基于并行混合网络融入注意力机制的情感分析
2020-09-29庄正飞余大为
孙 敏,李 旸,庄正飞,余大为
(安徽农业大学信息与计算机学院,合肥 230036)
0 引言
随着Web2.0时代的到来,越来越多的人们喜欢在网络上分享自己的一些经验、知识和感受等各种信息。例如,美团、饿了么、携程等各种应用软件都包含各种用户的评论信息,充分利用这些信息不仅能指导消费者进行合理消费,而且还能够让商家认识自身的问题,对下一次决策有关键的作用[1]。那么,如何从大量数据中高效、准确和快速获取用户的情感倾向就变得尤其重要。文本的情感分析是重要的研究方向其中之一,能够有效地分析出文本所包含的各种情感信息[2]。
文本情感分析[3]作为自然语言处理领域的一个重要研究方向。传统的文本情感分析的方法主要包含基于机器学习的方法[4]和基于词典[5]的情感分析两种。基于机器学习的方法需要大量人工标注数据,在处理复杂分类问题时泛化能力不强;基于词典的情感分析方法虽然不需要人工标注数据,但需要构建情感词典,而且分类的效果主要取决于情感词典的大小和质量。当下,卷积神经网络(Convolutional Neural Network,CNN)[6]和循环神经网络(Recurrent Neural Network,RNN)[7]作为两大主流深度学习模型被应用在自然语言处理领域并且取得很好的效果,尤其是在短文本的情感分析任务中。Kim[8]对比了词向量不同构造方法,把预训练处理好的词向量作为神经网络的输入,利用卷积神经网络实现句子级的文本分类,把神经网络应用于情感分类的任务中。Kalchbrenner 等[9]提出动态卷积神经网络模型用于提取句子的特征、处理不同长度的情感文本。由于传统的神经网络提取得到的只是局部特征,同时忽略了特征的前后联系,针对此问题本文提出并行混合网络融入注意力机制模型。
Mikolov 等[10]提出将循环神经网络应用到文本分类任务中,因为循环神经网络的输出取决于当前的输入和上一个节点输出的结果,可以更好学习到句子上下文的语义信息。但是循环神经网络在学习句子特征时容易出现梯度弥散问题,为了解决此问题,Hochreiter等[11]提出长短期记忆(Long Short-Term Memory,LSTM)网络模型,LSTM 是RNN 的众多变体之一,虽然LSTM 在提取长距离上下文语义信息上是一种很有效的网络模型,但结构复杂,因此导致训练需要大量的时间和内存空间。Cho 等[12]提出的门限循环单元(Gated Recurrent Unit,GRU)是LSTM 的一个变体,GRU 比LSTM 的架构简单,模型的训练效率得到了有效的提升。双向门限循环单元(Bidirectional Gated Recurrent Unit,BGRU)神经网络是由一个向前传播的GRU和一个向后传播GRU,前后两个方向GRU的输出状态连接组成的神经网络,本文使用BGRU 来提取全局的特征挖掘文本中深层语义信息。
