基于深度学习的医疗影像识别技术研究综述
2020-09-29张荣梅
张 琦,张荣梅,陈 彬
(河北经贸大学 信息技术学院,河北 石家庄 050061)
引言
智慧医疗是通过人工智能技术实现智能医疗诊断,而基于医疗影像的诊断是智能医学诊断的重要的方式之一。医疗影像数据作为疾病诊断决策的主要信息来源,包括二维医疗影像和高维医疗影像,其中二维医疗影像包括显微镜高清影像以及X光影像,高维医疗影像包括CT、MRI、超声等。医疗影像识别技术是指利用计算机技术对医疗影像中的病灶进行检测、分割,最终实现分类识别。
本文首先从二维医疗影像和高维医疗影像两方面介绍医疗影像识别技术的发展历史,然后讨论了医疗影像识别技术中几种典型的深度学习网络模型,包括深度对抗网络、全卷积神经网络、R-CNN网络、卷积神经网络以及三维卷积神经网络等。同时介绍了深度学习在医疗影像增强、医疗影像检测、医疗影像分割以及医疗影像识别四个方面的应用,最后给出了智慧医疗技术存在的问题及未来的发展方向。
1 医疗影像识别技术研究现状
1.1 二维医疗影像
医疗影像数据与自然领域图片不同,医疗影像数据的特征不明显,分类效果差。传统机器学习算法识别二维医疗影像[1,2]主要包括图像特征提取与图像识别两个部分,需要人工提取医疗影像特征,识别准确率偏低。而深度学习技术省去了传统机器学习算法的图像特征提取的步骤,可以利用网络结构自动提取图像特征并分类,识别准确率高。
2013年,Roa等人[3]利用卷积神经网络(Convolutional Neural Network,CNN)和SVM分类器实现自动检测基底细胞癌,并添加可判断层,实现深度学习过程可视化。该方法利用BCC、HistologyDS和STL-10组织病理数据集训练,得到了平均精度为91.4%。
2016年,Jeremy等人[4]利用CNN网络识别皮肤癌图像,将输入图片划分多个不同的分辨率,提取图像不同的特征。并利用Dermofit皮肤癌数据集训练,得到的诊断准确率为78.1%。Antony等人[5]利用迁移CNN网络识别膝关节X光影像,判断膝关节骨性关节炎(OA)严重程度。并使用骨关节炎OAI 数据集进行训练,得到了平均准确率为43%。
2017年,Lei等人[6]利用ISIC2017数据集作为训练数据,并对数据进行增强。同时使用ResNet网络迁移训练,识别准确率达到了91.5%。
2018年,Dorj等人[7]提出利用AlexNet网络提取皮肤癌图像的特征,并利用SVM分类器分类,通过收集3753幅皮肤癌图像训练,识别准确率为95.1%。Harangi等人[8]利用CNN网络对皮肤癌影像诊断分类,并通过加权融合四种不同的卷积网络结构的分类结果,得到了89.1%的预测结果。
2019年,周进凡[9]利用改进的VGG16网络对肺部X光图像进行识别预测,得到的识别准确率为81.98%。
1.2 高维医疗影像
为了对病灶了解得更全面,利用CT、MRI等技术观察立体病灶信息成为来了医疗影像诊断中的重要一部分。如何识别三维的医疗影像,提升病灶分类的准确率,成为了学者研究的方向。
2015年,Adrien等人[10]利用稀疏自编码器和3D-CNN网络结构识别大脑MRI影像诊断阿尔兹海默症患病状态,并利用ADNI数据集训练,得到了89.47%的准确率。Wei等人[11]利用多尺度卷积神经网络直接提取原始肺结节特征识别,并对LIDC-IDRI数据集训练,识别准确率为86.84%。
2016年,Hosseini等人[12]利用3D自编码卷积神经网络识别大脑MRI影像诊断阿尔兹海默症,并对完全连接的上卷积层参数进行微调,利用ADNI数据集训练,准确率达到了94.8%。Nie等人[13]提出利用3D-CNN网络结构和多通道数据结构训练大脑肿瘤MRI图像,并通过收集69为患者的MRI影像数据,得到了89.9%的诊断准确度。
