基于模块度和标签传递的推荐算法
2020-09-29盛俊,李斌,陈崚
盛 俊,李 斌,陈 崚
(1.扬州大学信息工程学院,江苏扬州 225000;2.扬州市职业大学信息工程学院,江苏扬州 225000)
0 引言
随着网民数量的增加,近年来各种推荐系统得到了广泛的应用,可以向用户推荐书籍[1]、产品[2]、视频[3]和云计算服务[4]等。此外,还能向客户推介其满意的领域专家、合作者、娱乐节目、餐厅、服装、金融服务、人寿保险、交友约会等。推荐系统的核心是推荐算法的设计[5]。推荐算法要能够快速地从大量的信息中及时发现用户的喜好与消费习惯,发现与商品有关的有价值的内容,并动态、及时地向用户推介。根据所基于的数据分析方法的不同,主要有3 类推荐方法:协同过滤方法、基于规则的和基于内容的推荐方法。
协同过滤[6]是最常用的推荐方法。协同过滤方法的基本思想是:如果两个人所喜好的项目很相似,其中一个人采用过的项目,另一个人很可能也会采用,并且他们会喜欢过去喜欢的类似的东西。虽然协同过滤方法已经被广泛使用,但它还存在3 个问题需要解决:冷启动问题、可伸缩性问题和数据稀疏性问题。如何解决这几个问题,是协同过滤方法性能提高的关键。
基于关联规则的推荐[7-8]是利用关联规则所提供的信息,通过关联规则来计算各种商品被用户所偏好程度的相关性。该方法的缺点是对关联规则的发现需要大量的计算时间,对于大型的推荐系统,很难满足实时应用的需要。
推荐系统的另一种常见方法是基于内容的推荐[9-11],这种方法将不同的候选项与用户先前评价的项目进行比较,推荐最佳匹配项。该类方法比较简单,而且推荐结果具有可解释性,易于被理解。
二部网络是一种重要的复杂网络形式,通常用于两种不同类型的对象之间的关系建模。二部网络可以用图论中的二部图来表示,它的顶点可以分成两个不相交的两种类型的集合,在同一类型的顶点间不存在连接,只有在不同类型的顶点间才可能有条边连接。现实中的许多两种不同类型的对象之间的关系度可以用二部网络来描述。例如,一个足球运动员和俱乐部的关系可以用二分网络来描述,如果球员为某俱乐部效力,在该球员和俱乐部之间就会有一个连接。二部网络的其他的例子包括:用户与项目的网络[12]、公司投资者之间形成的股份网络[13]、论文-作者网[14-15]、蛋白质交互作用网络[16]、基因-疾病网络[17-19]等。推荐问题主要是针对二部网络而言的,二部网络的加权的邻接矩阵就是推荐问题中的用户-项目评分表。已经有一些基于二部网络的推荐方法,如基于二部网络的链接预测的方法[20]、基于相似度网络的个性化推荐方法[21]等。
还有一些推荐方法是基于复杂网络社区挖掘技术的,万慧等[22]针对电影推荐问题,提出了一种融合电影类别、用户评分和用户标签的电影推荐模型。该方法基于电影类别使用凝聚式层次聚类算法进行社区划分,在社区中进行推荐。黄泳航等[23]提出了基于社区划分的学术论文推荐方法。该方法在社区好友关系网络图中进行社区划分,根据社区划分结果在社区内部的用户之间推荐学术论文。贺怀清等[24]提出基于网络社区划分的协同推荐算法。该方法首先利用社区划分算法对用户进行社区划分,使得划分在同一社区的用户有共同话题和爱好,接着利用同一社区的用户寻找目标用户近邻集,最后根据近邻用户对未知项目的评分来预测目标用户的评分。
上述的各种基于复杂网络社区挖掘技术的推荐方法在对用户-项目网络进行社区划分以后,仅仅在社区内通过用户或项目相似度对项目进行推荐,这就限制了推荐结果只能在同一社区内进行,使得推荐结果的质量与社区划分密切相关。对于不同的粒度、不同的社区个数,其社区划分结果是不一样的。这样就很难找到一个能取得最优推荐结果的社区划分。为此,本文提出了基于社区挖掘的推荐算法,在考虑项目之间、用户之间的相似性的同时,还考虑社区之间的相似性对项目进行推荐。这样可以提高推荐结果的质量。
本文用带权的二部图来表达用户-项目的评分矩阵,利用二部网络的社区挖掘的技术,提出了在二部网络上进行社区挖掘的标签传递的算法,基于社区之间的相似性和用户间的相似性对项目进行推荐。该方法基于二部网络中的社区结构信息,充分利用了用户所在的社区之间的相似性,以及项目之间、用户之间的相似性来挖掘用户可能感兴趣的项目。由于二部网络的社区信息在一定程度上反映了用户和项目的相似程度,算法可以取准确率较高的推荐结果。
1 二部网络及其社区挖掘
二部网络可用一个无向简单二部图G=(U,V,E)来表示,其中,E为G的边的集合,U和V分别是G的两部分顶点的集合。U和V两部分顶点内部不存在连接的边,对于所有边(u,v) ∈E必有u∈U、v∈V。二部网络可以用来描述推荐问题,例如图1 所示为一个二部网络,其中上面部分的节点表示用户,下面部分的节点表示商品,在两个部分的一些节点之间的连线上具有权重,表示上面部分的节点所代表的用户对相应的商品的评分值,其值的范围为1~5。这样就描述了7个用户对8个商品进行评分的推荐问题。在图1中,有些商品和用户的节点之间没有连线,说明该用户尚未对该商品评分,也可能是该项评分丢失了。在这种情况下,带权邻接矩阵中的相应的元素aij的值为0。图1 中的二部网络的带权邻接矩阵如图2 所示,其中每行代表用户类型的一个顶点,每列代表项目类型的一个顶点。这实际上是推荐问题中的评分矩阵。因此每个推荐问题对应了这样一个加权二部图。