注意力机制的核心作用是在众多信息中注意到对当前任务更关键的信息。Mnih 等[13]进行图像处理时在RNN 基础上引入注意力机制,使得图像处理效果较好。Bahdanau 等[14]把注意力机制应用在自然语言处理任务中,通过注意力机制可以把每个词学习到的表达和预测需要的词联系起来。从此之后,注意力机制被文本分析学者所广泛关注,例如,王伟等[15]提出基于BiGRU-Attention模型的情感分类;田生伟等[16]将Bi-LSTM 和attention 机制结合对维吾尔语事件实训关系进行识别;白静等[17]使用BiLSTM-CNN-Attention 进行两种特征融合的分类;陈洁等[18]采用混合神经网络模型处理短文本情感分析都取得比较好的分类结果。
为了避免单一卷积神经网络忽略词的上下文语义信息和最大池化处理时会丢失大量特征信息,本文在卷积神经网络和BGRU 提取得到的特征融合之后引入注意力机制提高文本情感分析的准确率和F1-Measure综合评价指标。
1 混合网络融入注意力机制模型
本文提出并行混合网络融入注意力机制模型的文本情感分析构造方法主要从以下两个方面考虑:1)把卷积神经网络和双向门限循环神经网络学习得到的特征进行融合;2)把融合之后的特征送入到注意力机制中以便判断不同的词对句子含义的重要程度。
1.1 CNN并联BGRU提取特征并融合
本文利用卷积神经网络提取句子的局部特征,卷积神经网络的结构主要有输入层、卷积层、池化层和输出层。卷积神经网络结构如图1所示。
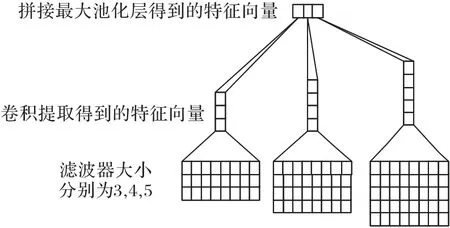
图1 卷积神经网络结构Fig.1 Convolutional neural network structure
输入层 文本中每个句子中每一个词都要利用Glove 映射为对应的词向量xi,句子中每个词向量xi组成句子矩阵S,如式(1)所示:

其中,xi∈Rk,xi表示句子矩阵中第i个词的词向量,k表示词向量的维度。S∈Rn×k,n表示句子矩阵中词向量的个数。本实验中词向量的维度k=200。
卷积层 卷积层采用r×k的滤波器对句子矩阵S执行卷积操作提取S的局部特征c。如式(2)所示:

其中:w代表卷积核,b代表偏置项;f代表通过ReLU进行非线性操作的函数;xi:i+r-1代表句子矩阵中从i到i+r-1 共r行向量;ci代表通过卷积操作得到的局部特征。滤波器在整个句子矩阵中从上往下已设置的步长进行滑动,得到局部特征向量集合C,如式(3)所示:

池化层 池化方法分为两种,分别为最大池化和平均池化,本实验采用最大池化的方法对卷积操作得到的局部特征向量集合提取最大的特征代替整个局部特征,而且通过池化操作还可以降低特征向量的大小。如式(4)所示:
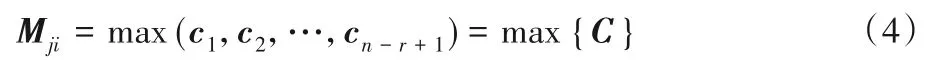
其中,1 ≤j≤r,1 ≤i≤n-m+1,m为卷积核个数。
输出层 将池化层中得到的所有Mji拼接组成句子级特征向量。
文本具有很强的序列性,因此充分提取文本上下文语义信息就显得非常重要。为了体现文本的序列特征,使用LSTM建立序列模型。但是LSTM 模型结构复杂,在训练时会花费更多的时间代价。GRU 是LSTM 的变体,主要的变化是使用更新门代替了LSTM 中的输入门和遗忘门,模型结构的复杂度相对变得更加简单,训练参数减少并且时间代价比较低。其模型结构如图2所示,具体的计算过程如式(5)~(8)所示:
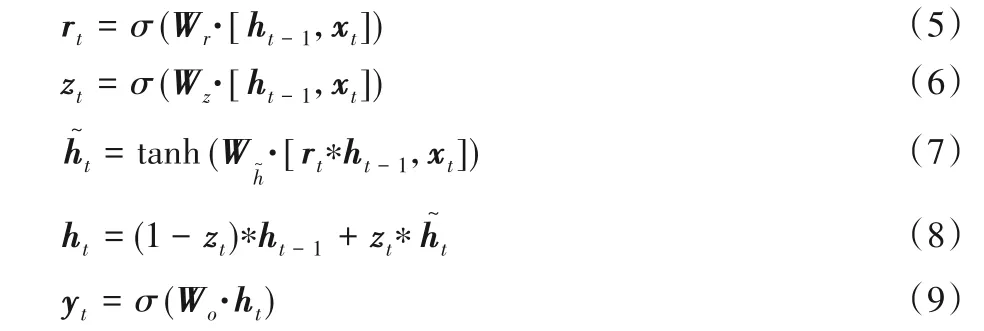
其中,rt表示重置门;zt表示更新门;ht表示隐含层状态的输出;yt表示GRU 的输出;Wr,Wz,Wh,Wo分别表示各个状态的权重矩阵,σ和tanh表示激活函数。
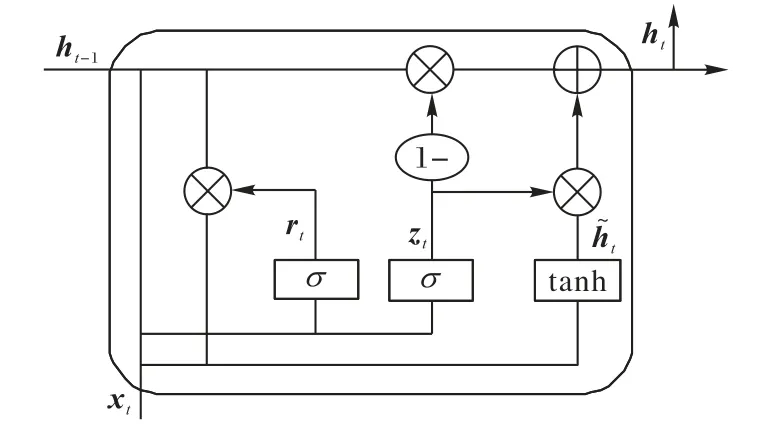
图2 GRU模型结构Fig.2 GRU model structure
GRU 只是考虑当前词的上文信息并没有考虑到下文的信息,为了解决这个问题,本文使用双向门限循环神经网络不仅能够充分提取上文信息而且还能考虑到下文信息对当前词的影响,主要是由1 个单向向前传播的GRU 和1 个单向向后传播的GRU 组成,输出的结果由这2 个GRU 共同决定。其网络结构如图3所示,具体的计算过程如式(10)~(12)所示:
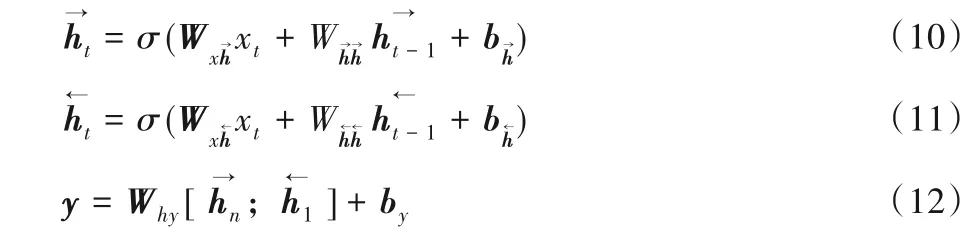
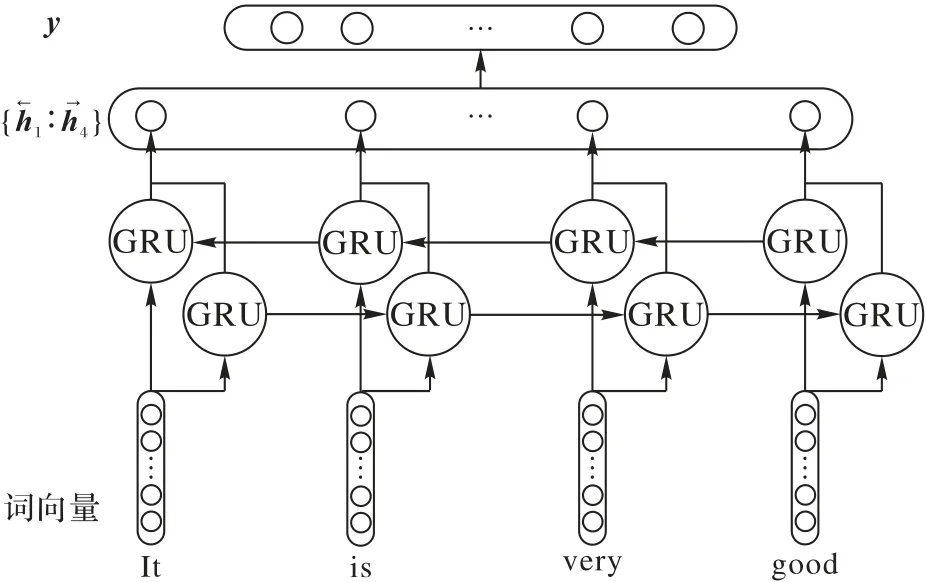
图3 BGRU情感分析网络模型Fig.3 BGRU sentiment analysis network model
1.2 注意力机制获取词的重要程度