2017年,Xiaojie Huang等人[14]利用局部几何模型滤波器生成候选结节,并利用3D-CNN预测肺结节种类,该方法对LIDC肺部CT影像训练,得到的分类准确率高于90%。
2018年,Marysia等人[15]提出3D G-CNN网络结构,利用三维旋转平、移群卷积代替传统的平移卷积,自动检测肺结节CT影像。该方法使用NLST数据集训练,并使用LIDC数据集进行训练,得到的识别准确率为88%。
2019年,Shahedi M等人[16]通过改进的U-Net网络对前列腺三维CT影像进行分割,得到的骰子相似系数为83%。Cao等人[17]提出两阶段的卷积神经网络,第一阶段利用U-Net网络检测肺结节,第二阶段利用3个3D-CNN网络分类,并在LUNA数据集训练,准确率为92.5%。金祝新等人[18]利用MCINet网络识别大脑痴呆MRI影像,该方法对ADNI数据集进行训练,得到的分类准确率为92.6%。
2 医疗影像识别的深度学习网络模型
医疗影像识别技术包括图像增强、图像检测、图像分割以及图像识别,本文分别从这四个部分介绍深度学习模型的相关技术。
2.1 图像增强技术
深度学习技术中,如果训练集样本数量过小容易造成过拟合的情况。由于医疗数据集的样本数量普遍较小,需要利用数据增强技术对现有的数据集样本扩充。数据增强是指将有限的训练数据通过某种变换,生成新数据的一种技术手段。
常规的数据增强的方法包括旋转、尺度变换和噪声干扰等变换,但是这些数据增强没有考虑医疗影像的特点,有时可能降低识别准确率。而基于深度学习的生成对抗网络[19](Generated Antagonistic Network,GAN)能够根据数据的特征自动生成新的医疗数据,可靠性较高,是图像增强技术种常用的方法。
GAN模型包括生成模型和判别模型两部分,生成模型通过噪声向量生成与真实图像相似的图像,判别模型则通过训练真实图像数据和生成模型生成的假的图像,达到判别图像真假的效果。通过两个模型交替迭代训练,最终使判别模型能最大概率地正确判断样本图像的真假,同时生成模型能够生成尽量真实的图像,达到纳什均衡的效果,图1为生成对抗网络的训练流程。

图1 GAN训练流程
2.2 图像检测算法
2.2.1 R-CNN
图像检测算法的作用是检测图像中感兴趣区域的类别和位置。2014年,Girshick等人[20]第一次提出R-CNN算法实现目标检测,该算法通过选择性搜索操作来确定候选区域,并对候选区域分类回归。R-CNN算法结构主要包括候选区域的提取、特征提取以及分类回归三部分。其中候选区域提取主要是从输入图片中提取可能出现物体的区域框,并归一化为固定大小;特征提取部分是将归一化后的候选区域分别输入到CNN网络模型获取图片特征,得到固定维度的特征输出;分类和回归部分是通过SVM分类器以及线性回归操作将输出特征进行分类识别的回归,判断目标类别并精确目标边界区域。R-CNN算法是目标检测算法中的经典算法,为后续的目标检测算法的改进提供了坚实的基础。
2.2.2 Faster R-CNN
R-CNN算法的缺点是需要依次提取候选区域的特征,非常耗费时间。为了加快算法的运行效率,2015年Ren[21]提出了Faster R-CNN算法,该算法将整个输入图片进行特征提取,再在生成的特征图像中通过区域建议网络生成候选区域,并利用感兴趣区域生成固定大小的特征向量,最后通过SoftMax以及SmoothLoss实现对图片进行识别分类和回归。Faster R-CNN算法减少了R-CNN算法中选择性搜索的时间,并且只对图像整体进行特征提取就可以实现目标检测,缩小了算法运行时间,是目前应用最广泛的目标检测算法之一。
2.3 图像分割技术
2.3.1 全卷积神经网络
