基于多尺度词包表示的h LDA模型的茶园识别研究
2020-09-30王小芹张志梅王常颖
王小芹,张志梅,王常颖
(青岛大学数据科学与软件工程学院,青岛266071)
中国不仅是茶叶的生产地,也是全球最先发现和使用茶叶的国家,茶园种植区域和茶叶生产率一直占据全球第一的地位,茶产业在中国农业经济和农村发展中发挥了至关重要的作用[1]。因此,准确掌握茶园的种植面积对于优化茶园的布局具有重要意义,同时也为长势分析、产量估算和灾害提防提供了数据依据[2]。长期以来,中国一直通过人工测量和抽样调查两种方式统计和预测农业生产状况,但这两种方式需要很长的时间,均不便于动态地观测大规模的农作物生长的趋势[3]。遥感技术因可以监测大范围区域、获取信息速度快等优点,自其应用以来,已经被证明了能够有效地监测农作物,对此国内外学者开展了大量的研究。Qin等[4]利用Landsat8、Landsat7和MODIS影像提取水稻种植面积;单捷等[5]利用Radarsat-2影像提取水稻种植面积;You等[6]利用GF-1影像提取冬小麦面积;黄健熙等[7]利用GF1-WFV 影像提取大豆和玉米种植面积;Vieira等[8]利用Landsat影像的时间序列提取甘蔗种植面积。也有学者通过遥感技术进行茶园识别研究,如金玉香[9]利用Landsat8卫星影像提取临翔区和双江县的茶园信息,但是对于中分辨率的数据,准确的选取训练样本有一定的难度;朱泽润[10]利用非监督卷积神经网络自动的提取特征进行茶园提取,但是自学习特征的获取需要大量的训练样本,到目前为止还没有专门针对茶园的数据集。那么如何利用高分辨率遥感影像进行茶园识别是本研究的重点。
1 数据准备及预处理
贵州省因其具有“高海拔、低纬度、寡日照”特点及酸性土壤等优势条件,非常适合茶叶生长,本文通过从贵州省农业局获取的高分一号(GF-1)影像上裁剪出7000×6000大小的位于湄潭县区域的影像作为研究区,分辨率为2m。图1为湄潭县茶园研究区域。
对图1进行数据解译,研究区数据的成像时间是2019年4月份,农田中还种植了各种作物,由于本研究是进行的茶园识别,故将所有作物归为农田一类。根据实地调查并结合目视解译,将地物划分为6大类:裸地、林地、建筑区、农田、水域和茶园,建立解译标志如表1所示。通过建立解译标志,对茶园信息有了更细致的了解,有助于更加准确地进行茶园识别。