注意力机制来源于对人类视觉的研究,人们会在所有的信息中选择性地关注自己在意的部分,同时还可以忽略其他的信息。把注意力机制应用在文本的情感分析中可以通过权重的分配计算不同词的词向量概率权重,使得部分词可以得到更多的关注从而突出重要的词语,提高分类的准确率。其模型结构如图4所示。
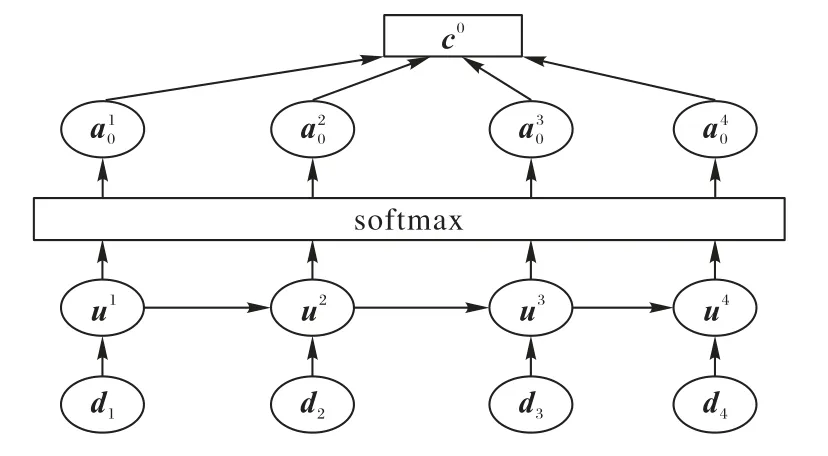
图4 注意力机制模型结构Fig.4 Attention mechanism model structure
假设dt为卷积神经网络和双向门限循环神经网络提取得到的特征融合之后的特征向量,通过神经网络得到对dt隐层的表示,如式(13)所示:

1.3 并行混合网络融入注意力机制模型
1.3.1 并行混合网络融入注意力机制模型的构造
并行混合网络融入注意力机制模型结构如图5 所示。本文的模型主要由卷积神经网络(CNN)、双向门限循环神经网络(BGRU)和注意力机制组成。其中,模型左边的卷积神经网络部分是由3个大小分别为3、4、5的卷积核组成,为了能够更加全面地提取文本中的局部特征;模型右边的是利用双向门限循环神经网络提取词的上下文的语义信息和文本中词的全局特征;模型的下面是注意力机制,主要是利用卷积神经网络和双向门限循环神经网络提取得到的特征计算不同的词向量概率权重,使得部分词得到更多的关注,提高分类的准确率。
本文并行混合网络融入注意力机制模型详细介绍如下:
1)将文本中的词利用Glove 映射为对应的词向量xi,然后组成句子矩阵S。
2)增加卷积神经网络,提取得到文本中的局部特征Mji。
3)增加双向门限循环神经网络,得到词的上下文语义信息和词的全局特征y。
4)将2)、3)提取的特征融合得到dt作为注意力机制的输入,为了使部分词得到更多的关注提高分类的准确率,得到文本向量ct。
5)增加Dense层,使用sigmoid激活函数对文本进行分类。
6)模型损失函数使用交叉熵损失函数categorical_crossentropy,模型在训练的过程中不断地更新参数达到最优的效果。

图5 并行混合网络融入注意力机制模型Fig.5 Model based on parallel hybrid network and attention mechanism
1.3.2 并行混合网络融入注意力机制模型的训练
本文在训练并行混合网络融入注意力机制模型中的参数包括卷积神经网络、双向门限循环神经网络和注意力机制中的全部参数。本模型使用的优化器是Adam,因为Adam 优化器结合了RMSProp 和AdaGrad 二者的优点,还可以计算参数的自适应学习率。为了防止在训练过程中过拟合,分别在三个卷积层之后加入Dropout 函数,并把Dropout 设置为0.5,通过在每一次的迭代中随机丢弃部分训练参数来提高模型的泛化能力。本模型使用Sigmoid函数进行分类如式(16)所示:
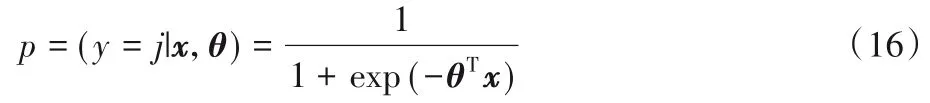
其中:j表示的是类别数,本文中主要分为积极和消极,取值是0 或者1。θ为模型所有的参数。训练模型的参数θ使用的损失函数是交叉熵损失函数。本文样本点为(x,y),y为真实的标签,取值是0或者1。现在假设yt为样本点的真实标签,yp为该样本点属于积极类别的概率。如式(17)所示:
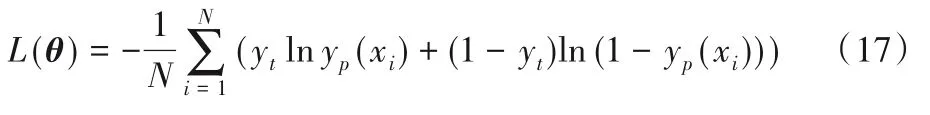
2 实验
在公开带有情感标签的电影评论IMDB 数据集上,对本文提出的情感模型进行验证和分析。实验环境具体配置如表1所示。
2.1 实验数据
实验的数据主要来自于电影评论IMDB 数据集,电影情感评论的标签主要分为二种:0 或者1。如果情感评论是积极的标记为1,情感评论是消极的标记为0。数据集的划分情况如表2所示。
表1 实验环境具体配置Tab.1 Detailed configuration of experimental environment

表2 数据集Tab.2 Datasets
2.2 实验参数设置
实验参数的设置直接影响模型的分类效果,但实验中又有很多的超参数需要设置与调整,在每一次迭代完成之后,会根据实验的准确率和损失率对所设置的超参数调整,经过多次实验以及多次迭代具体的参数设置如表3所示。
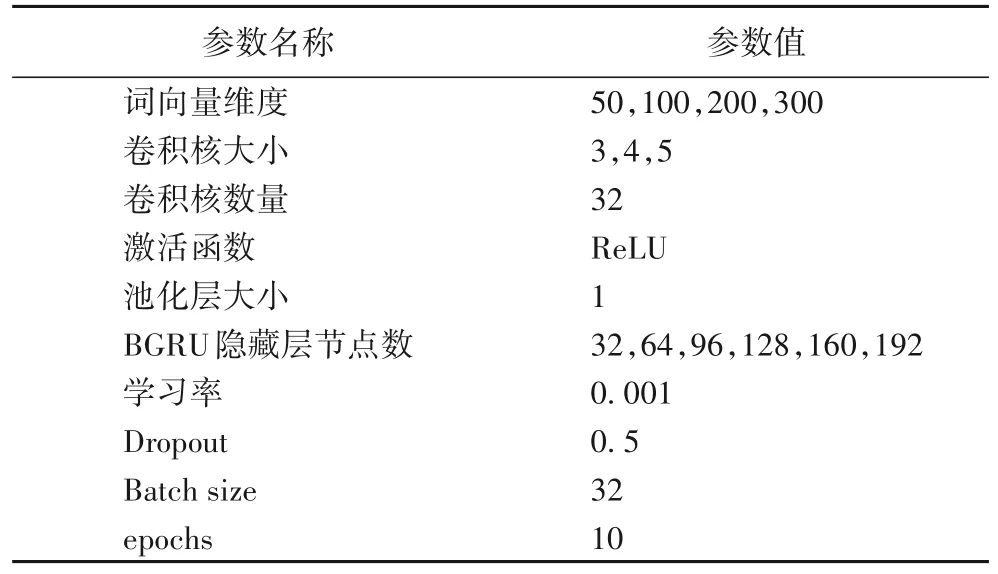
表3 参数设置Tab.3 Parameter settings
2.3 实验评价标准
评价是实验中一个重要的环节,可以直接反映出模型的好坏,本实验在电影评论情感分析的样本上采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Measure作为评价情感分析结果好坏的标准。准确率评估的是对模型正确分类的能力;精确率评估的是查准率;召回率评估的是查全率;F1-Measure 是综合评价指标。本实验针对该问题给出的分类结果混淆矩阵如表4所示,用此来介绍4种实验评价标准的计算方式。其中:TP(True Positive)指的是积极分类预测为积极分类数,FN(False Negative)指的是积极分类预测为消极分类数,FP(False Positive)指的是消极分类预测为积极分类数,TN(True Negative)指的是消极分类预测为消极分类数。
准确率(Accuracy)计算如式(18)所示:


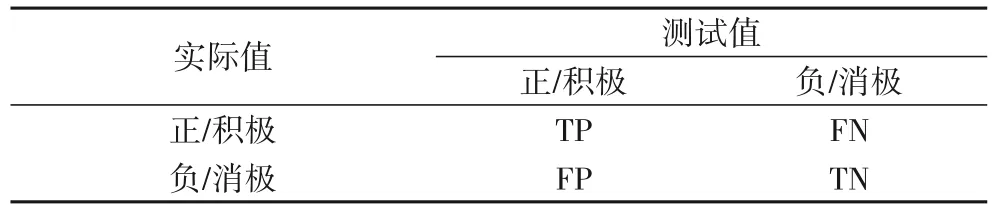
表4 分类结果混淆矩阵Tab.4 Confusion matrix of classification results
2.4 词向量维度的选择
词向量能够有效地反映词与词之间的关联度以及语义信息,理论上来说词向量维度越大越好,但是在实际情况的应用中需要考虑实验的整体性能和整体代价,从而选出最合适的词向量维度。分析表5可得,当词向量维度为50时,模型的整体性能最差,主要是因为词向量维度过小,使得词中包含的上下文相互影响的语义信息较少;当词向量维度为200 时,模型的整体性能最好,训练的时间相对较小,主要因为词中上下文的关联度比较大,包含更丰富的文本语义信息。因此本模型把词向量的维度设置成200。
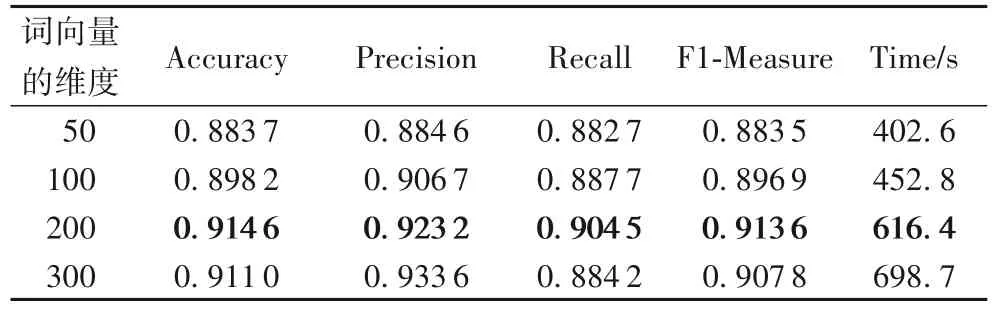
表5 不同词向量维度的实验结果Tab.5 Experimental results of different vectors dimensions of words
2.5 BGRU隐藏层节点数的选择
根据表6分析可以得出,当BGRU 隐含层节点数为32时,模型的accuracy 和F1-Measure 最低,因为节点数过少不能够完全地提取语义信息;当节点数由64 增加到96 时,模型的Accuracy 和F1-Measure 达到最高的值;随后继续增加节点数,Accuracy 和F1-Measure 都呈现下降的趋势,说明当节点数不断增加时,模型的整体性能越来越差。所以,本实验中BGRU隐含层节点数选择为96最好。
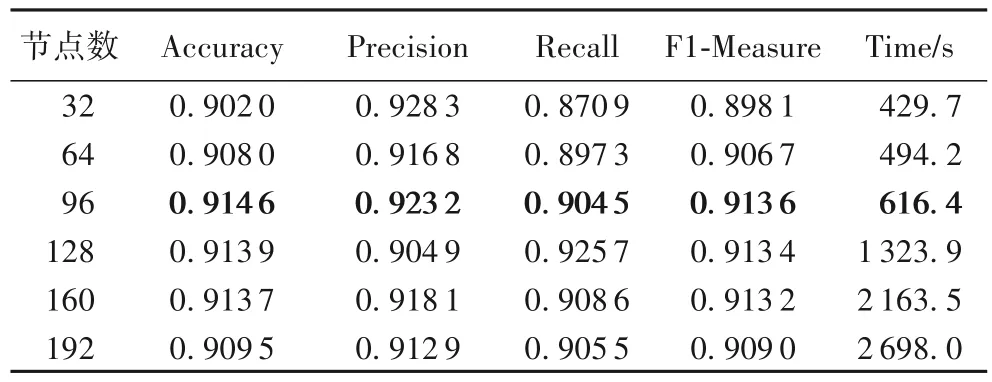
表6 不同节点数的实验结果Tab.6 Experimental results of different numbers of nodes
2.6 对比实验设置
本实验模型与以下几种常见模型进行对比分析。为了使对比的结果更具有可比性和准确性,所有模型词向量的输入都是Glove200维,每个对比模型中的参数值选取都一样。
1)CNN[19]:只有CNN,由3 个卷积核大小分别为3、4、5 的卷积神经网络组成。
2)BLSTM[20]:只有BLSTM 网络,其中BLSTM 隐含层节点数为96。
3)BGRU[21]:只有BGRU 网络,其中BGRU 隐含层节点数为96。
4)CNN-BGRU:把3 个卷积核大小分别为3、4、5 的CNN与隐含层节点数为96的BGRU网络链式连接。
