积神经网络的电话行为识别方法研究∗
2020-10-09张亚芹
张亚芹 刘 畅 覃 源 程 科
(1.江苏科技大学计算机学院 镇江 212003)(2.镇江明知科技有限公司 镇江 212003)
1 引言
进入21 世纪以后,人们生活水平的不断提升,尤其是物质生活水平的提升,大家越来越注重个人安全和工业安全,对人、家庭以及住所的小区的监控方面提出了更高的需求[1]。人防的保安方式难以适应人们的请求,智能监控已变成当下的主流趋势。所以目标检测成为当前计算机视觉和机器学习领域研究的热门课题。
图像目标检测算法发展史如图1 所示。从图可知,从2001年到2008年,都是用传统的方法进行目标检测,传统算法的典型代表有:Haar特征+Adaboost 算法,Hog 特征+Svm 算法和DPM 算法。在传统的方法中,目标检测算法流程为多尺度滑动窗口,对每个窗口进行特征提取,分类器分类。多尺度滑动窗口提取很多不同尺度的窗口,之后对每个窗口进行特征提取。比如多层感知机(MLP),其输入通常是一个特征向量,需要人工设计特征,然后将这些特征计算的值组成特征向量。以实践和经验来看,人工找到的特征并不是很准确,特征有时多有时少,更糟糕的是,有时选择的特征根本不起作用[2]。
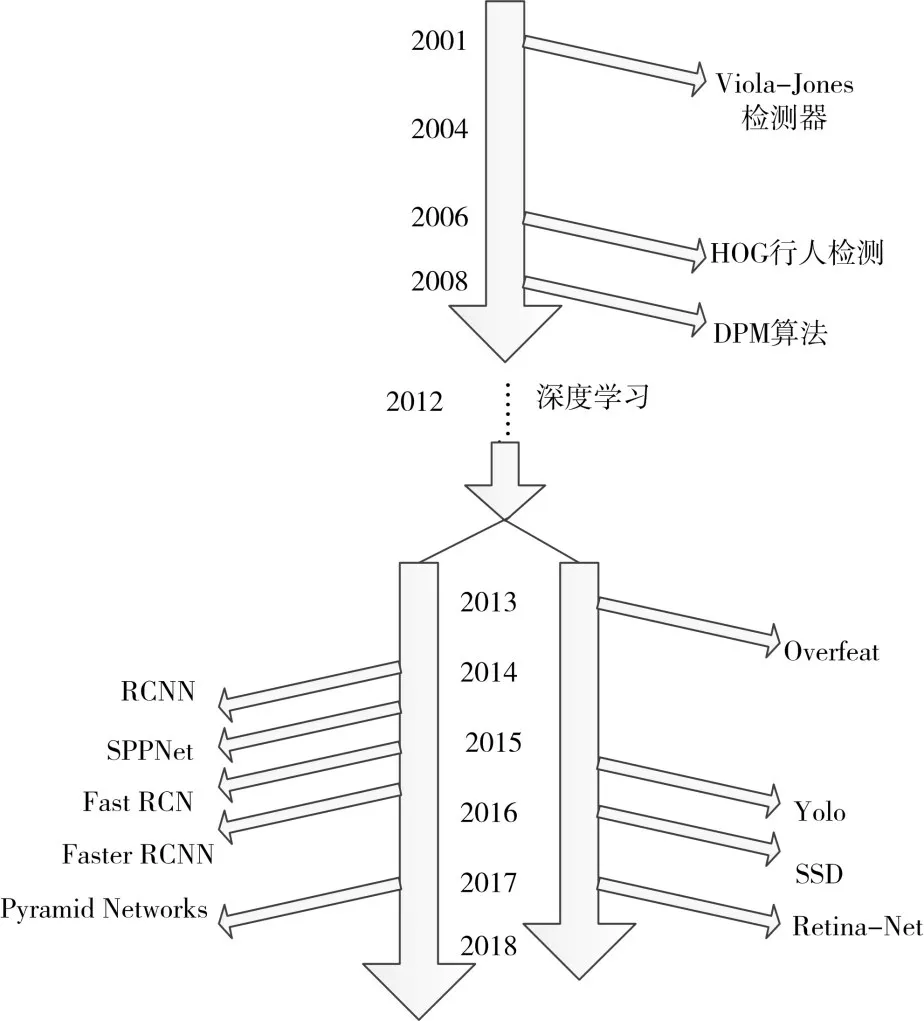
图1 图像目标检测算法发展史
从图1 可知,基于深度学习的目标检测算法的发展从2012 年兴起,有两条主线,第一条是基于Object Proposal 的检测主线,另一条是一体化卷积网络的检测主线,这条主线基本是按照YOLO,SSD,Retina-Net发展的。在第二条主线中,人们抛弃了传统的粗检测+精检测的检测流程,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度[3]。YOLO[4]是第一个一体化卷积网络检测算法,由Joseph 和Girshick 等人在2015 年提出。该算法最大的优势是速度快,彻底解决基于深度学习速度上的缺陷。SSD[5]算法由Wei Liu 等人于2015 年提出。SSD 算法吸收了YOLO 速度快和RPN 定位精准的优点,采用了RPN 中的多参考窗口技术,并进一步提出在多个分辨率的特征图上进行检测。
基于视觉的人体动作识别要解决的主要问题是通过计算机对摄像机采集的原始图像或图像序列数据进行处理和分析,学习并理解其中人的动作和行为,通过分析获得人体运动模式,最终正确识别出人体的动作。动作识别的主要难点在于模型的设计,使其不仅能从背景中检测出目标和动作,而且能准确识别动作多样性的变化。目前手动设计的模型,当动作有部分被遮挡或同一动作在不同的环境下发生时,识别的效果较差。利用卷积神经网络,能够学习到更高效的特征与模式[6]。同时SSD 算法吸收了YOLO 速度快和RPN 定位精准的优点,所以用SSD 框架进行训练和优化模型,不仅很好地解决了传统方法存在的缺陷,还能比在其他深度学习框架(如YOLO)下得到的模型,在精度和定位上更准确。