全卷积神经网络[22](Full Connected Network,FCN)的结构全部由卷积层构成,该网络的主要特点包括上采样操作和跨层连接。卷积池化操作后得到的特征图分辨率会越来越小,因此需要通过上采样操作将特征图恢复到原图分辨率。同时,如果只对最后一层特征图上采样会丢失很多细节信息,得到的结果不够精确。因此将浅层网络中的特征图也进行上采样,并通过跨层连接的形式进行整合,从而实现精准分割。但是FCN网络的分类结果还不够精确,因此基于FCN网络又出现了很多改进的分割网络,包括U-Net网络。
2.3.2 U-Net模型
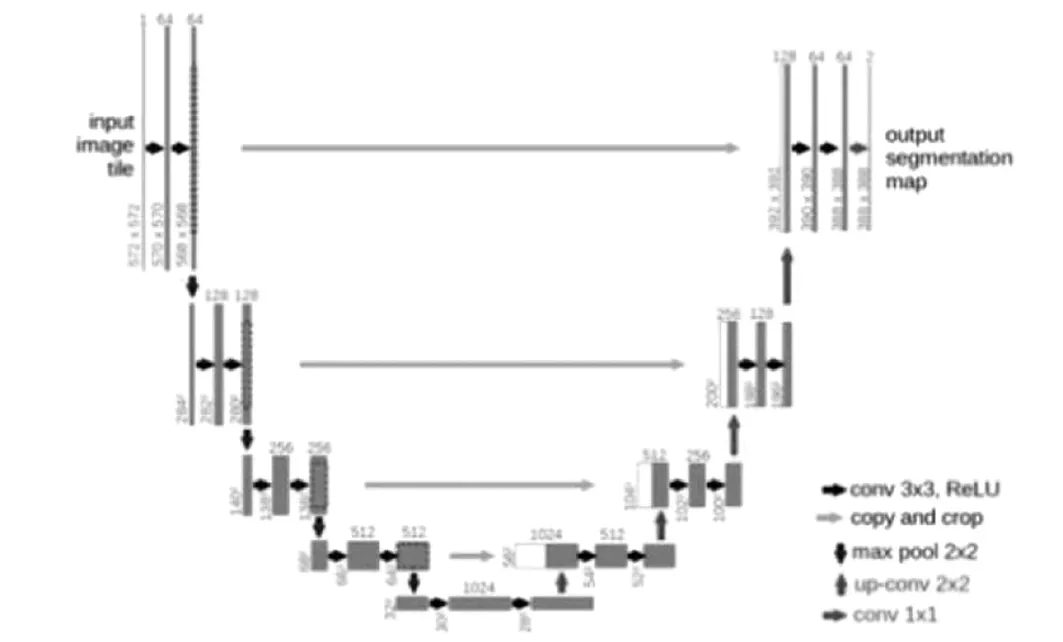
图2 U-Net网络结构
U-Net模型结构主要由特征提取部分与上采样部分组成,由于网络结构像U型,因此称为U-Net模型,如图2所示。U-Net模型的特征提取部分与卷积神经网络结构相同,用于提取图像的特征向量;上采样部分是将特征结果进行上采样操作,并与对应特征提取部分的结果拼接融合,实现多尺度融合,精确分割结果。U-Net模型的上采样结构中输入向量包括浅层网络中生成的特征向量,能够提取多尺度的图像特征,分割结果更精确。
2.4 图像识别模型
基于深度学习图像分类算法可以自动提取医疗图像的特征,分类诊断的准确率高。目前已经广泛应用于医疗影像的识别。
2.4.1 卷积神经网络
卷积神经网络[23]主要是通过卷积池化层提取图像的特征向量,并利用全连接层实现图像的特征分类,如图3所示为卷积神经网络结构。
其中卷积层的作用是通过卷积核在图像中滑动并与图像局部数据进行卷积计算生成特征图提取,用于图像特征数据。同时,卷积层通过局部关联的方式分别对神经元周围局部感知,最后综合局部的特征信息得到全局特征。池化层是对特征数据进行聚合统计,降低特征映射的维度,提高网络的计算效率。全连接层会将池化后的多组数据特征组合成一组信号数据输出,并通过分类器进行图片类别识别。
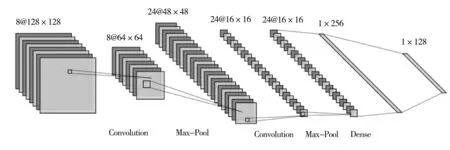
图3 CNN网络结构
2.4.2 三维卷积神经网络
传统的二维CNN结构的卷积核只会对二维图像进行卷积,提取图像特征。当输入图像为多通道时,卷积操作只能压缩多通道信息为二维信息,忽略多张图像之间的关联信息。而3D卷积神经网络可以对多通道图像输出为3D形式的特征图。对于立体图像和视频图像识别,二维CNN结构是将图像切割为连续帧图像,对每一帧图像分别进行识别,忽略考虑空间维度的信息;而3D-CNN结构则可以捕获图像之间的空间特征信息。

图4 2D卷积
3D卷积中,卷积核会与前一层中连续多帧图片都进行卷积操作,使下一层的特征图包含连续帧图像之间的空间维度信息,图4为2D卷积,图5为3D卷积。3D卷积的公式如式(1)所示:
(1)

3 深度学习在医疗影像识别中的应用
目前,深度学习技术在医疗影像识别领域已经有了长足的发展,在影像增强、影像分割、影像检测以及影像识别方面的研究取得了很大的成就。
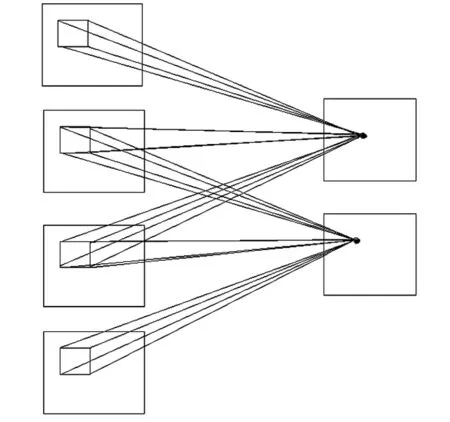
图5 3D卷积
3.1 医疗影像增强
深度学习需要从大量的医学影像数据中学习,但是医疗影像数据的难以获取,又涉及患者的隐私,无法获得大规模的数据;同时,医疗影像需要有经验丰富的医生进行数据标注,需要花费大量的人力与时间。因此对有限的医疗影像进行数据增强提高医疗影像病灶识别重要的一环。
2017年,CostaP等人[24]利用生成对抗网络生成了眼底图像,可以用于无监督学习模型训练。Nie等人[25]利用FCN网络作为生成器将MRI图像生成对应的CT图像,并用生成对抗思想训练,并通过自动上下文模型实现上下文感知的生成对抗网络。