图1 二部网络示例Fig.1 Bipartite network example

图2 二部网络邻接矩阵示例Fig.2 Example of bipartite network adjacency matrix
复杂网络往往具有社区特性,社区是由拓扑性质相似、联系密切的顶点所组成的。设二部网络的两部分顶点分别称为X部分和Y部分,二部网络的社区挖掘的目的就是要分别把二部网络的X部分顶点和Y部分顶点各自划分为若干个社区,而且定义两个部分的社区之间的对应关系,使得社区间顶点连接比较稀疏,而社区内顶点之间连接比较稠密。
自2001 年Newman[25]提出社区挖掘的概念至今,已有很多学者提出关于复杂网络社区挖掘的方法。网络社区挖掘的代表性方法有基于优化模块度、基于顶点划分、基于标签传播、基于仿生计算的方法以及利用Markov 随机游走理论的方法等。
基于标签传播的社区挖掘方法的基本思想是任一顶点都必须和它的大部分邻居被划分在同一个社区里.该方法开始时将每一个顶点看作是一个社区,并给每个社区设定一个标签,然后通过迭代将标签传递,实现社区的合并。标签传递的规则是:每个节点取其邻居节点中出现最多的标签为自己的新标签。若邻居节点中出现最多的标签有多个,则根据一定的规则选取其中某一个作为自己的新标签。经过若干次这样的迭代后,紧密相连的节点的标签会趋于相同,即表示它们被划分在同一个社区。
2 兴趣密度值和稠密用户
本文首先用一个矩阵P=[pij]n*n来表示由n个用户对M个项目的评分,将这个评分矩阵看成带权的邻接矩阵,可构建一个带权二部图G={(ui,vj)|ui∈U,vj∈V,pij>0}。这里,U为代表用户的顶点集合,V为代表项目的顶点集合,E为边的集合,边(i,j)上有权重值pij>0,为用户i对于项目j的评分。推荐问题的目标就是要对给定的用户,计算那些没有评分的项目的评分估计值,并将具有较高的评分估计值的一些项目向该用户进行推荐。
在用户和项目数增多时,社交网络规模迅速扩大。此时,每个用户所参与评价的项目数占总项目数的比例会迅速变小,使得评分矩阵变得稀疏,这就导致了网络数据出现稀疏性。此外,由于用户对某一类商品的偏好性,他的评分会集中在某一类商品上。还有由于一些商品的用户的数量相对较少,如房屋、汽车等,用户对商品评分也就较少,导致了在用户-商品评分数据库的稀疏性。此外,新增的用户往往评分的商品较少,也会增加数据的稀疏性,从而降低推荐结果的质量。
为了解决评分矩阵的稀疏性问题,本文提出了兴趣密度值来挑出用户顶点中对项目评分较多的顶点构成稠密子集。然后在稠密子集中使用标号传递的算法进行社区挖掘,最终在得到的社区的基础上进行推荐。由于将评分矩阵所提供的用户偏好信息和网络的拓扑特征有机地结合,使得推荐的准确度得到提高。这也是一种基于社区挖掘的推荐算法。
针对数据的稀疏性问题,为了提高推荐结果的质量,本文挑选出用户顶点中对项目评分较多的顶点,从而从稀疏网络中构造一个连接密集的子网络,然后对该子网络中的顶点进行社区挖掘。为此定义每个用户ui的兴趣密度值des(ui):