通过对比和分析各种目标检测方法,实验最终选择在ssd 框架上进行了实验,优化得出最终的模型。
2 卷积神经网络结构
2.1 卷积神经网络原理
卷积神经网络(Convolutional Neural Network,CNN),是一种前馈神经网络,人工神经元可以响应周围单元,从而进行大型图像处理。卷积神经网络是受到生物思考方式启发的MLPs(多层感知器),它有着不同的类别层次,并且各层的工作方式和作用也不同[7]。它主要由输入层、卷积层、激活层、池化层和输出层组成。卷积层用于局部感知和权重共享。激活层用于模拟人的神经系统,只对部分神经元的输入做出反应。常用的激活函数有Sigmoid 函数,Tanh 函数,Relu 函数等。池化层提供avg-pooling 和max-pooling 两种方式,来保证网络的鲁棒性,减少参数数量,防止过拟合现象的发生。输出层采用Softmax 回归模型,实现logistic 回归模型在多分类问题上的推广。
其工作原理是:由输入层对数据进行预处理,比如均值化,归一化等,然后经过若干次卷积+激励+池化后,最后到输出层,通过softmax 函数得到最终的输出。最终得到一个模型,该模型将学到一个高质量的特征图片全连接层。此外,为了得到更好的模型,也会在网络结构中增加一些额外的操作。比如,引入dropout 操作解决过拟合现象,或者采用进行局部归一化(LRN)、数据增强等操作,来增加鲁棒性[8]。
典型的CNN 结构有LeNet,AlexNet,VGG-Net,GoogLeNet,ResNet,轻 量 级CNN 模 型,如MobileNet,SqueezeNet,ShuffleNet 等。综合各个网络结构的特点,选择VGG16 网络结构,同时考虑内存和时间等因素,也用mobilenet_v1 进行了实验。对比实验表明,虽然mobilenet_v1 的内存占用率和时间大大减小,但是它的召回率和准确率也下降很多。
2.2 重构VGG16网络结构
本文的基于卷积神经网络的电话动作识别方法,其特征在于,使用的检测模型由重新设计的网络结构训练得到,所述模型网络基于VGG16 网络并进行了重构。
本文选择基于VGG16[17]网络并进行了重构。采用的模型网络在VGG16 的基础上减少了一个全连接层,保留了两个全连接层,增加了6 个卷积层和1个池化层,网络结构如图2所示。