5)CNN+BGRU:此模型主要是把3个卷积核大小分别为3、4、5的CNN与隐含层节点数为96的BGRU网络并行连接。
6)CNN+BGRU+Attention:本文提出的模型在把3 个卷积核大小分别为3、4、5的CNN与隐含层节点数为96的BGRU网络并行连接的基础上引入注意力机制。
2.7 实验结果分析
实验在测试集上计算出Accuracy 值、Precision 值、Recall值、F1-Measure值,具体各个模型实验结果如表7所示。
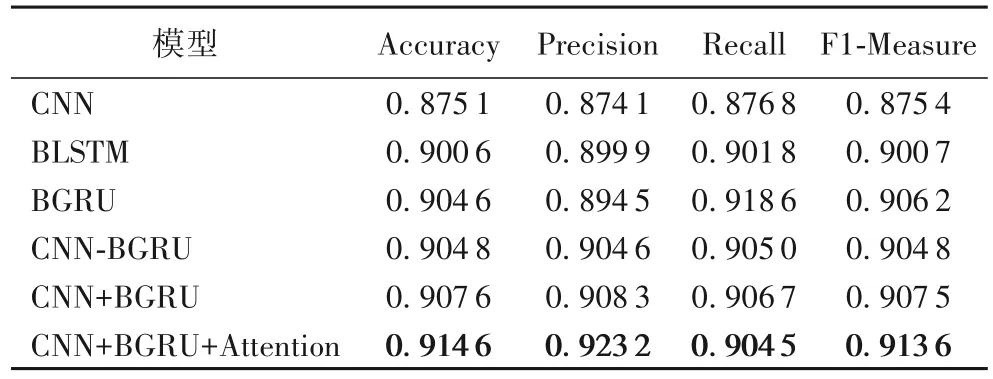
表7 不同模型的实验结果Tab.7 Experimental results of different models
表7给出了6种实验结果,从Accuracy 和F1-Measure这两个评价指标可以得出,本文提出的CNN+BGRU+Attention 模型分别达到了91.46%和91.36%,均优于其他的5种模型。从1、2组对比的实验结果可知,只利用卷积神经网络提取文本语义信息的效果远差于利用双向长短时记忆神经网络获取文本的上下文语义信息;从2、3 组可以看出在BLSM 结构上做了改进的BGRU 不仅在训练的时间上大幅缩减而且模型的Accuracy 和F1-Measure都得到了部分的提升;从4、5组和1、2、3组的实验结果可以看出,两种模型的任意组合在情感分析的任务中都要比单个CNN模型或者单个的BLSTM、BGRU模型效果好,主要是因为可以利用CNN提取文本的局部语义信息,以及对文本特征的强学习能力,双向循环神经网络可以提取序列化特征上下文的学习能力,因此在模型组合时对CNN提取得到的特征进行再加工有着积极作用;第4 组的链式融合主要来源于Lai 等[22]将CNN模型和BiGRU模型以链式的方式融合,从4、5组对比实验的结果可知本文提出并行融合的方式比链式融合方式效果更好;从5、6组实验得出,在融合之后的模型中引入注意力机制能有效地提高Accuracy和F1-Measure,因为注意力机制通过权重的分配计算不同词的词向量概率权重,为模型学习到的特征给予不同的关注度,有利于模型快速地抓住最重要的特征。
本文将6 种模型在IMDB 数据集上,利用表3 参数设置中的参数训练,得到在验证集上的准确率、损失率与迭代次数之间的变化曲线,分别如图6和图7所示。

图6 不同模型验证集准确率变化情况Fig.6 Variation of accuracy of different models on verification set