其中sign()是符号函数,定义为:

由于用户ui的兴趣密度值des(ui)反映了用户ui评价的项目数,为此,本文设定一个阈值ε>0,定义稠密用户集合为:

如此使得评价的项目数高于阈值的用户定义为稠密用户。兴趣密度阈值ε的确定取决于网络用户侧顶点连接的稠密程度。该稠密程度定义为,即为所有用户的评论总数。在用户侧顶点连接的稠密程度较低时,用户的评论较少,可取较低的值(如ε=0.5);在网络连接较稠密时,可取较高的值(如ε=1.5),对于一般的网络可取ε=1。
由于一些商品对于大部分用户仅仅是一次性需求,如房屋、汽车等,对它们总的评价数量相对较少。此外,新增的商品往往很少被用户所知,导致评分较少,使得这些商品在用户-商品评分数据库中的稀疏性。为了提高推荐结果的质量,本文挑选出项目顶点中被评分较多的顶点,从而从稀疏网络中构造一个连接密集的子网络。为了合理地挑选被评分较多的项目顶点,对项目顶点也定义其兴趣密度值des(vj):

设定一个λ>0,定义稠密项目集合为:

类似于兴趣密度阈值ε的确定,稠密项目的阈值λ的确定取决于网络项目侧顶点的稠密程度:在链接较稀疏时,可取较低的值(如λ=0.5);在网络链接较稠密时,可取较高的值(如λ=1.5);对于一般的网络可取λ=1。
用连接密集的子网络中的用户及其相关项目构建新的评分矩阵P',同时由P'构建原二部图的子图G'=(U′,V′,E′)。然后在新的二部图G'中利用标签传递进行社区挖掘,这样可以把用户和项目一起聚类为若干社区,从而利用社区信息来计算相似度,再进行推荐。本文根据兴趣密度值选取稠密的用户顶点和项目顶点构成新的二部网络,其优点是使得对项目的推荐的信息集中在用户最感兴趣的项目上,其参考信息也来源于参与评分最活跃的用户中,这就使得推荐结果的准确率得到提高。此外,由于减少了二部网络中的顶点的个数,可以提高算法的执行速度。
3 标签传递算法
在对二部网络划分社区时,本文用模块度作为度量社区划分结果质量的标准。设U、V两部分各有p、q个顶点,社区划分结果的模块度定义如下:

这里,用i=1,2,…,p表示集合U中的顶点u1,u2,…,up;用j=1,2,…,q表示集合V中的顶点v1,v2,…,vq;ki、kj分别表示顶点ui、vj的度。用Lui代表顶点ui所归属的社区的标签,用Lvi代表顶点vi所归属的社区的标签,指示函数δ(Lui,Luj)的定义为:

若ui与vj归属于同一个社区,则δ(Lui,Luj)的值为1;否则值为0。式(6)中的M为二部网络中所有边上的评分值之和:。为了找出具有最大模块度的社区划分,文中对网络中每一对顶点定义了一个模块度增量,顶点ui、vj之间的模块度增量定义为:

所有顶点对的模块度增量构成了p*q的矩阵B=[bij],称为模块度增量矩阵。
对照式(6)和(7)可以发现,顶点ui、vj之间的模块度增量bij的值的大小表示整体模块度增加的程度。如果模块度增量bij较大,顶点ui与vj就归属于同一个社区。所以本文的算法目的就是逐次挑选模块度增量值较大的顶点对,将其划归同一个社区之中。根据这样的想法,本文提出标签传递算法来划分社区。
首先,在原有网络的顶点集上构造一个带权完全图,该图每条边上的权重为它所连接的节点对的模块度增量。一开始,把一个顶点看成一个社区,并给它定一个标签,然后将各个顶点的标签根据边上的模块度增量在完全图中进行传递:节点之间传递标签的概率会随着模块度增量的增大而增大。如此,它们就越有可能被划归到同一个社区。在传递标签时,通过迭代把每个节点的标签根据其邻居节点的标签来逐次更新,将每个顶点的标签更新为其邻居顶点中边的权重值之和最大的标签。因为边上的权重值就是模块度增量,而边上模块度增量又与该顶点连接,其值越大,取相连接的节点的标签的可能性就越大,它们也就越可能被划分到同一个社区。这样可以将模块度增量较大节点对划归到同一个社区中。重复上述标签传递过程,直到网络中的顶点的标签不再变化时为止。此时得到的社区划分会具有最大的整体模块度。
基于模块度增量和标签传递的社区挖掘算法的框架如下:


经过算法1 的处理,将稠密的用户和项目分别划分为若干社区,其中用户的每个社区与一个项目社区对应。对于非稠密用户,将其划归到其感兴趣的项目最多的社区之中。设I(uj)为非稠密用户uj的感兴趣的项目集合,记I(Ci)为第i个社区Ci中的项目集合,将用户uj划归到其感兴趣的项目最多的社区Ck(j):

社区的再划分实际上是将用户和项目的集合各自划分成许多不重叠的社区,在用户社区和项目社区之间存在一一对应关系,相对应的用户社区和项目社区一起构成了一个网络的子图。在该子图中,用户之间和项目之间的相似度如果较高,用户和项目之间的相关性也会较高。
算法1 的标签传播规则让模块度增量较大的节点对之间的标签传播概率越大,这本质上是在使模块度最大化,这样使得算法的社区划分的准确率较高。由于算法1 的标签传播过程简单易行,每轮迭代所需的时间为O(max{p,q}),因此算法时间复杂度较低。算法1 的另一个优点是,社区的个数无需作为参数预先指定,而是由算法取得使模块度最大化的社区的个数。
4 基于社区划分的推荐算法
利用算法1 将用户和项目划分成社区,使得最相似的用户以及他们最感兴趣的项目划归于同一个社区,就可以基于社区的信息进行推荐。本文在社区挖掘的基础上,提出对指定用户的项目评分的推荐算法。记用户v所在的社区为U(v),项目j所在的社区为I(j),用户u和v所在的社区U(u)和U(v)的相似度为SU(u,v),项目i和j所在的社区I(i)和I(j)的相似度为SI(i,j)。算法主要有4步:
步骤1 计算项目社区之间、用户社区之间的相似度。
项目社区I(i)和I(j)之间的相似度定义为:
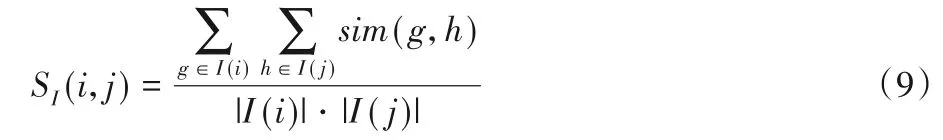
这里,sim(g,h)为项目g和h的相似度,可以通过计算评分矩阵相应列向量的余弦相似度或者相关系数得到。
用户社区U(i)、U(j)之间的相似度定义为:
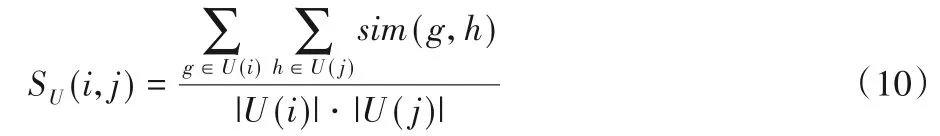
其中,sim(g,h)为用户g和h的相似度,可以通过计算评分矩阵相应行向量的余弦相似度或者相关系数得到。
步骤2 计算每一个用户u的相对于项目j的评分均值