图2 网络结构图
2.3 微调网络结构参数
为了优化模型,需要对网络结构进行参数调整。本实验调整了输入数据的尺寸大小,和各个卷积层的卷积核个数。
考虑到减小模型的内存占用率,实验对比两个输入图片尺寸,即512×512和300×300,综合对比内存占用率、所需时间和准确率,最终证明输入图片尺寸为512×512的效果更好。
由于VGG 网络结构的宽度和深度都相对较大,而本文选择的是对电话动作识别,是二分类问题。希望能够减小内存占用率和缩短处理时间,同时为了保证准确率。所以不改变网络结构的深度,尝试改变网络结构的宽度。最终通过多次实验调参数,最终得到:将VGG16 前四层的卷积核个数减半,既能保证在准确率只下降一点的情况,大大减小了模型的大小,同时也缩减了处理的时间。
3 实验模型训练及优化
3.1 图像增广功能
本实验的训练数据集是8400 张,测试集市2800 张图片。为了丰富图像训练集,更好地提取图像特征,提高模型的准确率,采取对样本进行随机扩充。主要有两种方式,一种是自己在准备数据时,编写程序,手动对样本进行增加。另一种是对caffe-ssd 源码进行了修改,增加了数据增广的功能,然后通过在网络结构给参数赋值,系统进行图像增广。综合考虑两种方法,发现第二种方法更加灵活,所以本文采用第二种方法增加数据增广功能。不过两种方法都是通过随机旋转图像,裁剪图像,改变图像色度,改变图像饱和度,图像亮度,图像尺寸大小等,进行对样本数据增广[18]。
实现原理是先将图像RBG 转换为HSV,然后随机对H(色度)S(饱和度)V(亮度)进行调整或同时对其中的两个或三个调整,之后再将图像HSV转换为RBG,最后将图像送入网络结构中。
具体实现:在ssd 的源程序data_transfer.cpp 程序中添加数据增广功能。DistortImage 这个主要是修改图片的亮度、色度、对比度和饱和度。在annotated_data_layer.cpp 增加颜色扭曲函数。 在im_transforms.cpp 中实现RandomHue()函数,AdjustHue()函数,RandomSaturation 函数,AdjustSaturation 函 数,RandomBrightness 函 数,AdjustBrightness各个函数,主要是实现随机更改图像中的某个参数。之后再编写ApplyDistort函数,通过调用ApplyDistort函数来实现随机更改图像。

图3 数据增广功能
3.2 K-means聚类算法计算box