从图6 中可以看出,随着迭代次数的增加,各个模型的准确率都在逐渐上升,并且在第二次迭代的时候所有模型的准确率都达到87%以上。本文模型的曲线相对于其他5条曲线变化比较平稳,波动较小,验证集准确率的值处于较高的位置,尤其在第7次迭代后较为明显达到93%以上,得出本文模型在提取文本特征情感分析任务中更稳定。
根据图7可以分析出,CNN模型和BLSTM模型相对于其他4种模型的损失率变化波动最大极其不稳定;而本文所使用的模型loss值下降速度较快并且loss值很快到达了一个相对低的稳定值,总结出本文设计的模型取得了较好的收敛效果。
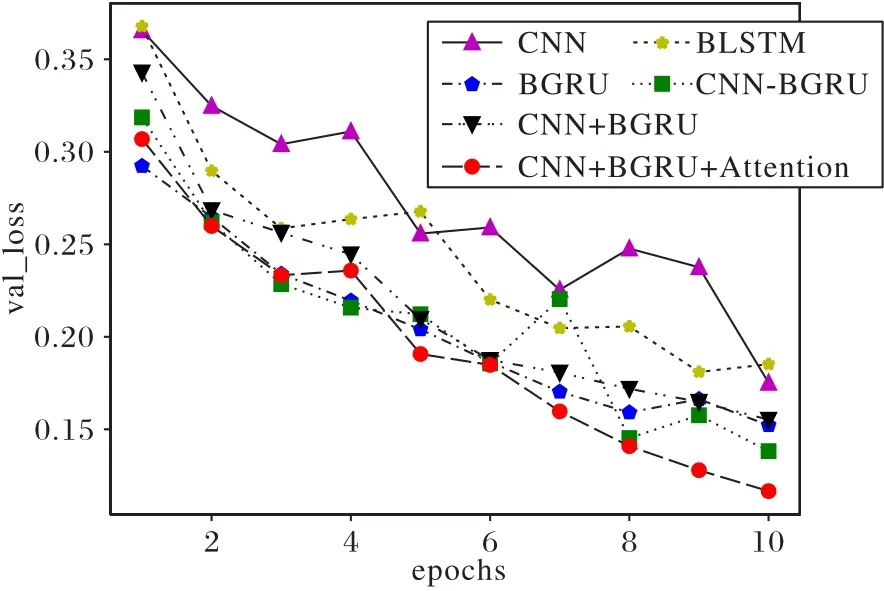
图7 不同模型验证集损失率变化情况Fig.7 Variation of loss of different models on verification set
迭代时间指的是完成一次实验所需要的时间。图8 给出了迭代时间与迭代次数之间的变化曲线。总体来看各个模型的迭代时间没有很大的波动,整体时间呈平稳趋势。CNN 模型的迭代时间最短,主要的原因是卷积神经网络的最大池化层的训练迭代收敛;BLSTM 的迭代时间最长,这与BLSTM 结构比较复杂、参数太多分不开,BGRU 是BLSTM 的一种改进,减少“门”的数量,并把细胞状态和隐藏状态结合在了一起,结构更加简单,训练参数减少,因此训练的时间也降低很多;本文提出模型的迭代时间高于CNN-BGRU 和CNN+BGRU,主要的原因是引入注意力机制在能够获取重点信息的同时也增加了加权计算时间。
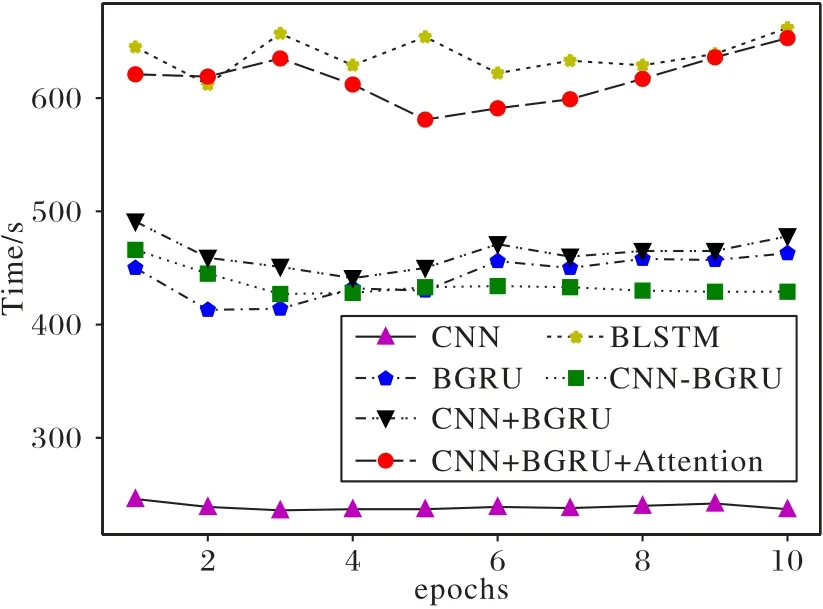
图8 不同模型迭代时间变化情况Fig.8 Iteration time variation of different models
3 结语
本文提出一种基于并行混合网络融入注意力机制的文本情感分析方法,该方法将文本转换为词向量后分别通过3 个大小不同的卷积核更全面、更细致地提取文本的特征和双向门限循环网络获取上下文的语义信息,在提取得到的特征进行融合之后引入注意力机制使部分词可以得到更多的关注突出重要的词语,从而提高模型对文本类别的分类能力。从实验结果的分析中可以看出,在相同的实验条件下本模型的整体性能比单个CNN 或者单个BGRU 要好得多,虽然本模型在IMDB数据集上的准确率、综合评价指标较高,损失率较低,但是如果数据集的数量比较大,准确率、综合评价指标可能会有所下降,同时训练的时间大大增加。需要不断地改进模型以及算法,使得模型在数据量比较大时,得到较高的准确率、较低的损失率,同时减少训练的时间。