其中:I(u)为用户所评价的项目的集合,SI(j,k)为项目j和k所在的社区I(j)和I(k)的相似度。
步骤3 根据用户间的评分偏差和用户的历史评分,预测用户对未评分物品的评分。还要计算用户u对项目j的评分puj。在对用户和项目进行社区划分后,首先判断用户u和项目j的社区U(u)和I(j)是否为相对应社区。若是,用户u对项目j的评分puj可以在U(u)和I(j)构成的子图中进行,计算公式为:

若用户u和项目j的社区U(u)和I(j)不是相对应社区,则要参考其他社区的信息以及社区间的相似度来计算用户u对项目j的评分puj,计算公式为:
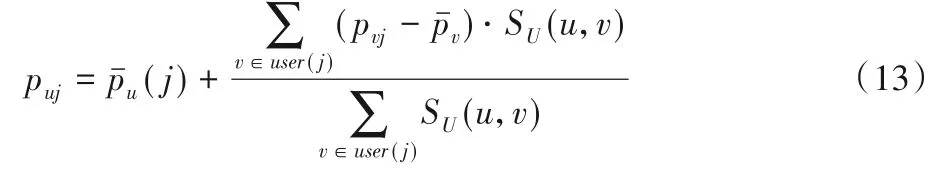
其中,user(j)是给项目j评分过的用户的集合,SU(u,v)为用户u和v所在的社区之间的相似度。在式(13)中,(j)为用户u对项目j的所在的社区的所有项目评分的均值,后面的一项为对用户u对项目j的偏好值的估计。这个估计值为所有给项目j评分过的用户v对项目j的偏好值的加权平均。权重为用户u与v所在社区的归一化相似度。计算过程如图3所示。

图3 评分puj的计算过程Fig.3 Computation of the score puj
从式(13)可见,对于某个用户来说,与他所在的社区相似度较高的社区里的用户的评分对他的推荐结果会产生较大的影响。
步骤4 对所得到的对项目的预测评分进行排序,将其中得分最高的N个项目向用户进行推荐。
下面给出基于社区挖掘的社交网络推荐算法的框架:

算法2 通过对二部图进行社区挖掘,对用户进行分类,然后根据用户对项目的偏好以及用户所在的社区间的相似度,再参考相关内容进行推荐。具有简单易行、效率高、推荐准确性较高的优点,还能有助于挖掘用户对一些项目潜在的偏好。
5 实验结果与分析
本文用电影网站数据集MovieLens 和Recsys 提供的Yelp消费评论的数据集,对上述基于社区挖掘的推荐算法CMBR进行实验,并将实验结果与类似的推荐算法进行了对比分析。文中采用Matlab 编码,在中央处理器为3.2 GHz,内存为8 GB,Windows 7,64位操作系统的计算机上运行。
5.1 实验数据集
5.1.1 MovieLens数据集
电影网站MovieLens数据集由GroupLens Research 实验室搜集整理。该数据集包含一些用户信息、电影信息以及电影评分,是一个最常用的实验数据集。本文选择数据集中100K大小的数据,包括1 682 部电影、943 个用户、100 000 个评分,评分值为1~5。
5.1.2 Yelp消费评论数据集
此数据集记录了Yelp 网站在美国亚利桑那州的每个顾客、每个商家的信息和他们的评分。该数据集被划分为训练集和测试集两部分:训练集中有商家12 742 个、顾客51 296个、评分252 863 条;测试集中有商家8 341 个、顾客15 001 个、评分36 404条。顾客的评分值为1~5。
上述两个数据集都是比较稀疏的。数据的稀疏度为未评分的数目占总体的百分比,稀疏度越大,数据集就越稀疏。
MovieLens 数据集共有943 个用户、1682 部电影以及100 000 条电影评价,训练集的稀疏度约为93.695%;Yelp 消费评论数据集中有20 万个顾客评分数据,其中有22 829 个用户仅有一个评分,Yelp训练集的稀疏度大约为99.961%。
5.2 推荐结果的评价指标
对于推荐结果的质量评估的最常用的指标是平均绝对差(Mean Absolute Error,MAE)和准确率(precision)。
5.2.1 平均绝对差
在统计学中,平均绝对误差(MAE)是两个连续变量之间的差值。在推荐问题中,平均绝对差定义为用户对项目的实际评分与推荐算法计算的评分之间的差。设用户对k个项目的实际评分值为{r1,r2,…,rk},推荐算法计算得到的相应的评分值为{p1,p2,…,pk},平均绝对偏差的计算公式如下:

由式(14)可以看出,较小的MAE 值表示推荐结果的精度较高。
5.2.2 准确率
在推荐问题中,设用户对k个项目的实际评分值为R={r1,r2,…,rk},而推荐算法计算得到的相应的评分值为I={p1,p2,…,pk},那么准确率的计算公式如下:

即为所推荐的正确项目的个数所占的百分比,其值在0~1,推荐结果越精确,准确率的值就越高。
5.3 实验结果及分析
本文把基于二部网络划分的标签传递社区挖掘推荐算法(CMBR)与其他4 种算法的预测结果准确度和平均绝对差进行比较。这4 个算法分别是基于双向关联规则项目评分预测的推荐算法(Collaborative Filtering recommendation algorithm based on item rating prediction using Bidirectional Association Rules,BAR-CF)[27]、基于项目评分预测的推荐算法(Collaborative Filtering recommendation algorithm based on Item Rating prediction,IR-CF)[28]、基于网络链接预测的用户偏好预测方法(user Preferences prediction method based on network Link Prediction,PLP)[29]和改进的基于用户的协同过滤的方法(Modified User-based Collaborative Filtering,MU-CF)[30]。从数据集中,观察到用户评论的条数的分布大部分集中在4~20,也就是说用户侧顶点的近邻个数集中在4~20。为了测试在各种近邻个数下不同算法的结果的平均绝对差,本文在实验中对4~20、间隔为4 的不同近邻数进行测试。实验结果如表1所示。