本文所重构的网络结构中,最后有五个prior-Box 层(即fc7_mbox_priorbox,conv6_2,conv7_2,conv8_2,conv9_2),用于在每一个feature map 上获得prior box。为了使获得的prior box 更加精准,最后的五个融合检测网络层所使用的预选框尺寸用K-means聚类算法进行统计来得到,因为目标框的宽高并不是简单的线性关系,而K-means聚类算法具有出色的速度和良好的可扩展性,所以用它来进行统计标定的目标框。可以让预选框尺寸大小和比例更为适配检测的场景。
Means 算法的原理[19]是:K-means 是一种通过均值对数据点进行聚类的算法。其中K 表示类别数,Means 表示均值。因为本文需要获得的是五个预选框的大小,所以K 取5。K-Means 算法通过预先设定的K 值及每个类别的初始质心对相似的数据点进行划分。并通过划分后的均值迭代优化获得最优的聚类结果。
3.3 图像光照不均匀预处理
由于天气或光照的原因,导致摄像头传送过来的图片存在偏暗或偏亮的现象,光照不均匀在一定程度上改变了图像的原始面貌,从而使模型检测结果出错[8]。为了提高模型的检测效果。在传送图像的过程中,对图像进行简单的光照判断。
图像偏暗或偏亮的判断方法:通过统计图像灰度直方图,然后统计达到阈值的灰度值(阈值是通过统计3000 张偏暗或偏亮的图片统计得到的),最后作灰度线性变换。
图像光照不均匀预处理的算法[9]为先对图像进行幂律变换,主要是扩大图像在光线不足情况下的动态范围和压缩在光线强烈时的动态范围。之后采用高斯差分滤波器,对低频和高频部分进行处理。最后,重新归一化所有的像素点值。

图4 图像光照处理流程图
4 实验结果及分析
模型测试结果如下图所示。
考虑到实际应用中对GPU 或CPU、内存占用率和时间的要求,本文综合考虑这几种因素,进行了三次模型的训练。由于每个模型要统计2800 张图片的测试结果,人为的统计费时长而且不科学,所以选择编写Python程序进行实现。

图5 模型测试结果
程序的主要思路是对比标定的框和模型测试的框是否重叠。反向思考,不妨先解决出“不重叠”的情况,设两个框为A,B 矩阵。即B 矩阵,可能在A 的左侧、右侧、上侧、下侧。如果用公式表示,即(p2.y≤p3.y)∨(p1.y≥p4.y)∨(p2.x≤p3.x)∨(p1.x≥p4.x),那么可知两个矩阵重叠时,公式为¬[(p2.y≤p3.y)∨(p1.y≥p4.y)∨(p2.x≤p3.x)∨(p1.x≥p4.x)]
根据德·摩根定律可转换为
(p2.y>p3.y)∧(p1.y<p4.y)∧(p2.x>p3.x)∧(p1.x<p4.x)。
4.1 不同网络结构的模型测试结果
SSD512模型是重构VGG16的网络结构训练所得,mobilenet 模型是用mobilenet v1 网络结构训练所得。