2018年,Hu等人[26]利用改进的GAN对病灶病理组织图像对病理组织细胞进行分类,并对骨髓细胞进行无监督训练。Talha等人[27]提出MI-GAN网络生成视网膜医学图像,并进行监督分类。
2019年,Abhishek等人[28]利用GAN网络增强原始皮肤癌ISIC2017数据集,并利用分割掩码来训练Mask2Lesion模型,使该模型生成任意掩码下的新的损伤图像,该模型在分割测试中准确率提高了5.17%。
3.2 医疗影像检测
在实际应用中,医疗影像中不仅含有需要检测的病变区域,还含有病变区域周围的背景区域。这些背景区域会极大地影响计算机识别诊断的准确率。因此对医疗影像中病变部分进行目标检测,是提高识别诊断率的重要步骤。
2017年,Ding等人[29]提出利用反卷积神经网络检测肺部CT图像轴向切片中的候选结节,并利用三维DCNN检测结节的假阳性。该方法在LUNA16数据集中训练,得到的检测准确率为89.3%。
2018年,Song等人[30]提出多任务级联CNN框架检测甲状腺超声图像中的甲状腺结节中的上下文信息,实现对甲状腺结节的检测与识别,识别准确率为98.2%。
2019年,Pang S等人[31]提出改进的YOLO网络Yolov3-arch检测识别胆结石CT影像并分类,通过自己构造的20多万张CT数据影像训练,得到的分类准确率平均为86.5%。
3.3 医疗影像分割
医疗影像的分割也是医疗影像诊断系统中重要的一部分,目前医疗影像分割技术已经成为了医疗图像处理领域中应用最广泛的方向。如何结合全局和局部信息对相关结构和病灶点进行准确的分割是研究的难点。
2017年,X.Zhang等人[32]利用改进的FCN模型对皮肤黑色素瘤进行分割,得到的分割准确率为91%。
2018年,杨晗[33]利用3D FCN分割肺结节区域,并利用对抗训练以及融合不同层级的特征,实现对检测到肺结节分割,分割准确率为89.56%。
2019年,X.Meng等人[34]提出利用改进的三维FCN模型分割视网膜OCT图像,该方法减少了类别不平衡的影响,提高了分割准确率,对视网膜图像的分割精度为99.56%。
3.4 医疗影像识别
医疗影像分类是医疗影像诊断系统中关键的一部分,也是医疗诊断系统的最终目标。传统的医疗影像识别方法如小波变换法对医疗图像的特征信息提取有限,识别准确率偏低。而基于深度学习的医疗影像识别算法是目前的主流方法。
2017年,Esteva A等人[35]收集整理了12万张由专业的皮肤癌医生标注皮肤癌图像,利用迁移学习在inceptionV3结构中训练,达到了91%的准确率。
2018年,何雪英等人[36]利用VGG19框架对ISIC2017皮肤黑色素癌数据集迁移训练,并更改SoftMax损失函数权重,缓解样本数据不平衡,得到的识别准确率为71.34%。
2019年,Alom等人[37]结合InceptionV4结构、残差结构和卷积结构提出了Inception残差卷积神经网络对乳腺癌病理图像预测,利用BreakHis数据集训练,得到的预测准确率97.09%。
4 问题与展望
通过对基于深度学习的医疗影像识别技术的分析可以看出,近几年通过深度学习技术实现病灶识别分类的准确率得到极大提升。但是目前该技术发展还不完善,存在许多问题需要研究者去解决。
(1) 目前用于医疗影像识别的深度学习模型大多数都是以CNN网络算法为基础的。在以后的研究中,可以考虑医疗影像的特点,研究适合医疗影像识别的深度学习模型。
(2) 医疗影像数据获取困难,同时需要有大量医学经验的医生进行数据标注,大多数的医疗影像样本的数量极少。因此利用无监督学习算法解决医疗影像识别分类问题是之后重要的研究方向。
(3) 目前医疗影像识别模型大多数还处于理论阶段,如何利用构建的模型在临床中辅助医生医疗诊断,得到优异的识别准确率是一个重要的问题。