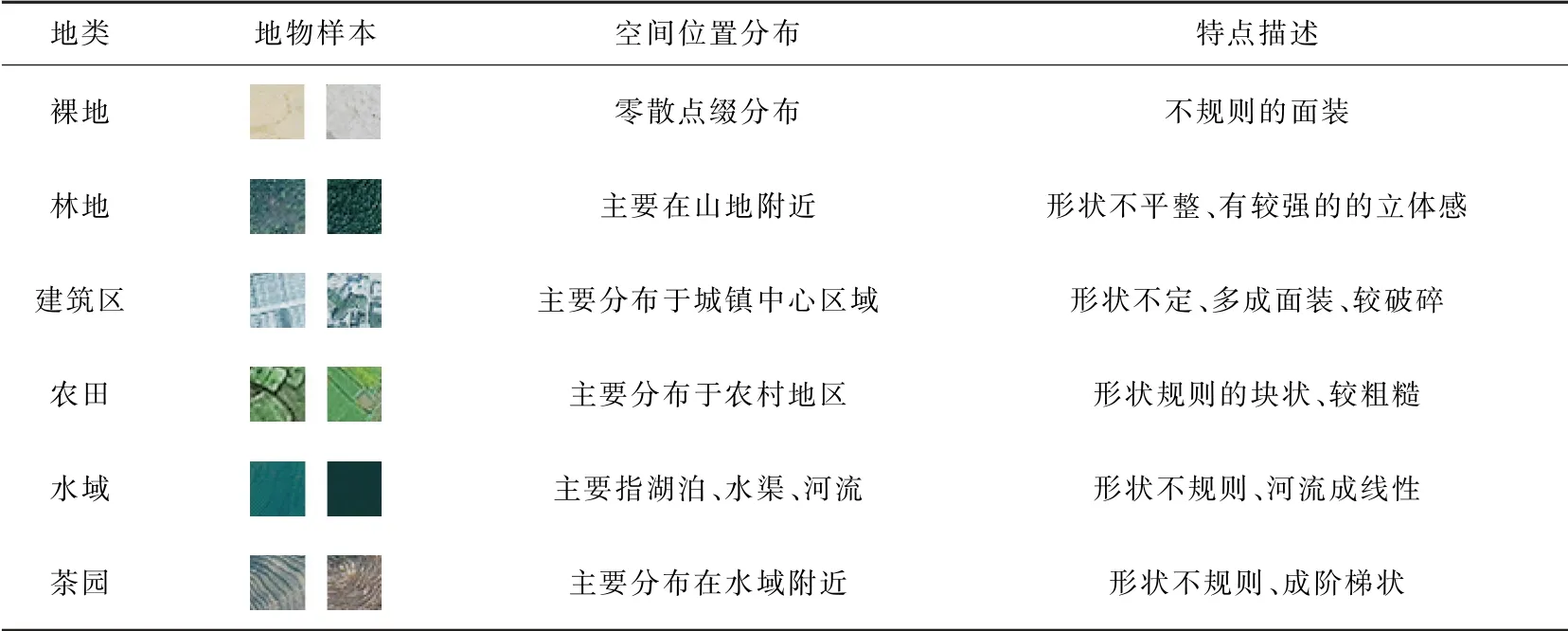
表1 地物解译标志
2 基于多尺度词包表示的h LDA模型
2.1 多尺度词包模型
将词包模型从文本分析迁移到图像分析,通过获取场景的特征,实现了对“语义鸿沟”的跨越。考虑到遥感影像的空间特性和尺度特征,将基于空间金字塔表示的多尺度词包模型用于场景的特征表达中。本研究将基于MS_BOVW 的方法用于地物识别中,首先生成多个尺度的图像金字塔,然后获取不同尺度下的场景并映射成相应的单词来构造直方图表示,将不同尺度下的直方图通过加权的方式合并,作为最终的特征。
2.2 层次主题模型
层次分类算法对每层的类别属性分析是通过对图像的特征属性进行细分完成的,例如首先把影像划分成植被、非植被两个大类,随后将每个大类进一步细分,最后继续细分第二层子类,得到更精细的类别。层次主题模型通过不断的重复以上操作,最终得到了一个具有层次性的树状结构,而树的层次和节点个数在计算的过程中被确定。通过分析层次主题模型,发现与人对事物进行分类时的思想一致,总是先将一个事物归于某个大类,接着细分到更具体的小类,最后才能确定事物所属的类别。
经典的h LDA 模型中视觉单词最开始时在层次结构中的位置是通过随机的方式确定的,如何根据已有的先验知识定义视觉单词的层次位置是本研究要解决的问题。当通过卫星监测地球时,能够看到大片的水体和陆地;当在飞机上观看时,映入眼帘的往往是农田或者各种各样的建筑物;如果直接站在地面上进行观看,那么更多的注意到脚下的植被和眼前的高楼。因此,对于同一块区域,当在不同尺度下观测时,关注到的语义也不同。因此不同层次的语义信息可以通过不同尺度下的视觉单词表示。
2.3 基于多尺度词包表示的h LDA模型基本流程
根据生成的多尺度视觉单词来定义视觉单词在初始化时的层次位置。将最大尺度下获得的单词作为第一层,下一尺度下的单词作为第二层,以此类推下去。本研究中使用的多尺度词包表示的h LDA 模型,只是将尺度信息加入到h LDA 模型初始化过程中,没有加入场景的任何类别信息,所以整个过程仍然是非监督的,因此计算效率没有显著降低。其一般步骤如下:
Step 1:通过遥感影像数据构造场景集合I={I1,…,IN};
Step 2:生成场景集合I 的多尺度视觉单词;
Step 3:对树的层次结构进行初始化,将各个尺度下的视觉单词随机指定为相应层次上的一个节点;
Step 4:生成影像Im对应的路径Cm;
Step 5:提取路径Cm上的所有主题θm,且使得θm满足Dirichlet分布;
Step 6:对场景Im,根据多项式分布选择对应的主题Zm,根据主题选择对应的单词Wm;
Step 7:通过对数似然函数L(t),比较(L =|L(t)-L(t-1)|,如果收敛则迭代结束,否则回到Step 4。
3 基于多尺度词包表示的h LDA模型的茶园识别
3.1 基于多尺度词包表示的茶园特征提取
基于多尺度视觉词包表示的茶园特征提取主要包括以下三个步骤:场景获取与描述、视觉词典构造、频次直方图表示。图2为基于多尺度词包表示的茶园特征提取流程图。
场景获取与描述。在本文的茶园识别研究中,首先得到影像的尺度金字塔,然后通过滑动窗口的方式提取三个尺度上的图像块作为场景。其中,茶园陇状特征是一个很关键的纹理信息,本研究将光谱特征和纹理特征作为视觉特征描述子。
视觉词典构造。将光谱特征和纹理特征进行量化,利用k-means方法获取所有特征向量聚类的结果作为视觉词典。目前对于获得合适的视觉词典没有明确的方法,只能通过实验衡量视觉单词大小对场景的描述性能和泛化性能。
频次直方图表示。在完成视觉词典构造后,在各个尺度下将每个场景标记成与词典中欧氏距离最小的视觉单词,最后用频率直方图统计每个单词出现的频率,完成图像特征表达,加权连接各个尺度上的频率直方图,将最终获取的多尺度词包表示作为的特征用于分类。
3.2 基于多尺度词包表示的h LDA模型的茶园识别框架
在完成多尺度词包表示的基础上,本文构建了一套基于茶园识别的框架,如图3所示。该框架中绿色虚线是基于MS_BOVW 模型的茶园识别流程,红色虚线是基于h LDA 模型的茶园识别流程,红色箭头和绿色箭头分别表示采用h LDA+SVM、MS_BOVW+SVM 方法的茶园识别。在这两种地物识别方法中又都包含了训练和测试两个不同的阶段。