表1 两个数据集上各种算法在不同近邻个数下的平均绝对差Tab.1 Average absolute errors of various algorithms on two datasets under different neighbor numbers
由表1 可以看出,算法CMBR 在两个数据集上对于各种近邻数都可以取得最低的MAE 值。这说明算法CMBR 能够比其他算法取得更好的推荐效果。同时也可以看出,较大的近邻数可以取得准确率较高的推荐结果。
为了进行更全面的性能比较,本文采用5 折交叉验证进行实验,需要进行5次重复实验。文中将数据集随机地分成5个部分。在每次实验中用其中的4 个部分作为训练集、剩下的一个部分作为测试集。如果5次实验得到的MAE值的标准差小于阈值0.024,则取5 次测试结果的MAE 值的平均值作为MAE估计值。各种算法对于MovieLens和Yelp数据集上的平均MAE值如图4所示。
由图4可见,随着近邻数的增加,各种算法的MAE值都有所降低。但在相同的数量的最近邻居时,本文的推荐算法CMBR 的平均绝对偏差(MAE)比其他的推荐算法更小,推荐结果的精度更高,这表明文中所提出的基于二部网络划分的标签传递社区挖掘推荐算法CMBR优于其他的推荐算法。
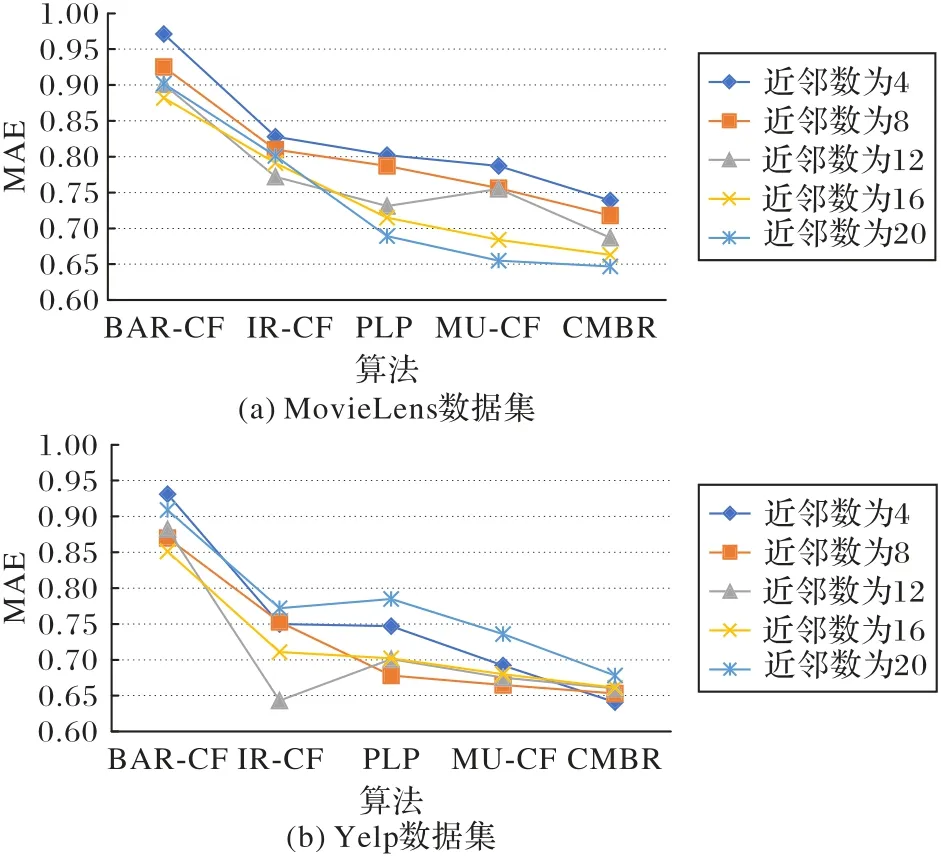
图4 两个数据集上各种算法在不同近邻数下的平均MAE值对比Fig.4 Average MAE value comparison of various algorithms on two datasets under different neighbor numbers
本文还测试了所提出的CMBR 算法的推荐结果与真实结果进行比较得出的准确率,并与其他四个算法在两个数据集上进行了比较,用得分最高的10 个项目作为推荐结果,其准确率的比较如图5所示。
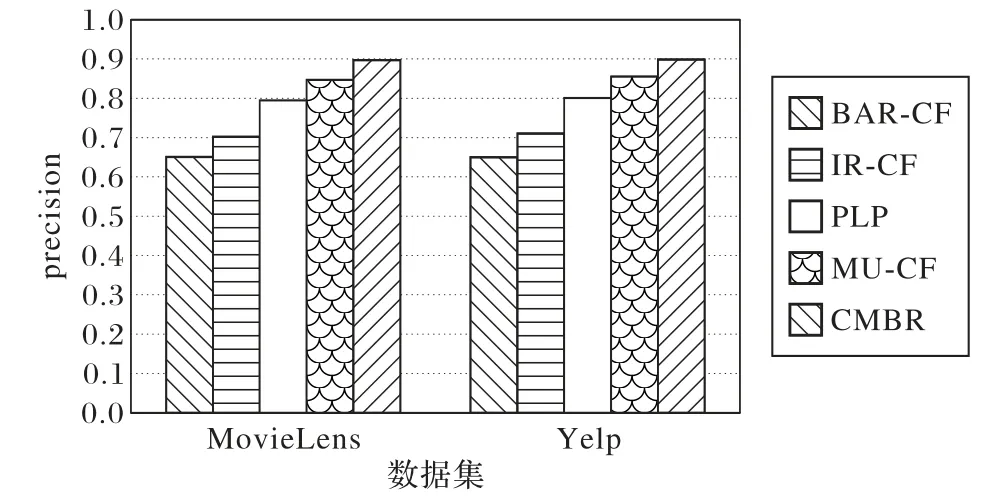
图5 各种算法推荐结果的准确率比较Fig.5 Precision comparison of recommendation results of various algorithms
由图5 可以看出,相较于其他的推荐算法,算法CMBR 在两个数据集上皆具有较高的准确率,取得较精确的推荐结果,说明本文提出的基于二部网络划分的标签传递社区挖掘推荐算法CMBR 明显优于其他的推荐算法。本文算法之所以能有效地提高推荐结果的准确率,是因为它充分利用了二部图的社区信息和用户-项目的评分信息,有机结合了用户和项目之间的评分信息和二部网络的拓扑结构[31]。
6 结语
本文提出了基于模块度和标签传递的推荐算法,该方法基于二部网络中的社区结构信息,充分利用了用户所在的社区之间的相似性,以及项目之间、用户之间的相似性来挖掘用户可能感兴趣的项目。实验结果也证明,该算法可以取得比其他类似方法更高准确率的推荐结果。