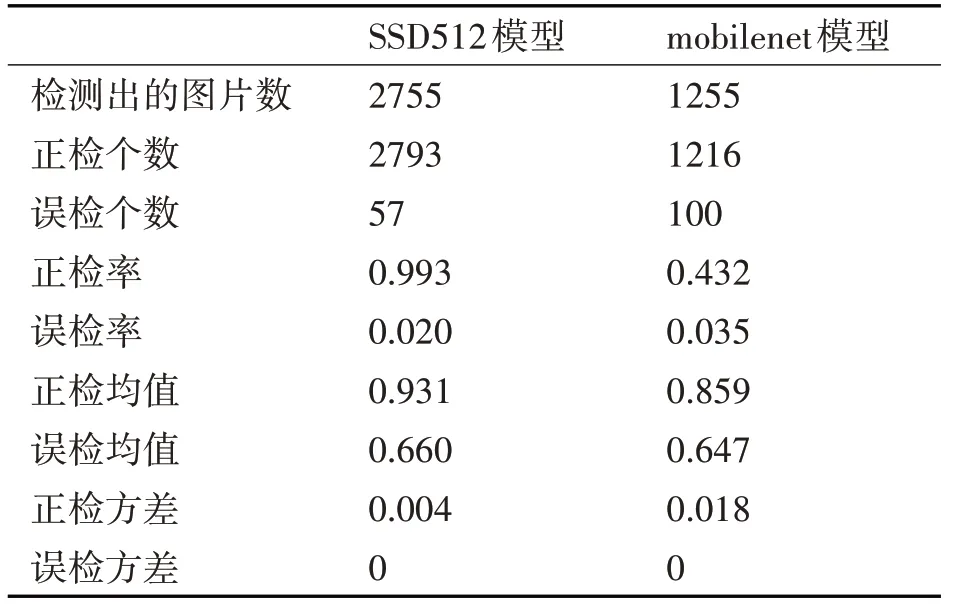
表1 不同网络结构模型测试结果统计表
SSD512 模型大小为96425K,约94.1M。mobilenet 模型大小为22764K,约为22.23M。根据上面表格统计的结果可知,mobilenet网络结构的模型虽然内存大大的减小,但是正检率也降低了很多,所以模型效果不好。
4.2 不同输入尺寸的模型测试结果
SSD512模型是重构VGG16的网络结构并且输入的图片尺寸为512×512 训练所得,SSD512 模型是用重构VGG16 的网络结构并且输入的图片尺寸为300×300训练所得。
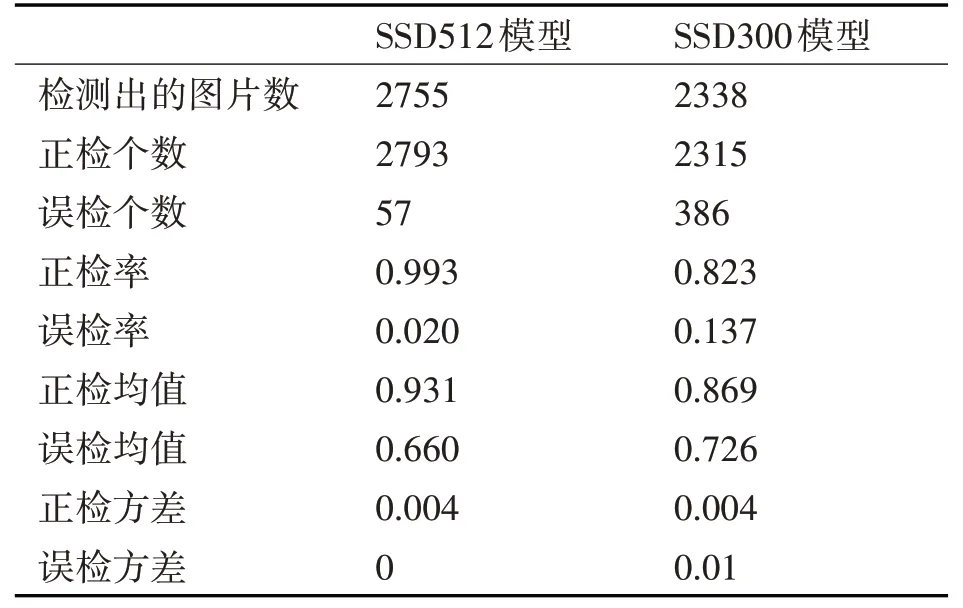
表2 不同输入尺寸模型测试结果统计表
SSD512 模 型 大 小 为96425K,约94.1M。SSD300 模型大小为:93814K,约91.6M。根据上面表格统计的结果可知,输入尺寸为300×300 的模型,内存只降低了一点,但正检率下降了0.170,误检率提高了0.117,时间处理上也没有减少。所以输入尺寸为300×300的模型效果不是很好。
4.3 同一卷积层不同的卷积核个数模型测试结果
SSD512模型是重构VGG16的网络结构训练所得,SSD512 卷积个数减半模型是用重构VGG16 的网络结构并且将前四层卷积层的卷积个数减半训练所得。
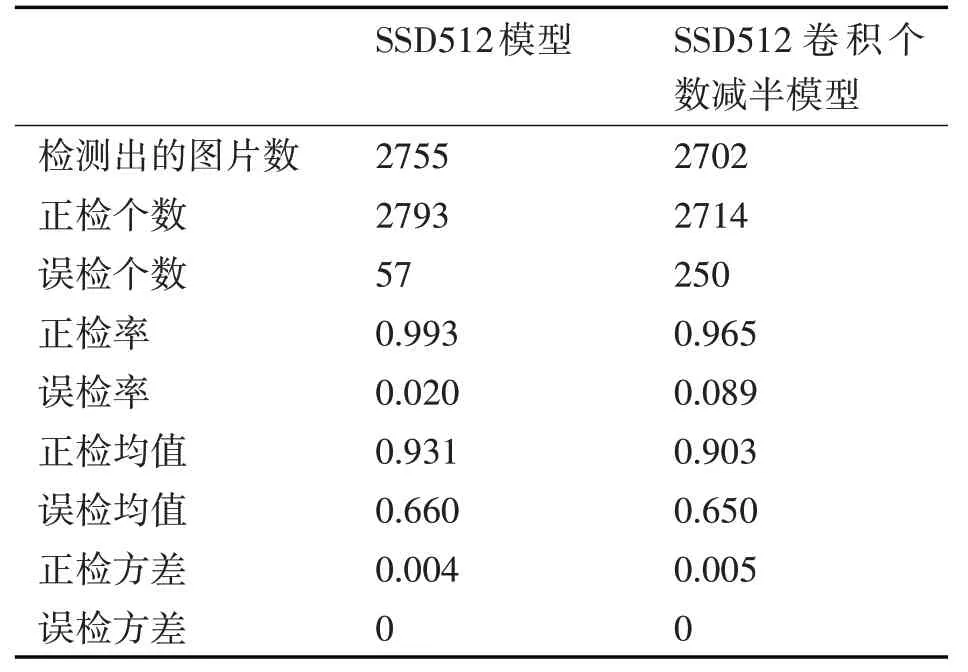
表3 同一卷积层不同的卷积核个数模型测试结果统计表
SSD512×512 模型大小为96425K,约94.1M。SSD512×512 卷积个数减半模型大小为78346K,约为76.5M。由上图表格可知:将VGG 前4 层的卷积层的卷积个数减半的模型,正检率只下降0.028,误检率提高0.069,而模型的内存下降了17.6M,处理每张图片的时间也减少了。综上可得:SSD512×512卷积个数减半模型是相对较好的模型。
5 结语
本文研究基于卷积神经网络的电话动作识别的方法,网络结构是基于VGG16 并重构VGG16。对比mobilenet 网络结构发现:重构后的VGG16 网络结构训练出的模型效果,同时还对比了微调参数的模型效果。对比结果表明,对于接打电话的监控检测,正检率可达0.965。此外,对于误检的图片进行分析,大多数为图像过暗、光照不均匀和动作与打电话动作相似的情况。图像过暗、光照不均匀已通过前期对送入的图像进行图像光照预处理得到解决,动作与打电话相似的还有待进一步优化。但是本文优化的模型已经能够很好地应用于智能监控场景。