基于多尺度词包表示的h LDA 模型的茶园识别框架中,训练阶段主要做的是从给定的场景训练集中训练SVM 分类器。首先通过下采样的方式构造图像尺度金字塔,并提取各个尺度下训练样本集的底层特征,对提取的特征向量利用k-means聚类方法进行聚类,通过选取合适的视觉单词构建多尺度视觉词典。然后分别获取多个尺度下的场景并映射成相应的单词,构造直方图表示,最后通过加权的方式将不同尺度下的直方图连接作为最终的特征。在得到最终的特征后,并结合相应的主题个数一起送入h LDA 模型中,通过得到的主题混合比例信息训练SVM 分类器。测试阶段进行地物识别时,利用滑动窗口的方式将场景测试集划分成不重叠的图像块,生成描述图像块的特征向量,并根据训练阶段构建的多尺度视觉词典将其标记成与词典中欧氏距离最小的单词,最后用频率直方图统计每个单词出现的频率得到最终的特征;利用h LDA 模型从最终的特征中获取主题的概率分布,送入到SVM 分类器进行分类。
4 茶园识别结果与分析
4.1 参数分析
实验提取了738个大小为40×40的样本用于参数分析和精度评价,其中裸地、森林、建筑、农田、水域和茶园样本的个数分别为:56、166、124、126、66、200。
基于主题模型茶园识别的精度在很大程度上与构建的多尺度视觉单词数量和主题的数目有关,因此,首先要确定进行茶园识别时最佳视觉单词和主题数目。本研究将多尺度视觉单词中的第一层单词个数设置为100~800,间隔为100;第二层为50~400,间隔为50;第三层为25~200,间隔为25。主题的个数设置为10~50,间隔为5。通过提取的738个样本计算茶园正确识别的精度,其结果如表2、图4所示,其中表2只展示了最大尺度下视觉单词个数的茶园识别精度。当最大尺度下视觉单词个数为600时,主题数量为20时,茶园识别精度达到最优。
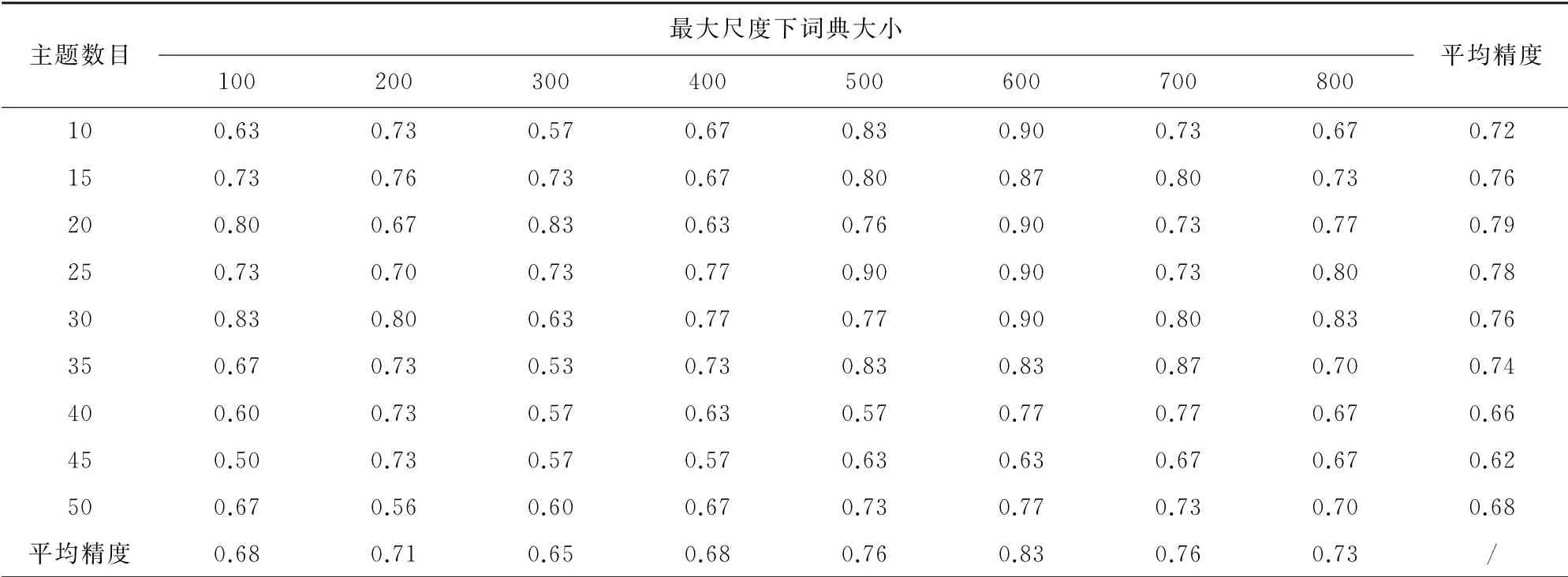
表2 茶园识别精度
4.2 茶园识别结果
为了验证h LDA 模型在茶园识别上的有效性,本研究同时比较了基于MS_BOVW+SVM 方法的茶园识别。为此选取了精度最高时的参数进行对比分析,即模型中第一层视觉单词数量设置为600,第二层视觉单词数量设置为300,第三层视觉单词数量设置为150,主题数量设成20,MS_BOVW 模型中视觉单词个数与h LDA 模型中数量一样。基于两个模型的茶园识别结果如图5所示,可以明显的看出来本研究方法提取的茶园区域噪声明显减少。
4.3 精度评价
将MS_BOVW+SVM 方法和h LDA+SVM 方法分别应用于提取的738个样本进行精度评价,其中模型参数同上,通过实地调查并结合目视解译建立混淆矩阵,如表3所示。
通过表3可知,MS_BOVW+SVM 方法和h LDA+SVM 方法的总体分类精度都高于90%,其中h LDA+SVM 方法比MS_BOVW+SVM 方法分类效果要好,总体分类精度为93.8%,Kappa系数为0.92。基于h LDA+SVM 方法在各个地物类型的制图精度和用户精度都有所提高,尤其是在茶园这种由多种地物构成的复杂场景效果更明显。虽然两种方法对于茶园场景的制图精度都超过90%,但是基于h LDA+SVM 方法错分误差减少了5.5%,说明主题模型的引入明显提高了茶园识别的精度。
通过分析造成茶园场景错分或者漏分的原因可能有:茶园不像玉米、小麦等作物具有规则的种植区域,形状不规则也加大了茶园识别的难度;一些茶园场景的地表纹理结构、色调与选取的农田、裸地场景相近,导致获取的特征相似,所以茶园场景很大可能错分成农田、裸地场景;不同区域的茶园种植方式不同,加上多为品种混杂的群体茶园,无法提取到茶园统一的特征。
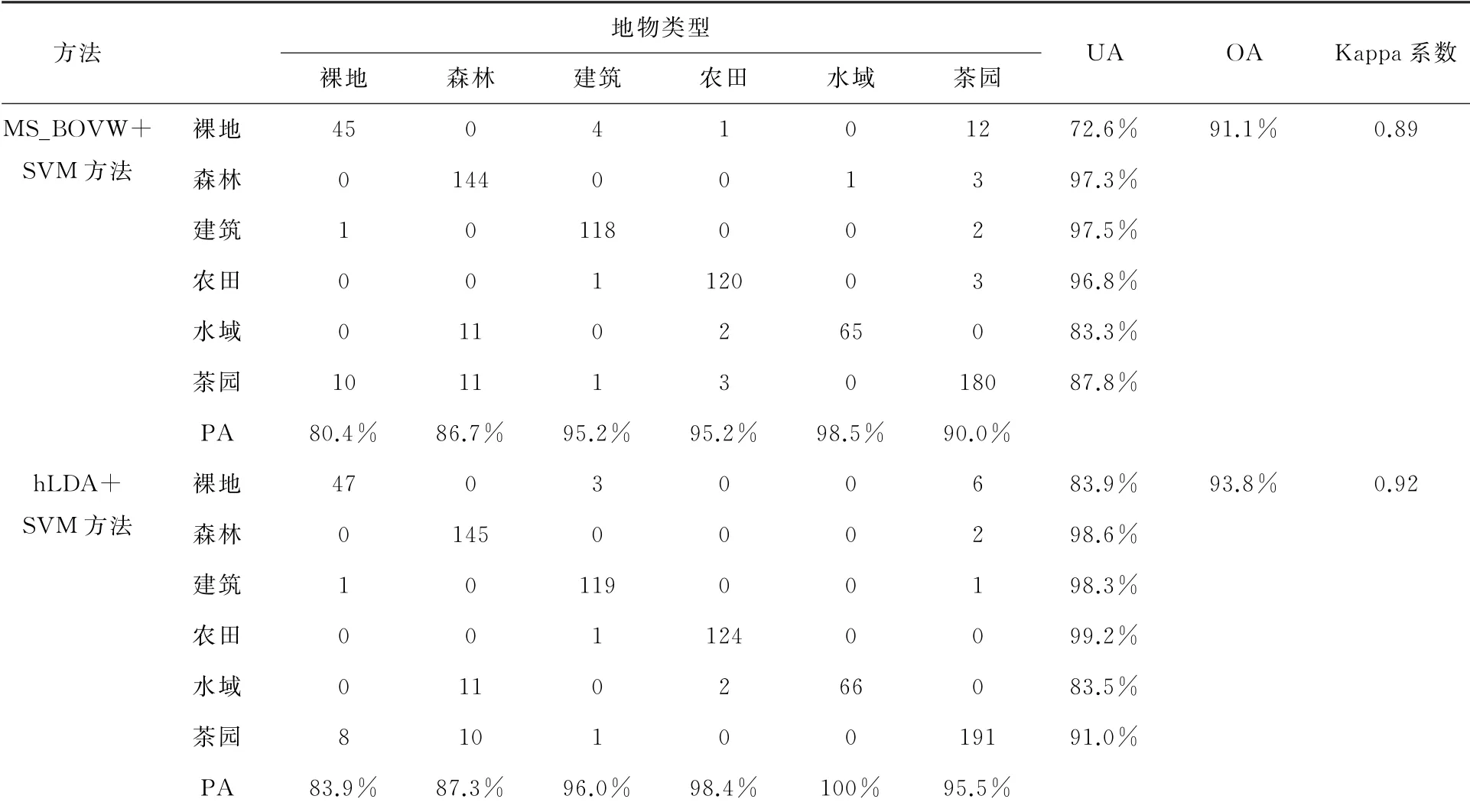
表3 茶园识别混淆矩阵
5 结论
将h LDA 模型应用于茶园识别中,通过建立起底层视觉特征与高层语义信息之间的联系,经过相关实验证实了该模型可以达到自动识别茶园的目的,为今后作物识别提供了一种新的思路。在h LDA 模型中,如何自动的选取最优视觉单词数量和主题个数,避免人工过多的干涉也是本文后序需要研究的目标。虽然达到了茶园识别的目的,但与实现整个县域遥感影像自动解译还有很大差距,因此下一步还需要寻找不同季节、不同地区、不同品种的茶园影像构建一个大型的数据库。
